Title: On the Dangers of Bootstrapping Generation for Continual Learning and Beyond
ArXiv ID: 2512.11867
Date: 2025-12-05
Authors: ** - Daniil Zverev¹ - A. Sophia Koepke¹˟² - Joao F. Henriques³ ¹ Technical University of Munich, MCML ² University of Tübingen, Tübingen AI Center ³ University of Oxford **
📝 Abstract
The use of synthetically generated data for training models is becoming a common practice. While generated data can augment the training data, repeated training on synthetic data raises concerns about distribution drift and degradation of performance due to contamination of the dataset. We investigate the consequences of this bootstrapping process through the lens of continual learning, drawing a connection to Generative Experience Replay (GER) methods. We present a statistical analysis showing that synthetic data introduces significant bias and variance into training objectives, weakening the reliability of maximum likelihood estimation. We provide empirical evidence showing that popular generative models collapse under repeated training with synthetic data. We quantify this degradation and show that state-of-the-art GER methods fail to maintain alignment in the latent space. Our findings raise critical concerns about the use of synthetic data in continual learning.
💡 Deep Analysis
📄 Full Content
On the Dangers of Bootstrapping Generation for
Continual Learning and Beyond
Daniil Zverev1, A. Sophia Koepke1,2, and Joao F. Henriques3
1 Technical University of Munich, MCML
2 University of T¨ubingen, T¨ubingen AI Center
3 University of Oxford
Abstract. The use of synthetically generated data for training models
is becoming a common practice. While generated data can augment the
training data, repeated training on synthetic data raises concerns about
distribution drift and degradation of performance due to contamination
of the dataset. We investigate the consequences of this bootstrapping
process through the lens of continual learning, drawing a connection to
Generative Experience Replay (GER) methods. We present a statisti-
cal analysis showing that synthetic data introduces significant bias and
variance into training objectives, weakening the reliability of maximum
likelihood estimation. We provide empirical evidence showing that pop-
ular generative models collapse under repeated training with synthetic
data. We quantify this degradation and show that state-of-the-art GER
methods fail to maintain alignment in the latent space. Our findings raise
critical concerns about the use of synthetic data in continual learning.
Keywords: Continual Learning · Generative Replay · Generative Col-
laps.
1
Introduction
Generative models have become essential for modern machine learning, being
used in various tasks ranging from text generation to image synthesis. These
models, such as GPT-based large language models [2] and diffusion-based image
generators like Midjourney, are now key components in consumer and industrial
applications. A natural consequence of their proliferation is the growing pres-
ence of synthetic data in the publicly available data corpus [11]. As this trend
continues, future models are likely to be trained on data that was itself gener-
ated by other models. This growing reliance on synthetic data raises questions
about the consequences of repeatedly training models on data generated by ear-
lier models. While synthetic data can temporarily enrich datasets, incorporating
generated samples into future training regimes risks long-term degradation of
model performance due to distributional drift and statistical contamination.
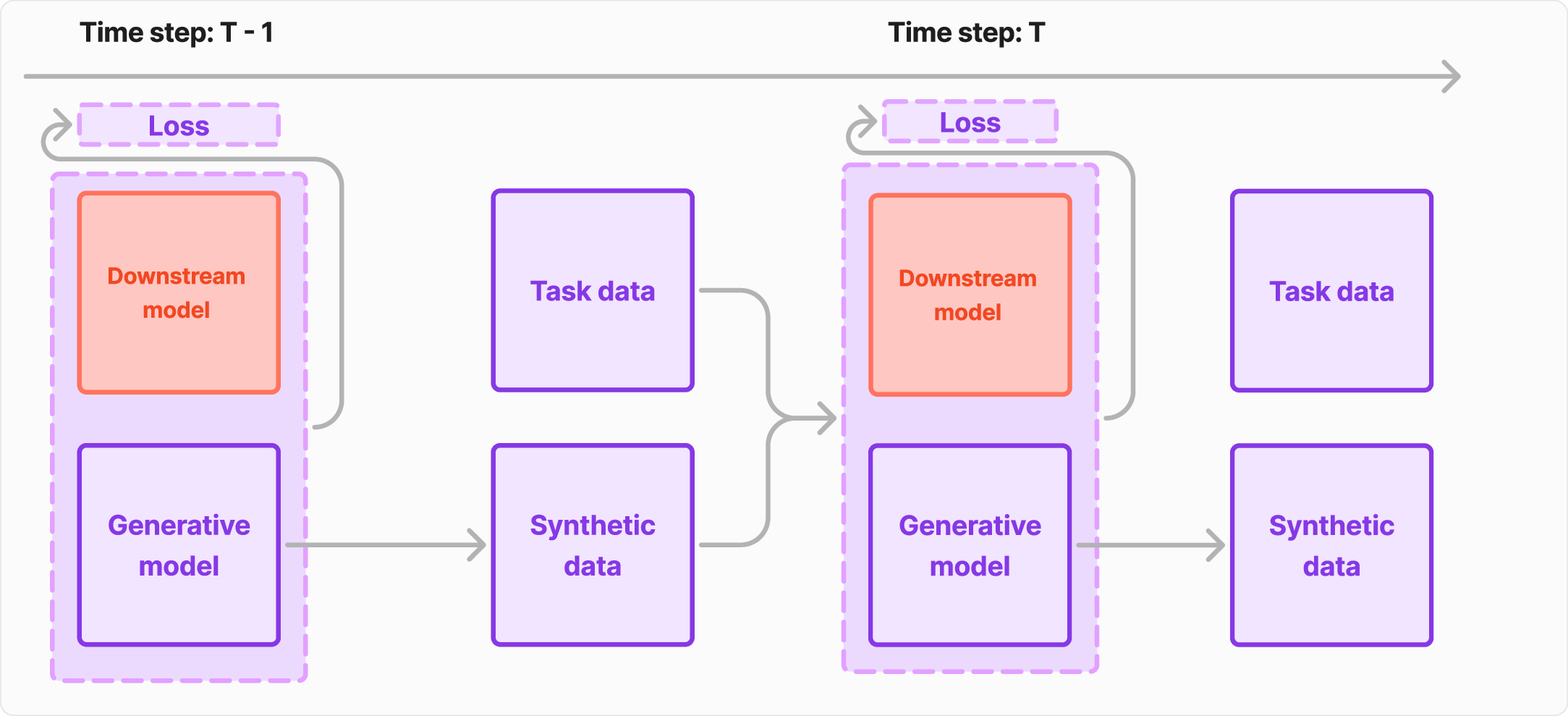
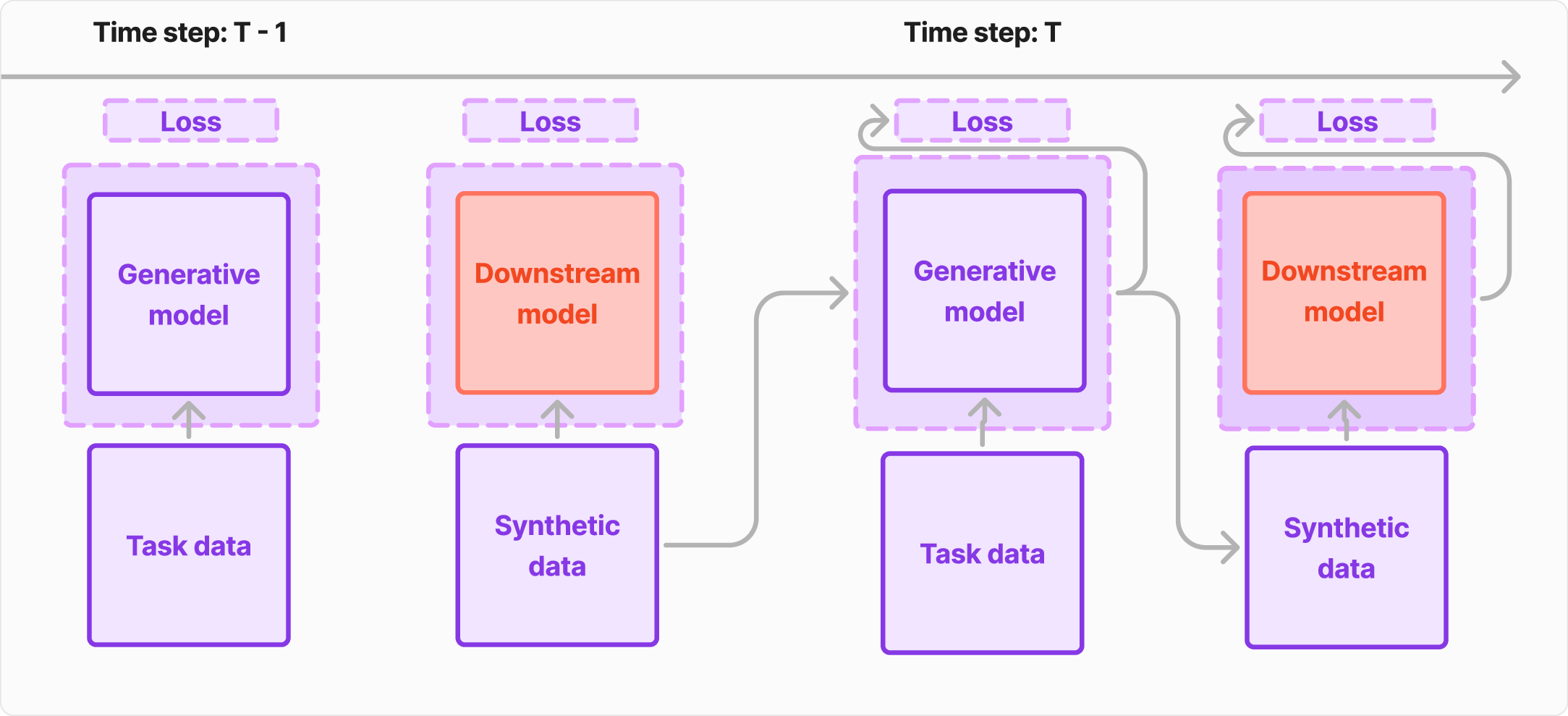
This phenomenon is closely related to continual learning (CL), specifically in
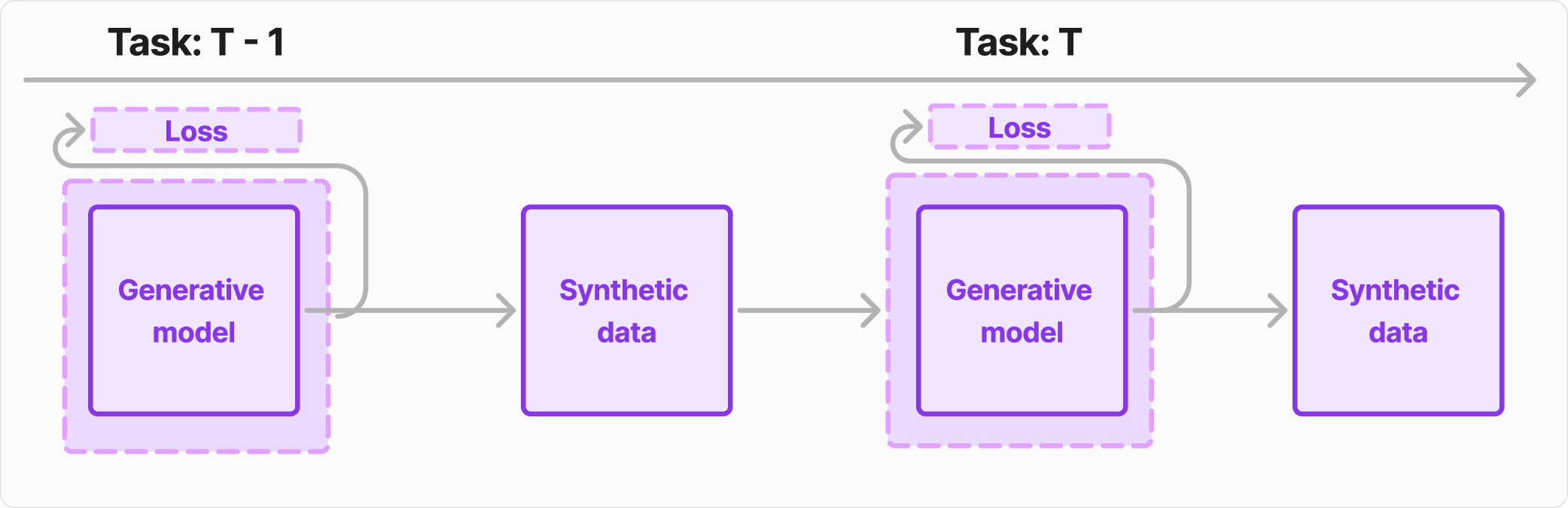
the form of Generative Experience Replay [49,13]. In GER, a model is exposed
to a stream of non-i.i.d. tasks and maintains performance across them by using a
arXiv:2512.11867v1 [cs.LG] 5 Dec 2025
2
D. Zverev et al.
generative model to replay synthetic samples from past tasks. This setup reflects
broader trends in machine learning, where synthetic data is reused across training
cycles.
In this paper, we study the statistical and empirical consequences of this syn-
thetic bootstrapping loop. We begin by formalising the continual learning setup
and examining the statistical errors introduced by synthetic data. In particular,
we consider bias and variance in maximum likelihood estimators when real data
is replaced by generated samples. We then analyse GER continual learning algo-
rithms, identifying how these statistical errors manifest in state-of-the-art meth-
ods. Our experiments highlight that generative models exhibit instability when
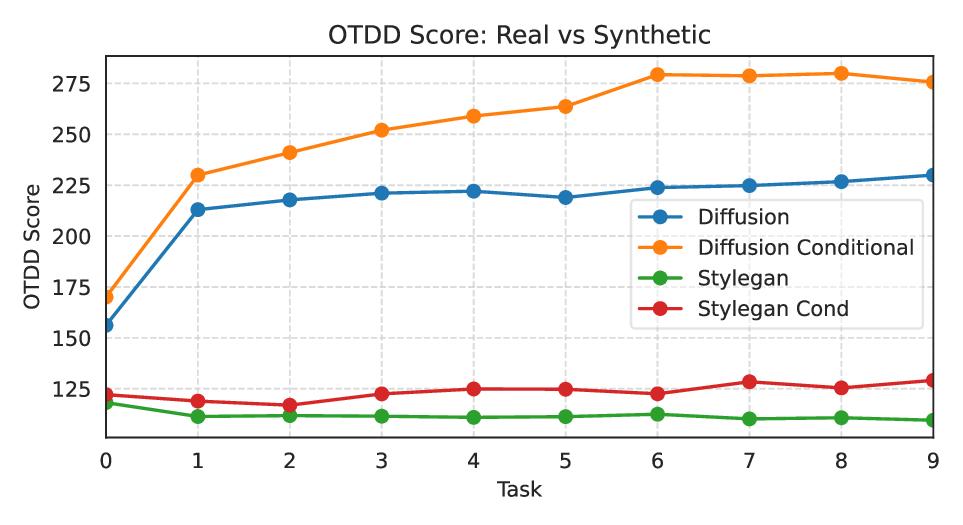
repeatedly trained on synthetic samples. We provide empirical evidence that,
over time, synthetic datasets diverge from their original distributions, leading
to a degradation in downstream performance and increased divergence in latent
space representations.
To summarise, our contributions are as follows:
1. We provide a theoretical analysis demonstrating how repeated training on
synthetic data introduces bias and variance into standard training objectives,
weakening the statistical guarantees of generative model learning.
2. We perform controlled experiments on GANs and diffusion models, empir-
ically showing that repeatedly training on generated data leads to distri-
butional drift and downstream performance degradation, even under ideal
conditions.
3. We quantify the divergence of synthetic and real data and show that state-
of-the-art GER methods fail to prevent latent space separation between the
two domains.
Our findings provide a cautionary perspective on synthetic data usage, along
with theoretical grounding for understanding the limitations of GER in continual
learning.
2
Related work
Continual learning and generative replay. CL addresses the challenge of train-
ing models on non-stationary data distributions without the important problem
of catastrophic forgetting [15,41,44,49,30]. This is commonly addressed by re-
visiting old data through experience replay methods [46,33,44,9]. A prominent
subfamily of methods, Generative Experience Replay (GER) [49,25,57,45], miti-
gates forgetting by using generative models to recreate past task data [49]. GAN
Memory [10] and DDGR [13] further scale GER to more complex datasets using
GANs and diffusion models respective