Analysts in Security Operations Centers routinely query massive telemetry streams using Kusto Query Language (KQL). Writing correct KQL requires specialized expertise, and this dependency creates a bottleneck as security teams scale. This paper investigates whether Small Language Models (SLMs) can enable accurate, cost-effective natural-language-to-KQL translation for enterprise security. We propose a three-knob framework targeting prompting, fine-tuning, and architecture design. First, we adapt existing NL2KQL framework for SLMs with lightweight retrieval and introduce error-aware prompting that addresses common parser failures without increasing token count. Second, we apply LoRA fine-tuning with rationale distillation, augmenting each NLQ-KQL pair with a brief chain-of-thought explanation to transfer reasoning from a teacher model while keeping the SLM compact. Third, we propose a two-stage architecture that uses an SLM for candidate generation and a low-cost LLM judge for schema-aware refinement and selection. We evaluate nine models (five SLMs and four LLMs) across syntax correctness, semantic accuracy, table selection, and filter precision, alongside latency and token cost. On Microsoft's NL2KQL Defender Evaluation dataset, our two-stage approach achieves 0.987 syntax and 0.906 semantic accuracy. We further demonstrate generalizability on Microsoft Sentinel data, reaching 0.964 syntax and 0.831 semantic accuracy. These results come at up to 10x lower token cost than GPT-5, establishing SLMs as a practical, scalable foundation for natural-language querying in security operations.
The evolving cybersecurity landscape has increased attack complexity and reshaped how analysts mitigate threats. In Security Operations Centers (SOCs), analysts face overwhelming volumes of event logs, network traffic, and threat intelligence feeds [6], receiving on average 5,000 alerts per day via SIEM systems and up to 100,000 in extreme cases [4]. To investigate these massive logs, they rely on query languages such as Sigma, Elastic EQL, and KQL [2,10,28], but translating natural-language intent into correct queries over large, evolving schemas remains a major bottleneck.
KQL, introduced by Microsoft in 2017 [19], is the most widely adopted. Integrated into Microsoft Sentinel and Defender, it is a Listing 1: Example KQL query that retrieves device IDs which last connected from IP address 89.12.55.1 within the last 7 days. The query references multiple columns in the DeviceNetworkEvents table schema, including Timestamp.
domain-specific, read-only language that lets analysts parse millions of log rows efficiently and extract relevant events. However, its expressiveness and non-trivial semantics make authoring accurate queries challenging for non-experts, especially during timesensitive investigations.
In the era of LLMs, automated KQL generation can further accelerate investigations by producing precise queries aligned with an analyst’s intent. Beyond code generation, LLMs have been applied across cybersecurity tasks, such as log analysis and penetration testing [8,23]. They have also been exploited for offensive purposes, including phishing and ransomware planning [13], while models like GPT-3.5 and GPT-4 show strong defensive potential in areas such as scam detection [17]. However, LLM-centric pipelines for NLQ-to-KQL translation can be costly, latency-sensitive, and difficult to deploy under enterprise data-governance constraints.
Unfortunately, LLMs also incur drawbacks, including higher latency, memory demands, and operational costs. Moreover, depending on the use case, they may be unsuitable for certain tasks [7]. As an alternative, we introduce SLMs, defined following [7] as language models that (i) can run on common consumer devices with practical inference latency, (ii) are not LLMs, and (iii) have at most 10 billion parameters. SLMs offer lower latency, memory, computational, and operational costs while still achieving accuracy comparable to LLMs in some domain-specific tasks [7]. Despite this promise, there has been no systematic study of SLMs for NLQ-to-KQL translation in realistic, schema-rich settings.
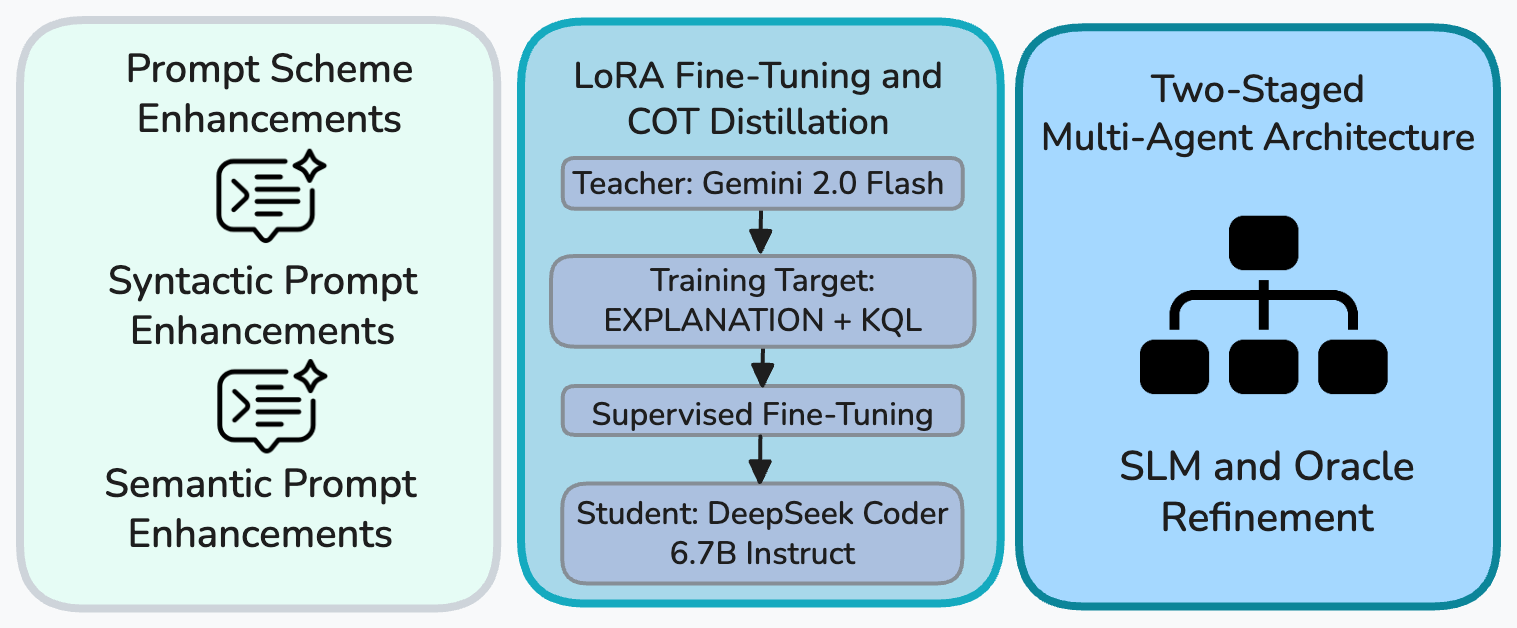
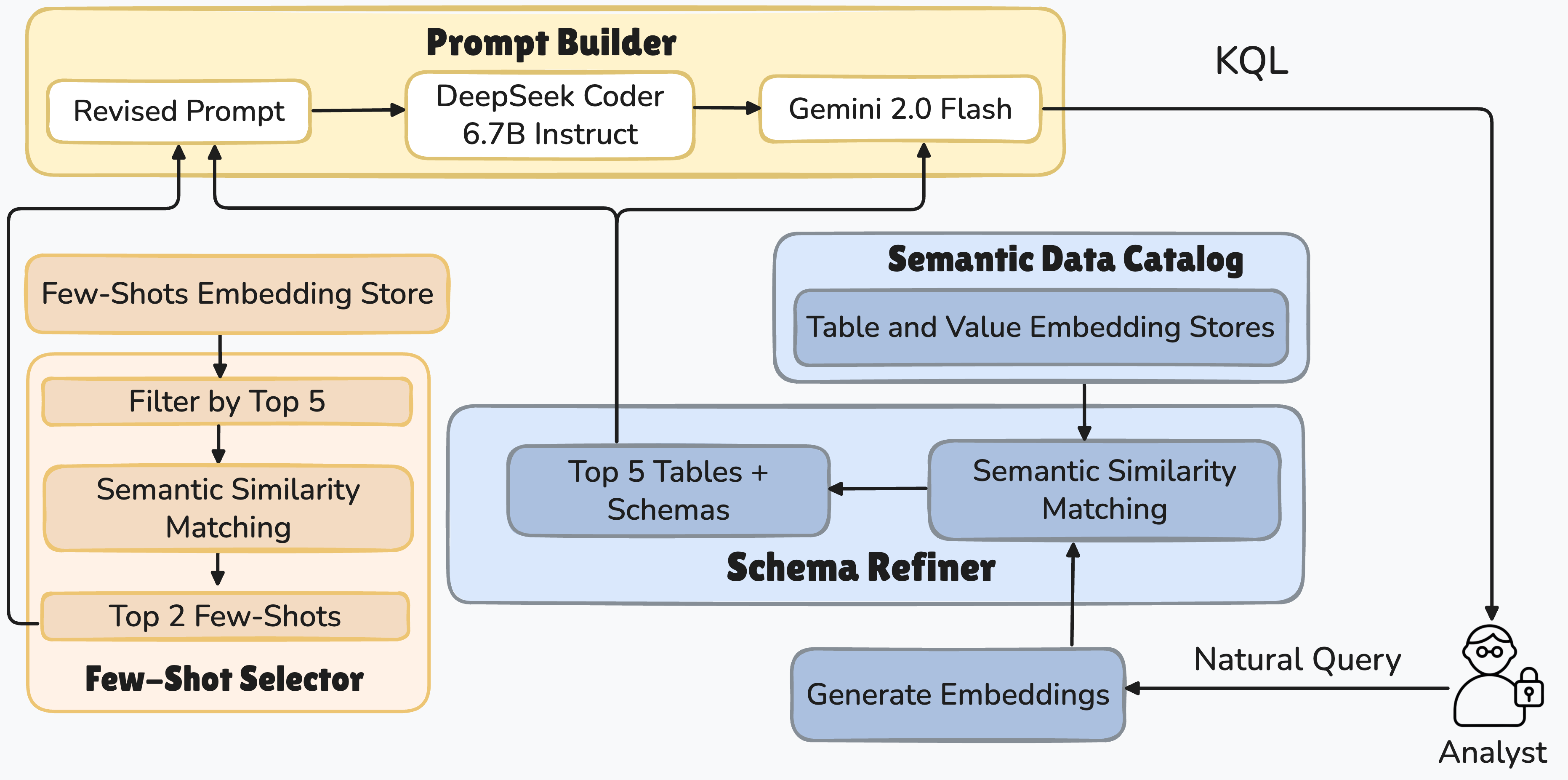
This work fills that gap through three orthogonal enhancement knobs (prompting, fine-tuning, and two-staged architecture design) and a comprehensive empirical study. We provide the first systematic evaluation of SLMs for NLQ-to-KQL translation across multiple accuracy metrics, latency, and cost, establishing clear baselines against representative LLMs. We adapt the NL2KQL architecture for SLMs by replacing heavy components with lightweight alternatives while preserving the prompting, retrieval, and refinement structure so that results are both comparable and cost efficient. We also introduce error-aware prompting based on common KQL parser failures, which improves syntactic and semantic correctness without increasing token count.
We further explore LoRA fine-tuning [15] with rationale distillation to transfer reasoning from a teacher LLM into an SLM. LoRA trains only low-rank adapter parameters while freezing the original model weights, enabling efficient fine-tuning on NLQ-KQL pairs. To embed reasoning capabilities, each training example is augmented with a short chain-of-thought explanation produced by the teacher model, followed by the target KQL. This rationale-augmented setup allows the SLM to learn intermediate reasoning steps in addition to final outputs, strengthening its ability to handle structured code generation tasks without increasing model size.
Beyond prompting and fine-tuning, our core contribution is a two-stage SLM-Oracle architecture for KQL generation. The first stage uses an SLM to efficiently generate candidate queries, while the second employs a lightweight LLM as an Oracle to validate, refine, and select the best output using schema information and parsing feedback. This division of labor lets the SLM focus on fast generation and the Oracle on correctness, creating a scalable architecture that balances efficiency and accuracy. This design is the key novelty of our work, combining the complementary strengths of SLMs and LLMs in a modular, resource-conscious framework for real-world security analytics.
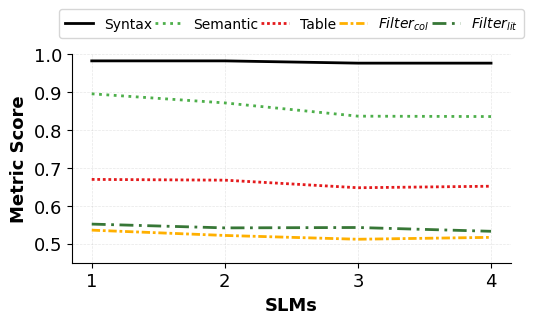
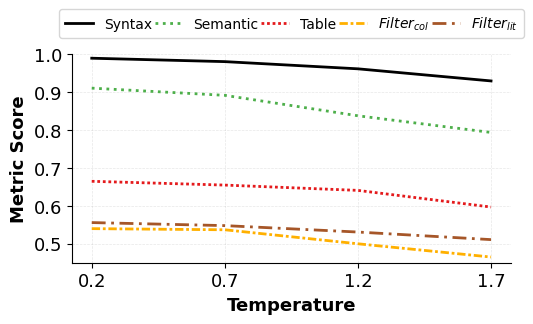
We conduct extensive experiments spanning baseline performance, prompting strategies, fine-tuning, and architectural design. Our evaluation covers nine models: five SLMs (Gemma-3-1B-IT, Gemma-3-4B-IT, Phi-4-Mini-Instruct,Qwen-2.5-7B-Instruct-1M, and DeepSeek Coder 6.7B Instruct) and four LLMs (GPT-5, GPT-4o, Gemini 2.0 Flash, and Phi-4), using 230 NLQ-KQL pairs fro
This content is AI-processed based on open access ArXiv data.