Title: Uncovering Competency Gaps in Large Language Models and Their Benchmarks
ArXiv ID: 2512.20638
Date: 2025-12-06
Authors: Matyas Bohacek, Nino Scherrer, Nicholas Dufour, Thomas Leung, Christoph Bregler, Stephanie C. Y. Chan
📝 Abstract
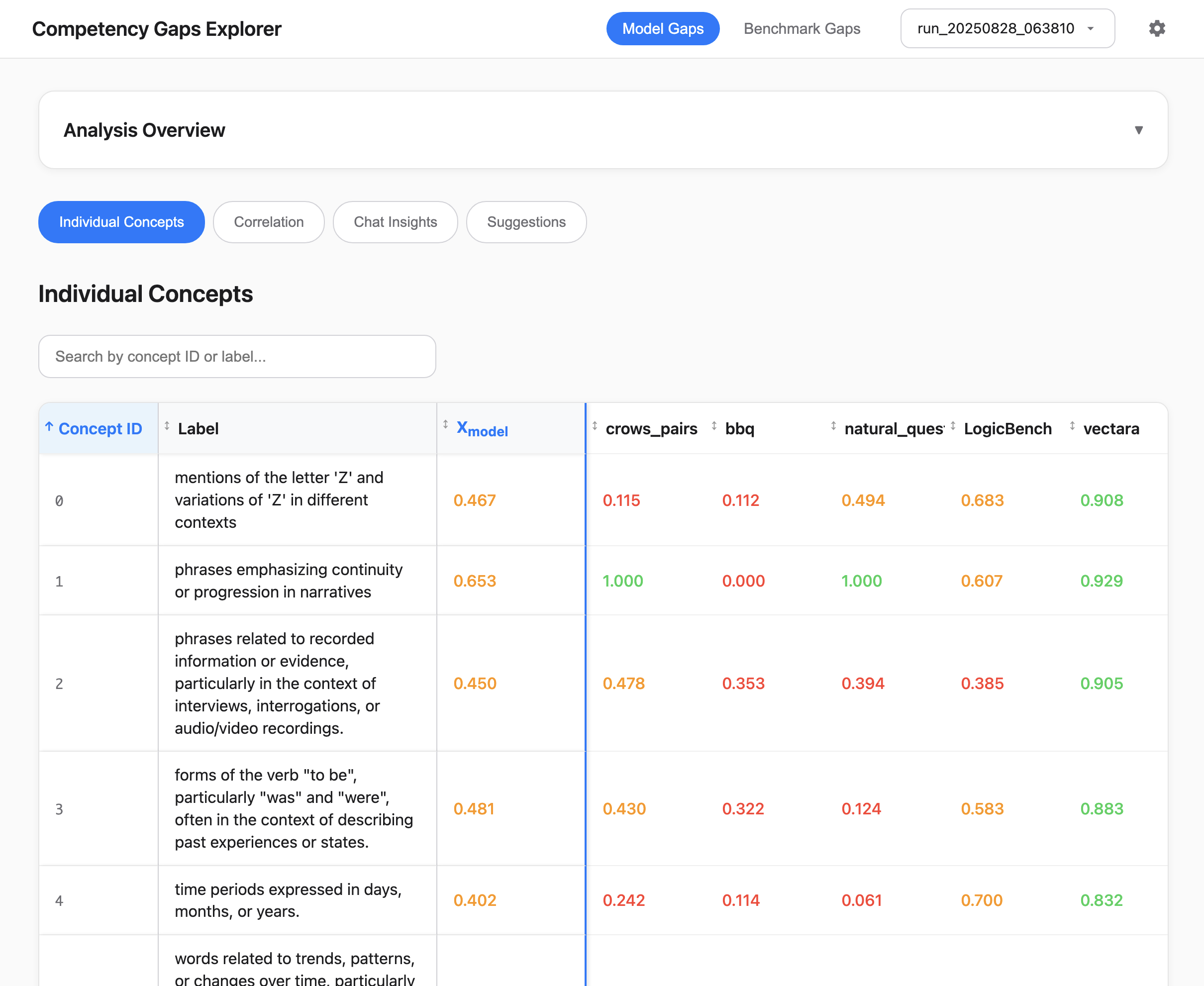
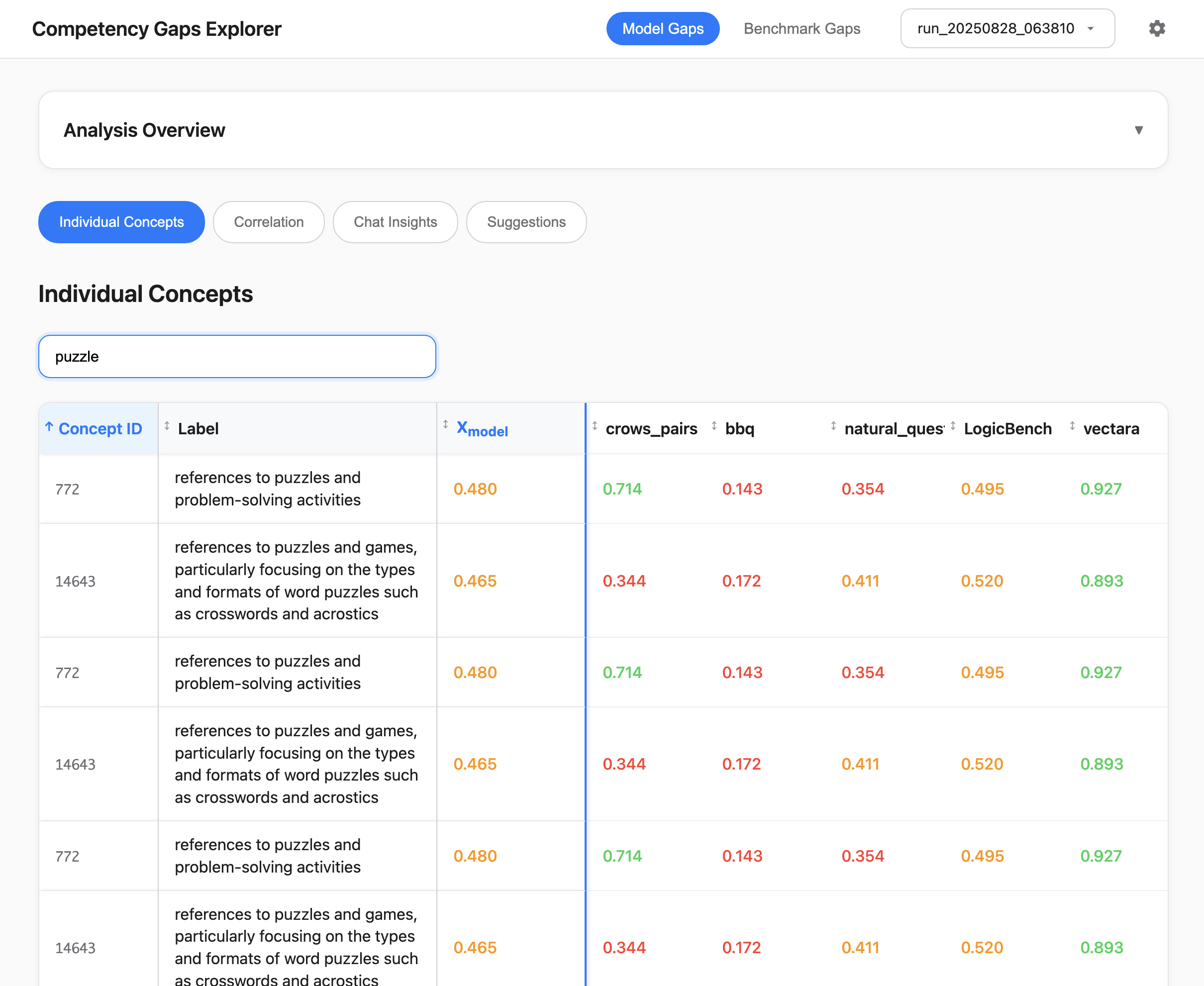
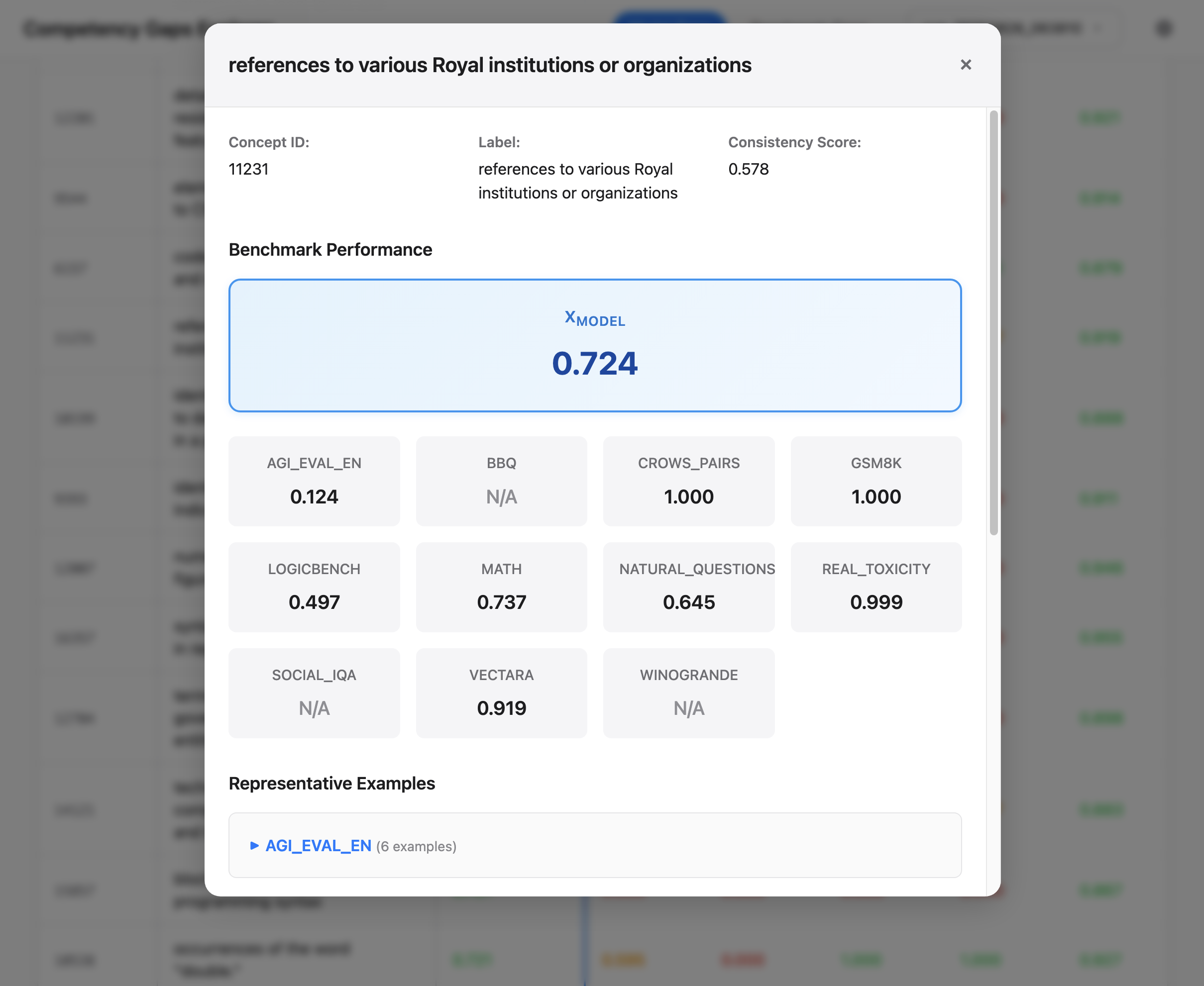
The evaluation of large language models (LLMs) relies heavily on standardized benchmarks. These benchmarks provide useful aggregated metrics for a given capability, but those aggregated metrics can obscure (i) particular sub-areas where the LLMs are weak ("model gaps") and (ii) imbalanced coverage in the benchmarks themselves ("benchmark gaps"). We propose a new method that uses sparse autoencoders (SAEs) to automatically uncover both types of gaps. By extracting SAE concept activations and computing saliency-weighted performance scores across benchmark data, the method grounds evaluation in the model's internal representations and enables comparison across benchmarks. As examples demonstrating our approach, we applied the method to two popular open-source models and ten benchmarks. We found that these models consistently underperformed on concepts that stand in contrast to sycophantic behaviors (e.g., politely refusing a request or asserting boundaries) and concepts connected to safety discussions. These model gaps align with observations previously surfaced in the literature; our automated, unsupervised method was able to recover them without manual supervision. We also observed benchmark gaps: many of the evaluated benchmarks over-represented concepts related to obedience, authority, or instruction-following, while missing core concepts that should fall within their intended scope. In sum, our method offers a representation-grounded approach to evaluation, enabling concept-level decomposition of benchmark scores. Rather than replacing conventional aggregated metrics, CG complements them by providing a concept-level decomposition that can reveal why a model scored as it did and how benchmarks could evolve to better reflect their intended scope. Code is available at https://competency-gaps.github.io.
💡 Deep Analysis
📄 Full Content
Pre-print. Under review.
UNCOVERING COMPETENCY GAPS IN LARGE
LANGUAGE MODELS AND THEIR BENCHMARKS
Matyas Bohacek1,2
Nino Scherrer2
Nicholas Dufour2
Thomas Leung2
Christoph Bregler2
Stephanie C. Y. Chan2
1Stanford University
2Google DeepMind
ABSTRACT
The evaluation of large language models (LLMs) relies heavily on standardized
benchmarks. These benchmarks provide useful aggregated metrics for a given
capability, but those aggregated metrics can obscure (i) particular sub-areas where
the LLMs are weak (“model gaps”) and (ii) imbalanced coverage in the benchmarks
themselves (“benchmark gaps”). We propose a new method that uses sparse au-
toencoders (SAEs) to automatically uncover both types of gaps. By extracting SAE
concept activations and computing saliency-weighted performance scores across
benchmark data, the method grounds evaluation in the model’s internal represen-
tations and enables comparison across benchmarks. As examples demonstrating
our approach, we applied the method to two popular open-source models and ten
benchmarks. We found that these models consistently underperformed on concepts
that stand in contrast to sycophantic behaviors (e.g., politely refusing a request or
asserting boundaries) and concepts connected to safety discussions. These model
gaps align with observations previously surfaced in the literature; our automated,
unsupervised method was able to recover them without manual supervision. We
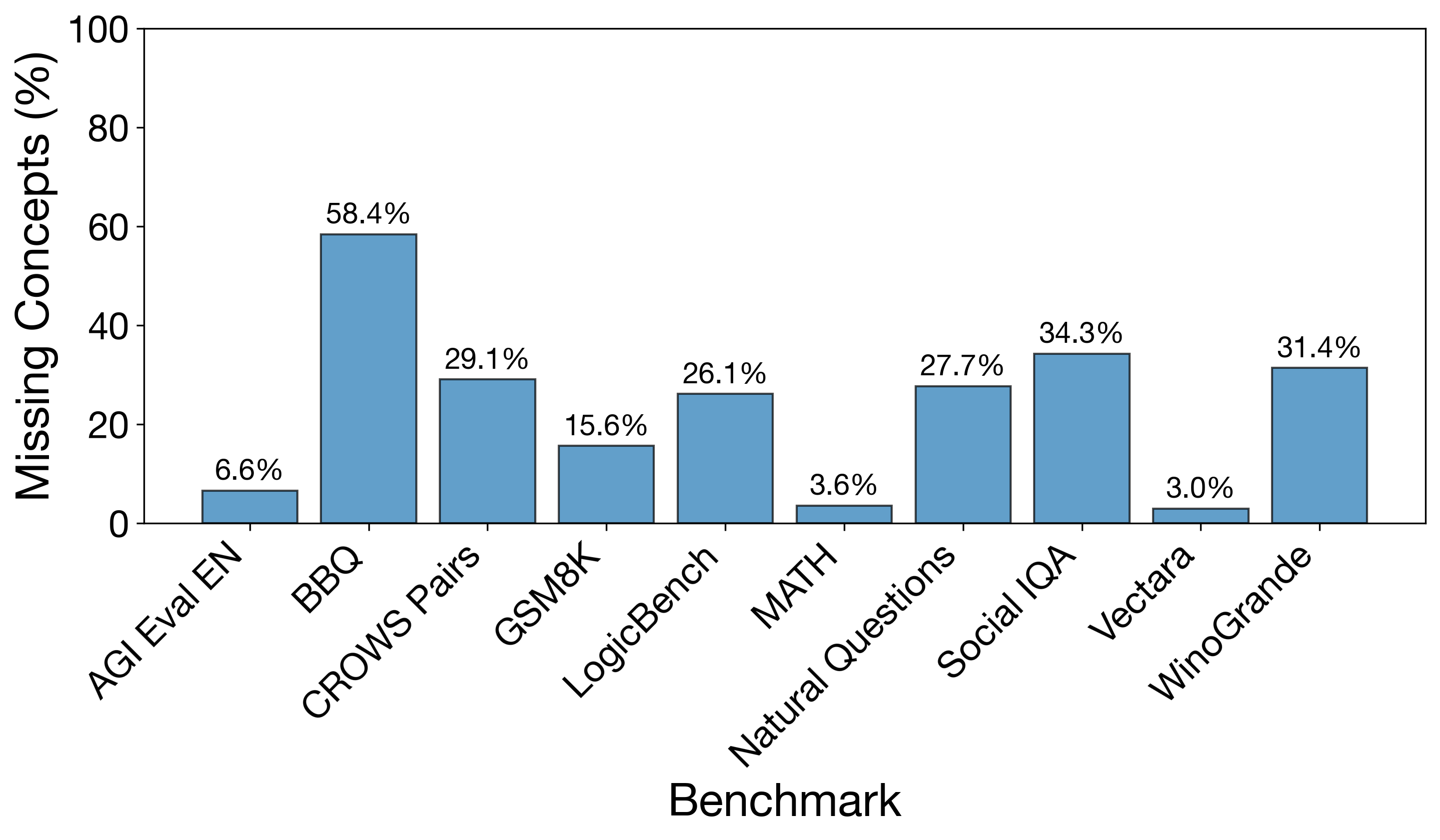
also observed benchmark gaps: many of the evaluated benchmarks over-represented
concepts related to obedience, authority, or instruction-following, while missing
core concepts that should fall within their intended scope. In sum, our method
offers a representation-grounded approach to evaluation, enabling concept-level de-
composition of benchmark scores. Rather than replacing conventional aggregated
metrics, CG complements them by providing a concept-level decomposition that
can reveal why a model scored as it did and how benchmarks could evolve to better
reflect their intended scope. Code is available at competency-gaps.github.io.
1
INTRODUCTION
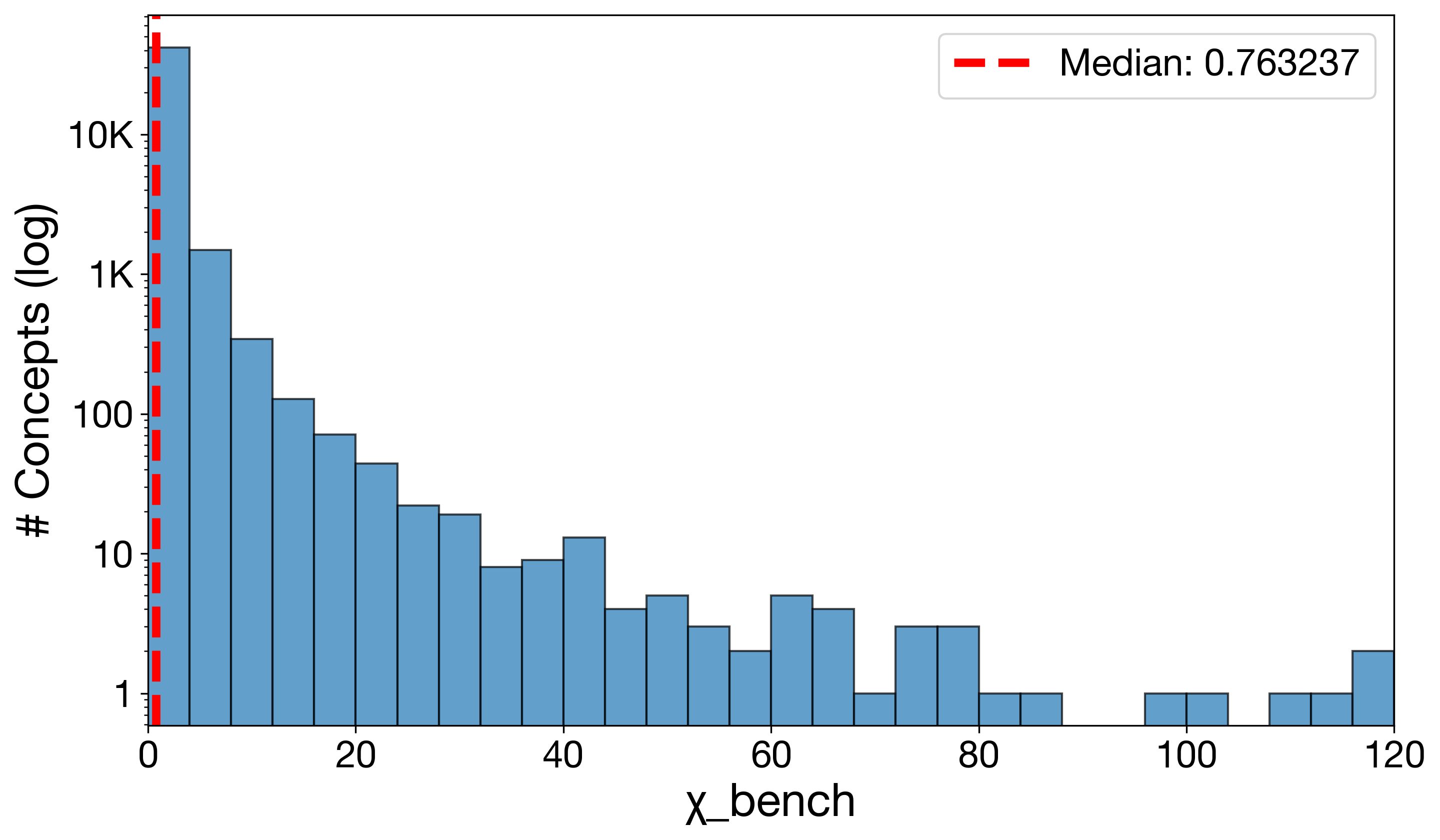
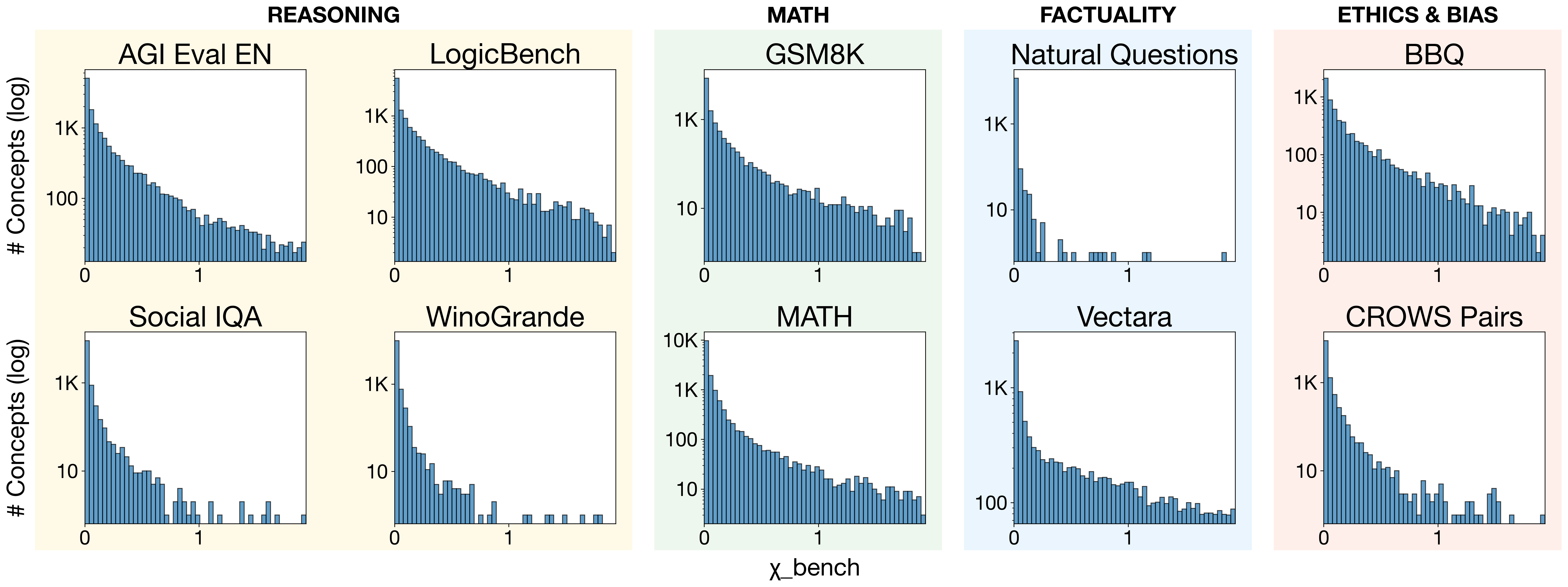
Evaluating large language models (LLMs) relies heavily on benchmarks that report aggregated scores
(e.g., accuracy or pass@k). Over the last decade, hundreds of benchmarks have been introduced
across diverse domains [Guo et al., 2023; Chang et al., 2024]. While these benchmarks have fueled
progress, uniform aggregation can obscure important sub-trends and mask model weaknesses [Hardt,
2025; Burnell et al., 2023]. For instance, Didolkar et al. [2024] disaggregated performance on
MATH [Hendrycks et al., 2021a] and found topic-wise scores ranging from 27% to 74%, despite
an overall score of 54%.
To counteract these aggregation issues, some benchmarks provide “semantic” topic annotations
(e.g., hand-curated topics in MATH [Hendrycks et al., 2021b] or GPQA [Rein et al., 2024], or
embedding-based clusters [Perez et al., 2023]). These high-level labels help characterize benchmark
distributions and disaggregate performance, but they are coarse-grained and offer limited insight
into model strengths and weaknesses. In particular, we lack a view of how finer-grained concepts,
contexts, and reasoning patterns extend beyond coarse topic labels and how they relate to real-world
model usage and capabilities [Miller and Tang, 2025; Mizrahi et al., 2024]. Furthermore, many
of these semantic annotations are manually curated and difficult to scale. Without a scalable,
fine-grained understanding of benchmark distributions, we risk overlooking benchmark gaps and
systematically overtesting certain concept types.
*Correspondence: maty@stanford.edu. Work carried out at Google DeepMind with the exception of
replication studies on Llama 3.1 and 3.3, which were performed exclusively using time and resources of Matyas
Bohacek at Stanford University.
1
arXiv:2512.20638v1 [cs.CL] 6 Dec 2025
Pre-print. Under review.
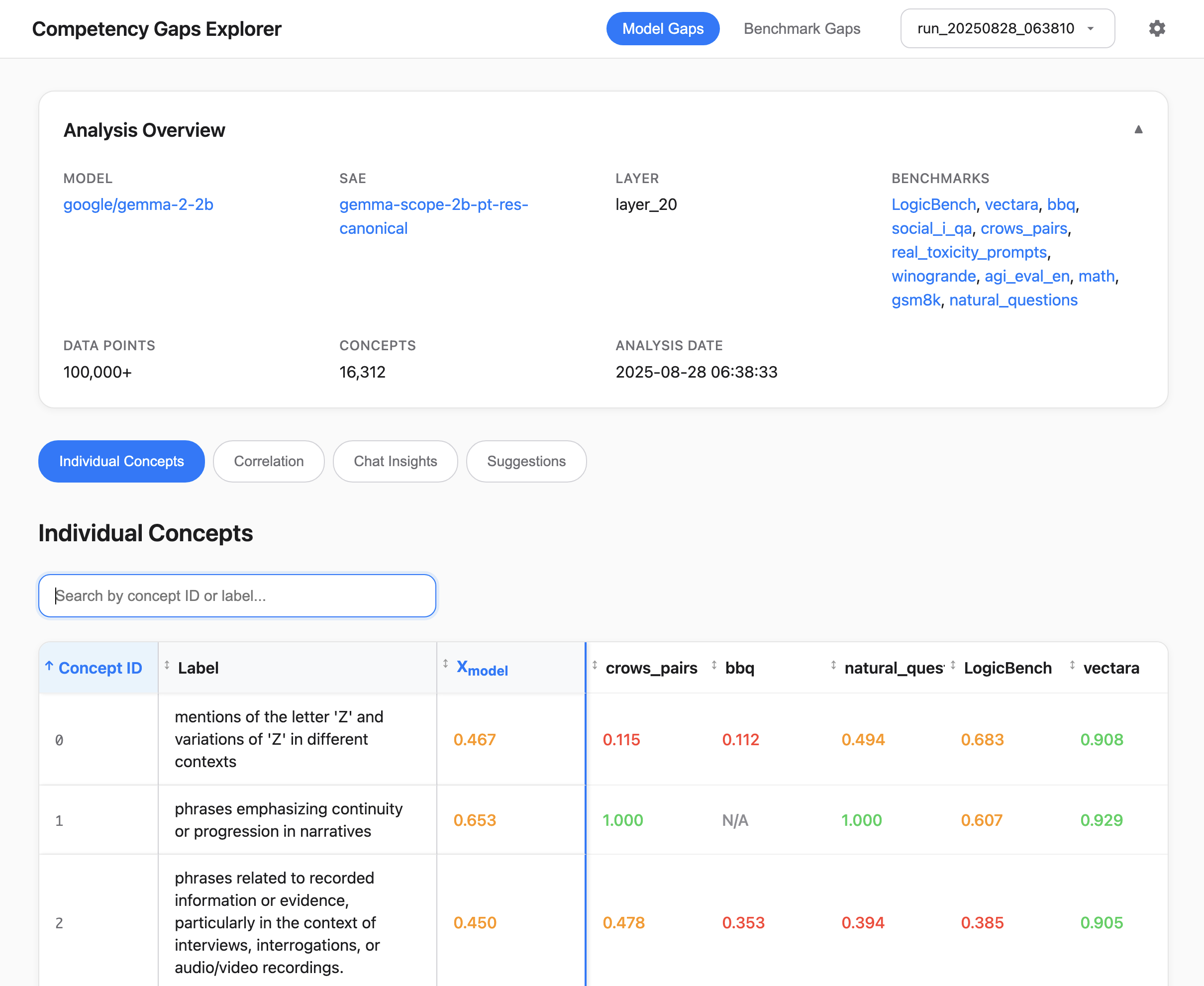
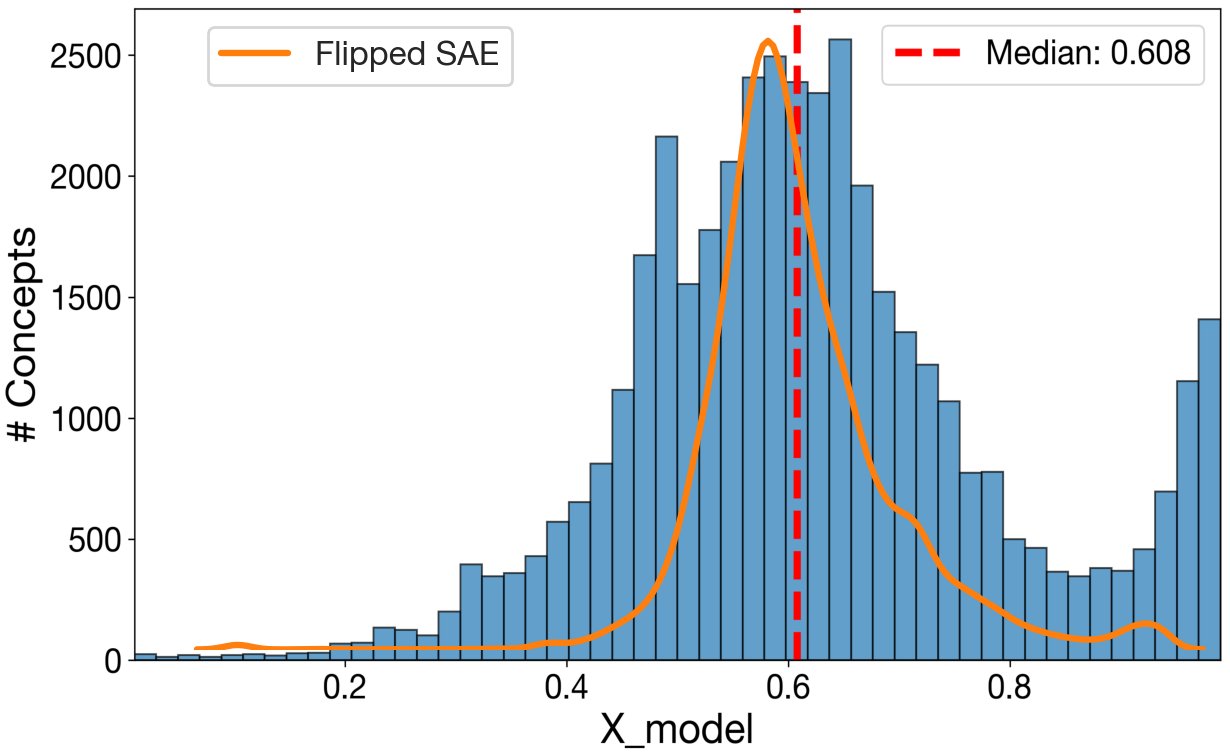
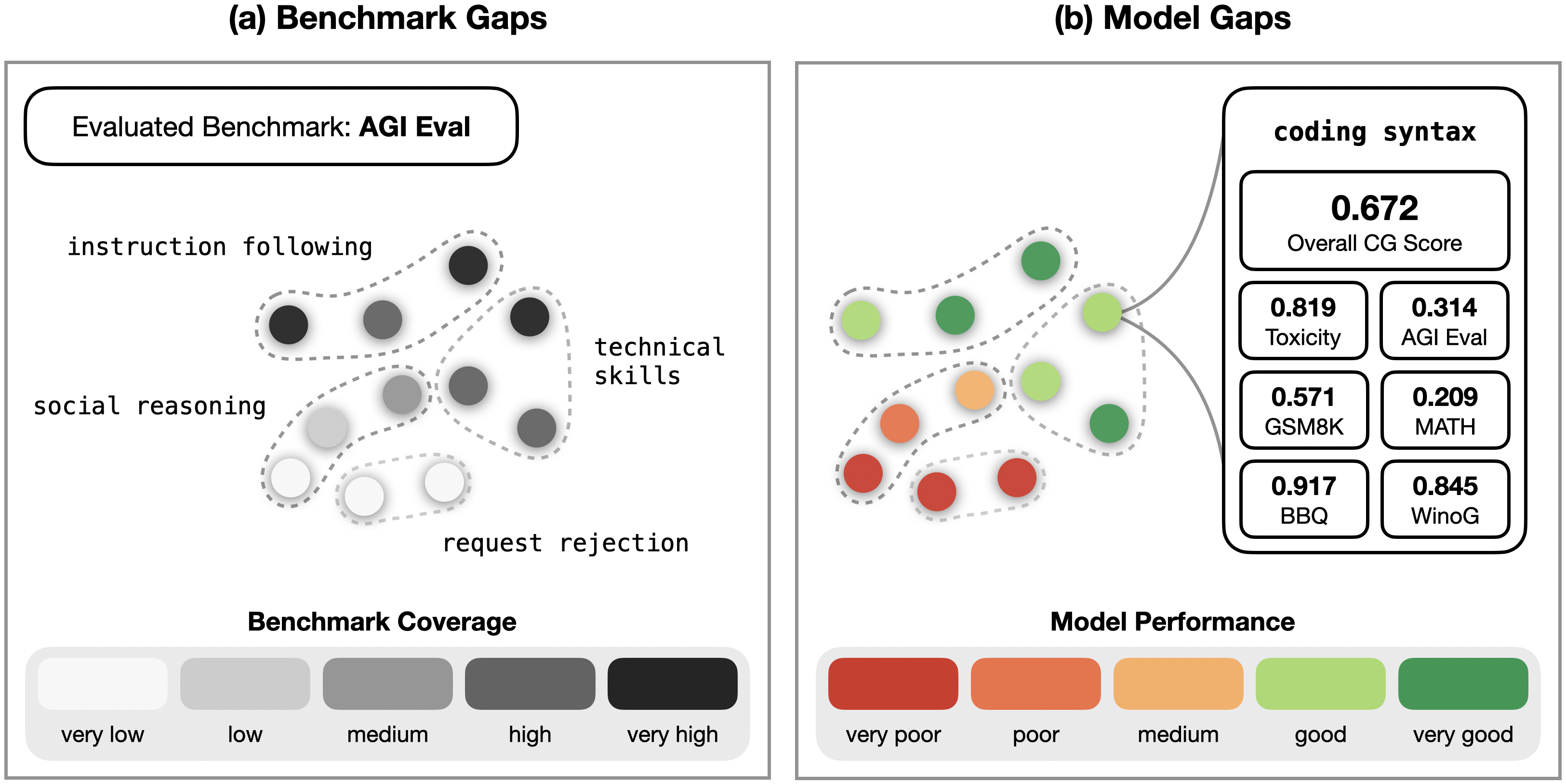
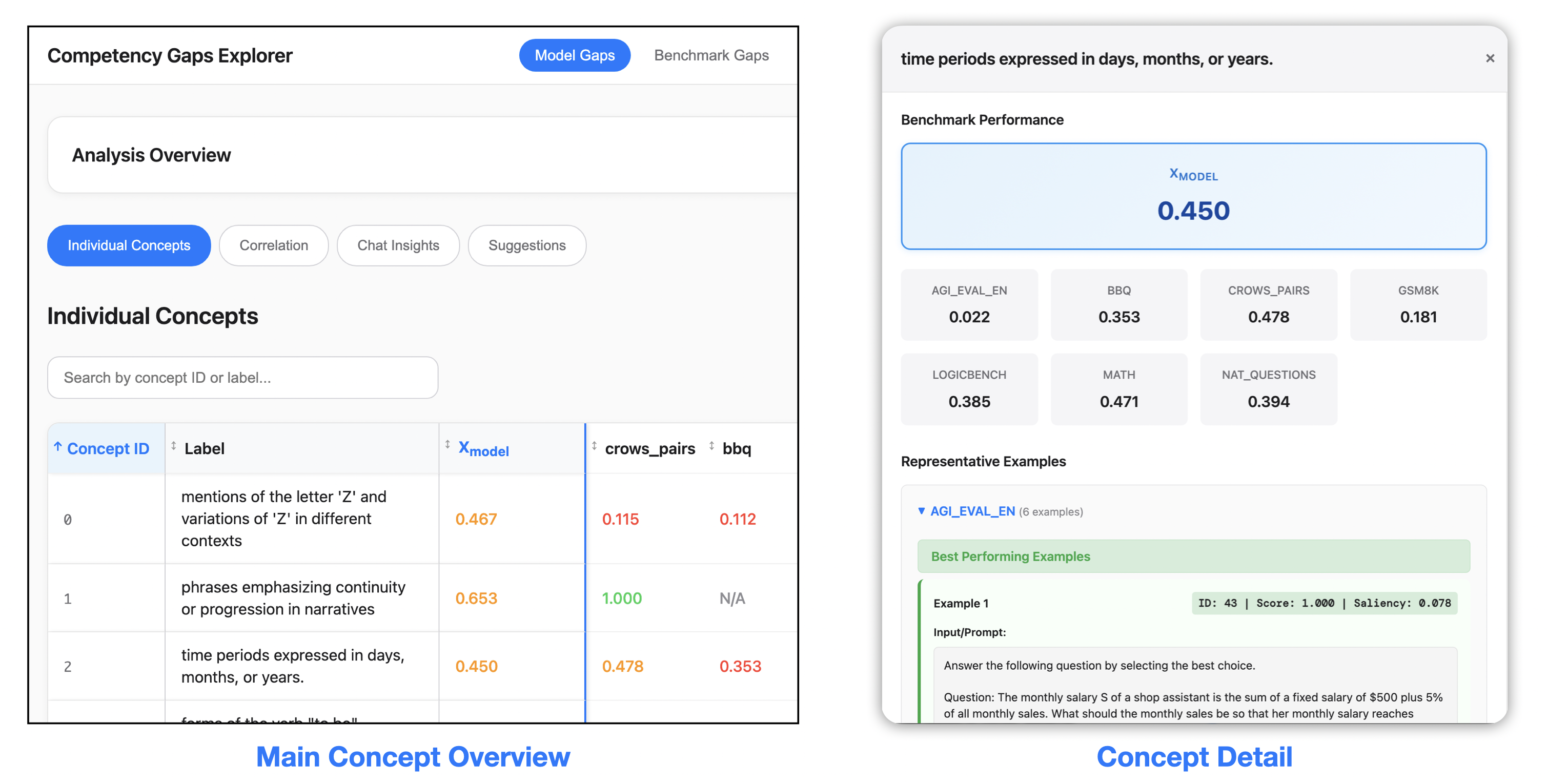
Figure 1: Competency Gaps (CG) Method Overview. CG decomposes LLM evaluation into
interpretable benchmark gaps and model gaps using the concept dictionary learned by a sparse
autoencoder (SAE), a subset of which is visualized above. (a) Benchmark Gaps quantify how much
benchmarks activate individual concepts and hence surface underrepresented regions. (b) Model Gaps
project model performance into concept space, yielding per-concept scores for individual benchmarks
and for entire multi-benchmark evaluation suites.
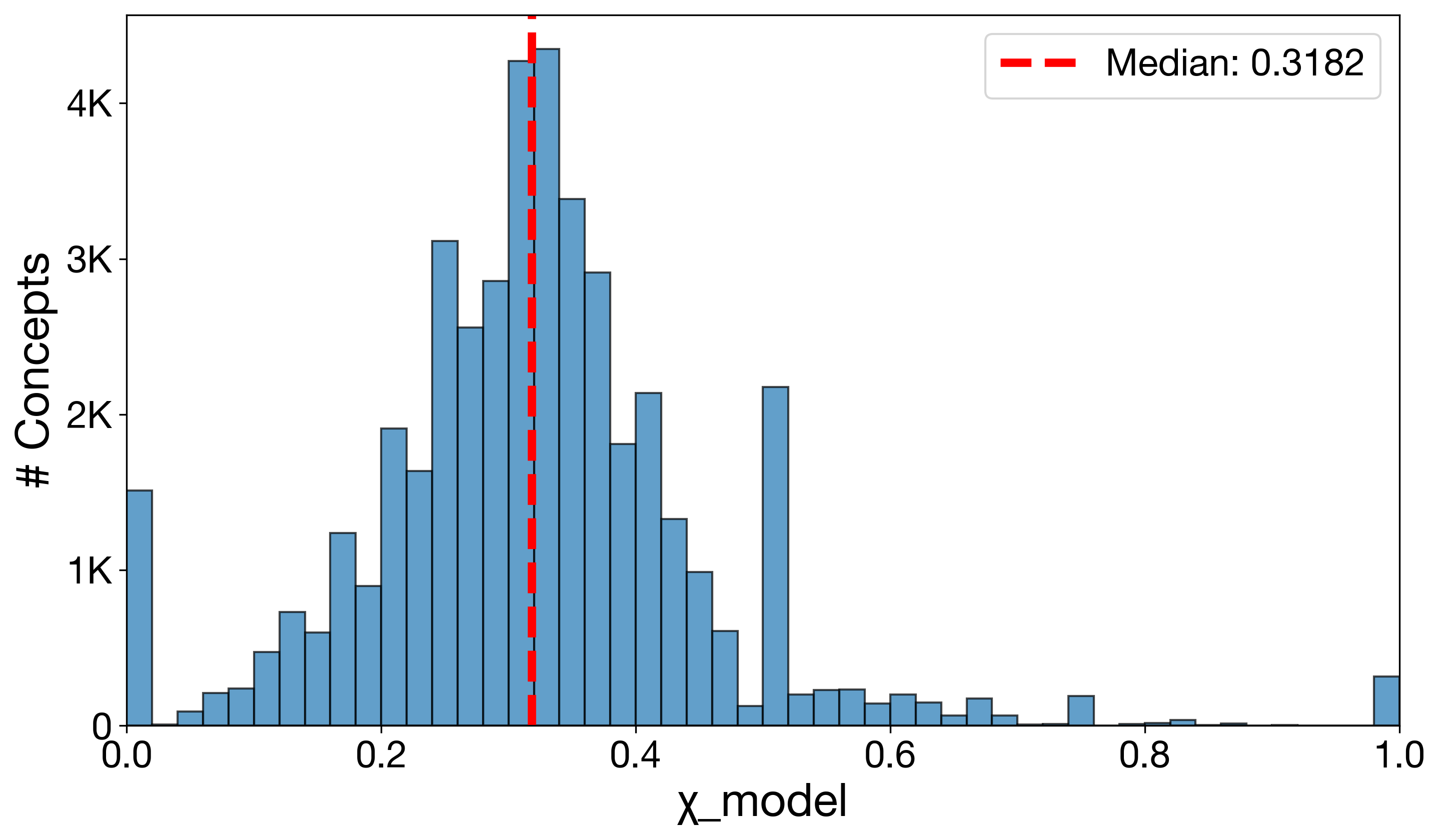
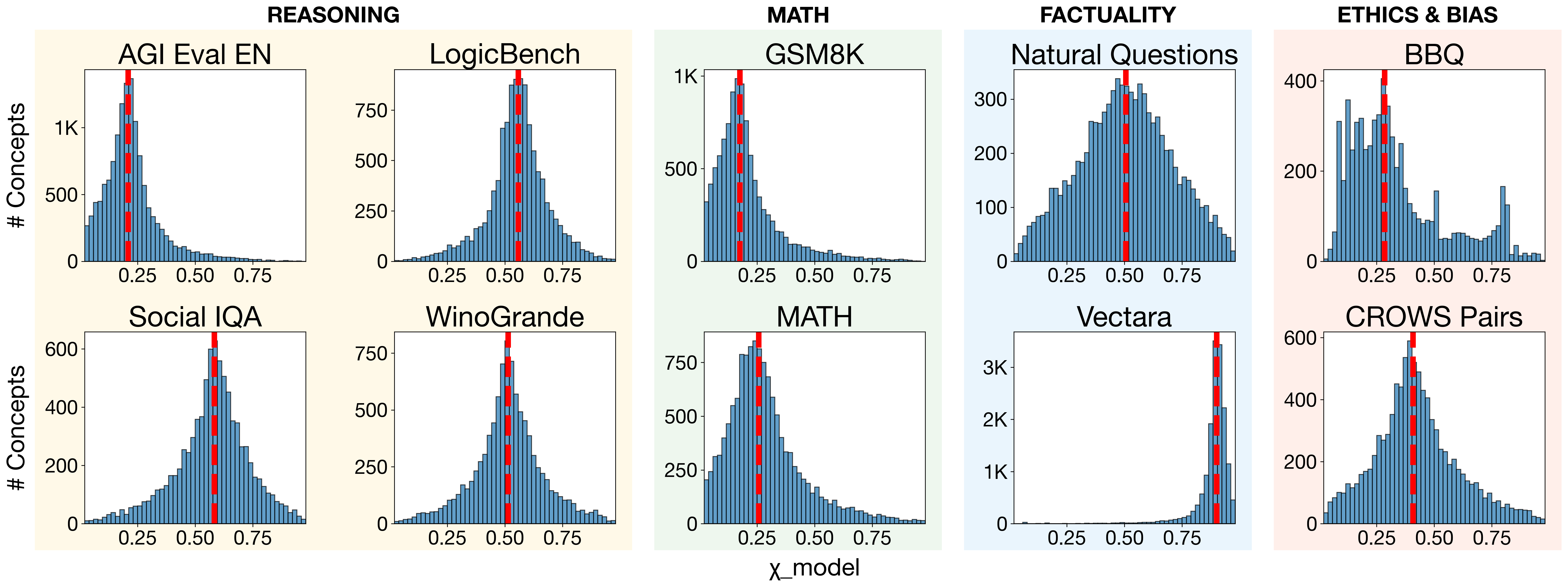
In this work, we are interested in the automated identification of two types of gaps: (i) benchmark
gaps, i.e., concept domains that are inadequately represented in an evaluation dataset, and (ii) model
gaps, i.e., concept domains where models systematically underperform (see Figure 1). To this end,
we introduce a new method called Competency Gaps (CG). Therein, we leverage sparse autoencoders
(SAEs), which transform dense internal representations of a scrutinized LLM into high-dimensional,
sparse feature vectors called SAE concept activations [Bricken et al.,