We present a vision-action policy that won 1st place in the 2025 BEHAVIOR Challenge - a large-scale benchmark featuring 50 diverse long-horizon household tasks in photo-realistic simulation, requiring bimanual manipulation, navigation, and context-aware decision making. Building on the Pi0.5 architecture, we introduce several innovations. Our primary contribution is correlated noise for flow matching, which improves training efficiency and enables correlation-aware inpainting for smooth action sequences. We also apply learnable mixed-layer attention and System 2 stage tracking for ambiguity resolution. Training employs multi-sample flow matching to reduce variance, while inference uses action compression and challenge-specific correction rules. Our approach achieves 26% q-score across all 50 tasks on both public and private leaderboards.
1 Introduction
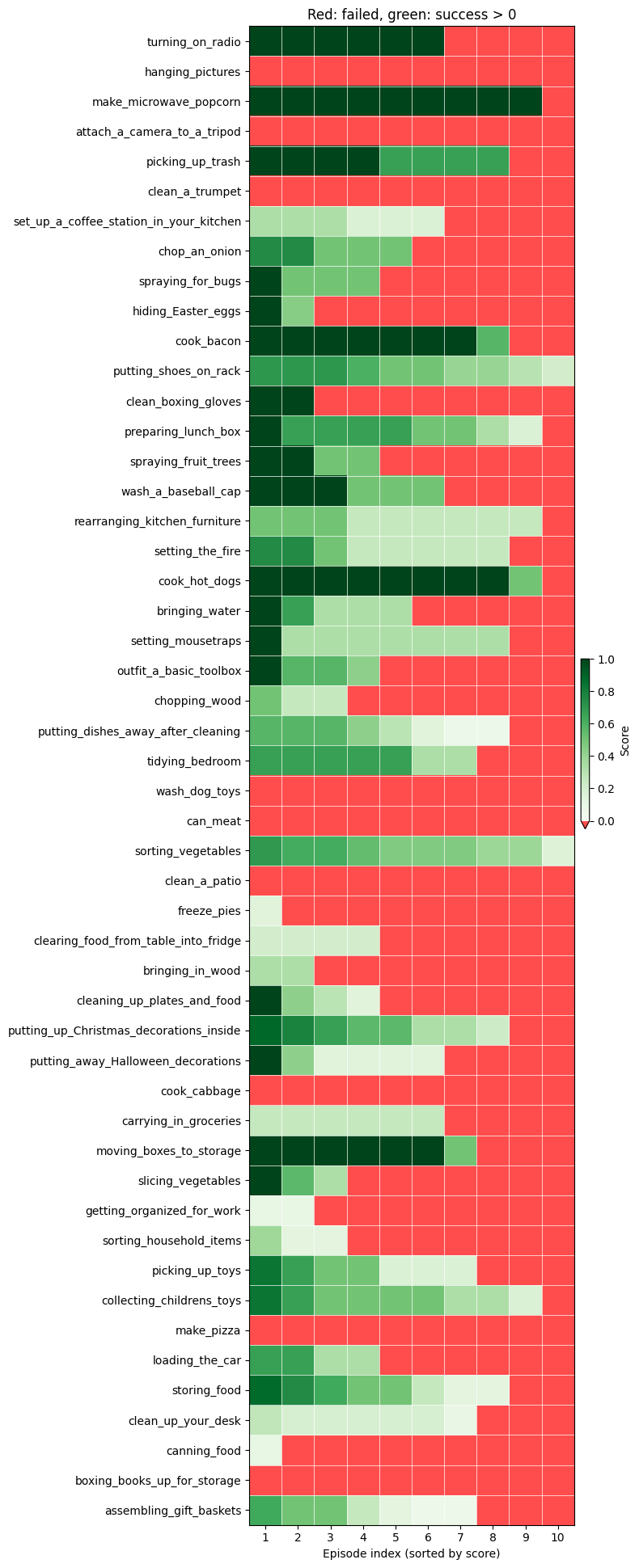
The BEHAVIOR Challenge presents a demanding benchmark for embodied AI: performing 50 diverse, long-horizon household tasks in photo-realistic simulation. Tasks range from simple (turning on radio) to complex multi-step activities (cooking a hotdog). The challenge requires:
• Long-horizon execution: 6.6 minutes on average per task, with the longest tasks averaging 14 minutes
• Bimanual manipulation: Coordinated use of two 7-DOF arms with parallel-jaw grippers
• Mobile navigation: Indoor navigation through cluttered environments
• Multi-camera perception: Processing RGB images from head and both wrist cameras
• Task diversity: 50 different activities evaluated with a single policy (or small set of checkpoints)
The benchmark uses OmniGibson simulation built on NVIDIA Isaac Sim, providing realistic physics and rendering. Each task is evaluated over 10 episodes with randomized initial conditions, and performance is measured by a q-score that combines success rate with partial credit for subtask completion.
Long-horizon household manipulation poses several fundamental challenges:
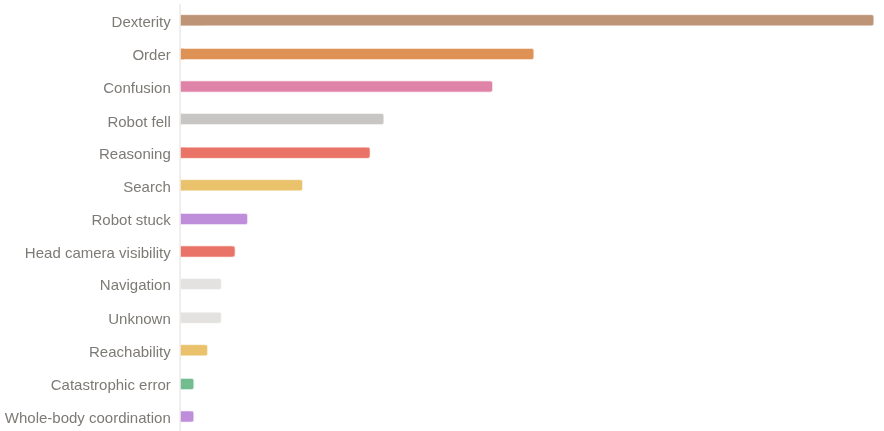
• Compounding errors. With episodes spanning thousands of timesteps, small prediction errors can accumulate. This demands either extremely accurate predictions or robust recovery behaviors.
• Non-Markovian states. Many task states are visually ambiguous-the robot holding a radio at the start of a task looks identical to holding it at the end. Without memory of past actions or explicit stage tracking, the policy cannot distinguish these states and may execute incorrect actions.
• No recovery demonstrations. The training data consists of successful demonstrations only. When the robot deviates from demonstrated trajectories (inevitable given compounding errors), it encounters states never seen during training. The policy must somehow generalize to recover from these out-of-distribution situations.
• Multi-modal action distributions. Many states admit multiple valid action sequences (e.g., which hand to use, which object to grasp first). Different episodes of the same tasks were completed at different speeds in the training data.
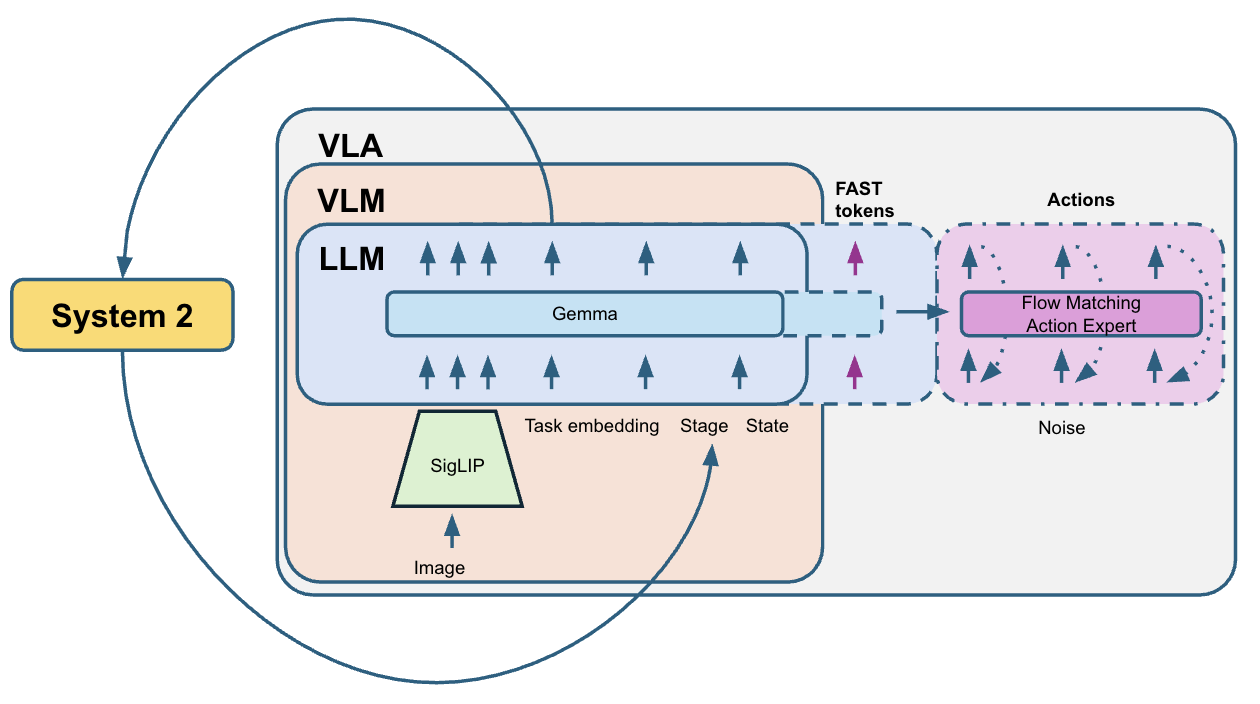
We build upon Pi0.5 [3], a vision-language-action (VLA) model that uses flow matching to predict action sequences.
Our modifications address the challenges above through the following novel components:
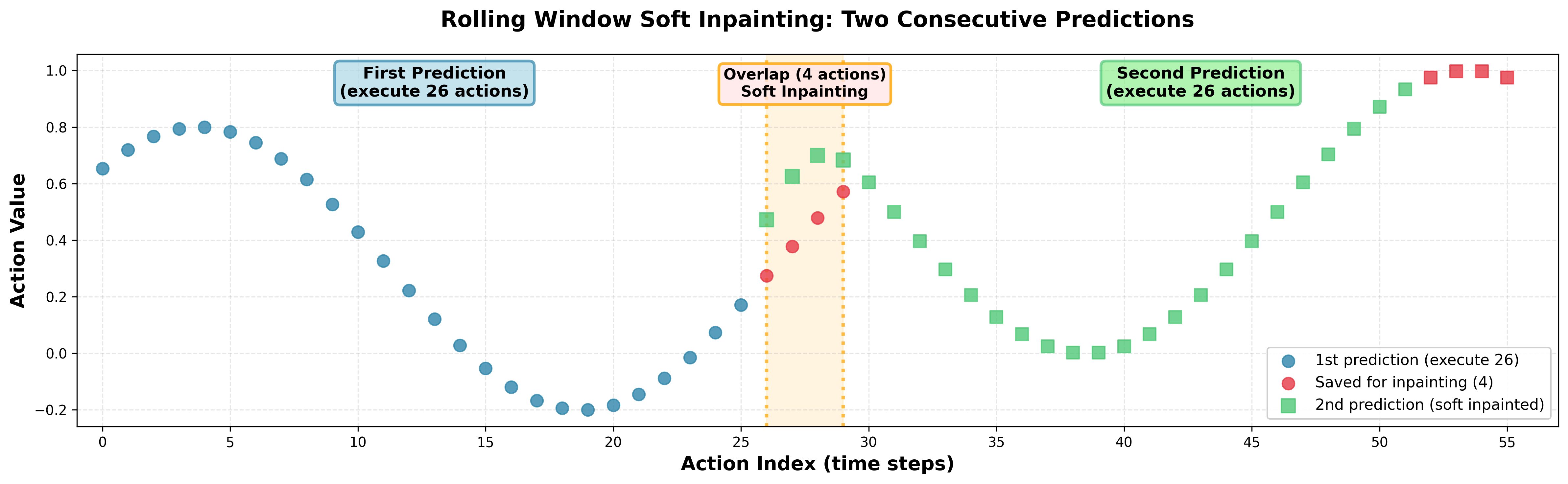
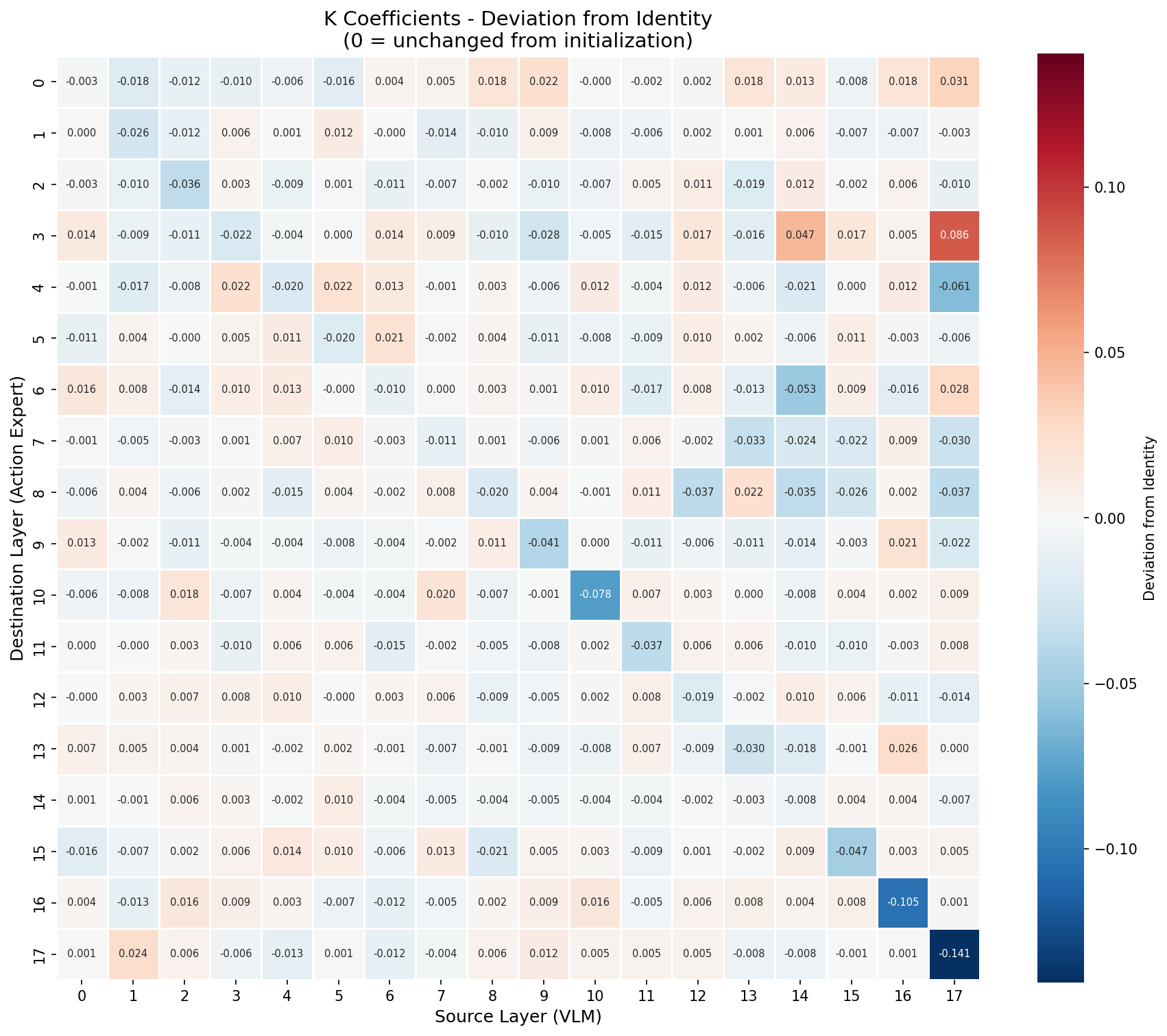
• Modeling action structure. Robot actions exhibit strong correlations-temporally (smooth trajectories) and across dimensions (coordinated joint movements). We model this structure explicitly by training with correlated noise sampled from N (0, βΣ + (1 -β)I), where Σ is the empirical action covariance and β = 0.5. This makes training more efficient and enables principled inpainting during inference.
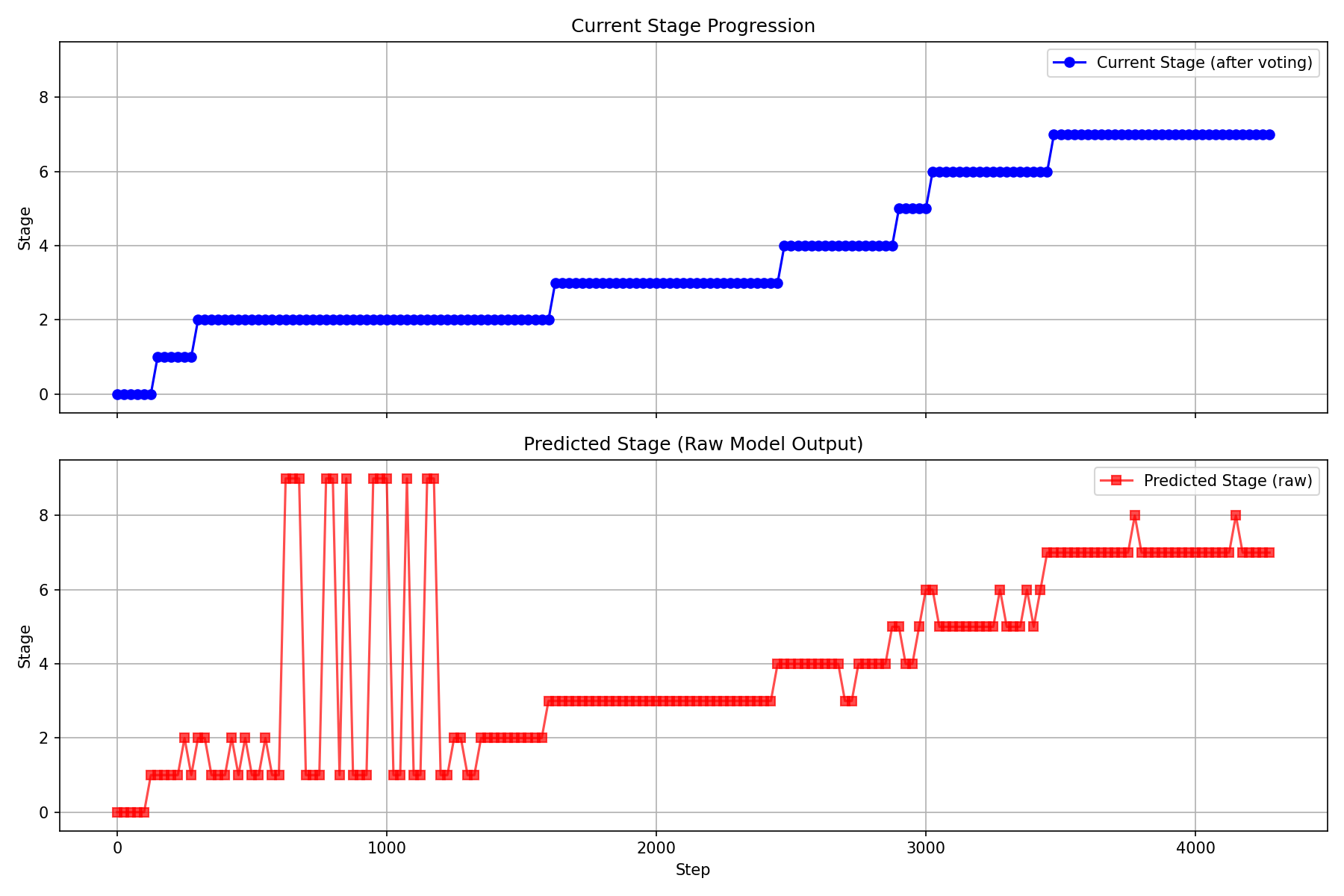
• Providing non-Markovian context. We introduce System 2 stage tracking: the model predicts the current task stage, and a voting mechanism filters noisy predictions to maintain stable stage estimates. This stage information is fused with task embeddings and fed back to the model, resolving ambiguous states.
• Combining learning with heuristics. Pure learning struggles with the lack of recovery data. We complement the learned policy with correction rules derived from failure analysis: simple heuristics that detect and recover from common failure modes like accidental gripper closures.
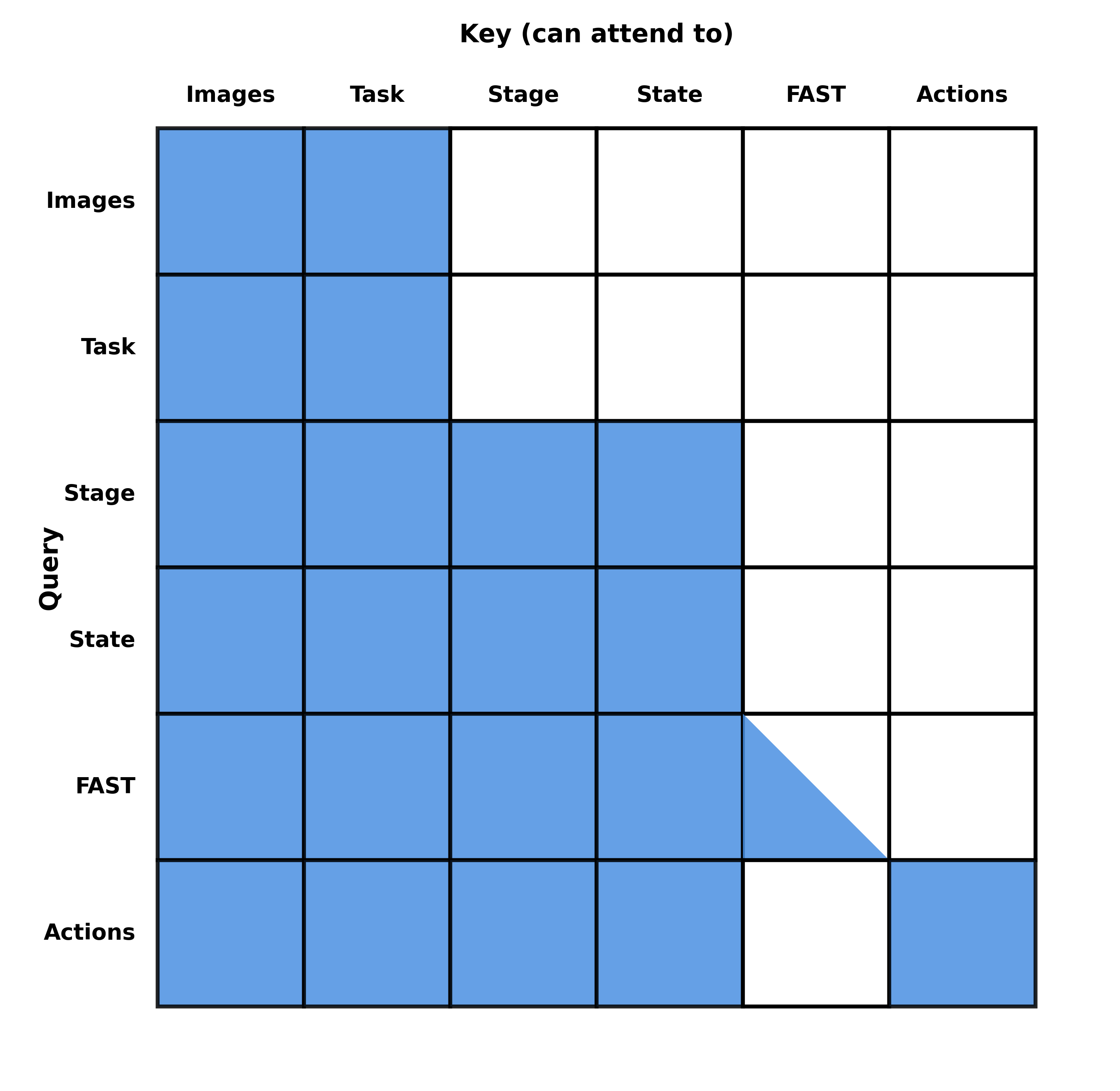
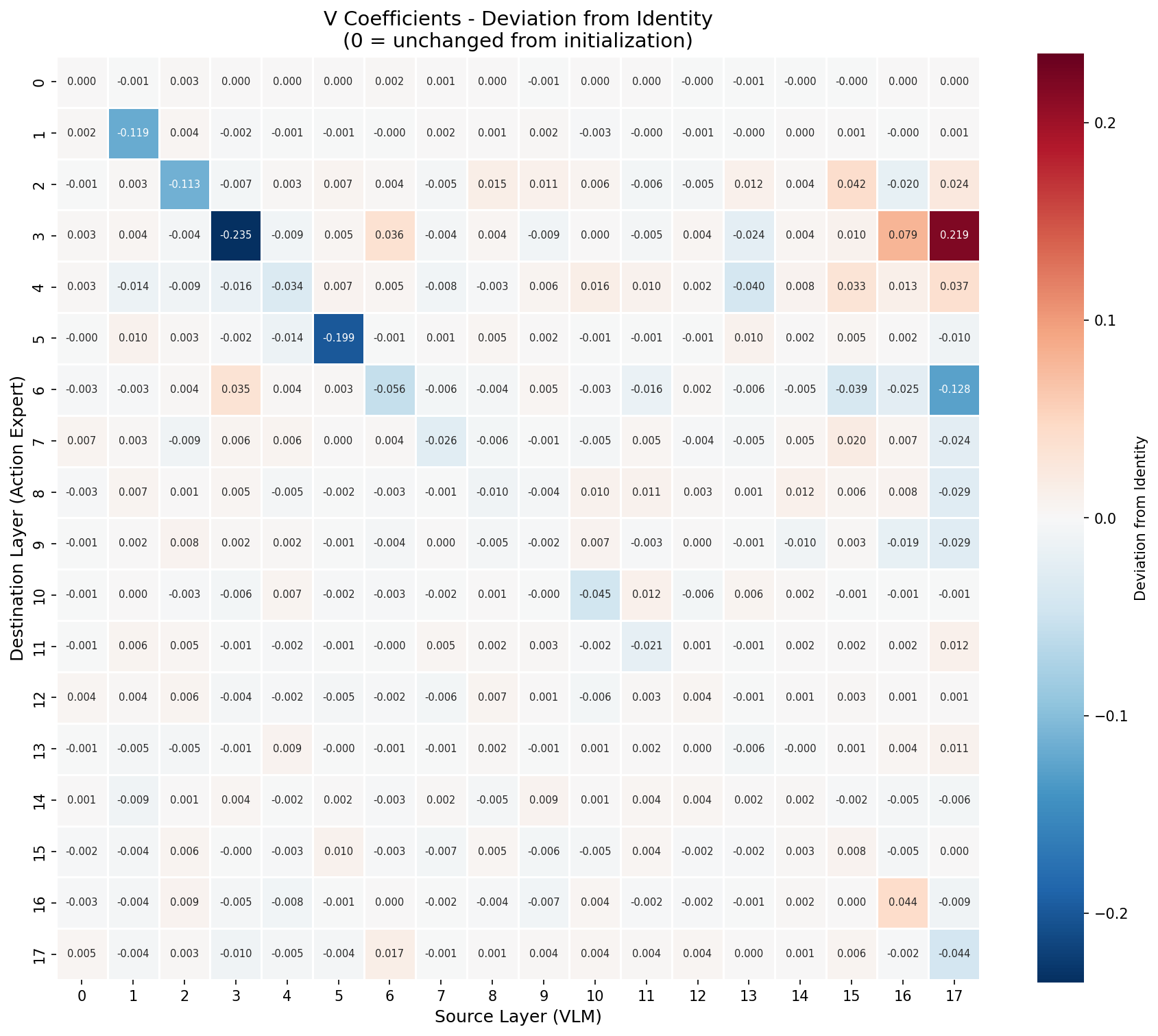
• We apply learnable mixed-layer attention that allows each action expert layer to attend to learned linear combinations of all VLM layers rather than arbitrarily deciding how action expert layers should attend to VLM layers.
• For training, we employ multi-sample flow matching (15 predictions per VLM forward pass) to reduce gradient variance while amortizing expensive vision-language computations.
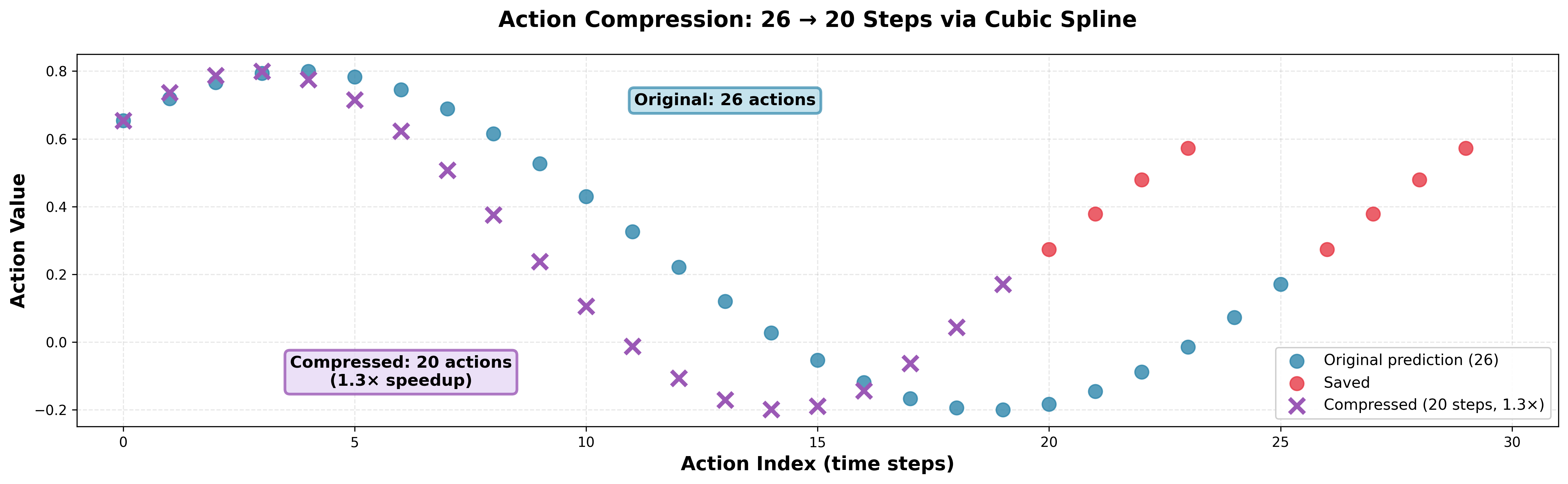
• At inference, we apply action compression via cubic splines to speed up action execution by 1.3×.
• We also simplified the VLM part by removing text processing and using trainable task embeddings instead of the text prompt. Technically this removes “L” from “VLA” and “VLM” terms but we keep the names “VLA” and “VLM” for simplicity.
This report describes a competition entry, not a research paper. As a small independent team with limited compute, we prioritized winning over rigorous ablation studies. Many design choices were guided by intuition or quick experiments rather than systematic evaluation.
We present our methods honestly, without claiming that every component is necessary or optimal. That said, first place on the leaderboard suggests the overall approach is soundeven if we cannot isolate the contribution of each piece.
Our code for training and inference is available at https: //github.com/IliaLarchenko/behavior-1k-s olution.
We also share our model weights at https://huggingf ace.co/IliaLarchenko/behavior_submission.
This code and these weights should allow anyone to reproduce our results.
Our work builds on vision-language-action models, flow matching, action chunking, and multi-task learning for
This content is AI-processed based on open access ArXiv data.