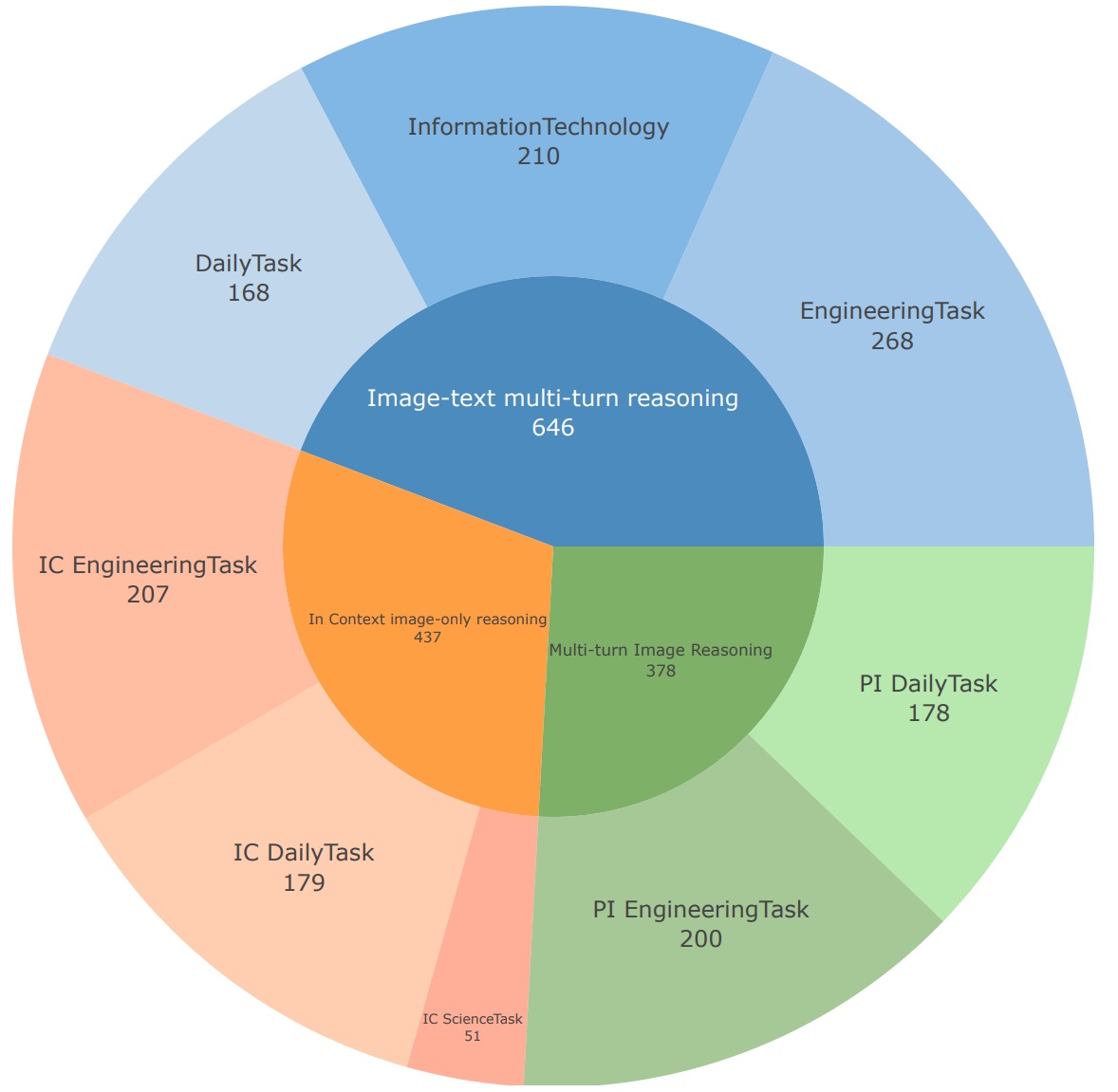
Understanding multi-image, multi-turn scenarios is a critical yet underexplored capability for Large Vision-Language Models (LVLMs). Existing benchmarks predominantly focus on static or horizontal comparisons -- e.g., spotting visual differences or assessing appropriateness -- while relying heavily on language cues. Such settings overlook progressive, context-dependent reasoning and the challenge of visual-to-visual inference. To bridge this gap, we present VisChainBench, a large-scale benchmark designed to rigorously evaluate LVLMs' ability to perform multi-step visual reasoning across sequential, interdependent tasks with minimal language guidance. VisChainBench contains 1,457 tasks spanning over 20,000 images across three diverse domains (e.g., daily scenarios, engineering troubleshooting), structured to mimic real-world decision-making processes. Uniquely, the benchmark is constructed using a multi-agent generation pipeline, ensuring high visual diversity and controlled language bias. All the benchmark data and code for benchmark construction are available for viewing and download via following Link: https://huggingface.co/datasets/eyehole/VisChainBench
💡 Deep Analysis
📄 Full Content
VisChainBench: A Benchmark for Multi-Turn, Multi-Image Visual Reasoning
Beyond Language Priors
Wenbo Lyu1, Yingjun Du2, Jinglin Zhao3, Xianton Zhen4, Ling Shao1
1University of Chinese Academy of Sciences
2University of Amsterdam
2Huazhong University of Science and Technology
2United Imaging Healthcare
lvwenbo23@mails.ucas.ac.cn
Abstract
Understanding multi-image, multi-turn scenarios is a critical
yet underexplored capability for Large Vision-Language Mod-
els (LVLMs). Existing benchmarks predominantly focus on
static or horizontal comparisons—e.g., spotting visual differ-
ences or assessing appropriateness-while relying heavily on
language cues. Such settings overlook progressive, context-
dependent reasoning and the challenge of visual-to-visual in-
ference. To bridge this gap, we present VisChainBench, a large-
scale benchmark designed to rigorously evaluate LVLMs’ abil-
ity to perform multi-step visual reasoning across sequential,
interdependent tasks with minimal language guidance. Vis-
ChainBench contains 1,457 tasks spanning over 20,000 images
across three diverse domains (e.g., daily scenarios, engineer-
ing troubleshooting), structured to mimic real-world decision-
making processes. Uniquely, the benchmark is constructed
using a multi-agent generation pipeline, ensuring high visual
diversity and controlled language bias. All the benchmark data
and code for benchmark construction are available for viewing
and download via following Link:
https://huggingface.co/datasets/eyehole/VisChainBench
Introduction
The rapid development of Large Vision-Language Models
(LVLMs) (Li et al. 2025; Bai et al. 2025; Google 2024; Liu
et al. 2024a; openai 2024) has led to impressive progress
in multimodal understanding, enabling applications rang-
ing from visual question answering (Yu et al. 2023; Masry
et al. 2022) to interactive robotics (Zitkovich et al. 2023; Li
et al. 2024b). A core capability underlying these advances is
the ability to reason over multiple images across extended
interactions-a skill essential for real-world tasks such as tech-
nical troubleshooting, intelligent device agents, or sequential
visual decision-making. For instance, diagnosing a malfunc-
tioning device may require analyzing its defective component,
selecting the appropriate repair tool, and verifying the out-
come—all through a chain of visual inputs.
In realistic scenarios such as embodied agents (Yang et al.
2025; Koh et al. 2024; Jansen et al. 2024), models are ex-
pected to track dynamic environmental changes across im-
age sequences and respond accordingly. Similarly, personal
assistant agents must interpret evolving screenshots and au-
tonomously identify pending tasks. These applications re-
Preprint
Figure 1: Traditional VQA tasks rely on language prompts and re-
sponses (top). VisChainBench introduces a purely visual paradigm,
where the context, prompt, and answer are all images-challenging
models to perform multi-step visual reasoning without textual cues
(bottom).
quire models to infer task objectives purely from visual con-
text, without explicit textual prompts—a capability largely
absent from current benchmark evaluations. This gap raises a
critical question: what forms of reasoning must LVLMs per-
form to succeed in such settings? From assessing the current
visual state to anticipating future steps and making decisions
under uncertainty with less language guidance, robust multi-
modal reasoning is key.
Although many LVLMs achieve strong results on percep-
tual or single-step tasks, their ability to conduct multi-step,
image-to-image, and context-dependent reasoning, as men-
tioned above, remains underexplored. To address this, we
introduce VisChainBench, a benchmark specifically designed
to evaluate multi-turn visual reasoning under minimal linguis-
tic guidance. Unlike prior datasets, our benchmark presents
tasks as structured visual chains, requiring models to reason
progressively across linked visual contexts.
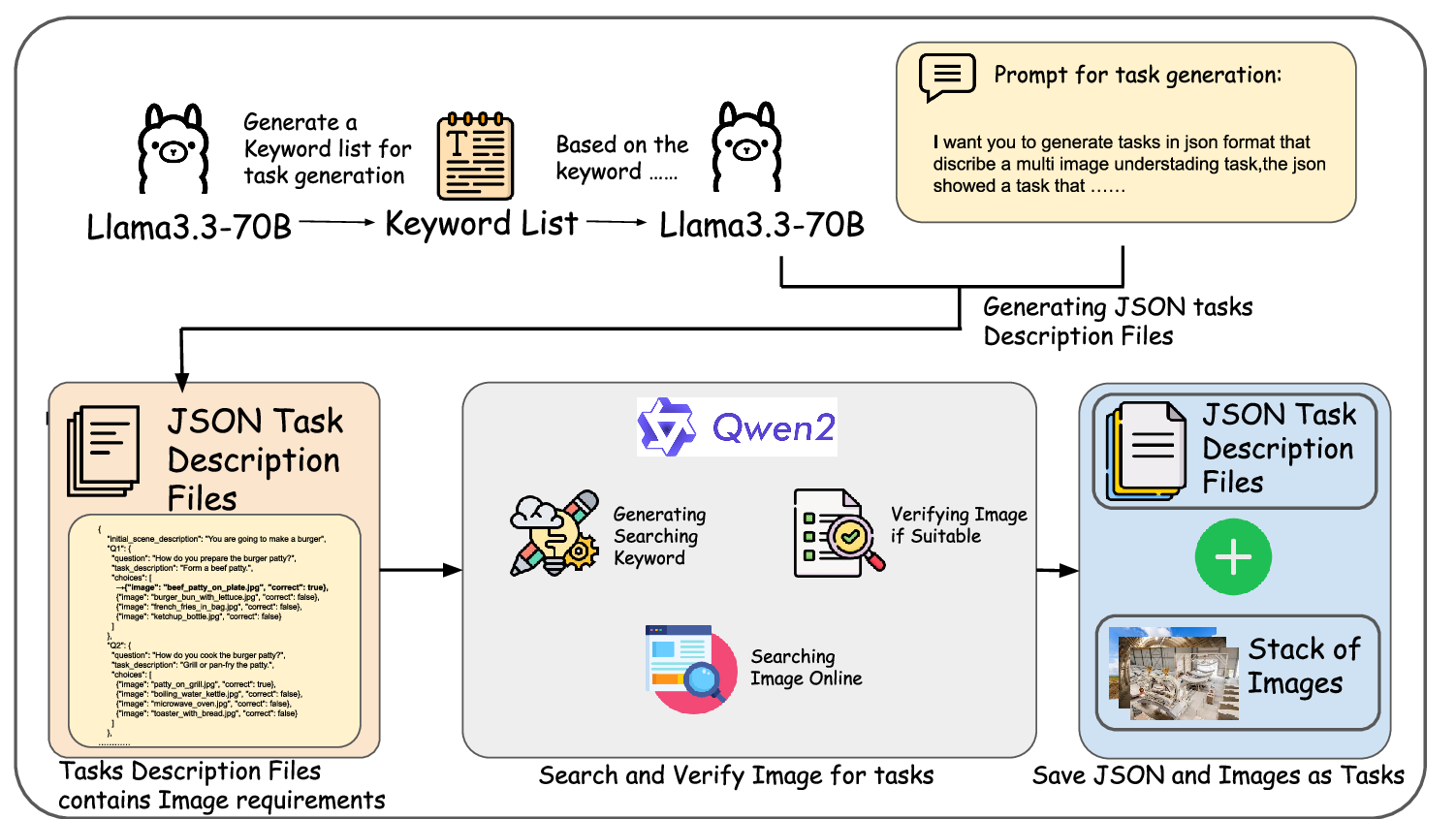
VisChainBench is constructed using a multi-agent pipeline:
initial task structures are generated by language models, rele-
vant images are retrieved or synthesized, and human annota-
tors refine both the tasks and their annotations. This process
ensures high-quality, diverse, and visually grounded task se-
quences that challenge model reasoning beyond superficial
patterns.
arXiv:2512.06759v1 [cs.CV] 7 Dec 2025
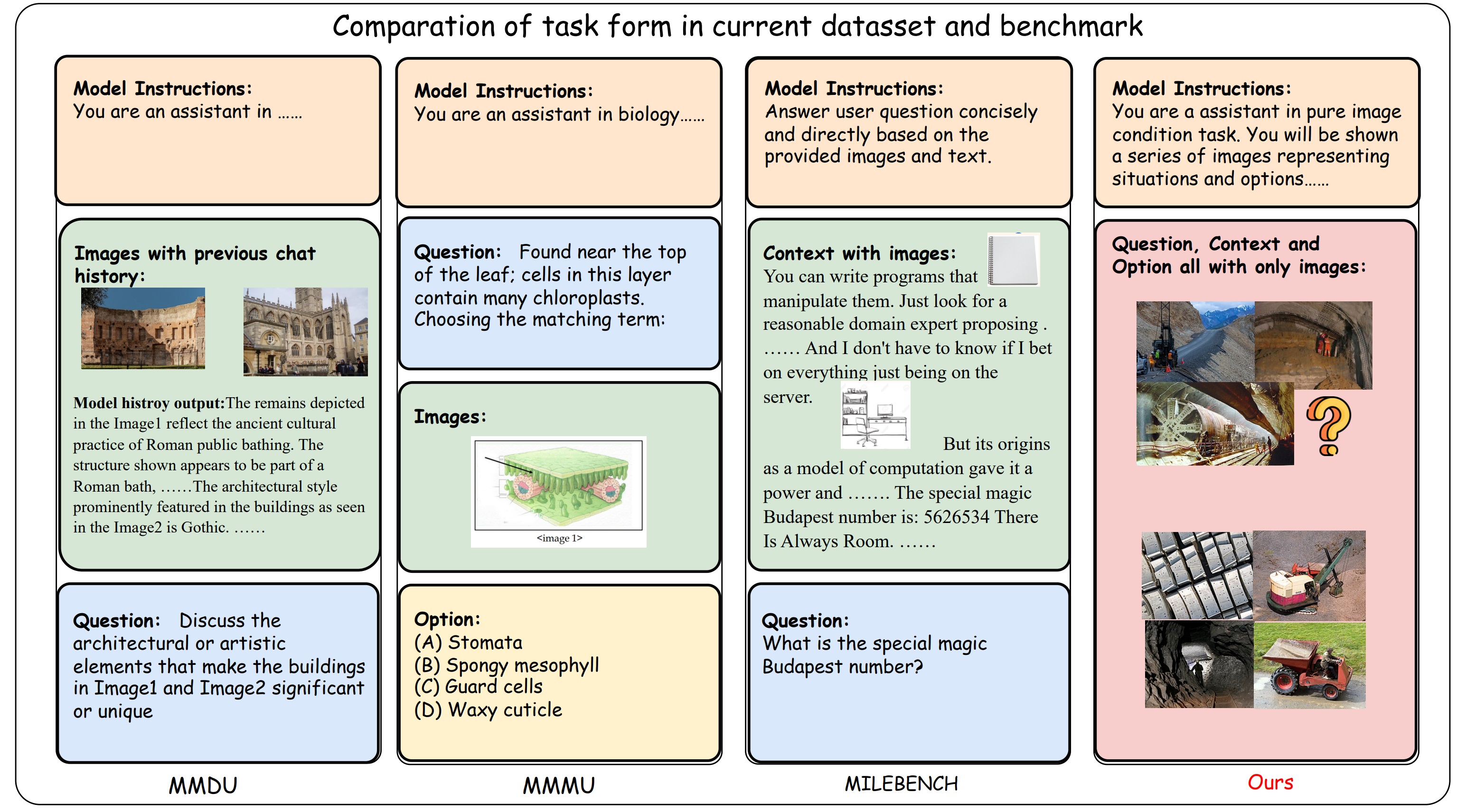
Figure 2: Comparison of task formats in prior benchmarks. Previous benchmarks are often text-heavy and encourage shallow image
comparisons, whereas our benchmark emphasizes progressive image-grounded reasoning.
Our benchmark features the following distinctive aspects:
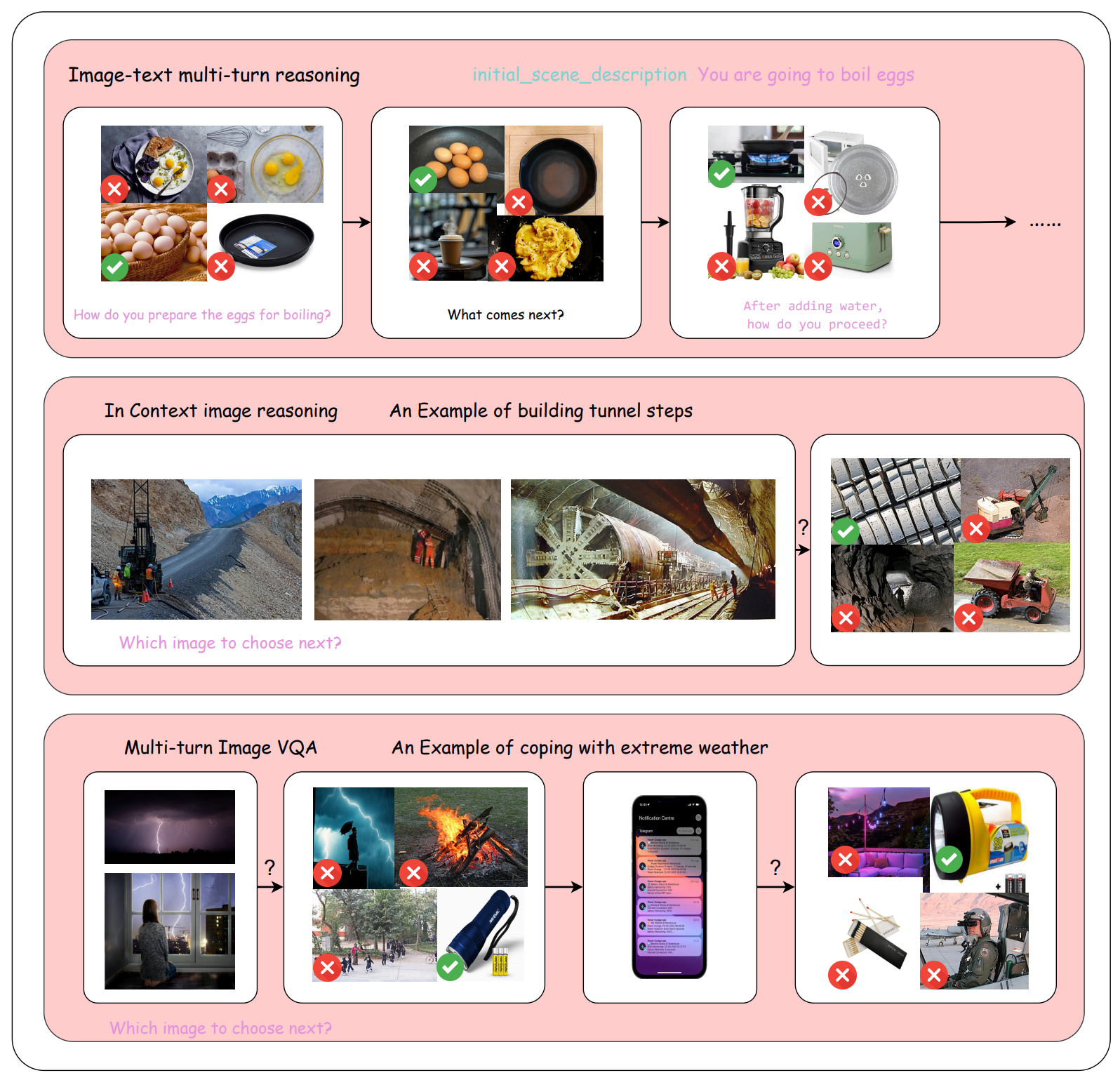
(1) Multi-turn, multi-image structure. Each task simulates
extended human-AI interactions, involving up to 6 dialogue
turns and 27 evolving images—capturing real-world com-
plexity such as procedural workflows and troubleshooting
steps. (2) Image-centric reasoning with distractors. Tasks are
designed to probe models’ ability to reason betwe