CAuSE: Decoding Multimodal Classifiers using Faithful Natural Language Explanation
Reading time: 5 minute
...
📝 Original Info
Title: CAuSE: Decoding Multimodal Classifiers using Faithful Natural Language Explanation
ArXiv ID: 2512.06814
Date: 2025-12-07
Authors: ** - Dibyanayan Bandyopadhyay¹ - Soham Bhattacharjee¹ - Mohammed Hasanuzzaman² - Asif Ekbal¹ ¹ Indian Institute of Technology Patna, India ² Queen’s University Belfast, United Kingdom **
📝 Abstract
Multimodal classifiers function as opaque black box models. While several techniques exist to interpret their predictions, very few of them are as intuitive and accessible as natural language explanations (NLEs). To build trust, such explanations must faithfully capture the classifier's internal decision making behavior, a property known as faithfulness. In this paper, we propose CAuSE (Causal Abstraction under Simulated Explanations), a novel framework to generate faithful NLEs for any pretrained multimodal classifier. We demonstrate that CAuSE generalizes across datasets and models through extensive empirical evaluations. Theoretically, we show that CAuSE, trained via interchange intervention, forms a causal abstraction of the underlying classifier. We further validate this through a redesigned metric for measuring causal faithfulness in multimodal settings. CAuSE surpasses other methods on this metric, with qualitative analysis reinforcing its advantages. We perform detailed error analysis to pinpoint the failure cases of CAuSE. For replicability, we make the codes available at https://github.com/newcodevelop/CAuSE
💡 Deep Analysis
📄 Full Content
CAuSE: Decoding Multimodal Classifiers using Faithful Natural
Language Explanation
Dibyanayan Bandyopadhyay1
Soham Bhattacharjee1
Mohammed Hasanuzzaman2
Asif Ekbal1
1Indian Institute of Technology Patna
2Queen’s University Belfast
1{dibyanayan, sohambhattacharjeenghss, asif.ekbal}@gmail.com
2m.hasanuzzaman@qub.ac.uk
Abstract
Multimodal classifiers function as opaque
black box models.
While several tech-
niques exist to interpret their predictions,
very few of them are as intuitive and ac-
cessible as natural language explanations
(NLEs). To build trust, such explanations
must faithfully capture the classifier’s in-
ternal decision making behavior, a prop-
erty known as faithfulness.
In this pa-
per, we propose CAuSE (Causal Abstrac-
tion under Simulated Explanations), a novel
framework to generate faithful NLEs for
any pretrained multimodal classifier.
We
demonstrate that CAuSE generalizes across
datasets and models through extensive em-
pirical evaluations. Theoretically, we show
that CAuSE, trained via interchange inter-
vention, forms a causal abstraction of the
underlying classifier.
We further validate
this through a redesigned metric for mea-
suring causal faithfulness in multimodal set-
tings. CAuSE surpasses other methods on
this metric, with qualitative analysis rein-
forcing its advantages. We perform detailed
error analysis to pinpoint the failure cases
of CAuSE. For replicability, we make the
codes available at https://github.
com/newcodevelop/CAuSE.
1
Introduction
Multimodal classifiers (e.g. VisualBERT (Li et al.,
2019)) integrate information from multiple modal-
ities, such as images, text, and audio, and clas-
sify input into a predefined set of classes. These
models are vital in a range of applications. For
instance, given radiology reports in free-text for-
mat and corresponding chest X-ray images, a mul-
timodal classifier can be trained to predict whether
a patient has COVID-19 (Baltrušaitis et al., 2019).
However, their widespread adoption depends on
whether we can trust their predictions. This re-
quires the development of interpretability tech-
niques that explain how the classifier came to
its prediction. Input attribution methods aim to
identify features or concepts in the input that in-
fluence the classifier’s decision. Although these
techniques provide useful insights, they face two
significant limitations: (i) Lack of natural lan-
guage explanations (NLEs). Their outputs are typ-
ically low-level and not conveyed in natural lan-
guage, which hampers interpretability (Sundarara-
jan et al., 2017); and (ii) Causal faithfulness. They
often do not capture a true causal link between the
input and the prediction of the model (Bandyopad-
hyay et al., 2024b; Chattopadhyay et al., 2019).
Crucially, faithfulness is essential to trust the pre-
dictions of a model.
To address these limitations,
we propose
CAuSE (Causal Abstraction under Simulated
Explanations), a novel post-hoc framework for
generating causally faithful NLEs for any frozen
multimodal classifier.
CAuSE specifically tar-
gets discriminative classifiers with an encoder-
classification head architecture, which are found
to have been deployed in today’s production sys-
tems (Megahed et al., 2025; Ji et al., 2025). Un-
like generative models, these discriminative clas-
sifiers lack native explanation generation capabili-
ties, necessitating post-hoc interpretability frame-
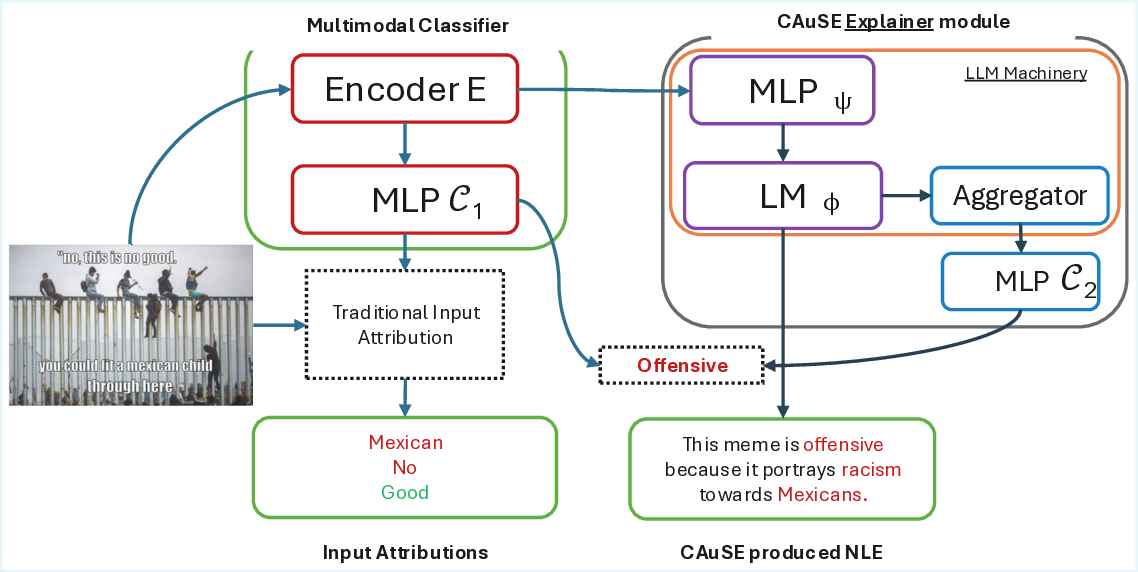
works like CAuSE. Figure 1 shows an example of
CAuSE explaining a frozen multimodal offensive-
ness classifier decision for a meme.
At the core of CAuSE is a pretrained language
model ϕ, which is guided by the hidden states of
the classifier to produce natural language explana-
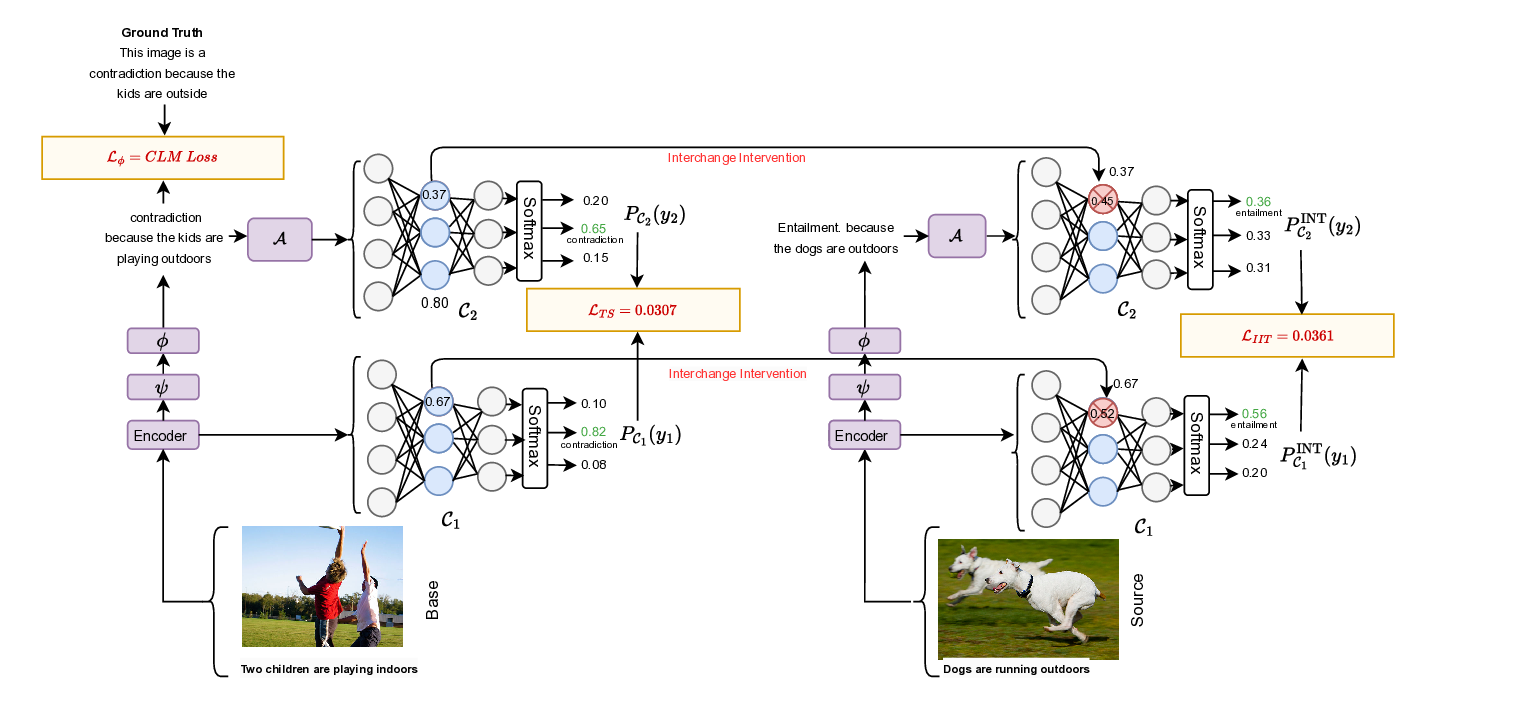
tions. CAuSE uses a novel loss function, grounded
in interchange intervention training (Geiger et al.,
2021), that enforces causal faithfulness of the gen-
erated explanations (see Section 5 for results and
analysis). We also propose a variant of a widely
used causal faithfulness metric (Atanasova et al.,
2023), termed CCMR (Counterfactual Consis-
tency via Multimodal Representation), tailored
arXiv:2512.06814v1 [cs.CL] 7 Dec 2025
for evaluating faithfulness of NLEs in multimodal
contexts. Under this metric, CAuSE demonstrates
strong performance on benchmark datasets such as
e-SNLI-VE (Do et al., 2021), which is a dataset of
image premises and text hypotheses labeled with
entailment, contradiction, or neutral labels; Face-
book Hateful Memes (Kiela et al., 2020) in which
the task is to predict whether an input meme is
offensive or not; and VQA-X (Park et al., 2018),
which is a visual question answering dataset cou-
pled with gold explanations.
We conduct extensive qualitative analyses to ex-
amine: (i) where and how CAuSE succeeds in pro-
ducing causally faithful NLEs (§5.5.1 and §5.5.2),
(ii) typical failure cases (§5.5.3), and (iii) general
trends observed in error analysis (§5.6).
Our contributions are three-fold: (1) a frame-
work for generating faithful, post-hoc NLEs for
multimod