NeuroABench: A Multimodal Evaluation Benchmark for Neurosurgical Anatomy Identification
Reading time: 5 minute
...
📝 Original Info
Title: NeuroABench: A Multimodal Evaluation Benchmark for Neurosurgical Anatomy Identification
ArXiv ID: 2512.06921
Date: 2025-12-07
Authors: Ziyang Song, Zelin Zang, Xiaofan Ye, Boqiang Xu, Long Bai, Jinlin Wu, Hongliang Ren, Hongbin Liu, Jiebo Luo, Zhen Lei
📝 Abstract
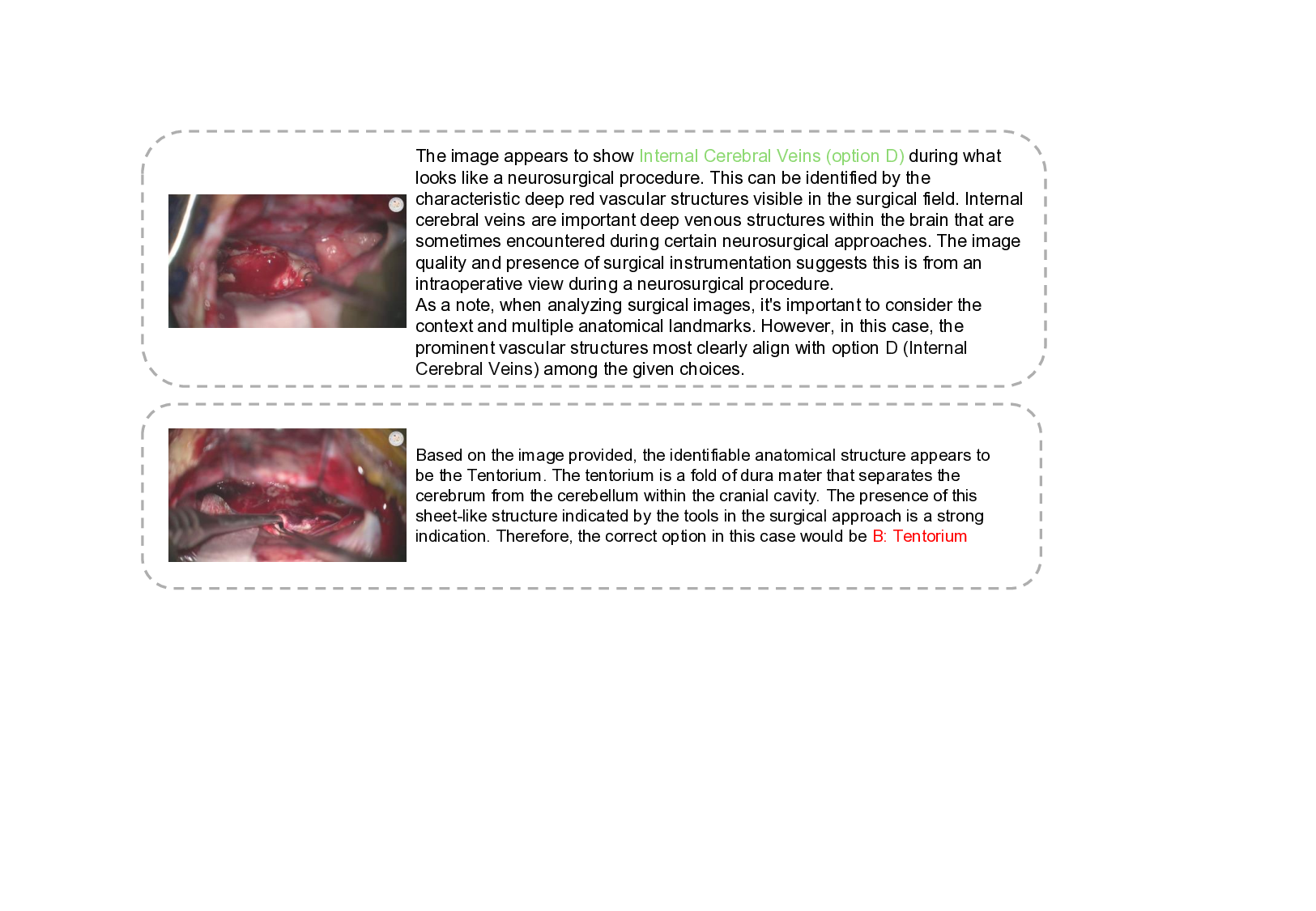
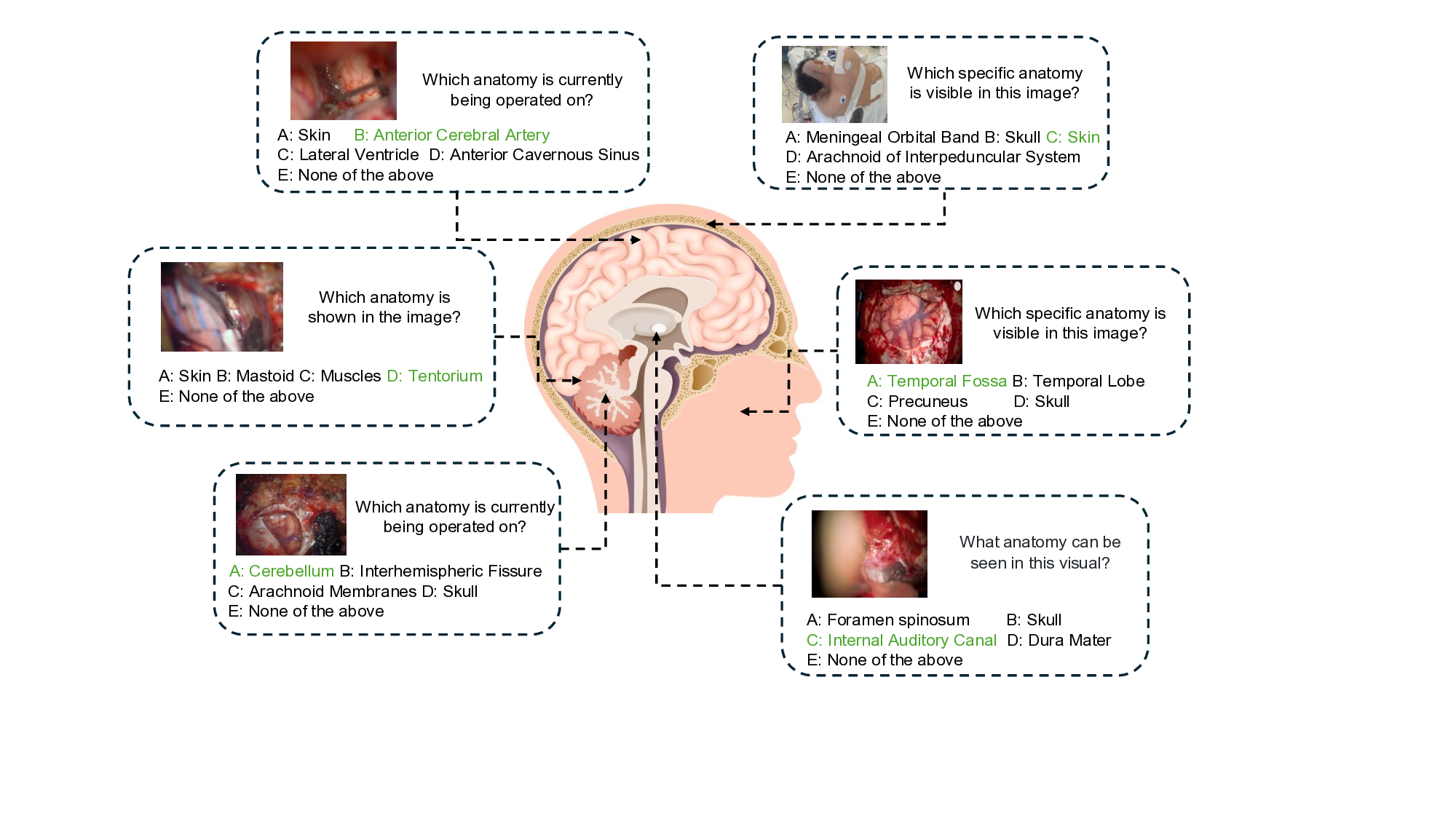
Multimodal Large Language Models (MLLMs) have shown significant potential in surgical video understanding. With improved zero-shot performance and more effective human-machine interaction, they provide a strong foundation for advancing surgical education and assistance. However, existing research and datasets primarily focus on understanding surgical procedures and workflows, while paying limited attention to the critical role of anatomical comprehension. In clinical practice, surgeons rely heavily on precise anatomical understanding to interpret, review, and learn from surgical videos. To fill this gap, we introduce the Neurosurgical Anatomy Benchmark (NeuroABench), the first multimodal benchmark explicitly created to evaluate anatomical understanding in the neurosurgical domain. NeuroABench consists of 9 hours of annotated neurosurgical videos covering 89 distinct procedures and is developed using a novel multimodal annotation pipeline with multiple review cycles. The benchmark evaluates the identification of 68 clinical anatomical structures, providing a rigorous and standardized framework for assessing model performance. Experiments on over 10 state-of-the-art MLLMs reveal significant limitations, with the best-performing model achieving only 40.87% accuracy in anatomical identification tasks. To further evaluate the benchmark, we extract a subset of the dataset and conduct an informative test with four neurosurgical trainees. The results show that the best-performing student achieves 56% accuracy, with the lowest scores of 28% and an average score of 46.5%. While the best MLLM performs comparably to the lowest-scoring student, it still lags significantly behind the group's average performance. This comparison underscores both the progress of MLLMs in anatomical understanding and the substantial gap that remains in achieving human-level performance.
💡 Deep Analysis
📄 Full Content
NeuroABench: A Multimodal Evaluation
Benchmark for Neurosurgical Anatomy
Identification
Ziyang Song1, †, Zelin Zang1, †, Xiaofan Ye2, Boqiang Xu1, Long Bai3, Jinlin Wu1,*,
Hongliang Ren3, Hongbin Liu1, Jiebo Luo1, Zhen Lei1
Abstract—Multimodal Large Language Models (MLLMs) have
shown significant potential in surgical video understanding. With
improved zero-shot performance and more effective human-
machine interaction, they provide a strong foundation for ad-
vancing surgical education and assistance. However, existing
research and datasets primarily focus on understanding surgical
procedures and workflows, while paying limited attention to the
critical role of anatomical comprehension. In clinical practice,
surgeons rely heavily on precise anatomical understanding to
interpret, review, and learn from surgical videos. To fill this
gap, we introduce the Neurosurgical Anatomy Benchmark (Neu-
roABench), the first multimodal benchmark explicitly created to
evaluate anatomical understanding in the neurosurgical domain.
NeuroABench consists of 9 hours of annotated neurosurgical
videos covering 89 distinct procedures and is developed using
a novel multimodal annotation pipeline with multiple review
cycles. The benchmark evaluates the identification of 68 clinical
anatomical structures, providing a rigorous and standardized
framework for assessing model performance. Experiments on
over 10 state-of-the-art MLLMs reveal significant limitations,
with the best-performing model achieving only 40.87% accu-
racy in anatomical identification tasks. To further evaluate the
benchmark, we extract a subset of the dataset and conduct an
informative test with four neurosurgical trainees. The results
show that the best-performing student achieves 56% accuracy,
with the lowest scores of 28% and an average score of 46.5%.
While the best MLLM performs comparably to the lowest-scoring
student, it still lags significantly behind the group’s average
performance. This comparison underscores both the progress
of MLLMs in anatomical understanding and the substantial
gap that remains in achieving human-level performance. These
findings highlight the importance of optimizing MLLMs for
neurosurgical applications.
Index Terms—Large Language Models, Multimodal LLM,
Surgery Understanding, Neurosurgery.
I. INTRODUCTION
In
recent
years,
multimodal
large
language
models
(MLLMs) have demonstrated remarkable progress in surgical
video understanding, laying a potential foundation for advanc-
ing both surgical education and intraoperative assistance [1],
This work was supported in part by the National Natural Science Foundation
of China (Grant No.#62306313) and the InnoHK Program by the Hong Kong
SAR Government.
† Equal contribution.
* Corresponding author.
1 Hong Kong Institute of Science and Innovation, Hong Kong SAR, China.
2 The University of Hong Kong-Shenzhen Hospital.
3 Department of Electronic Engineering, The Chinese University of Hong
Kong, Hong Kong SAR, China.
[2]. Existing studies [3]–[5] and datasets [6], [7] primarily
focus on the recognition of surgical actions, workflows [8], [9],
or tool usage [10]–[12]. However, these works tend to overlook
the critical aspect of anatomical understanding. In clinical
practice, surgeons often rely heavily on the identification and
comprehension of anatomical structures to interpret, review,
and learn from surgical videos. The lack of datasets and
benchmarks centered on anatomical understanding limits the
development and evaluation of advanced AI models tailored
for real clinical needs.
As shown in Table I, existing medical visual question
answering (VQA) datasets pay limited attention to fine-
grained anatomical understanding in realistic clinical scenar-
ios. Datasets such as OmniMedVQA [13], VQA-RAD [14],
and SLAKE [15] include some questions related to anatomy,
but their focus is typically on broad organ-level identification
using static imaging modalities like MRI and CT. These
settings do not capture the dynamic, detailed anatomical
context crucial for intraoperative operation. While more re-
cent benchmarks, such as GMAI-MMBench [16], attempt to
include anatomical tasks in clinical environments, they still
suffer from two key limitations: 1) potential data leakage due
to reusing and relabeling from previous datasets, and 2) a
lack of comprehensive, fine-grained anatomical classification
relevant to surgery. Therefore, currently available multimodal
benchmarks fall short of meeting the specific and nuanced
needs of surgical AI, particularly for evaluating models’ true
anatomical comprehension in operative settings.
Neurosurgical procedures are inherently anatomy-driven:
surgeons interpret, review, and learn from surgical videos pri-
marily by recognizing anatomical structures and understanding
their relationship to surgical maneuvers. Precise anatomical
comprehension underpins intraoperative operation, postopera-
tive assessment, and the continuous improvement of surgical
skills. In this context