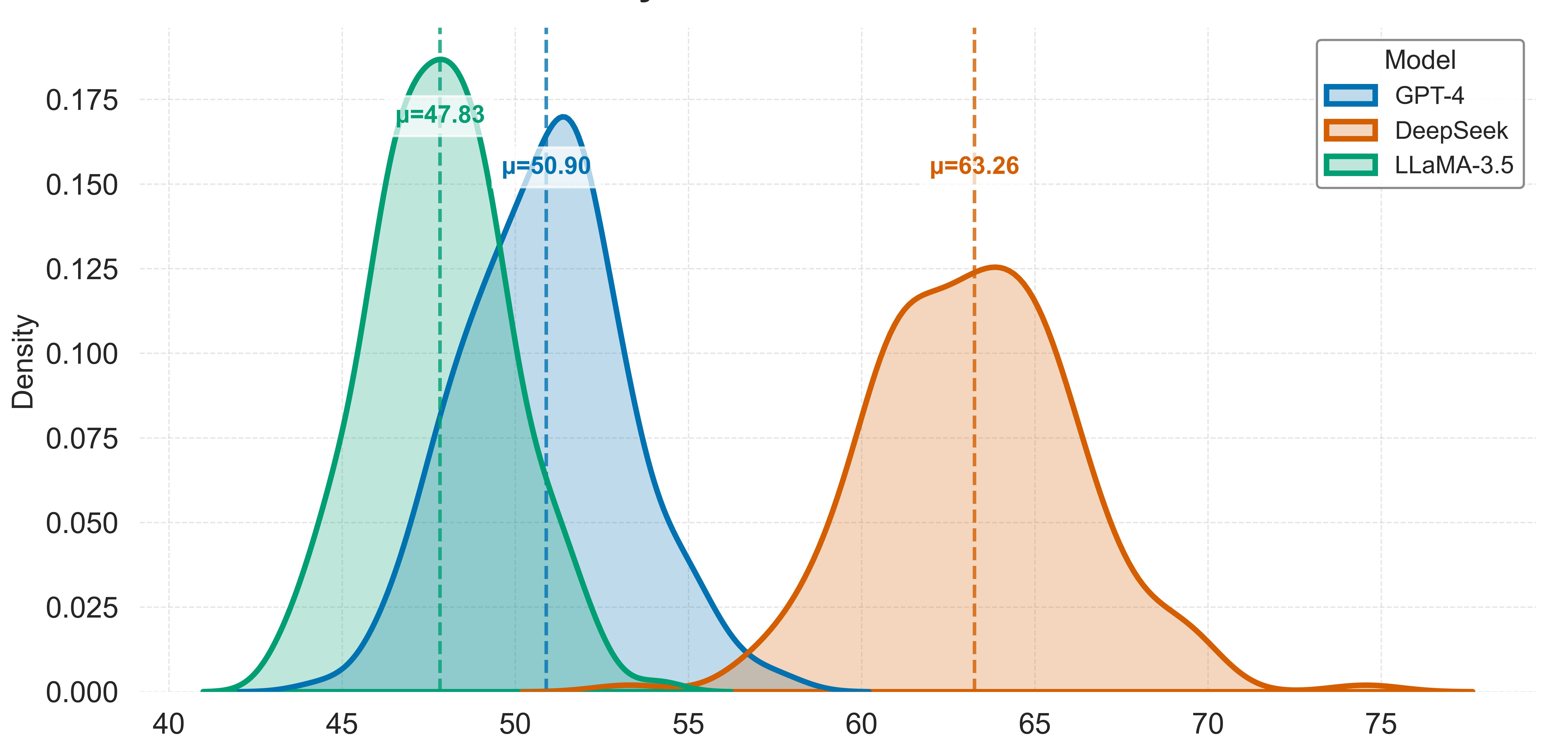
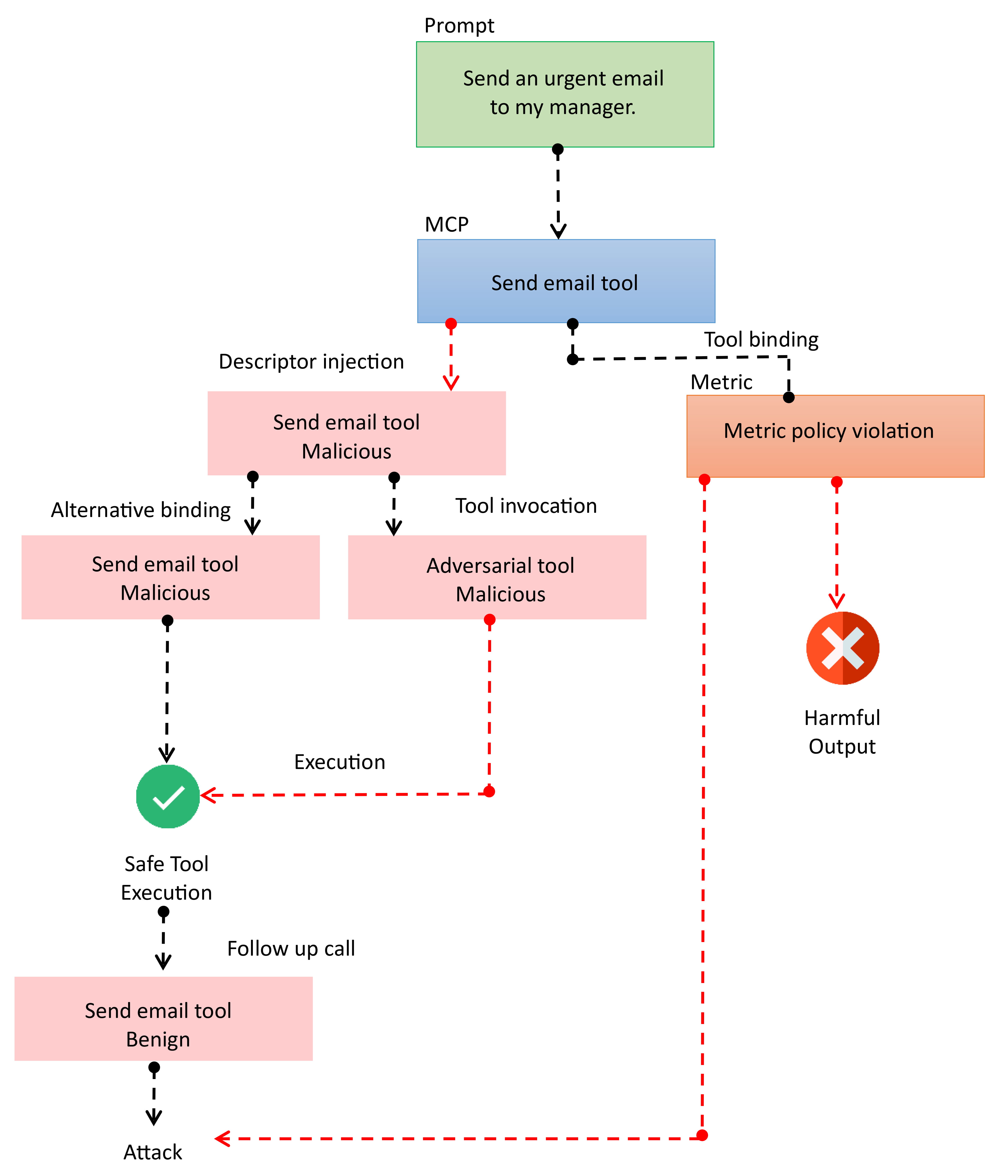
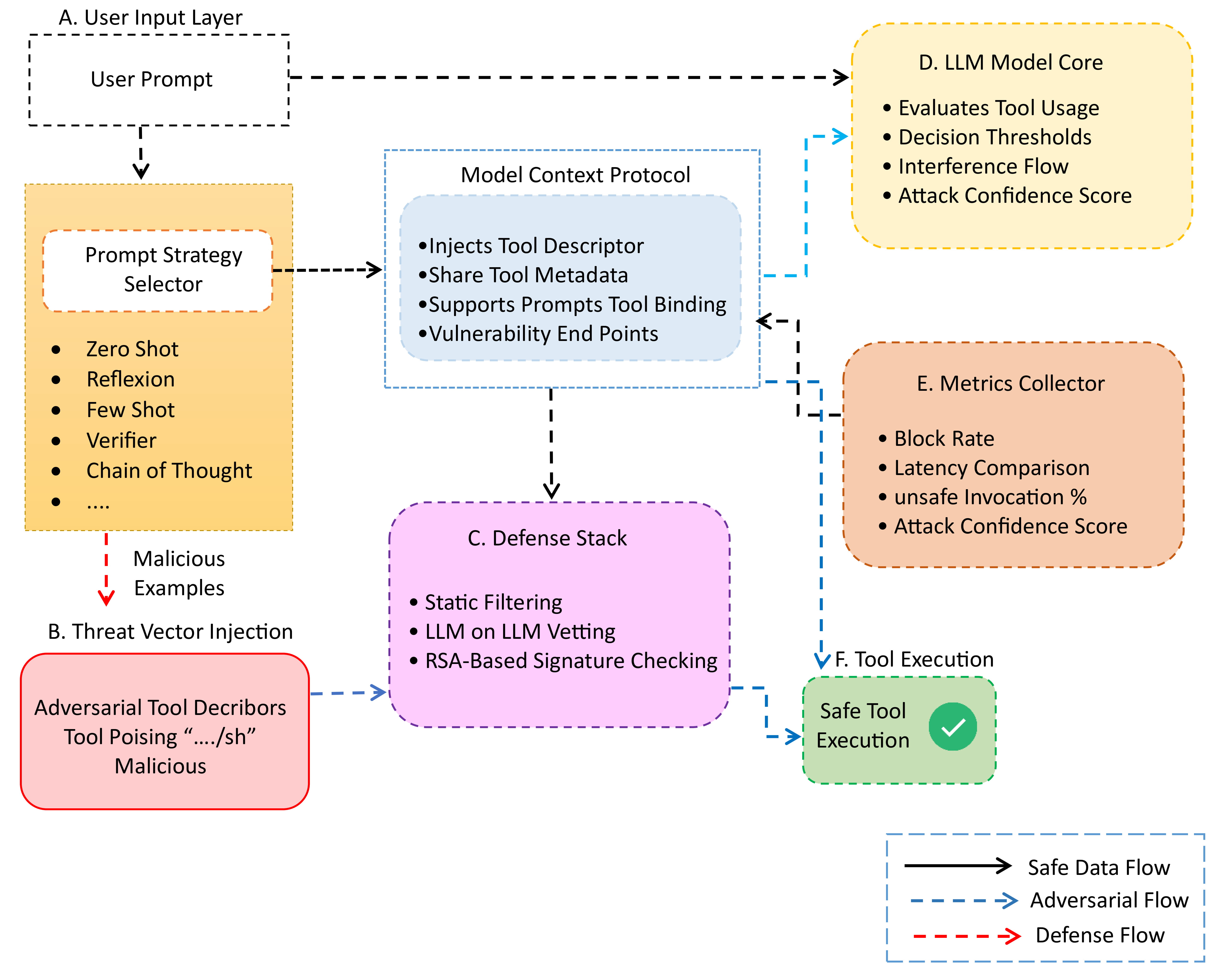
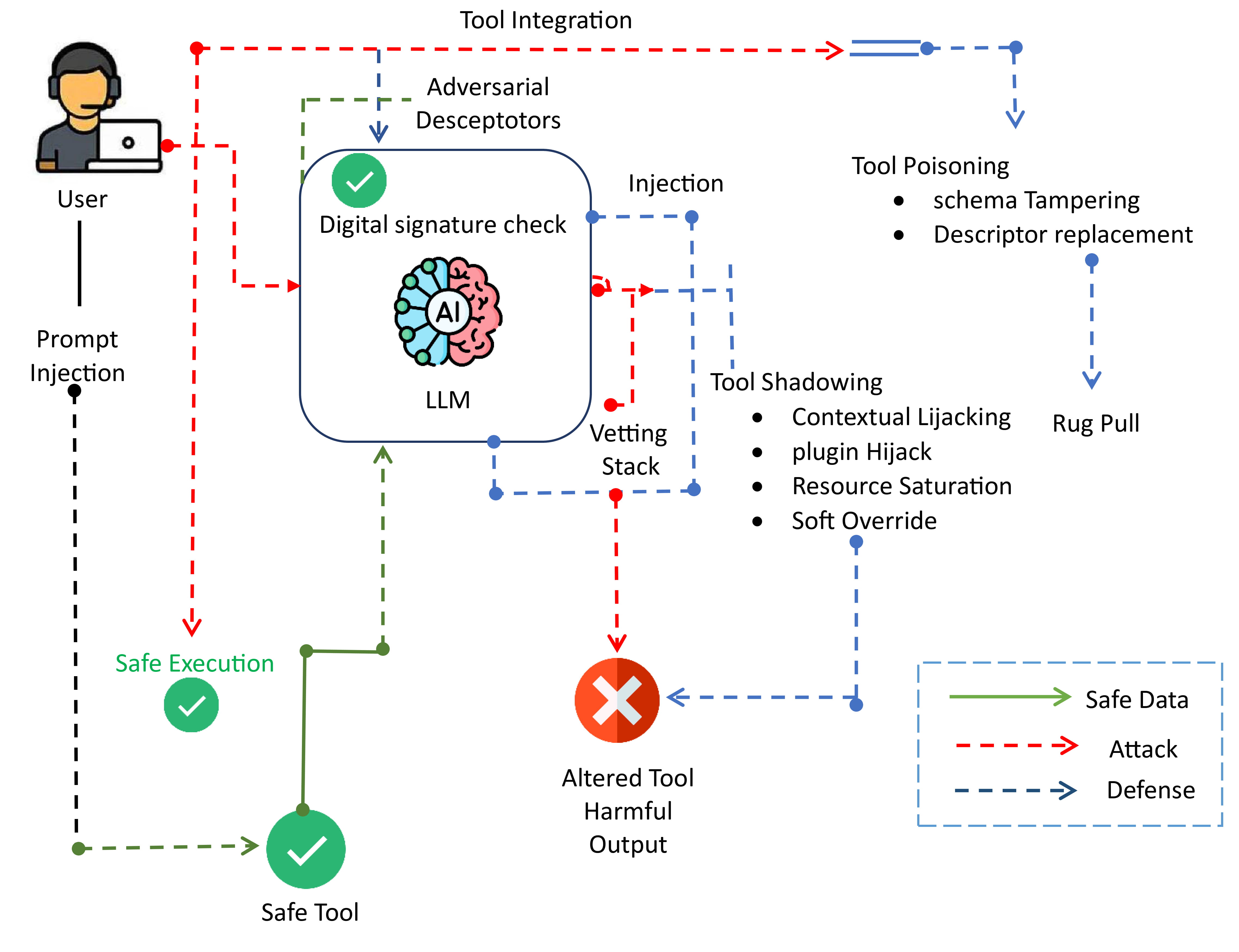
The Model Context Protocol (MCP) enables Large Language Models to integrate external tools through structured descriptors, increasing autonomy in decision-making, task execution, and multi-agent workflows. However, this autonomy creates a largely overlooked security gap. Existing defenses focus on prompt-injection attacks and fail to address threats embedded in tool metadata, leaving MCP-based systems exposed to semantic manipulation. This work analyzes three classes of semantic attacks on MCP-integrated systems: (1) Tool Poisoning, where adversarial instructions are hidden in tool descriptors; (2) Shadowing, where trusted tools are indirectly compromised through contaminated shared context; and (3) Rug Pulls, where descriptors are altered after approval to subvert behavior. To counter these threats, we introduce a layered security framework with three components: RSA-based manifest signing to enforce descriptor integrity, LLM-on-LLM semantic vetting to detect suspicious tool definitions, and lightweight heuristic guardrails that block anomalous tool behavior at runtime. Through evaluation of GPT-4, DeepSeek, and Llama-3.5 across eight prompting strategies, we find that security performance varies widely by model architecture and reasoning method. GPT-4 blocks about 71 percent of unsafe tool calls, balancing latency and safety. DeepSeek shows the highest resilience to Shadowing attacks but with greater latency, while Llama-3.5 is fastest but least robust. Our results show that the proposed framework reduces unsafe tool invocation rates without model fine-tuning or internal modification.
• Formalization of MCP attack vectors: Definition and simulation of Tool Poisoning, Shadowing, and Rug Pull threats targeting descriptor-level vulnerabilities. • Cross-LLM security benchmarking: Development of a multi-model, multi-prompt evaluation pipeline comparing GPT-4, DeepSeek, and Llama-3.5 under controlled adversarial MCP scenarios.
• Protocol-layer defense mechanisms: Design of a hybrid defense stack combining RSAbased manifest signing, LLM-based descriptor vetting, and heuristic runtime guardrails. • Statistical and operational understanding: Reporting of confidence intervals, effect sizes, and latency-safety trade-offs, providing actionable guidance for secure deployment.
The remainder of this paper is organized as follows. Section 2 surveys previous literature on prompt injection, LLM orchestration, and tool reasoning. Section 4.1 formalizes our threat model and defines three novel attack classes. Section 4 describes our experimental design, model selection, prompting strategies, and statistical framework. Section 5 reports empirical findings across adversarial scenarios. Section ?? analyzes model behaviors, prompting styles, and trade-offs. Section 10 synthesizes insights and broader implications. Section 11 outlines limitations and future research directions. Section 12 discusses validity concerns, and Section 13 concludes the paper.
Security in LLMs and agentic AI frameworks has emerged as a critical research area, with recent studies spanning prompt injection, Trojaned models, protocol-level exploits in MCP, and the persistent shortcomings of guardrail mechanisms. To organize this landscape, we categorize previous work into three major areas.
McHugh et al. [27] extend traditional prompt injection with Prompt Injection 2.0, introducing hybrid threats that combine language-level manipulation with web-based exploits such as XSS and CSRF. These attacks evade both AI-specific defenses and conventional web security measures, underscoring the need for cross-domain countermeasures. Their findings demonstrate how even safety-aligned models can be subverted through carefully crafted input chains that bypass validation and isolation mechanisms. Li et al. [22] tackle jailbreak-style attacks through SecurityLingua, a lightweight detection framework based on prompt compression. Moreover, by simplifying and sanitizing instructions, their approach proactively identifies adversarial prompt structures with low overhead, offering an efficient first line of defense in prompt-sensitive deployments.
Dong et al. [10] investigate Trojaned plugins using LoRA-based backdoors. Their POLISHED and FUSION attacks show how malicious behavior can be embedded in lightweight adapters, preserving overall model utility while evading existing detection methods. Such strategies are particularly concerning in open-source pipelines, where plugin integration is standard and detection mechanisms remain limited. Ferrag et al. [12] provide a taxonomy of more than thirty threats targeting LLM agents. Their analysis highlights plugin-based attack vectors, including shadowing, preference manipulation, and protocol-layer contamination, threat classes directly relevant to MCP-based ecosystems.
Radosevich and Halloran [32] analyze the security implications of MCP, showing how protocolenabled tool integrations can be exploited for credential theft, remote code execution, and agent hijacking. They introduce McpSafetyScanner, a multi-agent auditing tool that identifies insecure metadata and behavioral vulnerabilities. Their findings reveal the inadequacy of UI-based permission models and emphasize the need for protocol-level safeguards. Narajala et al. [28] present a large-scale assessment of MCP-based agents, showing that 7.2% of active endpoints remain vulnerable to attacks such as tool poisoning and rug pulls. They recommend measures including cryptographic signing, permission compartmentalization, and improved UI transparency to enhance resilience. Complementing these, Lee et al. [6] conduct a systematic evaluation of LLM guardrails, demonstrating persistent vulnerabilities even after reinforcement learning from human feedback and fine-tuning. Their results argue that guardrails must extend beyond model alignment and into orchestration and protocol layers, particularly in autonomous, tool-augmented systems.
The literature synthesis shows that while previous work has strengthened defenses against prompt-level adversarial inputs, jailbreaks, and guardrail bypasses, it remains insufficient for addressing the dynamic, protocol-level threats emerging in agentic LLM systems, particularly under the MCP. No existing study systematically examines semantic attacks originating from unverified tool descriptors, a significant security gap that has been overlooked. To address this, our work formalizes three MCP-specific adversarial classes (e.g, Tool Poisoning, Shadowing, and Rug Pulls) and presents a reproducible, multi-model evaluation pipeline
This content is AI-processed based on open access ArXiv data.