Title: DoVer: Intervention-Driven Auto Debugging for LLM Multi-Agent Systems
ArXiv ID: 2512.06749
Date: 2025-12-07
Authors: ** Ming Ma¹²*, Jue Zhang³†, Fangkai Yang³†, Yu Kang³, Qingwei Lin³, Saravan Rajmohan³, Dongmei Zhang³ ¹ Institute of Neuroscience, Chinese Academy of Sciences, Shanghai, China ² University of Chinese Academy of Sciences, School of Future Technology, Beijing, China ³ Microsoft (Beijing) **
📝 Abstract
Large language model (LLM)-based multi-agent systems are challenging to debug because failures often arise from long, branching interaction traces. The prevailing practice is to leverage LLMs for log-based failure localization, attributing errors to a specific agent and step. However, this paradigm has two key limitations: (i) log-only debugging lacks validation, producing untested hypotheses, and (ii) single-step or single-agent attribution is often ill-posed, as we find that multiple distinct interventions can independently repair the failed task. To address the first limitation, we introduce DoVer, an intervention-driven debugging framework, which augments hypothesis generation with active verification through targeted interventions (e.g., editing messages, altering plans). For the second limitation, rather than evaluating on attribution accuracy, we focus on measuring whether the system resolves the failure or makes quantifiable progress toward task success, reflecting a more outcome-oriented view of debugging. Within the Magnetic-One agent framework, on the datasets derived from GAIA and AssistantBench, DoVer flips 18-28% of failed trials into successes, achieves up to 16% milestone progress, and validates or refutes 30-60% of failure hypotheses. DoVer also performs effectively on a different dataset (GSMPlus) and agent framework (AG2), where it recovers 49% of failed trials. These results highlight intervention as a practical mechanism for improving reliability in agentic systems and open opportunities for more robust, scalable debugging methods for LLM-based multi-agent systems. Project website and code will be available at https://aka.ms/DoVer.
💡 Deep Analysis
📄 Full Content
Preprint
DOVER: INTERVENTION-DRIVEN AUTO DEBUGGING
FOR LLM MULTI-AGENT SYSTEMS
Ming Ma1,2∗, Jue Zhang3† , Fangkai Yang3†,
Yu Kang3, Qingwei Lin3, Saravan Rajmohan3, Dongmei Zhang3
1 Institute of Neuroscience,
State Key Laboratory of Brain Cognition and Brain-inspired Intelligence Technology,
Center for Excellence in Brain Science and Intelligence Technology,
Chinese Academy of Sciences, Shanghai, 200031, China
2 University of Chinese Academy of Sciences, School of Future Technology,
Beijing, 100049, China
3 Microsoft
mam2022@ion.ac.cn,
{juezhang, fangkaiyang}@microsoft.com
ABSTRACT
Large language model (LLM)–based multi-agent systems are challenging to de-
bug because failures often arise from long, branching interaction traces. The pre-
vailing practice is to leverage LLMs for log-based failure localization, attributing
errors to a specific agent and step. However, this paradigm has two key limitations:
(i) log-only debugging lacks validation, producing untested hypotheses, and (ii)
single-step or single-agent attribution is often ill-posed, as we find that multiple
distinct interventions can independently repair the failed task. To address the first
limitation, we introduce DoVer, an intervention-driven debugging framework,
which augments hypothesis generation with active verification through targeted
interventions (e.g., editing messages, altering plans). For the second limitation,
rather than evaluating on attribution accuracy, we focus on measuring whether the
system resolves the failure or makes quantifiable progress toward task success,
reflecting a more outcome-oriented view of debugging. Within the Magnetic-
One agent framework, on the datasets derived from GAIA and AssistantBench,
DoVer flips 18–28% of failed trials into successes, achieves up to 16% milestone
progress, and validates or refutes 30-60% of failure hypotheses. DoVer also per-
forms effectively on a different dataset (GSMPlus) and agent framework (AG2),
where it recovers 49% of failed trials. These results highlight intervention as a
practical mechanism for improving reliability in agentic systems and open oppor-
tunities for more robust, scalable debugging methods for LLM-based multi-agent
systems. Project website and code will be available at https://aka.ms/DoVer.
1
INTRODUCTION
The advancement of Large Language Models (LLMs) has led to the rapid rise of LLM-based agent
systems, particularly multi-agent architectures where agents of different roles work collaboratively
to solve complex tasks Li et al. (2023); Wu et al. (2023a); Hong et al. (2024). As these systems
are increasingly developed and deployed in production, the need to debug their failures becomes
inevitable during their lifecycle. Importantly, by “failures” we do not refer to conventional software
errors (e.g., exceptions or crashes), but rather to the errors where the system executes without in-
terruption yet produces incorrect or unsatisfactory results Mialon et al. (2024); Yoran et al. (2024).
Such failures frequently arise in scenarios where one diagnoses why an agent system underperforms
on benchmark tasks during the development phase, or when one addresses user-reported dissatisfac-
tion (e.g., a ‘thumbs-down’ signal with textual feedback) from an online deployed system.
∗Work is done during an internship at Microsoft.
† Corresponding authors.
1
arXiv:2512.06749v3 [cs.AI] 31 Jan 2026
Preprint
Debugging failures in LLM-based agent systems presents unique challenges. These systems typi-
cally involve multiple rounds of LLM calls, each with extensive textual context, making manual log
inspection labor-intensive. Furthermore, in multi-agent tasks, tracking inter-agent information flow
is crucial, as failures often stem from Inter-Agent Misalignment Cemri et al. (2025). Recent efforts
address these issues by using LLMs to analyze system failures Zhuge et al. (2024); Zhang et al.
(2025c;a), often via single-agent, single-step failure attribution. In this method, an execution log is
input to an LLM tasked with identifying the agent and step responsible for the failure Zhang et al.
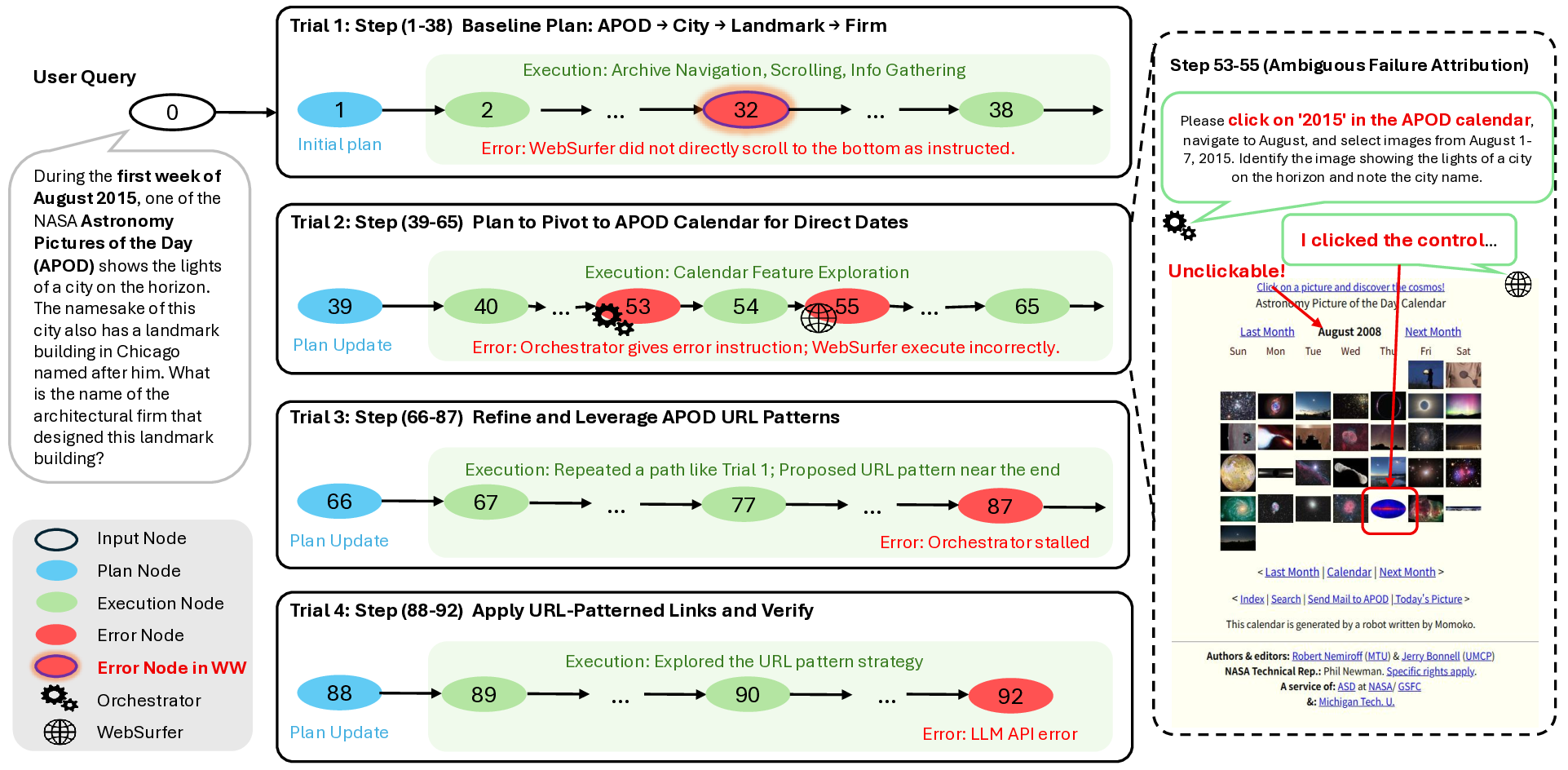
(2025c). However, as shown in our reproduction study (Section 3), log-based failure attribution is
fundamentally limited by the uncertainty of ground-truth annotations. This uncertainty arises for
several reasons: agent systems often employ multiple strategies (e.g., ReAct Yao et al. (2023)) with
distinct failure points in a single session, and inter-agent misalignment can render the assignment of
responsibility to a single agent or step ambiguous.
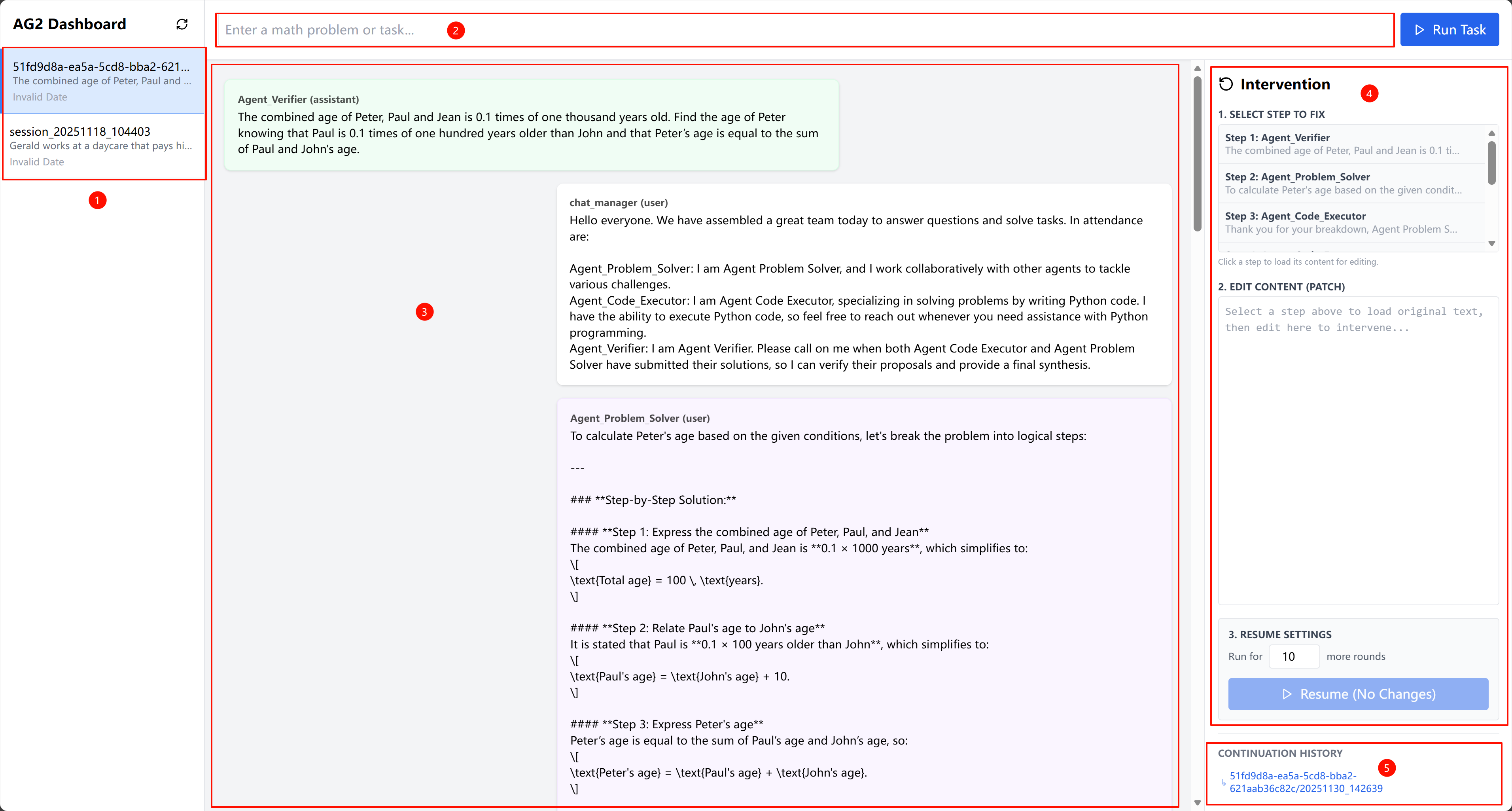
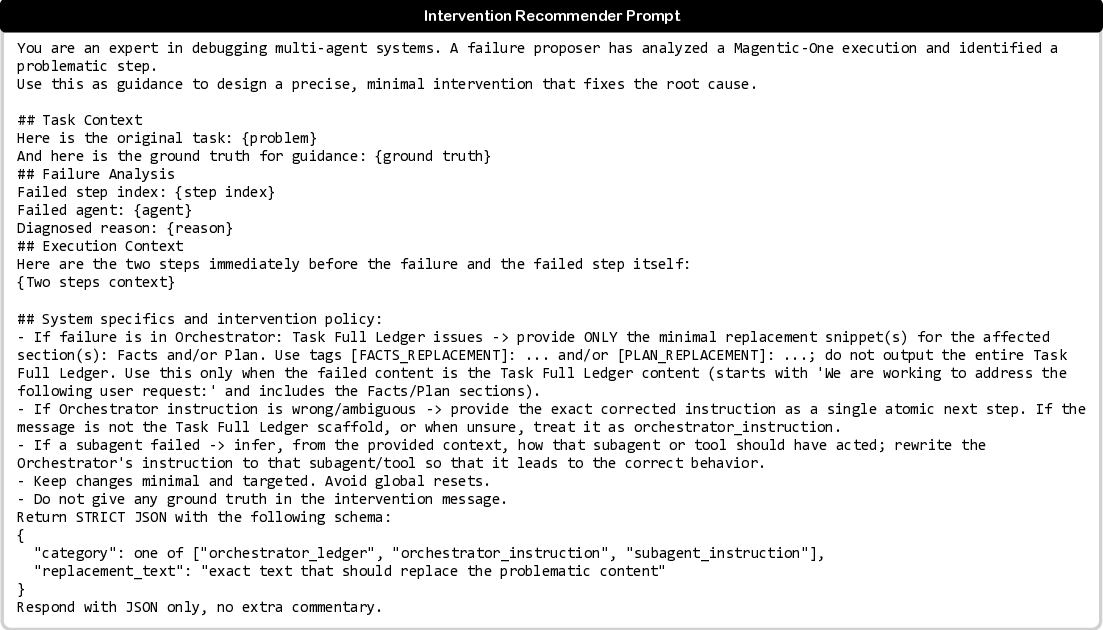
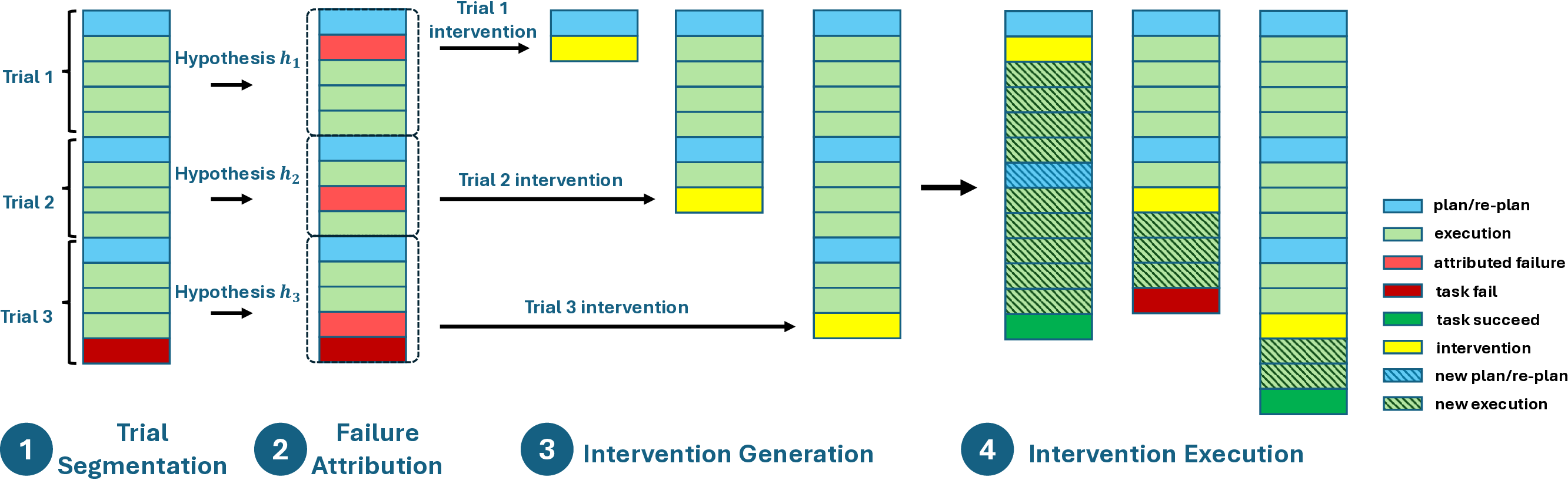
To circumvent the limitations of uncertain ground-truth attribution, we propose explicit validation
via intervention, introducing DoVer (Do-then-Verify), an intervention-driven framework for auto-
mated debugging. DoVer explicitly validates failure attribution hypotheses derived from session
logs by intervening at suspected failure points, modifying agent instructions or task plans, while
preserving prior context. The system is then re-executed fro