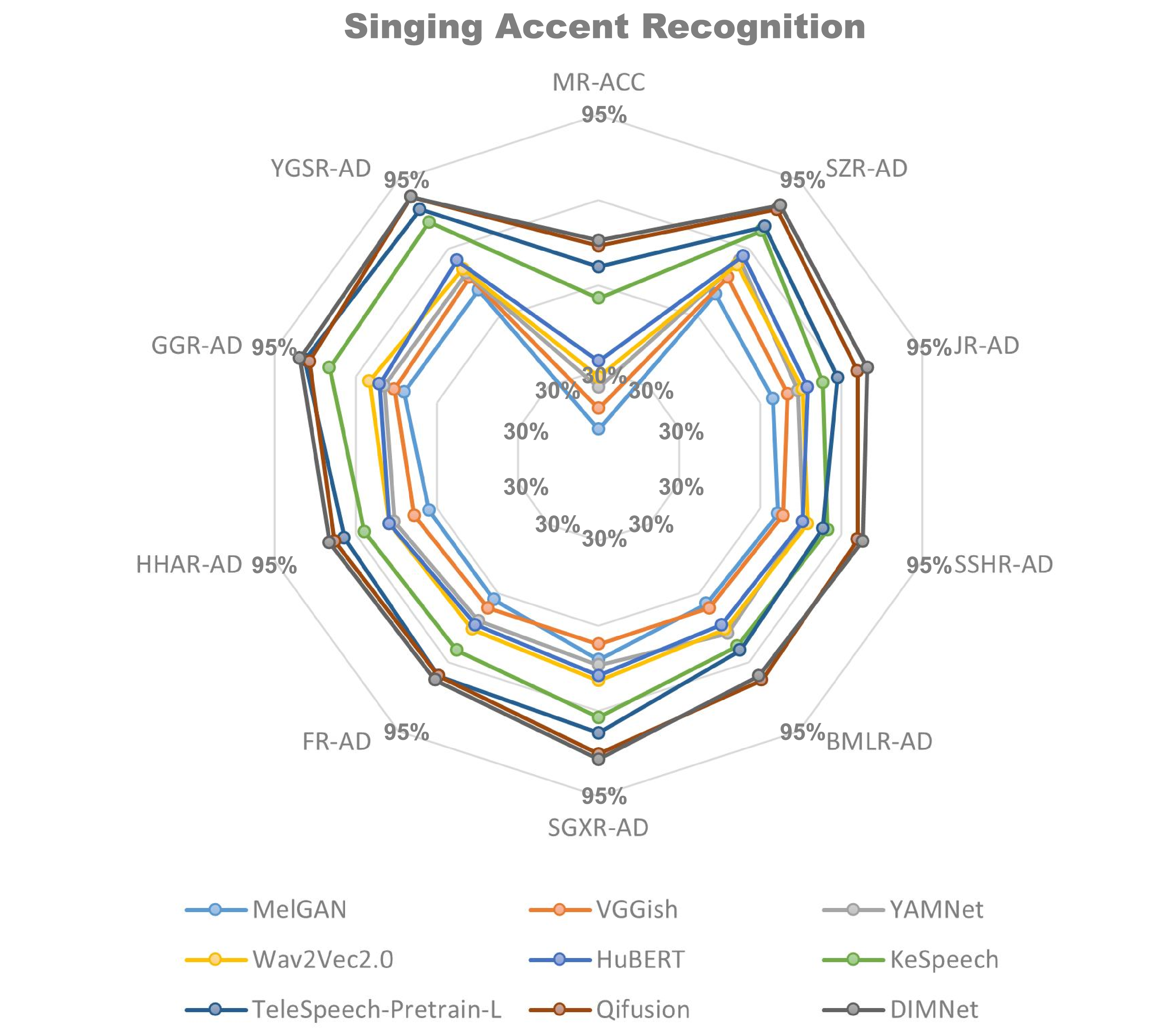
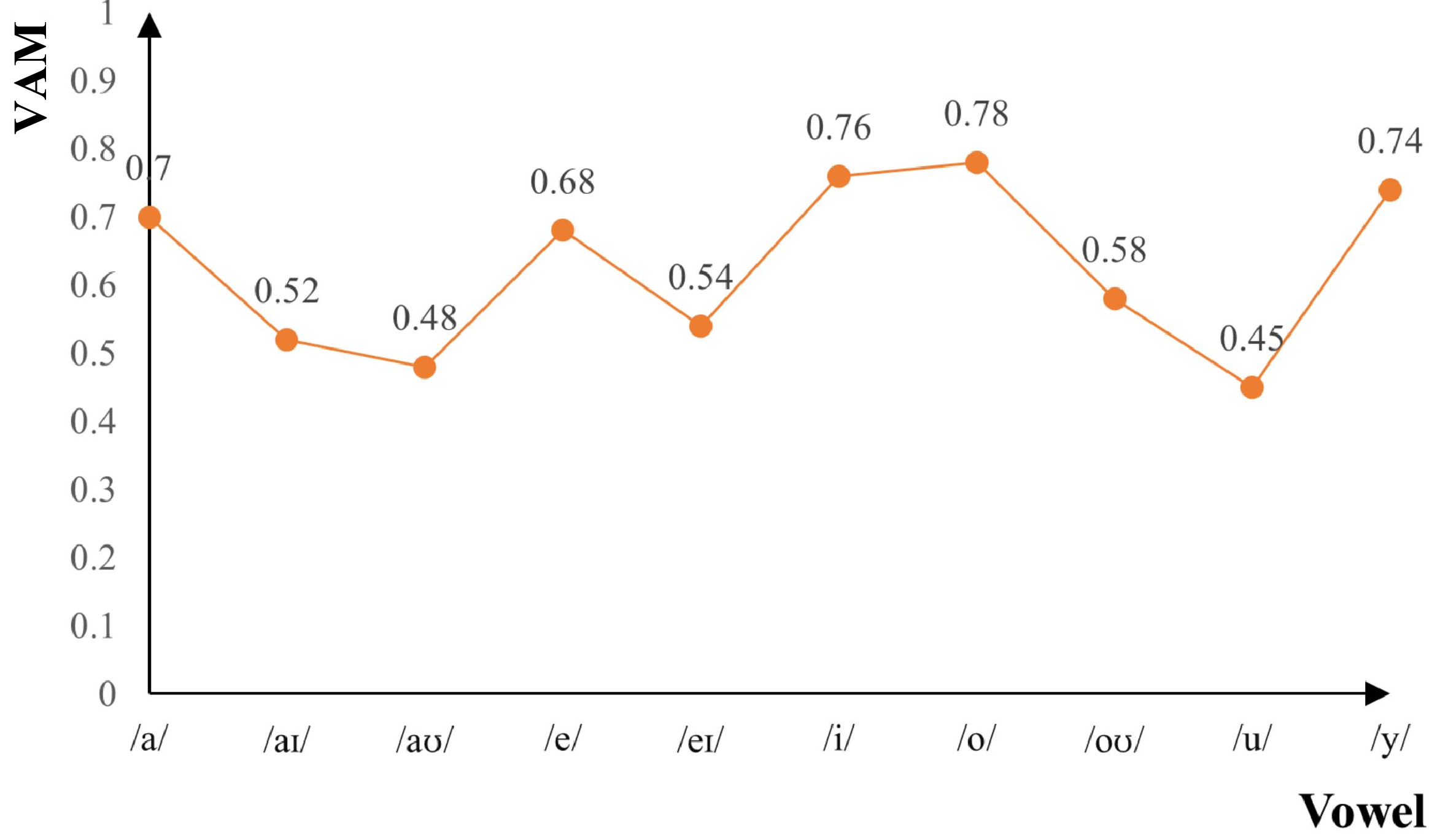
📝 Original Info 📝 Abstract Singing accent research is underexplored compared to speech accent studies, primarily due to the scarcity of suitable datasets. Existing singing datasets often suffer from detail loss, frequently resulting from the vocal-instrumental separation process. Additionally, they often lack regional accent annotations. To address this, we introduce the Multi-Accent Mandarin Dry-Vocal Singing Dataset (MADVSD). MADVSD comprises over 670 hours of dry vocal recordings from 4,206 native Mandarin speakers across nine distinct Chinese regions. In addition to each participant recording audio of three popular songs in their native accent, they also recorded phonetic exercises covering all Mandarin vowels and a full octave range. We validated MADVSD through benchmark experiments in singing accent recognition, demonstrating its utility for evaluating state-of-the-art speech models in singing contexts. Furthermore, we explored dialectal influences on singing accent and analyzed the role of vowels in accentual variations, leveraging MADVSD's unique phonetic exercises.
💡 Deep Analysis
📄 Full Content Multi-Accent Mandarin Dry-Vocal Singing Dataset: Benchmark
for Singing Accent Recognition
Zihao Wang
Zhejiang University
Hangzhou, China
Carnegie Mellon University
Pittsburgh, United States
carlwang@zju.edu.cn
Shulei Ji
Zhejiang University
Hangzhou, China
Innovation Center of Yangtze River
Delta, Zhejiang University
Hangzhou, China
shuleiji@zju.edu.cn
Le Ma
Zhejiang University
Hangzhou, China
maller@zju.edu.cn
Yuhang Jin
Zhejiang University
Hangzhou, China
3210103422@zju.edu.cn
Shun Lei
Tsinghua University
Shenzhen, China
leis21@mails.tsinghua.edu.cn
Jianyi Chen
Hong Kong University of Science and
Technology
Hongkong, China
jchenil@connect.ust.hk
Haoying Fu
Mei KTV
Beijing, China
326452438@qq.com
Roger B. Dannenberg
Carnegie Mellon University
Pittsburgh, United States
rbd@cs.cmu.edu
Kejun Zhang∗
Zhejiang University
Hangzhou, China
Innovation Center of Yangtze River
Delta, Zhejiang University
Hangzhou, China
zhangkejun@zju.edu.cn
Abstract
Singing accent research is underexplored compared to speech ac-
cent studies, primarily due to the scarcity of suitable datasets. Ex-
isting singing datasets often suffer from detail loss, frequently
resulting from the vocal-instrumental separation process. Addi-
tionally, they often lack regional accent annotations. To address
this, we introduce the Multi-Accent Mandarin Dry-Vocal Singing
Dataset (MADVSD). MADVSD comprises over 670 hours of dry
vocal recordings from 4,206 native Mandarin speakers across nine
distinct Chinese regions. In addition to each participant record-
ing audio of three popular songs in their native accent, they also
recorded phonetic exercises covering all Mandarin vowels and a
full octave range. We validated MADVSD through benchmark ex-
periments in singing accent recognition, demonstrating its utility
for evaluating state-of-the-art speech models in singing contexts.
Furthermore, we explored dialectal influences on singing accent
and analyzed the role of vowels in accentual variations, leveraging
MADVSD’s unique phonetic exercises.
∗Corresponding author
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
MM ’25, Dublin, Ireland
© 2025 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-2035-2/2025/10
https://doi.org/10.1145/3746027.3758210
CCS Concepts
• Applied computing →Sound and music computing; • Com-
puting methodologies →Speech recognition; • Information
systems →Multimedia databases.
Keywords
Mandarin Singing Dataset; Singing Accent Recognition; Dry Vocals;
Regional Chinese Accents
ACM Reference Format:
Zihao Wang, Shulei Ji, Le Ma, Yuhang Jin, Shun Lei, Jianyi Chen, Haoying
Fu, Roger B. Dannenberg, and Kejun Zhang. 2025. Multi-Accent Mandarin
Dry-Vocal Singing Dataset: Benchmark for Singing Accent Recognition. In
Proceedings of the 33rd ACM International Conference on Multimedia (MM
’25), October 27–31, 2025, Dublin, Ireland. ACM, New York, NY, USA, 8 pages.
https://doi.org/10.1145/3746027.3758210
1
Introduction
In recent years, speech and music models have developed rapidly [8,
10, 25, 34, 36, 38, 42]. However, in the field of accent research, the
singing domain significantly lags behind the speech domain. This
is primarily due to the lack of high-quality accent datasets in the
singing field [17]. Existing large-scale singing datasets are mostly
wet vocal tracks extracted from songs [4]. Audio effects processing
(such as reverb, echo, equalization, etc.) inevitably sacrifices original
sound details. Furthermore, existing dry vocal singing datasets [16,
45] generally lack regional accent labels.
To bridge this data gap and facilitate focused research on singing
accent, we introduce the Multi-Accent Mandarin Dry Singing Vocal
arXiv:2512.07005v1 [cs.SD] 7 Dec 2025
MM ’25, October 27–31, 2025, Dublin, Ireland
Zihao Wang et al.
Dataset (MADVSD)1. MADVSD is a relatively large-scale, metic-
ulously curated dataset comprising over 670 hours of dry vocal
recordings from 4,206 native Mandarin speakers across diverse
geographical regions of China. Collaborating with a nationwide
organization, their employees across various provinces and cities
were coordinated to record dry vocals at home using their mobile
phones. These participants were recorded performing popular Man-
darin songs and specifically designed phonetic exercises. These
exercises encompass all Mandarin vowels and a full octave range
of scales, providing granular phonetic and acoustic data for accent
analysis. The data
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.