Smart farming has emerged as a key technology for advancing modern agriculture through automation and intelligent control. However, systems relying on RGB cameras for perception and robotic manipulators for control, common in smart farming, are vulnerable to photometric perturbations such as hue, illumination, and noise changes, which can cause malfunction under adversarial attacks. To address this issue, we propose an explainable adversarial-robust Vision-Language-Action model based on the OpenVLA-OFT framework. The model integrates an Evidence-3 module that detects photometric perturbations and generates natural language explanations of their causes and effects. Experiments show that the proposed model reduces Current Action L1 loss by 21.7% and Next Actions L1 loss by 18.4% compared to the baseline, demonstrating improved action prediction accuracy and explainability under adversarial conditions.
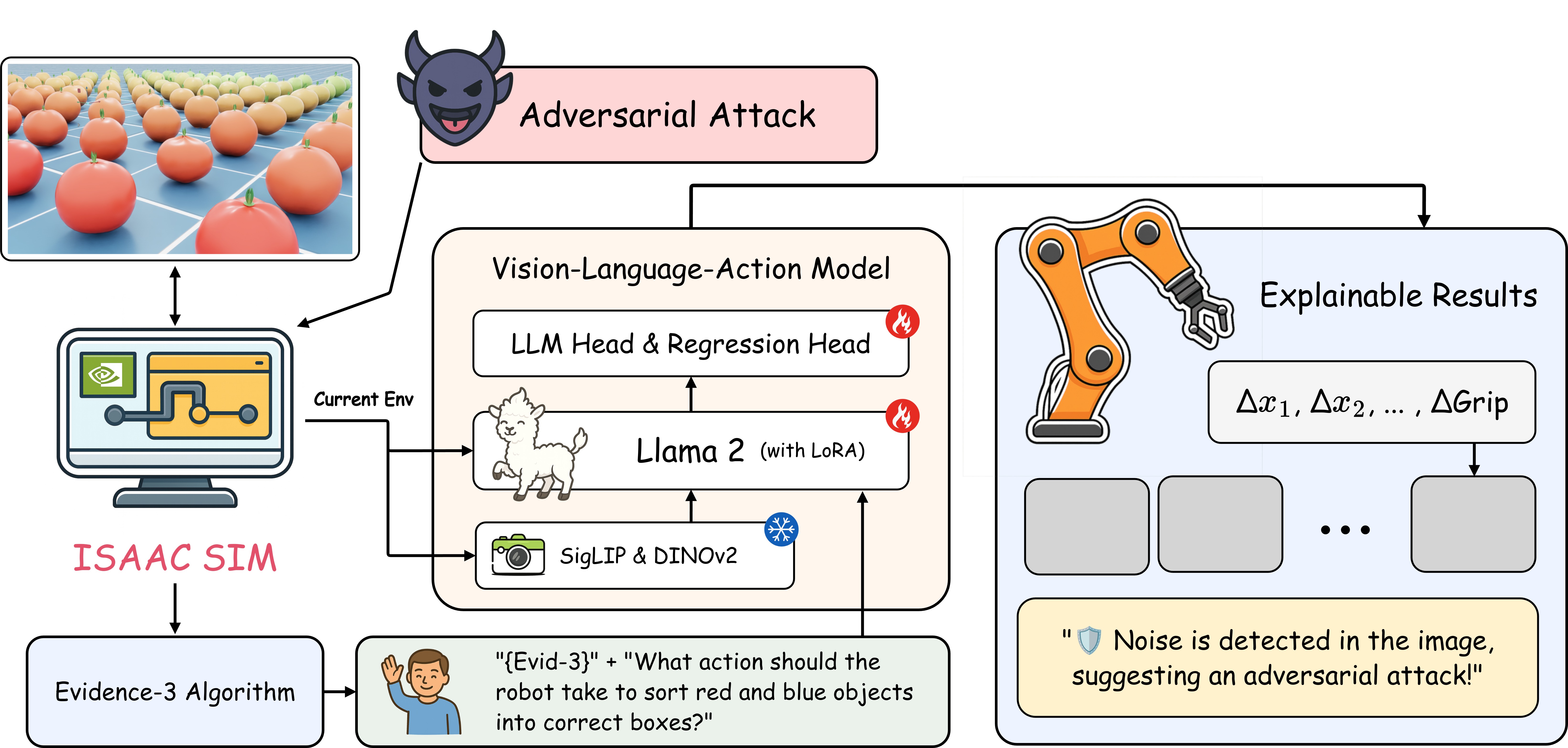
Smart farming systems are complex intelligent systems that integrate various modules such as robots, sensors, and cameras. While Vision-Language-Action (VLA) research has advanced in processing multimodal data for environmental perception and control, studies on explainable artificial intelligence (XAI) for defending against adversarial attacks remain limited [1]. This paper proposes a VLA model capable of detecting and explaining adversarial attacks by integrating an adversarial detection and explanation module into the existing VLA framework, as illustrated in Figure 1. The following section outlines the proposed architecture.
- Adversarial Data Generation: Simulation data are collected using the Franka Emika Panda robotic arm and an RGB camera in Isaac Sim. Random photometric transformations including hue shift (T color ), illumination adjustment (T illum ), and noise injection (T noise ) are applied to generate adversarial variants. Formally, this process can be expressed as x ′ = T S (x), T S ⊆ {T color , T illum , T noise }, where x denotes the original input image, and S is a randomly selected subset of transformations.
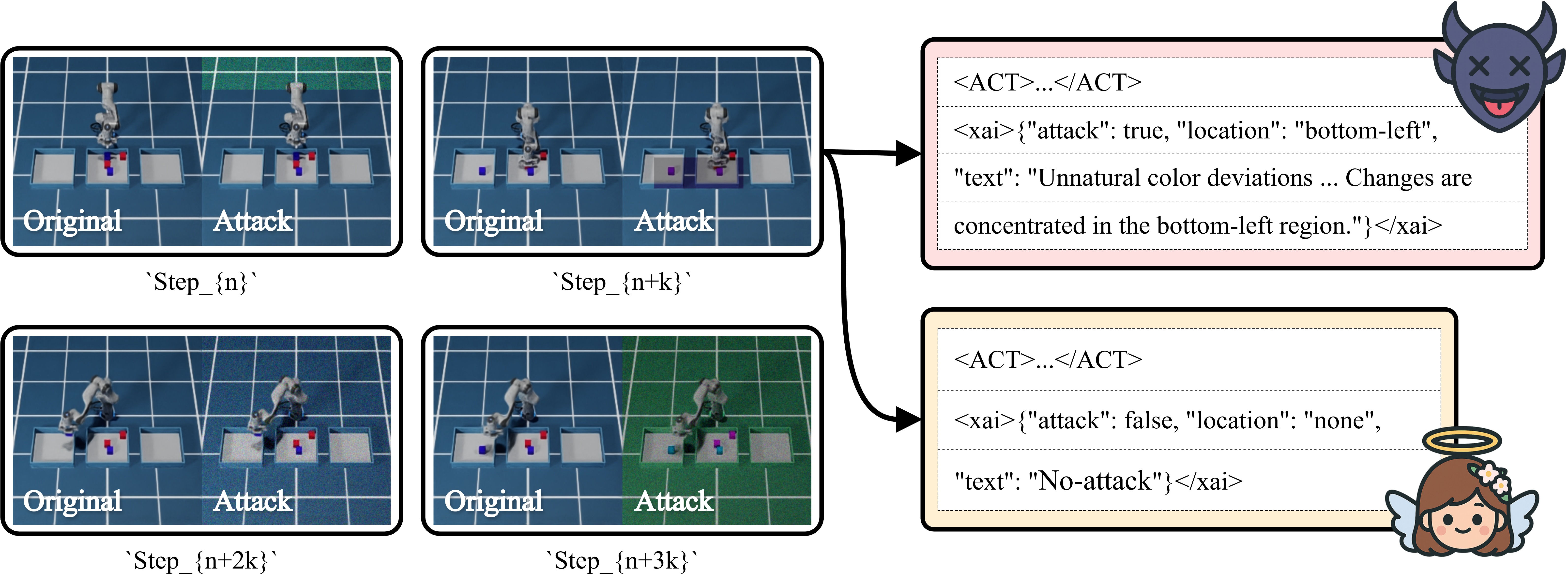
The proposed architecture builds upon the OpenVLA-OFT framework [2] and incorporates an additional Evidence-3 module for adversarial attack detection. The Evidence-3 module consists of a detection pipeline based on three statistical metrics: HSV Mahalanobis Distance (detecting color distribution anomalies), High-Frequency Energy Ratio (identifying noise injection), and Local Entropy Standard Deviation (capturing spatial irregularities). These statistical cues are embedded into the user instruction and provided as auxiliary input to the model.
The action prediction head receives hidden representations from the Llama2 backbone and predicts the current and subsequent actions by minimizing the L1 loss. In parallel, the model is trained to detect and describe adversarial attacks by minimizing the cross-entropy loss over the XAI tokens generated by the Llama2 output. The total loss is defined as
where L xai represents the cross-entropy loss for explanation tokens, scaled by a weighting hyperparameter λ xai that controls the relative importance of explanation learning, set to 0.5 in this work. Meanwhile, L act denotes the L1 regression loss for action prediction.
To evaluate the proposed architecture, we compared three configurations: the baseline (Default), an adversarially trained model (Augmentd), and the proposed model. Table 1 summarizes the results. Compared with the Default model, the proposed model reduced the Current and Next Action L1 losses by 21.6% and 18.4%, respectively, while outperforming the Augmented model by 6.9% and 7.8%, respectively. It also achieved an XAI token accuracy of 99.77%, showing that joint learning of robustness and explainability improves action prediction under adversarial conditions. Future work will explore the applicability of our approach to real-world smart farming environments and extend validation using robotic simulations.
This content is AI-processed based on open access ArXiv data.