Title: Hidden Leaks in Time Series Forecasting: How Data Leakage Affects LSTM Evaluation Across Configurations and Validation Strategies
ArXiv ID: 2512.06932
Date: 2025-12-07
Authors: ** - Salma Albelali (King Fahd University of Petroleum & Minerals; Imam Abdulrahman Bin Faisal University) - Moataz Ahmed (King Fahd University of Petroleum & Minerals; SDAIA‑KFUPM Joint Research Center for AI) **
📝 Abstract
Deep learning models, particularly Long Short-Term Memory (LSTM) networks, are widely used in time series forecasting due to their ability to capture complex temporal dependencies. However, evaluation integrity is often compromised by data leakage, a methodological flaw in which input-output sequences are constructed before dataset partitioning, allowing future information to unintentionally influence training. This study investigates the impact of data leakage on performance, focusing on how validation design mediates leakage sensitivity. Three widely used validation techniques (2-way split, 3-way split, and 10-fold cross-validation) are evaluated under both leaky (pre-split sequence generation) and clean conditions, with the latter mitigating leakage risk by enforcing temporal separation during data splitting prior to sequence construction. The effect of leakage is assessed using RMSE Gain, which measures the relative increase in RMSE caused by leakage, computed as the percentage difference between leaky and clean setups. Empirical results show that 10-fold cross-validation exhibits RMSE Gain values of up to 20.5% at extended lag steps. In contrast, 2-way and 3-way splits demonstrate greater robustness, typically maintaining RMSE Gain below 5% across diverse configurations. Moreover, input window size and lag step significantly influence leakage sensitivity: smaller windows and longer lags increase the risk of leakage, whereas larger windows help reduce it. These findings underscore the need for configuration-aware, leakage-resistant evaluation pipelines to ensure reliable performance estimation.
💡 Deep Analysis
📄 Full Content
Hidden Leaks in Time Series Forecasting: How
Data Leakage Affects LSTM Evaluation Across
Configurations and Validation Strategies
Salma Albelali1,2
and Moataz Ahmed1,3
1 King Fahd University of Petroleum & Minerals, Department of Information and
Computer Science, Dhahran, Saudi Arabia
2 Imam Abdulrahman Bin Faisal University, Department of Computer Science,
Dammam, Saudi Arabia
salbelali@iau.edu.sa
3 SDAIA-KFUPM Joint Research Center for Artificial Intelligence, Dhahran, Saudi
Arabia
g201907430@kfupm.edu.sa, moataz@kfupm.edu.sa
Abstract. Deep learning models, particularly Long Short-Term Mem-
ory (LSTM) networks, are widely used in time series forecasting due to
their ability to capture complex temporal dependencies. However, evalu-
ation integrity is often compromised by data leakage—a methodological
flaw where input-output sequences are constructed prior to dataset parti-
tioning, allowing future information to unintentionally influence training.
This study investigates the impact of data leakage on performance, focus-
ing on how validation design mediates leakage sensitivity. Three widely
used validation techniques—2-way split, 3-way split, and 10-fold cross-
validation—are evaluated under both leaky (pre-split sequence genera-
tion) and clean conditions, the latter mitigating leakage risk by enforcing
temporal separation during data splitting prior to sequence construction.
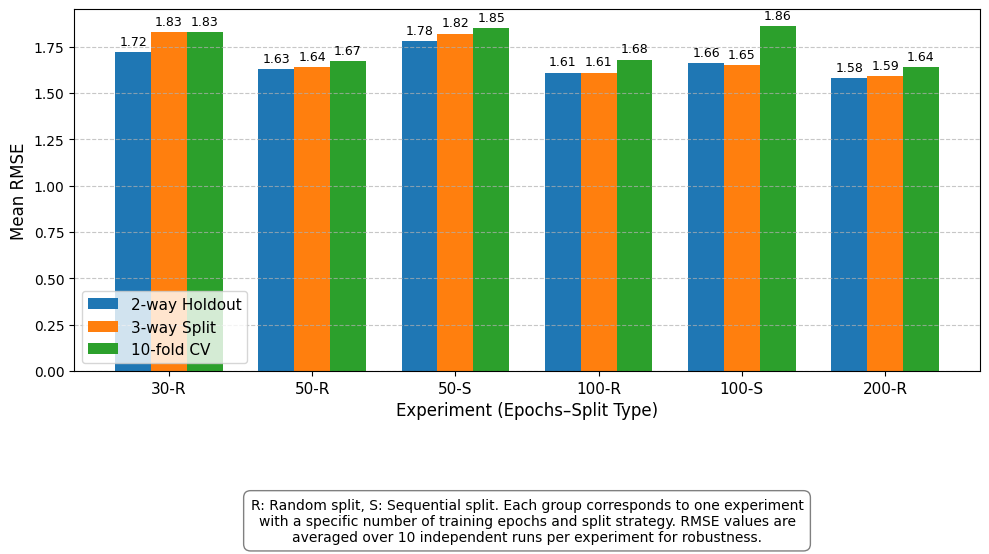
The effect of leakage is assessed using RMSE Gain, which measures the
relative increase in RMSE caused by leakage, calculated as the percent-
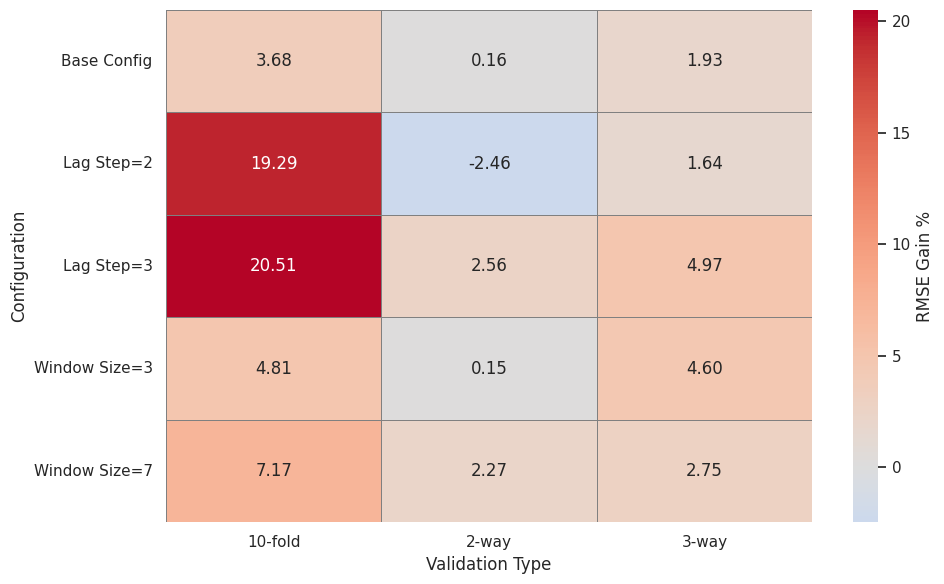
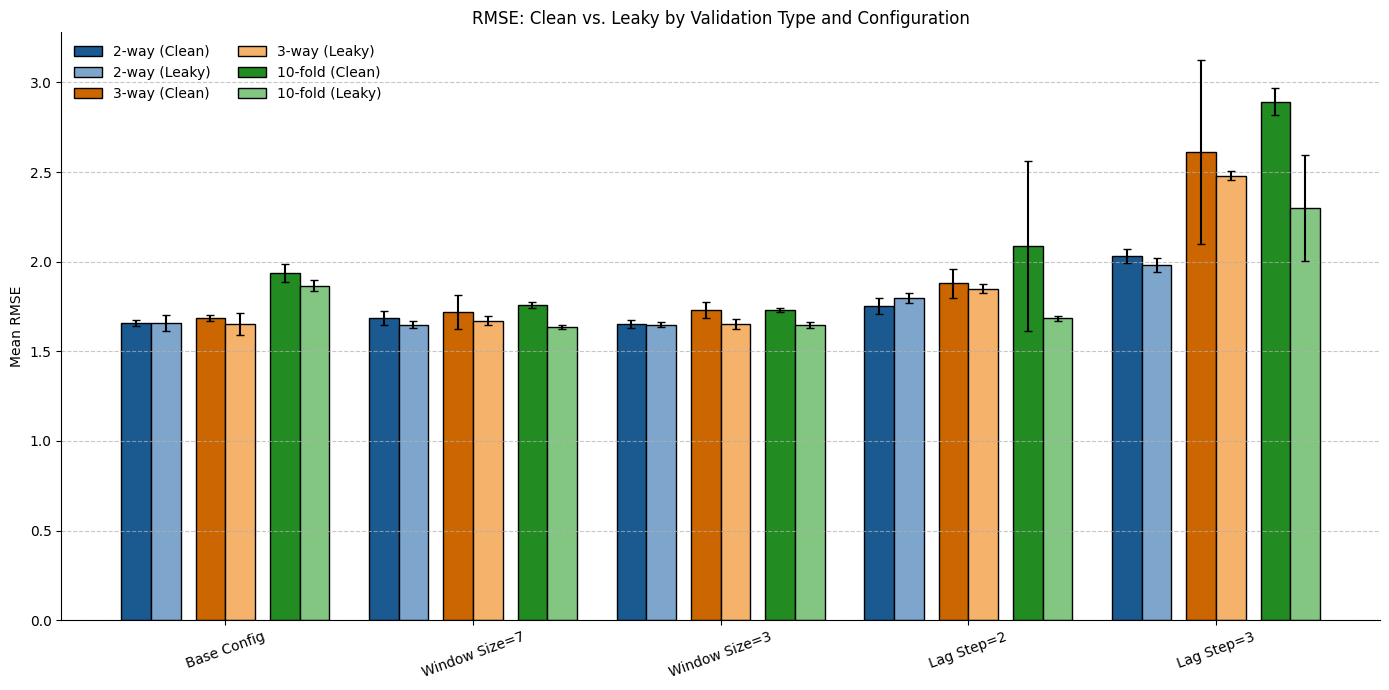
age difference between leaky and clean setups. Empirical results show
that 10-fold cross-validation exhibits RMSE Gain values up to 20.5%
at extended lag steps. In contrast, 2-way and 3-way splits demonstrate
greater robustness, typically maintaining RMSE Gain below 5% across
diverse configurations. Moreover, input window size and lag step signifi-
cantly influence leakage sensitivity: smaller windows and longer lags in-
crease the risk of leakage, whereas larger windows help reduce it. These
findings underscore the need for configuration-aware, leakage-resistant
evaluation pipelines to ensure reliable performance estimation.
Keywords: Data Leakage · Testing Deep Learning · Validation and Ver-
ification · Time Series Forecasting
1
Introduction
Deep learning has significantly advanced time series forecasting by enabling mod-
els to learn complex temporal patterns from large volumes of sequential data.
arXiv:2512.06932v1 [cs.LG] 7 Dec 2025
2
S. Albelali and M. Ahmed
Among various architectures, Long Short-Term Memory (LSTM) networks have
played a pivotal role in modeling time-dependent relationships due to their abil-
ity to mitigate vanishing gradient issues and retain long-range dependencies.
While recent architectures such as Transformers have gained attention, LSTMs
remain widely adopted and benchmarked in applied forecasting pipelines.
Accurate performance estimation is a critical concern in the verification and
validation of deep learning models, especially in time series applications where
the assumptions of traditional validation techniques are frequently violated due
to temporal dependencies. Improper evaluation not only misrepresents a model’s
generalization capacity but also compromises the trustworthiness of downstream
deployment. Data leakage refers to a methodological flaw in machine learning
pipelines where information from outside the training set (typically future ob-
servations) unintentionally influences model training, thereby violating the in-
dependence between training and test data [12]. In time series forecasting, a
common form of leakage arises when sequence windows are generated prior to
dataset partitioning, allowing future values to be embedded in the training set
through overlapping temporal context. This results in overly optimistic evalu-
ation metrics that do not reflect true generalization capability. A particularly
underexamined form of data leakage arises when input-output sequences are
generated prior to dataset partitioning. This flawed pre-splitting design—often
influenced by the chosen validation technique—can inadvertently allow future
information to leak into the training set, thereby violating temporal causality
and inflating reported performance.
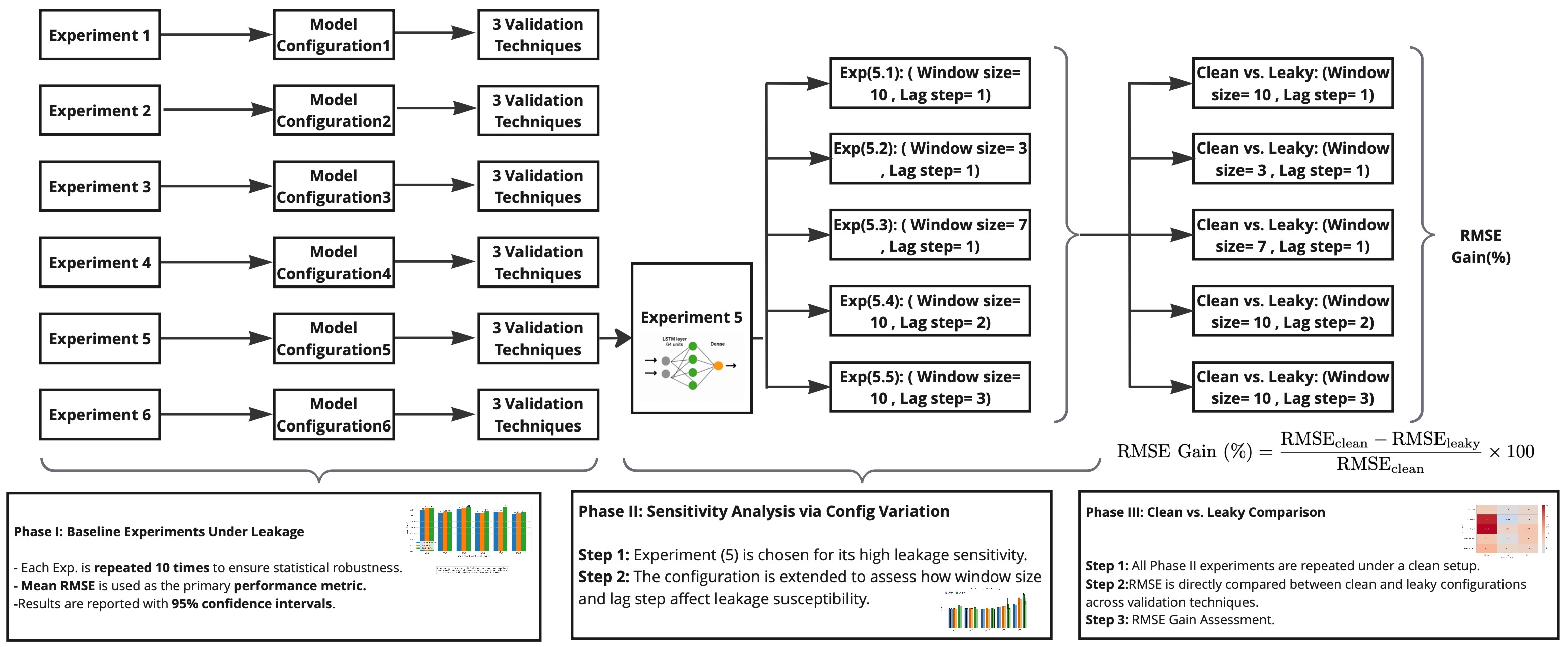
The interaction between data leakage and validation design has received lim-
ited attention in time series machine learning. One of the central objectives of this
study is to assess how different validation techniques respond to data leakage in
time series forecasting. By systematically comparing 2-way, 3-way, and 10-fold
cross-validation under both clean (post-split) and leaky (pre-split) configura-
tions, we aim to identify which techniques exhibit the highest RMSE Gain due
to improper sequence handling. To achieve this, we adopt a configuration-centric
evaluation framework that treats the validation pipeline itself as a testable com-
ponent within the forecasting system. Our experiments vary key modeling p