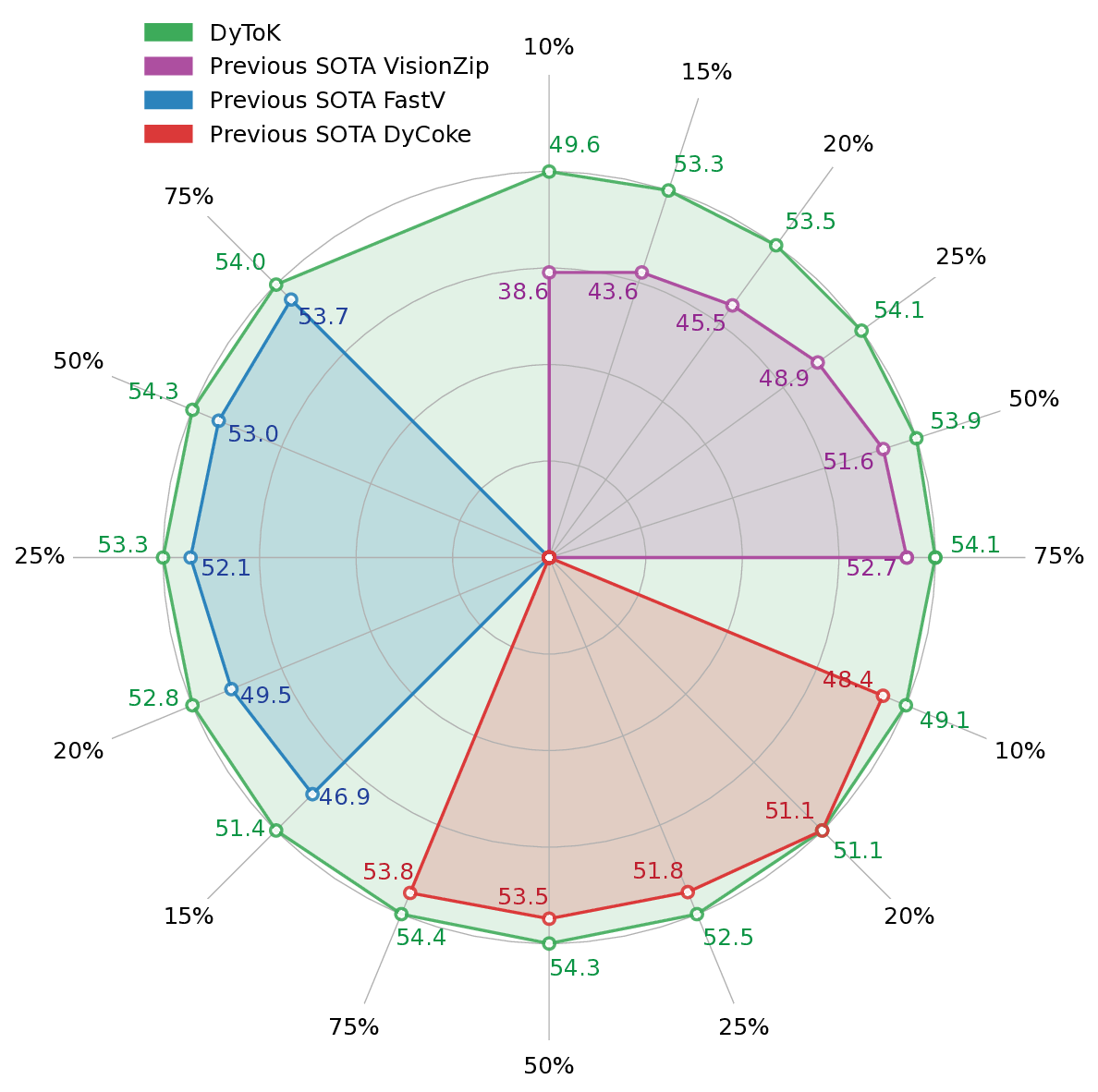
Recent advances in Video Large Language Models (VLLMs) have achieved remarkable video understanding capabilities, yet face critical efficiency bottlenecks due to quadratic computational growth with lengthy visual token sequences of long videos. While existing keyframe sampling methods can improve temporal modeling efficiency, additional computational cost is introduced before feature encoding, and the binary frame selection paradigm is found suboptimal. Therefore, in this work, we propose Dynamic Token compression via LLM-guided Keyframe prior (DyToK), a training-free paradigm that enables dynamic token compression by harnessing VLLMs' inherent attention mechanisms. Our analysis reveals that VLLM attention layers naturally encoding query-conditioned keyframe priors, by which DyToK dynamically adjusts per-frame token retention ratios, prioritizing semantically rich frames while suppressing redundancies. Extensive experiments demonstrate that DyToK achieves state-of-the-art efficiency-accuracy tradeoffs. DyToK shows plug-and-play compatibility with existing compression methods, such as VisionZip and FastV, attaining 4.3x faster inference while preserving accuracy across multiple VLLMs, such as LLaVA-OneVision and Qwen2.5-VL. Code is available at https://github.com/yu-lin-li/DyToK .
Recent advancements in Video Large Language Models (VLLMs) [1,2,3,4] have demonstrated remarkable capabilities in processing complex video content. However, their practical deployment faces critical challenges when handling long videos [5,6,7], including excessive computational overhead, slow inference speeds, and performance degradation caused by redundant visual information.
Existing solutions primarily focus on token compression through saliency metrics derived from either LLM attention patterns [8,9,10] or visual encoder features [11,12,13]. While LLM attention-based methods selectively retain prompt-relevant tokens, their effectiveness heavily relies on layer-specific attention maps, introducing instability as shallow layers yield noisy signals while deeper layers negate computational benefits [14,15]. Conversely, encoder feature-based approaches exploit intra-frame token sparsity through CLS token attention [16] or inter-patch correlations [17] but uniformly apply fixed compression ratios across frames, ignoring temporal dynamics critical for video understanding.
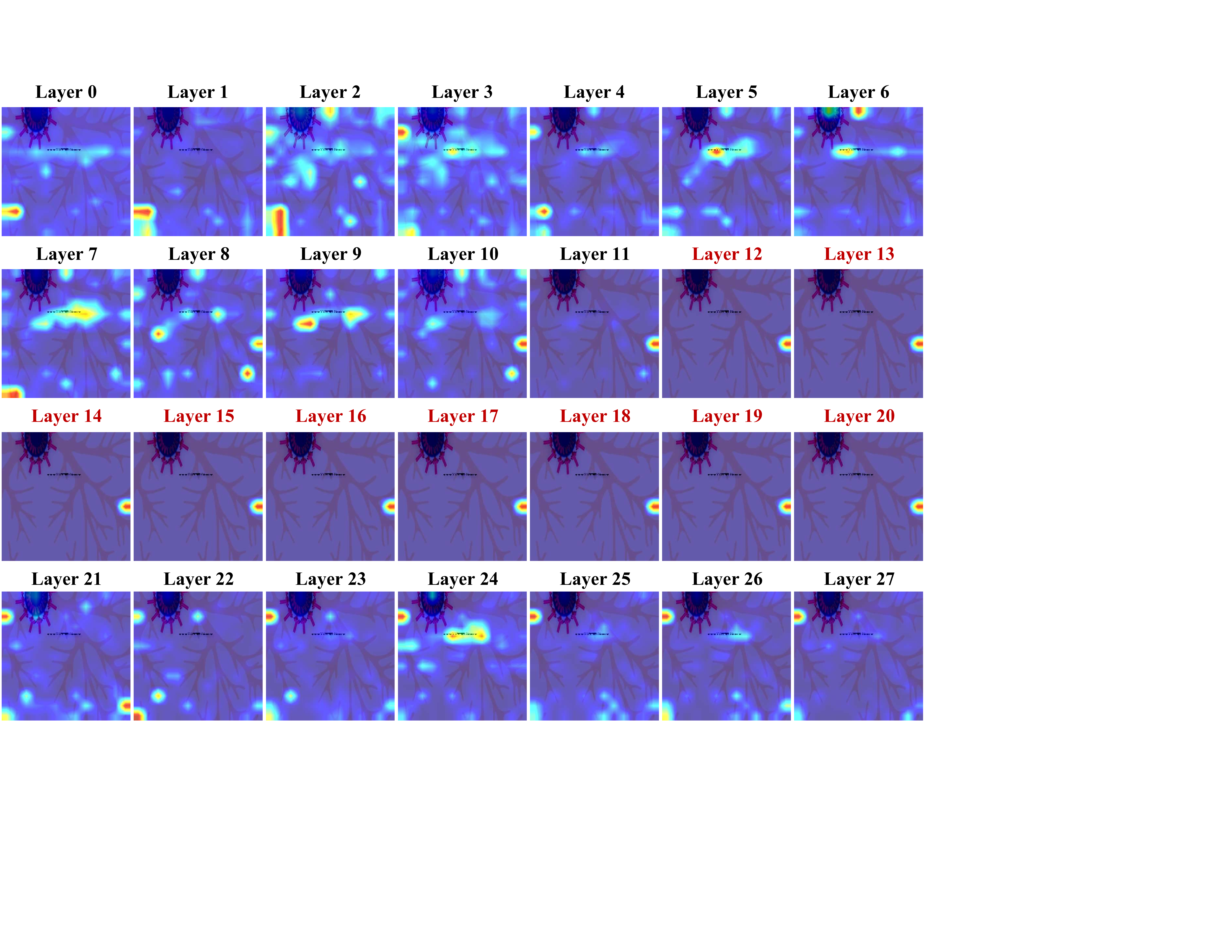
Motivation. Unlike token compression for images, which applies a single ratio, video frames contain varying spatiotemporal information-some are critical for answering user queries, while Figure 1: Unveiling the keyframe prior in VLLMs. LLaVA-OneVision’s answers to video QA tasks are shown on the left. On the right, we plot the averaged attention from the final text token to visual tokens across all layers and within each frame. The top-8 frames by attention scores are arranged in time order, and the Ground Truth (GT) keyframes are highlighted in red. We observe that even when the model answers incorrectly, its attention still pinpoints the relevant frames, revealing a strong task-dependent keyframe prior. others may hold less relevance. This inherent variation suggests that the shared compression ratios may be inappropriate for processing video frames. Consequently, a key question emerges: How can we dynamically retain task-relevant information while filtering out the irrelevant components?
In the following, we provide a concise overview of foundational concepts that underlie this study in Sec. 2.1, and highlight the key observations in Sec. 2.2, which offer valuable insights for motivating the proposed approach.
Architecture of VLLMs. Modern VLLMs [1,3,4] are typically composed of three core components: a vision encoder, a modality projector, and an LLM backbone. The vision encoder, often pre-trained on large-scale image datasets (e.g., CLIP [16], SigLip [17]), processes each video frame into a sequence of visual tokens, with some variants incorporating video-specific pretraining [20,21] for temporal modeling. The projector aligns these tokens with the LLM’s textual embedding space, enabling cross-modal fusion. Finally, the LLM integrates the aligned visual and textual tokens to generate contextually relevant responses.
Computational bottleneck analysis. Though VLLMs have shown promising performance, the computational overhead impedes their practical applications. Specifically, the computational complexity of VLLMs is dominated by the self-attention mechanism and Feed-Forward Networks (FFNs) in transformer layers. For a model with T transformer layers, the total Floating Point Operations (FLOPs) can be formulated as:
where n denotes the input sequence length, d is the hidden dimension, and m represents the FFN’s intermediate size. In video tasks, n is dominated by visual tokens n vis , which often exceed textual tokens n sys + n question by orders of magnitude through frame accumulation [12,22]. Reducing n vis is thus crucial for improving inference efficiency.
Efficient inference paradigms for VLLMs. Recent advancements in efficient inference for VLLMs can be categorized into two paradigms: LLM attention-based token pruning [10,13] and encoder feature-based token selection [23,24]. The former (Fig. 2(a)) dynamically eliminates redundant visual tokens during LLM inference by leveraging cross-modal attention patterns from intermediate layers, yet suffers from unstable pruning decisions due to shallow-layer attention noise. The latter (Fig. 2(b)) statically selects tokens at the encoder output using feature correlations, but disregards temporal dependencies critical for video comprehension.
Notably, existing keyframe selection techniques [19,18] primarily address issues arising from uniform input sampling in long videos, rather than optimizing for computational acceleration. Moreover, their binary frame selection approach risks discarding useful tokens of the discarded frames, potentially harming overall performance. Differently, in this study, we leverage a novel keyframe-aware compression strategy (Fig. 2(c)) that actively reduces inference latency for different frames, by which more tokens will be retained in the semantically important frames and fewer will be kept in those less relevant, thereby enhancing efficiency without comprom
This content is AI-processed based on open access ArXiv data.