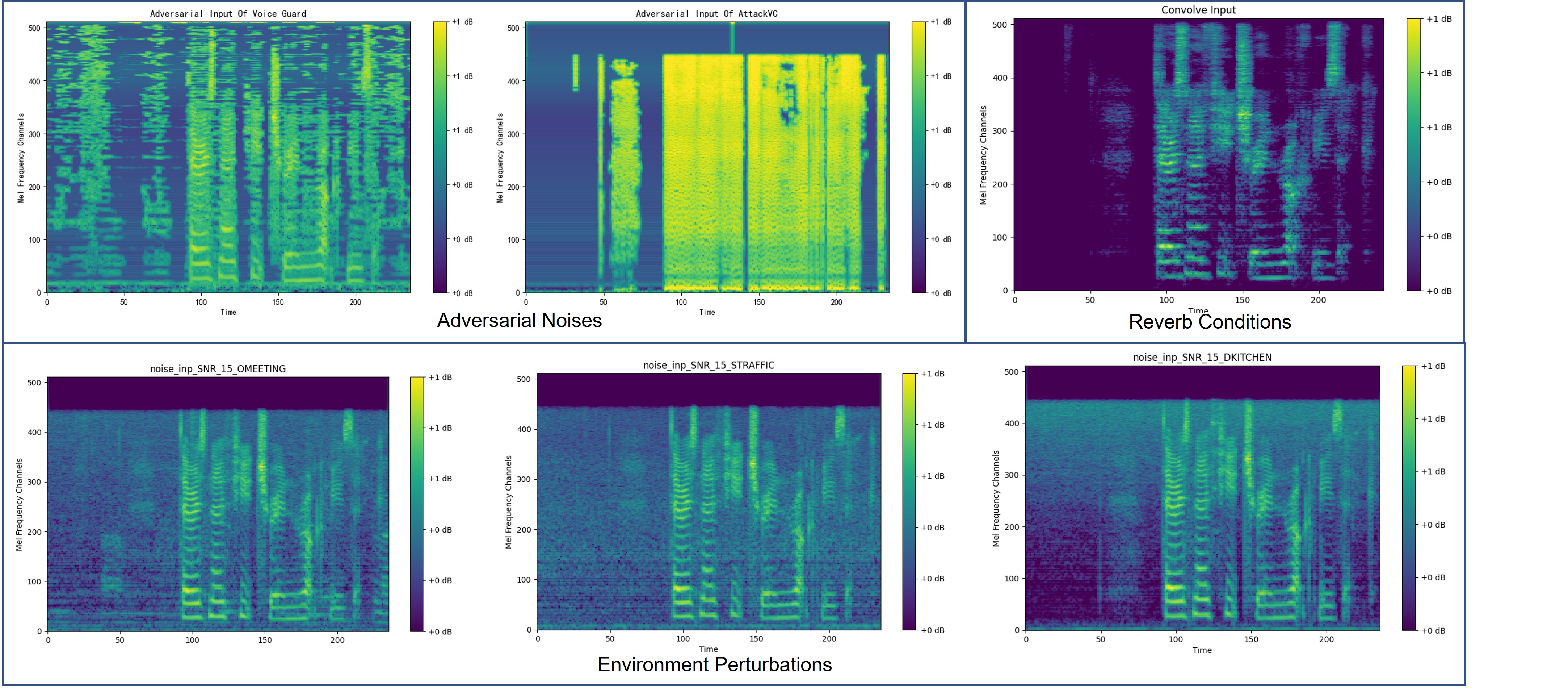
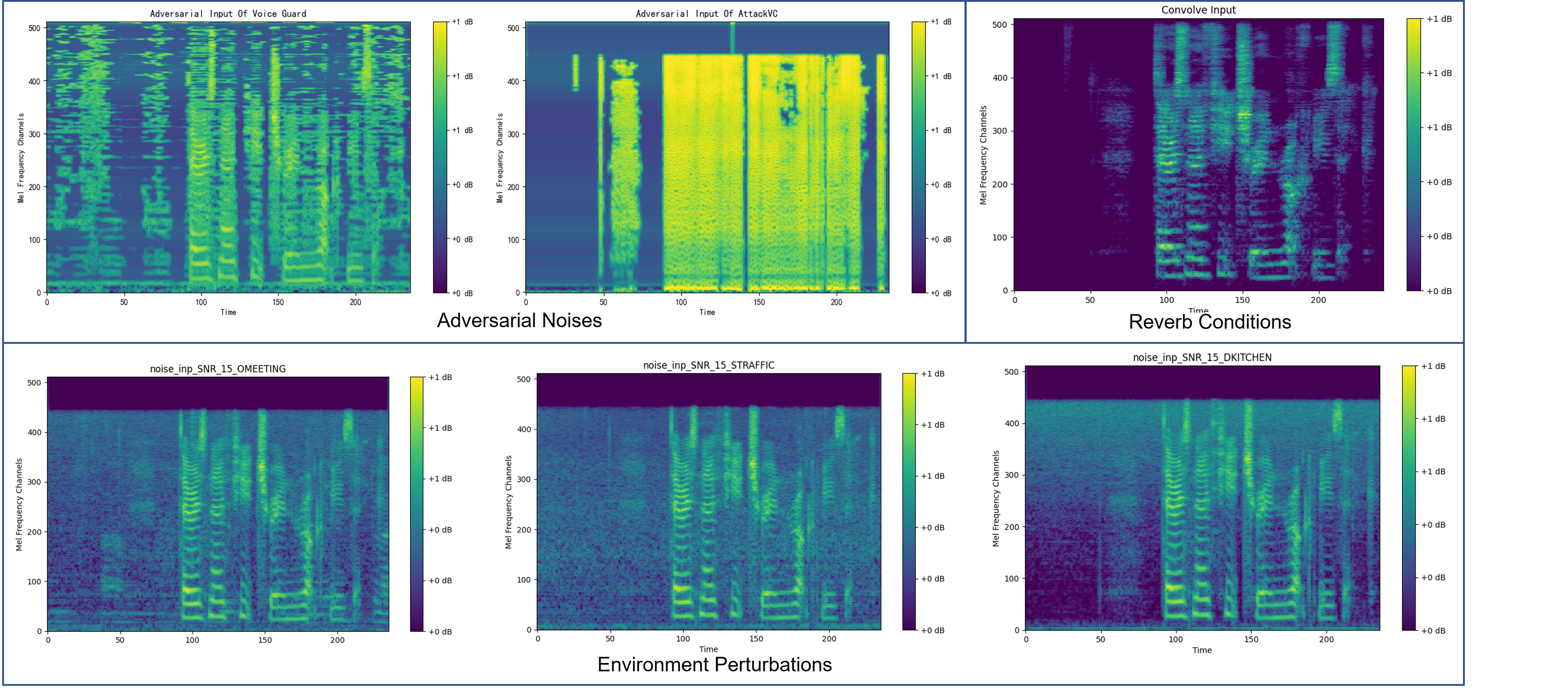
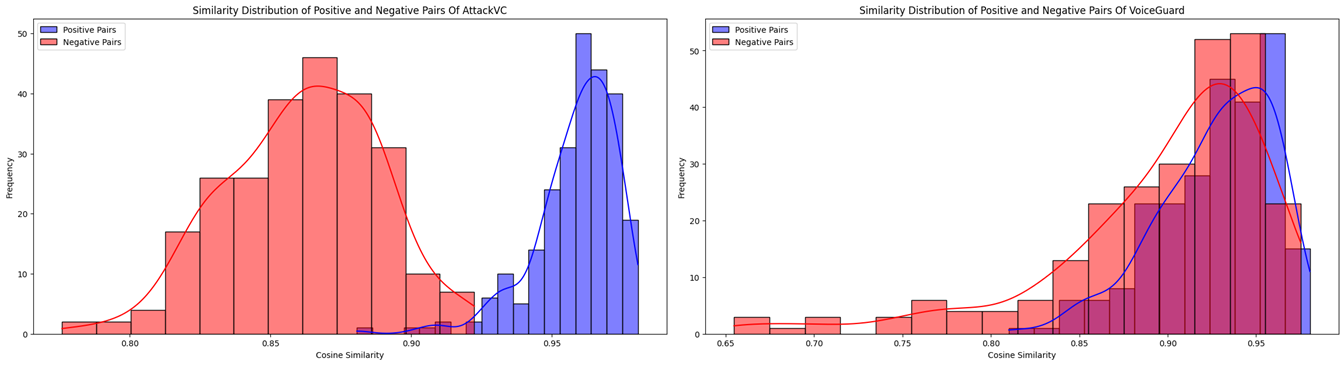
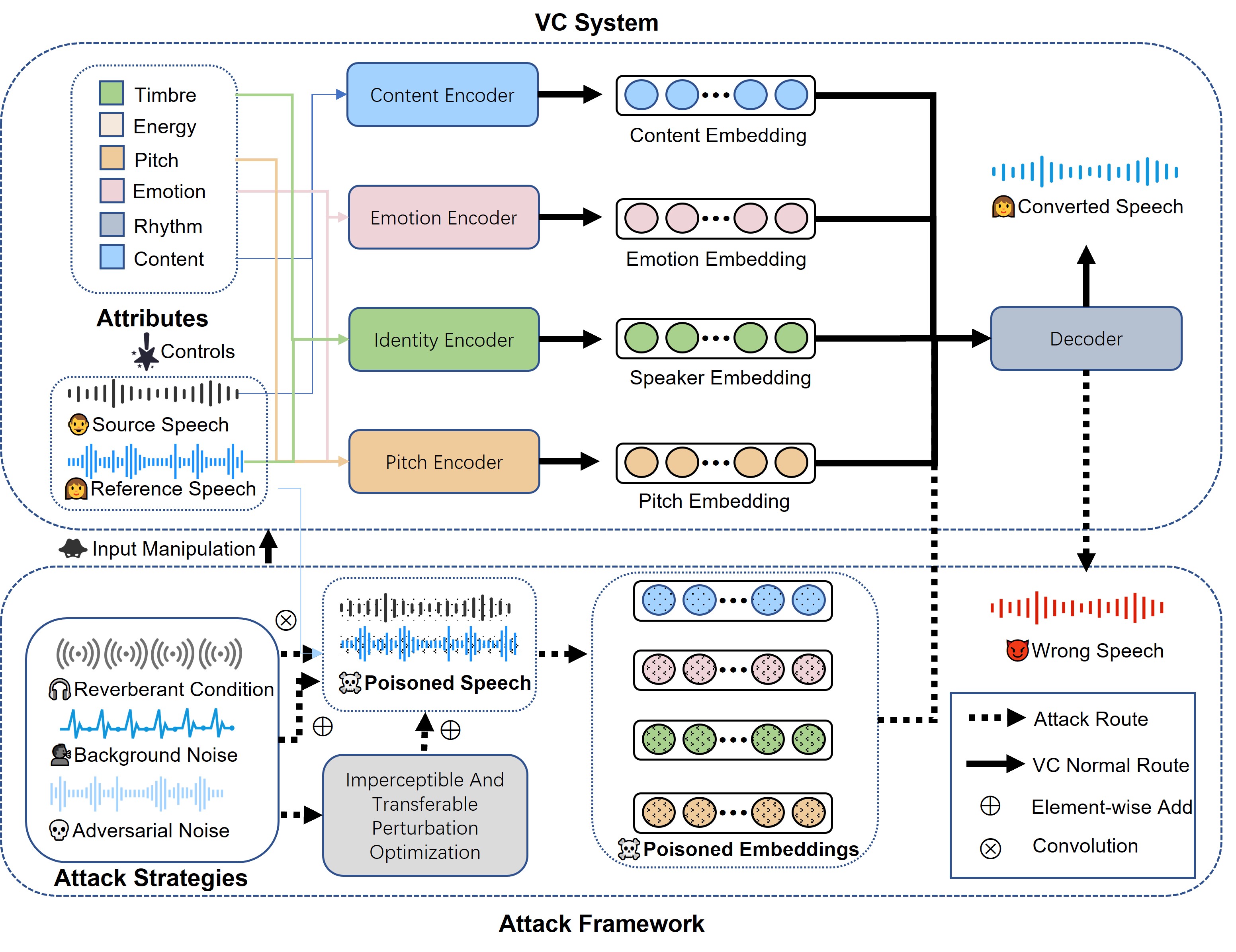
Identity, accent, style, and emotions are essential components of human speech. Voice conversion (VC) techniques process the speech signals of two input speakers and other modalities of auxiliary information such as prompts and emotion tags. It changes para-linguistic features from one to another, while maintaining linguistic contents. Recently, VC models have made rapid advancements in both generation quality and personalization capabilities. These developments have attracted considerable attention for diverse applications, including privacy preservation, voice-print reproduction for the deceased, and dysarthric speech recovery. However, these models only learn non-robust features due to the clean training data. Subsequently, it results in unsatisfactory performances when dealing with degraded input speech in real-world scenarios, including additional noise, reverberation, adversarial attacks, or even minor perturbation. Hence, it demands robust deployments, especially in real-world settings. Although latest researches attempt to find potential attacks and countermeasures for VC systems, there remains a significant gap in the comprehensive understanding of how robust the VC model is under input manipulation. here also raises many questions: For instance, to what extent do different forms of input degradation attacks alter the expected output of VC models? Is there potential for optimizing these attack and defense strategies? To answer these questions, we classify existing attack and defense methods from the perspective of input manipulation and evaluate the impact of degraded input speech across four dimensions, including intelligibility, naturalness, timbre similarity, and subjective perception. Finally, we outline open issues and future directions.