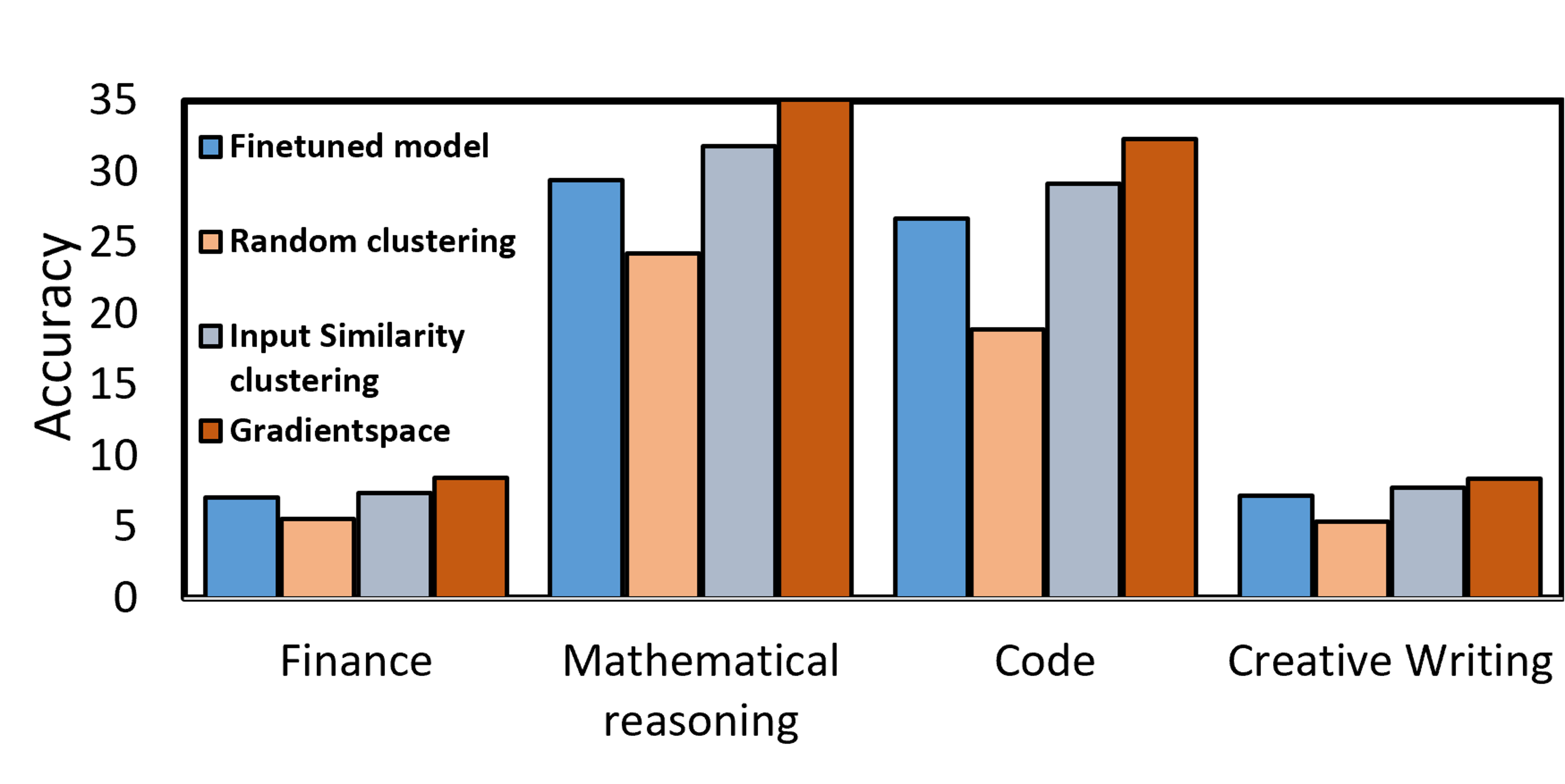
Instruction tuning is one of the key steps required for adapting large language models (LLMs) to a broad spectrum of downstream applications. However, this procedure is difficult because real-world datasets are rarely homogeneous; they consist of a mixture of diverse information, causing gradient interference, where conflicting gradients pull the model in opposing directions, degrading performance. A common strategy to mitigate this issue is to group data based on semantic or embedding similarity. However, this fails to capture how data influences model parameters during learning. While recent works have attempted to cluster gradients directly, they randomly project gradients into lower dimensions to manage memory, which leads to accuracy loss. Moreover, these methods rely on expert ensembles which necessitates multiple inference passes and expensive on-the-fly gradient computations during inference. To address these limitations, we propose GradientSpace, a framework that clusters samples directly in full-dimensional gradient space. We introduce an online SVD-based algorithm that operates on LoRA gradients to identify latent skills without the infeasible cost of storing all sample gradients. Each cluster is used to train a specialized LoRA expert along with a lightweight router trained to select the best expert during inference. We show that routing to a single, appropriate expert outperforms expert ensembles used in prior work, while significantly reducing inference latency. Our experiments across mathematical reasoning, code generation, finance, and creative writing tasks demonstrate that GradientSpace leads to coherent expert specialization and consistent accuracy gains over state-of-the-art clustering methods and finetuning techniques.
Large language models (LLMs) like GPT (OpenAI et al., 2024), Llama (Grattafiori et al., 2024), and DeepSeek (DeepSeek-AI et al., 2025) have become integral components in modern AI systems such as conversational agents and chatbots due to their ability to generate coherent text that closely mirrors natural human communication. One of the key reasons for this success is instruction tuning, a procedure where pretrained models are finetuned on datasets that consist of human-written instructions paired with responses (Zhang et al., 2025c;Han et al., 2025).
Although instruction tuning has shown good efficacy, the datasets are usually curated from a single source or belong to a specific domain, which limits their ability to generalize across diverse real-world data distributions (Ghosh et al., 2024;Han et al., 2025). For example, when building an internal knowledge assistant within an organization, the underlying training data may include a mixture of documents, emails, support tickets, and wiki pages. Re-cent works (Bukharin et al., 2024;Chen et al., 2024;Wu et al., 2024a) have demonstrated that when instructions are mixed naively from different datasets, the performance of the model degrades. This is primarily due to a phenomenon called gradient interference (Yu et al., 2020;Shi et al., 2023), where examples corresponding to distinct tasks or domains push model parameters in conflicting directions. Learning from diverse sources is challenging because the model must reconcile competing learning signals, leading to negative transfer and reduced overall performance.
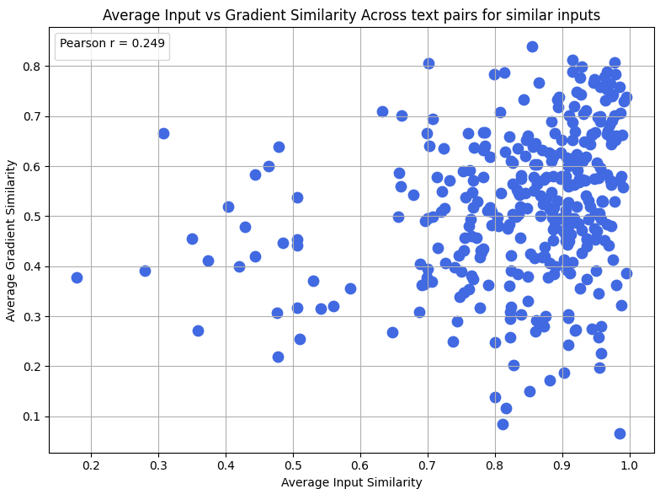
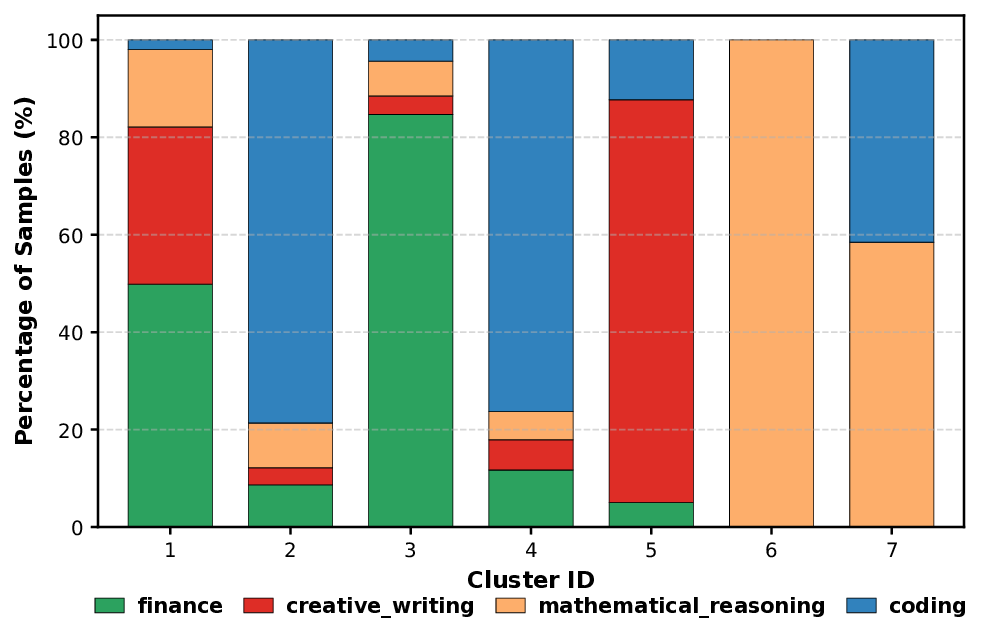
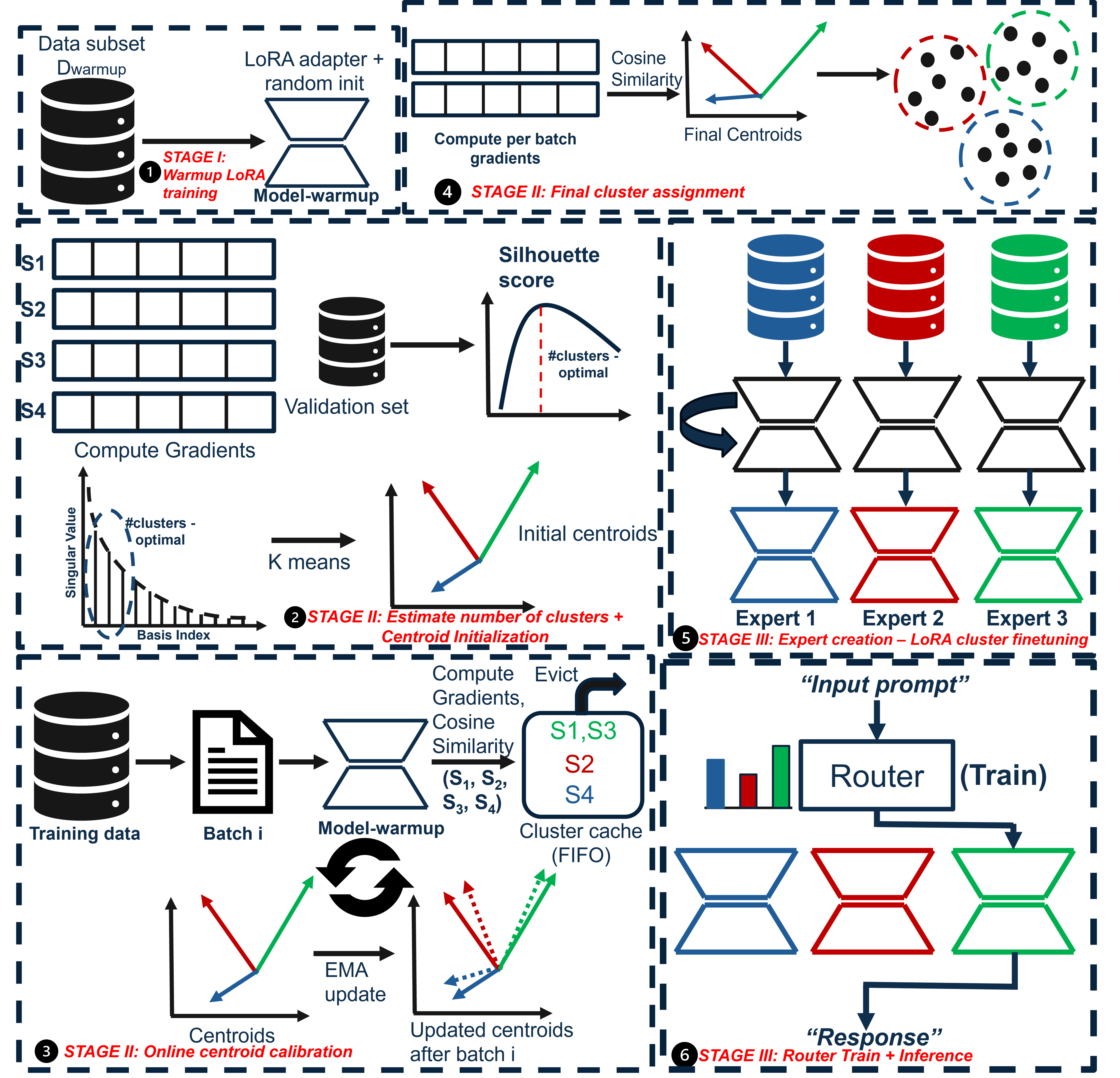
To address this challenge, previous efforts have explored strategies to mitigate gradient interference. One such approach groups training examples by semantic similarity, assuming that semantically related inputs would influence compatible parameter updates (Rao et al., 2024;Ge et al., 2024). However, input similarity is not a reliable proxy for how the model learns these inputs. Two semantically similar inputs may produce opposing gradients, while unrelated examples can reinforce each other if their updates are aligned. As shown in Figure 4, gradient and semantic similarities show little correlation, highlighting the need for organizing data based on learning dynamics. A different line of research, known as gradient surgery, modifies gradients during training to remove conflicts. Methods such as (Yu et al., 2020) and (Liu et al., 2024) project gradients from different tasks onto non-conflicting subspaces to reduce interference. However, these approaches rely on explicit task labels to project gradients, which limits their applicability to real-world instruction tuning. This motivates a fundamental question: “How should finetuning data be partitioned effectively when task boundaries are unknown?” To address this, we introduce GRA-DIENTSPACE, a framework that clusters data based on gradient similarity and groups samples that produce positively correlated parameter updates. GRADIENTSPACE naturally identifies latent “skills” within unlabeled data by clustering examples that produce positively aligned gradient updates. Theoretically, this is equivalent to the covariance term in the gradient variance decomposition, showing that grouping examples with high positive covariance reduces gradient interference and improves Stochastic Gradient Descent (SGD) convergence (more details in Section 4). Recent work from (Li et al., 2025) takes a similar approach, building ensembles with LoRA adaptors on gradient-clustered data. However, such an approach requires computing and storing gradients for every input sample, which is infeasible; consequently, they down-project the gradients into a lower dimension, losing performance. This is a general issue for calculating sample influence, such as in LESS (Xia et al., 2024).
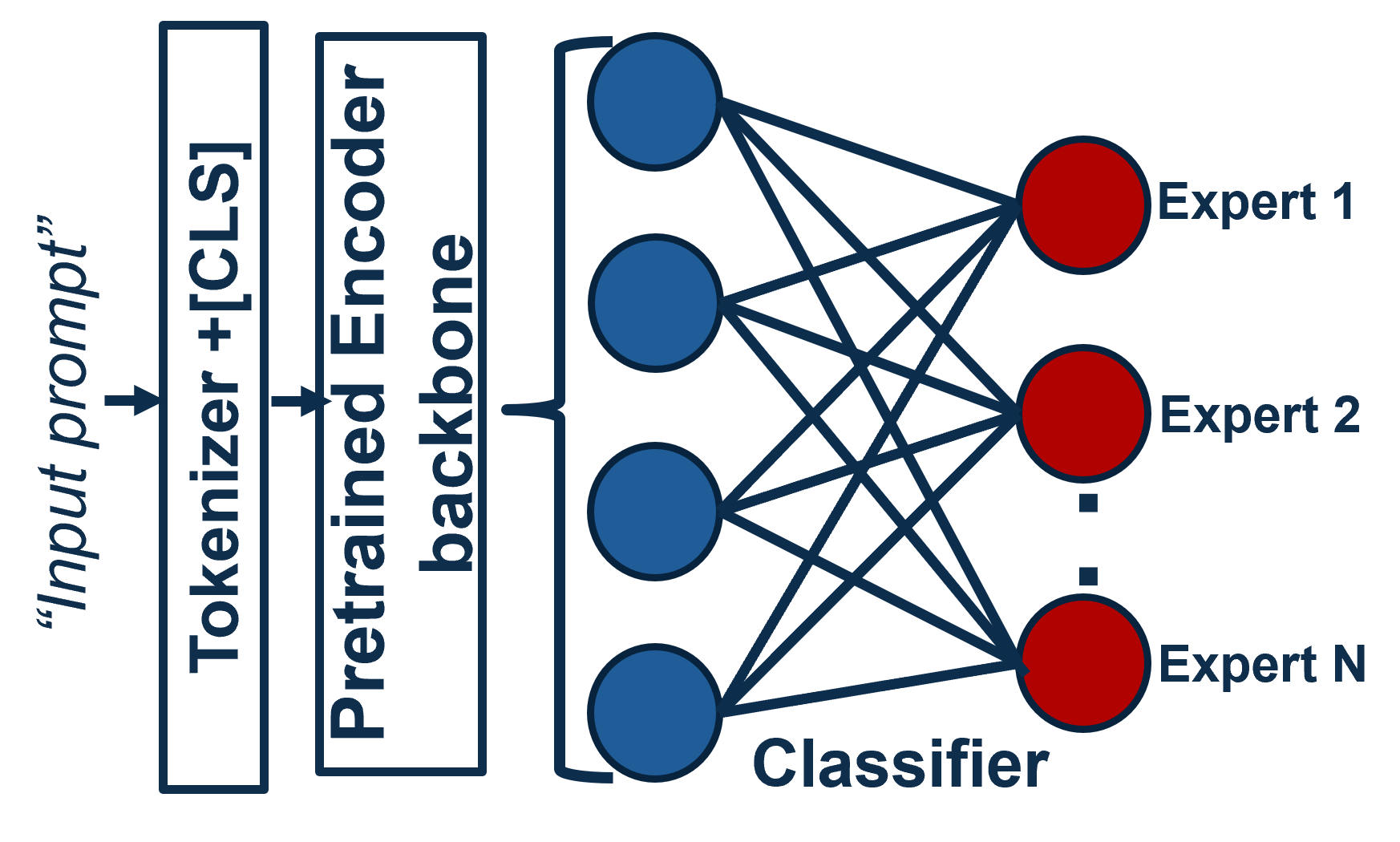
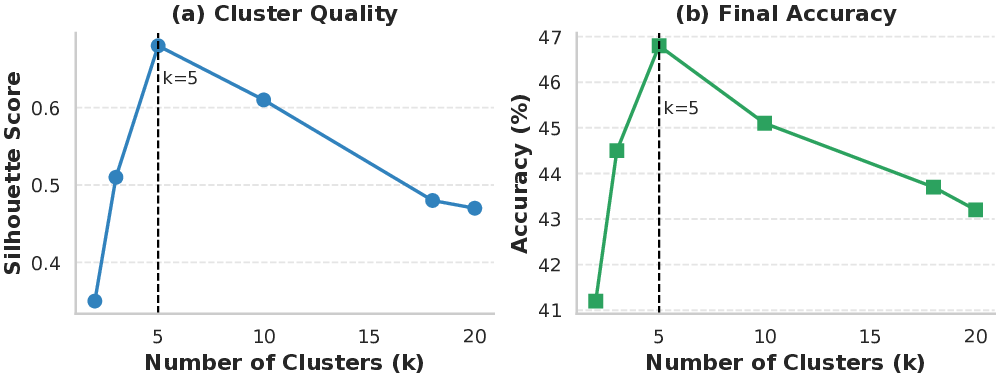
To address this, we develop a novel online learning methodology which handles LoRA gradients in full dimensionality, thus making full use of the gradient signals. This is performed by first training a LoRA adapter (Hu et al., 2022) on a warm-up dataset to obtain meaningful gradient representations and adapt the model to the input data distribution. Next, online singular value decomposition (SVD)-based clustering is performed, where SVD over the gradient matrix is employed to estimate the number of latent clusters and initialize their centroids based on the dominant gradient directions. This ensures that clustering begins in a subspace capturing the most significant gradient variance. Centroids are then refined using an exponential moving average (EMA) update. Next, each discovered cluster is finetuned into a specialized LoRA expert.
While identifying clusters and training a LoRA expert for each is essential, a fast inference method is also needed. Techniques such as (Li et al., 2025) employ gradient similarity during inference to identify the right set of experts; this can be very expensive, unrealistic for production deployment, and result in suboptima
This content is AI-processed based on open access ArXiv data.