Title: Mechanistic Interpretability of GPT-2: Lexical and Contextual Layers in Sentiment Analysis
ArXiv ID: 2512.06681
Date: 2025-12-07
Authors: Amartya Hatua
📝 Abstract
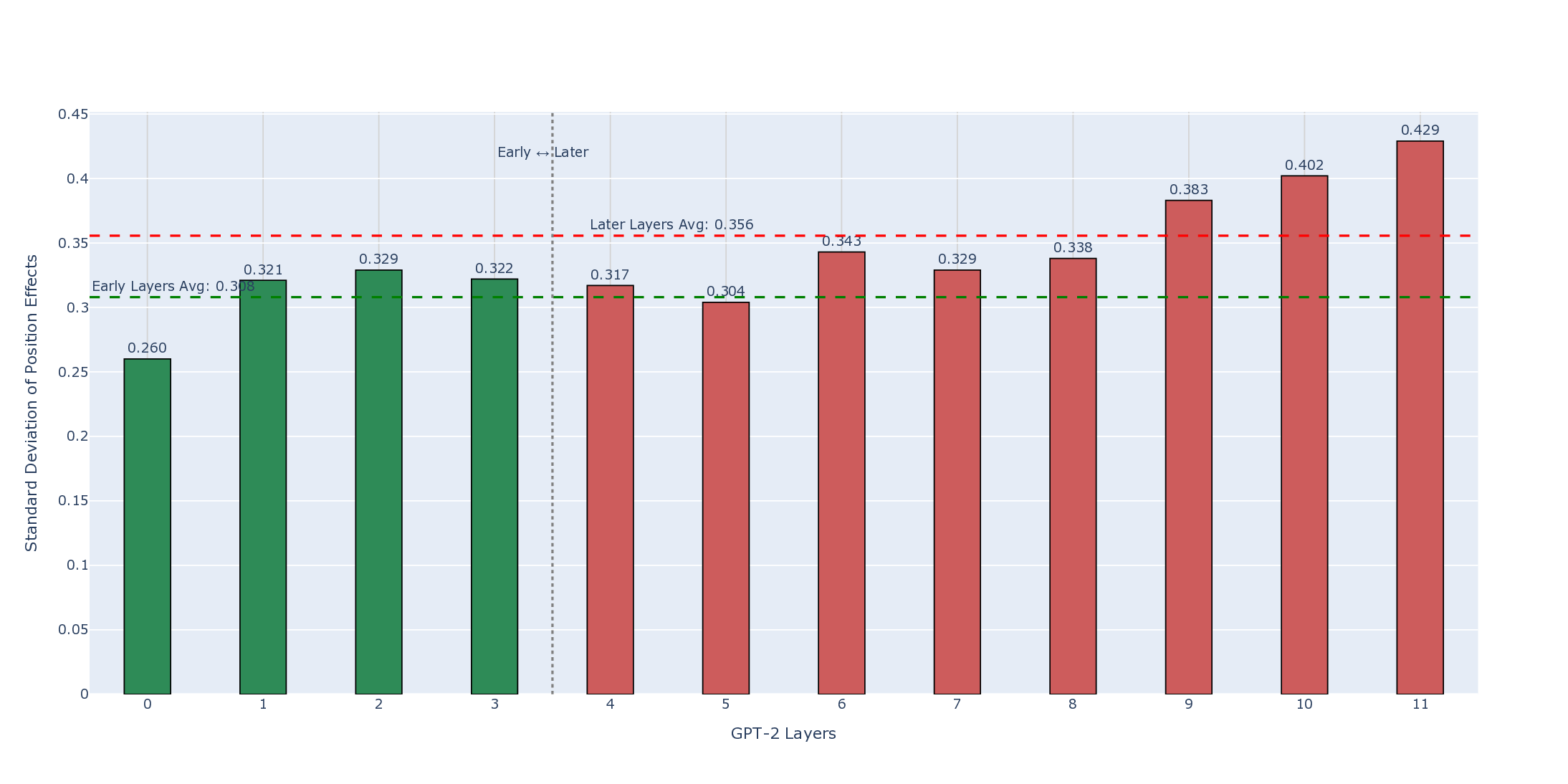
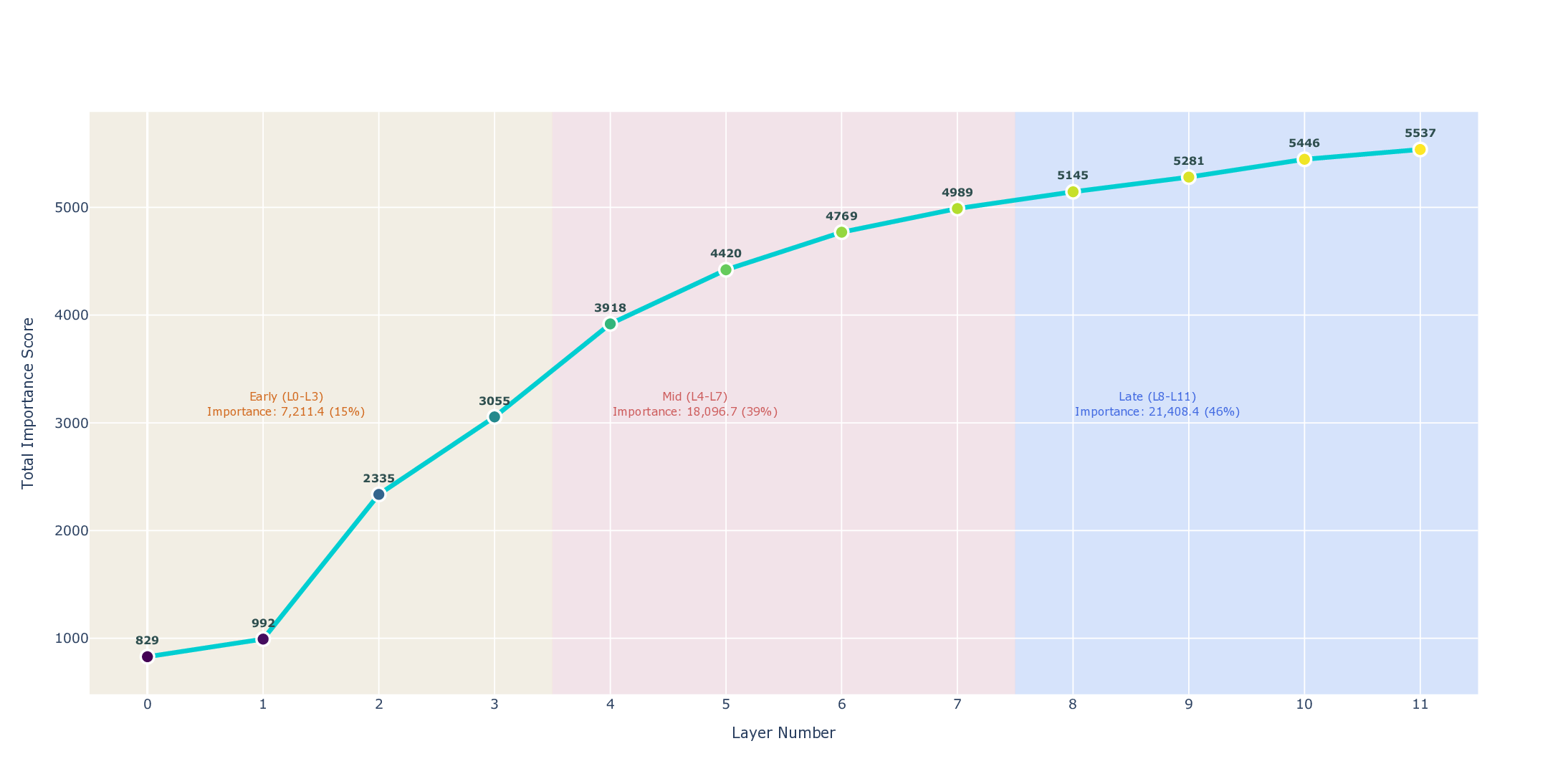
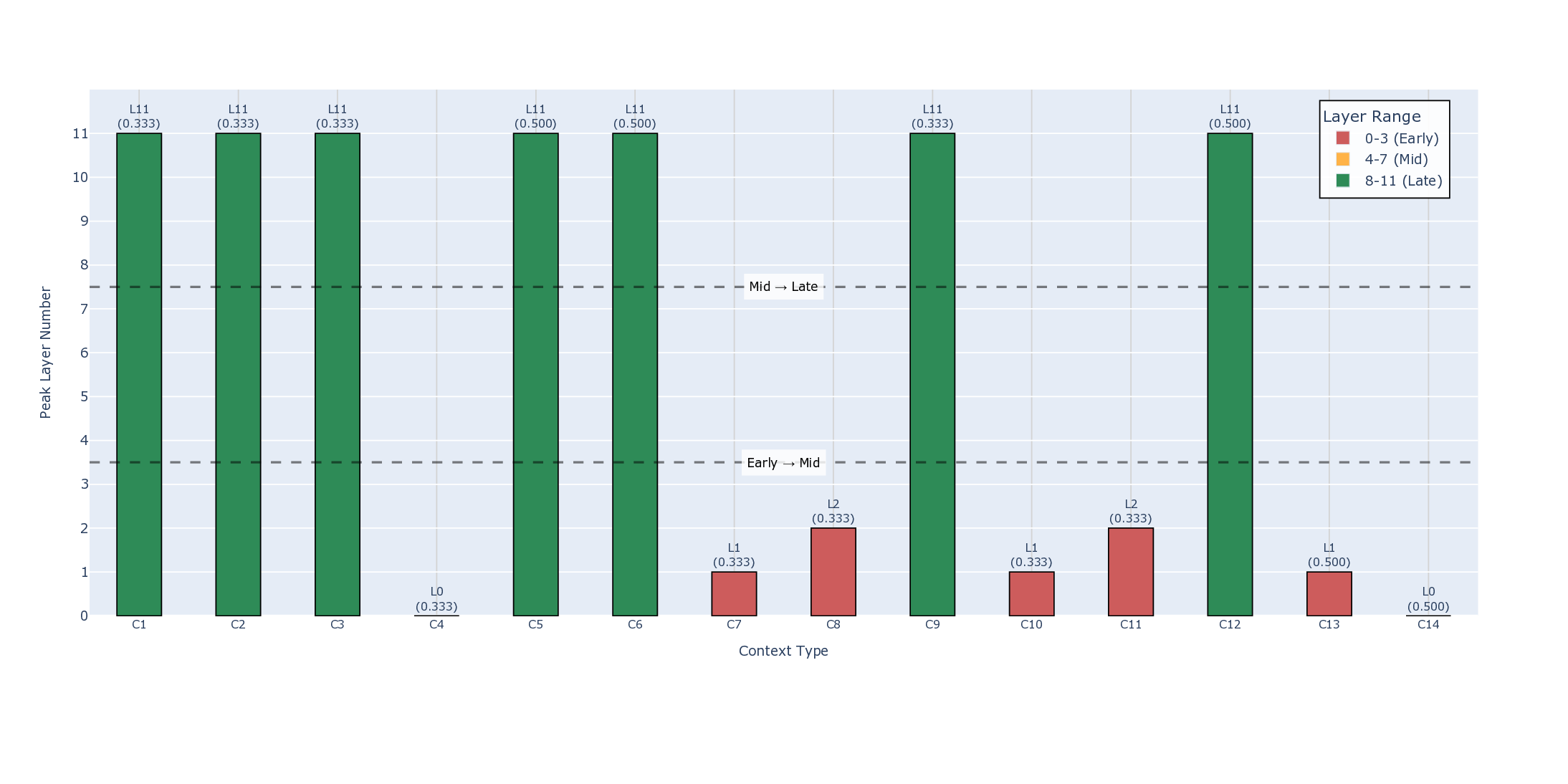
We present a mechanistic interpretability study of GPT-2 that causally examines how sentiment information is processed across its transformer layers. Using systematic activation patching across all 12 layers, we test the hypothesized two-stage sentiment architecture comprising early lexical detection and mid-layer contextual integration. Our experiments confirm that early layers (0-3) act as lexical sentiment detectors, encoding stable, position specific polarity signals that are largely independent of context. However, all three contextual integration hypotheses: Middle Layer Concentration, Phenomenon Specificity, and Distributed Processing are falsified. Instead of mid-layer specialization, we find that contextual phenomena such as negation, sarcasm, domain shifts etc. are integrated primarily in late layers (8-11) through a unified, non-modular mechanism. These experimental findings provide causal evidence that GPT-2's sentiment computation differs from the predicted hierarchical pattern, highlighting the need for further empirical characterization of contextual integration in large language models.
💡 Deep Analysis
📄 Full Content
Mechanistic Interpretability of GPT-2: Lexical and
Contextual Layers in Sentiment Analysis
Amartya Hatua ∗
AI Center of Excellence
Fidelity Investments
Boston, MA 02210
amartyahatua@gmail.com
Abstract
We present a mechanistic interpretability study of GPT-2 that causally examines
how sentiment information is processed across its transformer layers. Using
systematic activation patching across all 12 layers, we test the hypothesized two-
stage sentiment architecture comprising early lexical detection and mid-layer
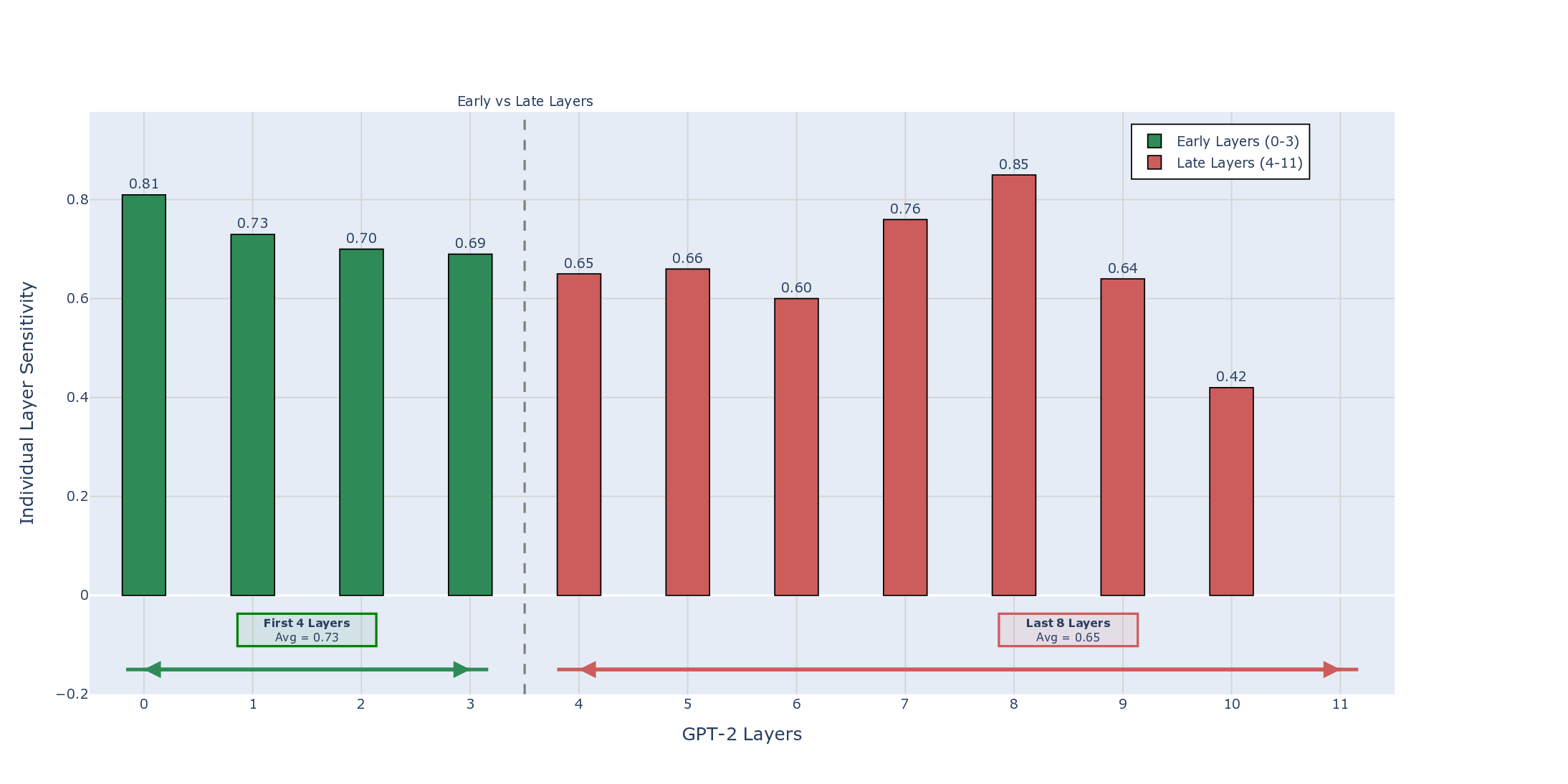
contextual integration. Our experiments confirm that early layers (0-3) act as
lexical sentiment detectors, encoding stable, position specific polarity signals that
are largely independent of context. However, all three contextual integration
hypotheses: Middle Layer Concentration, Phenomenon Specificity, and Distributed
Processing are falsified. Instead of mid-layer specialization, we find that contextual
phenomena such as negation, sarcasm, domain shifts etc. are integrated primarily in
late layers (8-11) through a unified, non-modular mechanism. These experimental
findings provide causal evidence that GPT-2’s sentiment computation differs from
the predicted hierarchical pattern, highlighting the need for further empirical
characterization of contextual integration in large language models.
1
Introduction
Large language models demonstrate impressive capabilities across a wide range of diverse linguistic
tasks. Despite this progress, existing interpretability research primarily relies on correlational
evidence from probing or attention analysis. Consequently, the internal causal structure through
which these models encode and transform linguistic information has not been widely explored.
Early research focused on identifying how distinct layers within transformers contribute to different
stages of linguistic processing. Tenney et al. [2019] found that BERT processes language in stages
early layers handle syntactic information, while later layers understand semantic relationships. This
suggests that transformers operate similarly to a pipeline, progressing from simple features to a
complex understanding. It was the first clear evidence that these models have organized, step
by step processing. Building upon this foundation, Jawahar et al. [2019], formalized a three-tier
hierarchical framework: early layers handle basic word features, middle layers deal with grammar
and sentence structure, and late layers understand meaning and how distant words relate to each
other. Simultaneously, Clark et al. [2019] revealed that individual heads develop specialized functions
for specific linguistic phenomena, following the same early to late progression. In Rogers et al.
[2020], a comprehensive synthesis was provided that established a general consensus on middle
layer specialization for syntactic structure, while highlighting that semantic processing remains
more distributed and less well understood. All these studies showed that transformers seem to
process language in organized, step-by-step ways. However, their methodologies were predominantly
∗Code and data available at: https://github.com/amartyahatua/MI_Sentiment_Analysis
39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: Efficient Reasoning.
arXiv:2512.06681v1 [cs.CL] 7 Dec 2025
correlational, relying on probing classifiers and attention analysis to identify what information exists
in representations rather than what models actually use during inference.
Newer research has highlighted this gap. Scientists now realize that finding patterns doesn’t prove the
model actually uses them. As Belinkov et al. [2023] puts it, there’s a gap between what we can detect
in the model and what the model actually relies on; just because we can find information doesn’t
mean the model uses it. When Elazar and Goldberg [2018] tried removing features they thought were
important, the models often worked just fine without them. This suggested they were finding fake
patterns, not real ones. Makelov et al. [2024] found “interpretability illusions” interventions that
seemed to reveal how models work but were actually triggering backup systems that had nothing to
do with normal processing.
Recent years have brought major improvements in solving the correlation-causation problem. The
field of mechanistic interpretability Rai et al. [2024] has developed new techniques like activation
patching Heimersheim and Nanda [2024] that let researchers directly test cause and effect, while
automated tools have made the analysis process more systematic. Companies like Anthropic and
OpenAI have successfully applied these mechanistic methods to real models, finding millions of
interpretable features in their large language models. Among these challenging phenomena, sentiment
analysis presents a particularly instructive case. Sentiment analysis represents a particularly complex
challenge for mechanistic interpretability. Unlike syntactic phenomena that localize to s