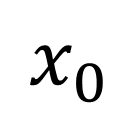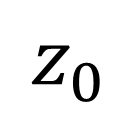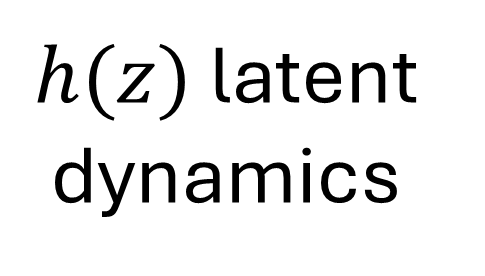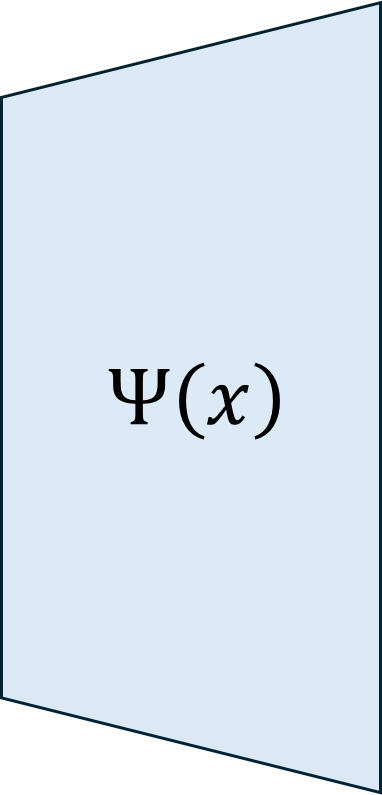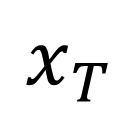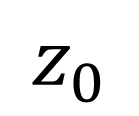Model Recovery (MR) is a core primitive for physical AI and real-time digital twins, but GPUs often execute MR inefficiently due to iterative dependencies, kernel-launch overheads, underutilized memory bandwidth, and high data-movement latency. We present MERINDA, an FPGA-accelerated MR framework that restructures computation as a streaming dataflow pipeline. MERINDA exploits on-chip locality through BRAM tiling, fixed-point kernels, and the concurrent use of LUT fabric and carry-chain adders to expose fine-grained spatial parallelism while minimizing off-chip traffic. This hardware-aware formulation removes synchronization bottlenecks and sustains high throughput across the iterative updates in MR. On representative MR workloads, MERINDA delivers up to 6.3x fewer cycles than an FPGA-based LTC baseline, enabling real-time performance for time-critical physical systems.
One of the central advances in the AI revolution is physical AI, where computational agents interact with-and learn from-physical systems for control and continual adaptation [1]. In edge AI settings, these agents must operate under tight latency, power, and privacy constraints, making physics-guided predictive inference especially valuable. A key enabler is model recovery (MR): extracting firstprinciples-guided dynamical equations from real-world data so the learned model serves as a digital twin (DT). Unlike purely datadriven models, the recovered DT supports online monitoring of safety, integrity, and unknown errors, while feedback from forward simulation can be used to adjust system responses in real time [2,3].
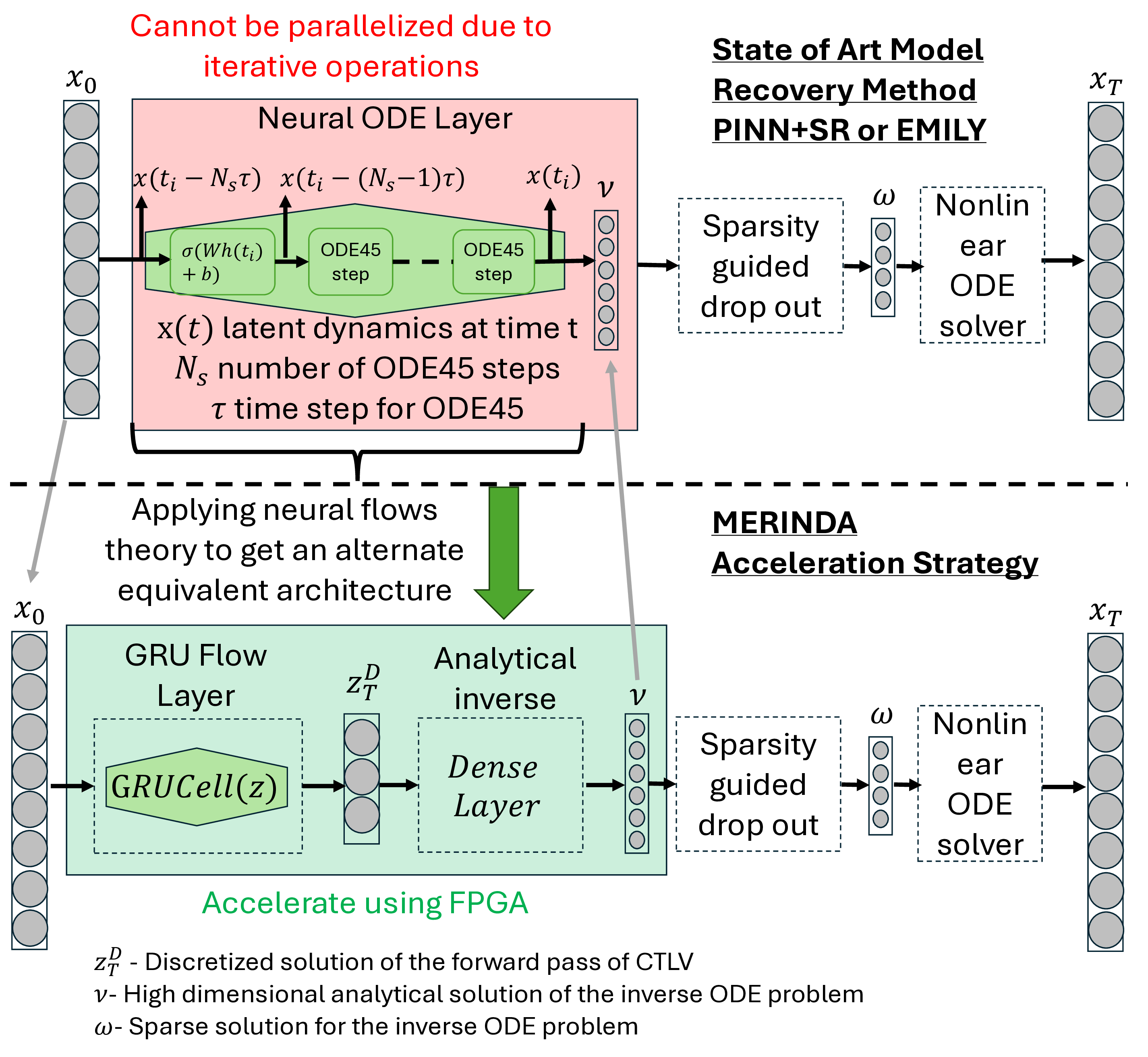
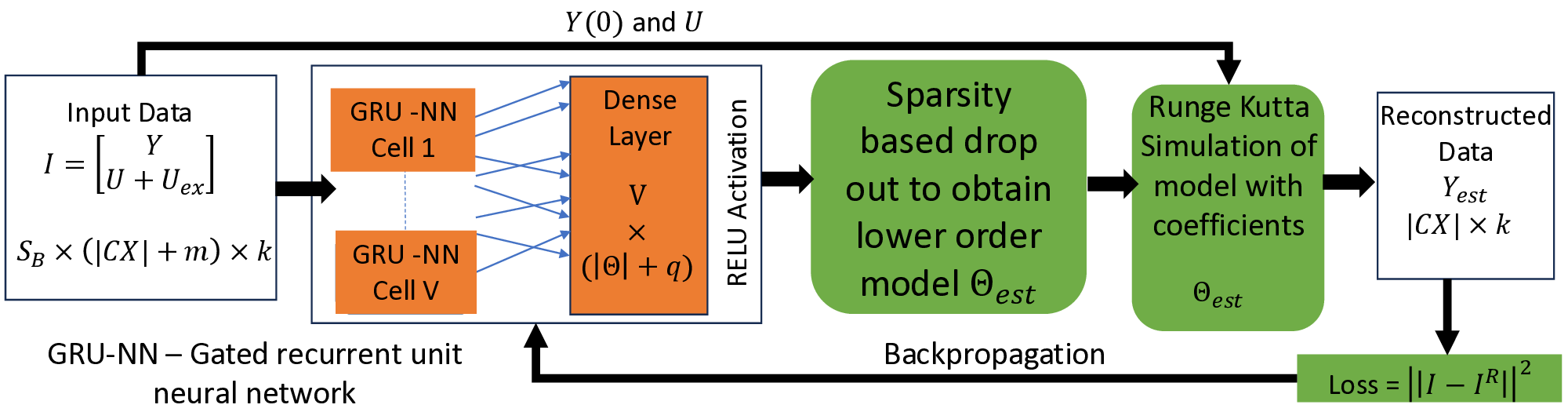
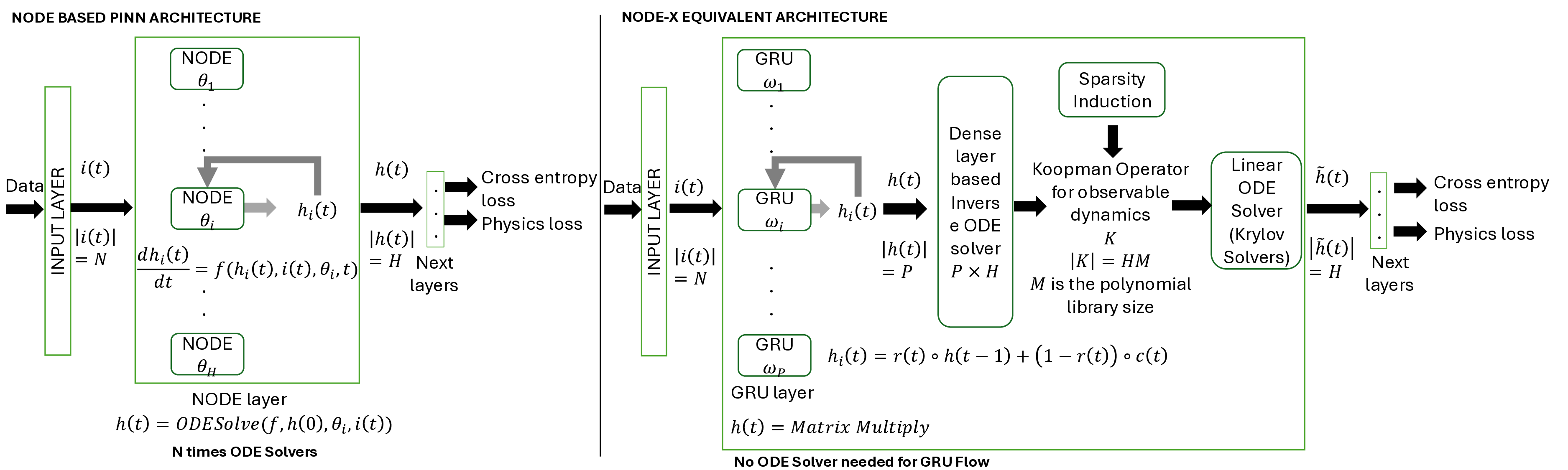
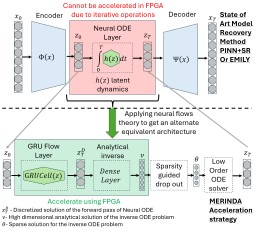
Traditionally, Model Recovery (MR) relies on Neural Ordinary Differential Equations (NODEs), which underpin continuous-depth residual networks and continuous normalizing flows [4]. This paradigm extends to Liquid Time-Constant (LTC) networks, which attain state-of-the-art sequence modeling by modulating input-driven nonlinear dynamical systems [5]. Despite their expressivity, these models depend on iterative ODE solvers during both training and inference, incurring substantial compute, latency, and energy costs. As illustrated in Fig. 1(left panel), a single forward pass through a NODE layer typically requires 𝑁 function evaluations to advance the state. Because each sub-step depends on the previous one, these computations are inherently sequential and difficult to parallelize across steps, limiting throughput and amplifying launch/memory overheads on conventional accelerators. High-Level Optimization. Prior accelerators for ODENet [6] and NODE layers [7] typically assume a fixed solver depth and static coefficients, which conflicts with data-driven MR frameworks (PINN+SR, PiNODE, EMILY) whose solver depth, step size, and parameters adapt to the input. Stand-alone ODE-solver engines [8,9] make similar assumptions, limiting their utility when coefficients vary online or when low-latency, streaming execution is required at the edge.
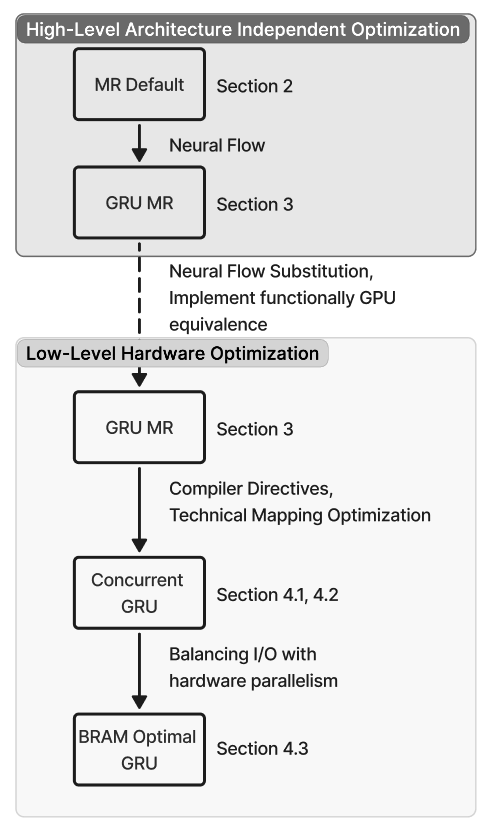
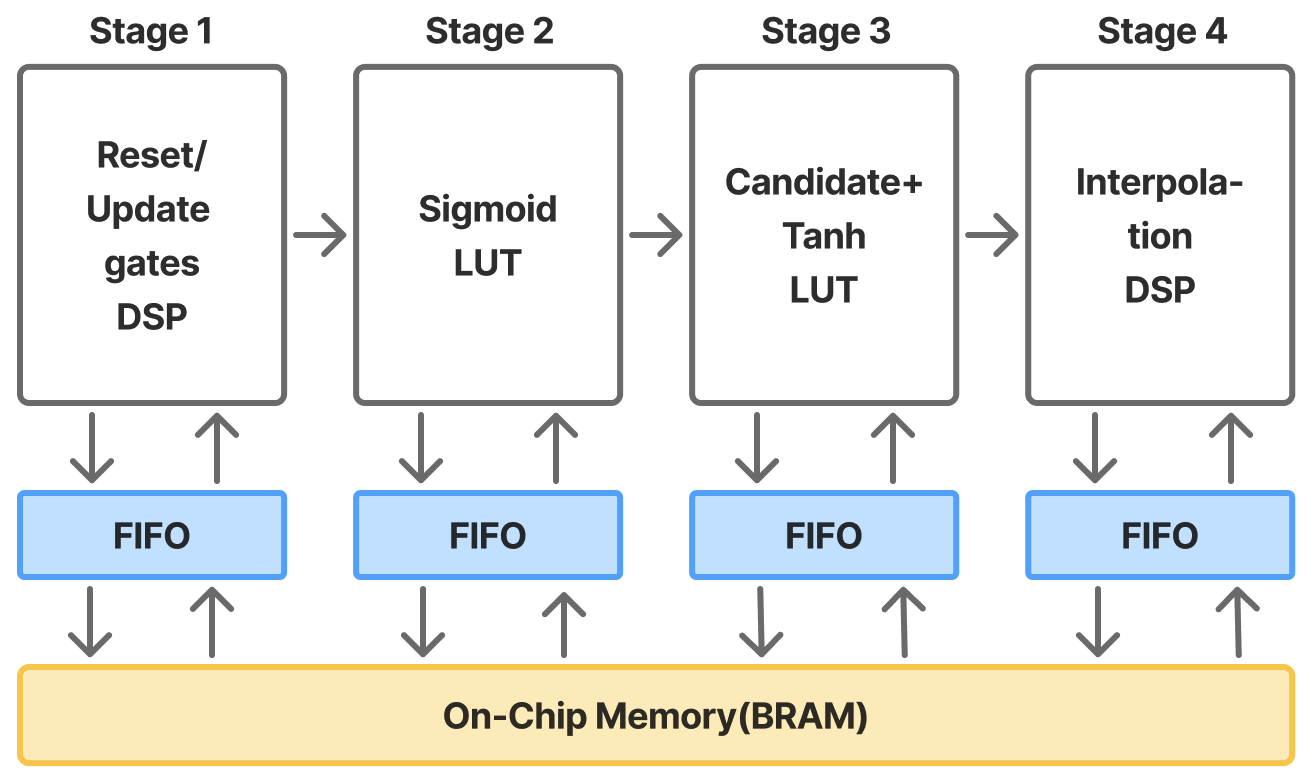
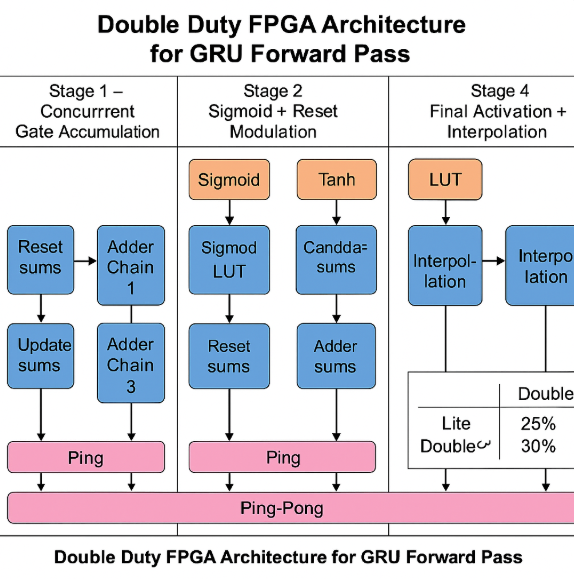
Profiling highlights the ODE solver as the dominant cost: in Table 1, it accounts for 87.7% of forward-pass latency (pre-processing 12.3%) for a total of 0.106 ms. The per-step breakdown in Table 2 identifies Recurrent Sigmoid (46.7%) and Sum Operations (34.4%) as the main hotspots, followed by the Euler update (14.0%), while weight and reversal activations contribute < 5%. These findings show the bottleneck of computing N times ODE-Solvers during forward pass and backpropagation and motivate our substitution of the NODE layer with an equivalent, FPGA-friendly block (Fig. 1, right): a GRU followed by a lightweight dense non-linearity and a single-step ODE solver. Concretely, the block computes a gated increment based on the current state and input, and then updates the state by adding this increment scaled by the step size, thereby preserving the original NODE mapping for both training and inference while eliminating multi-step solver overhead. Low-Level Optimization To our knowledge, MR has not been systematically evaluated on FPGA platforms. This paper closes that gap by implementing and characterizing MR on edge-class FPGAs.
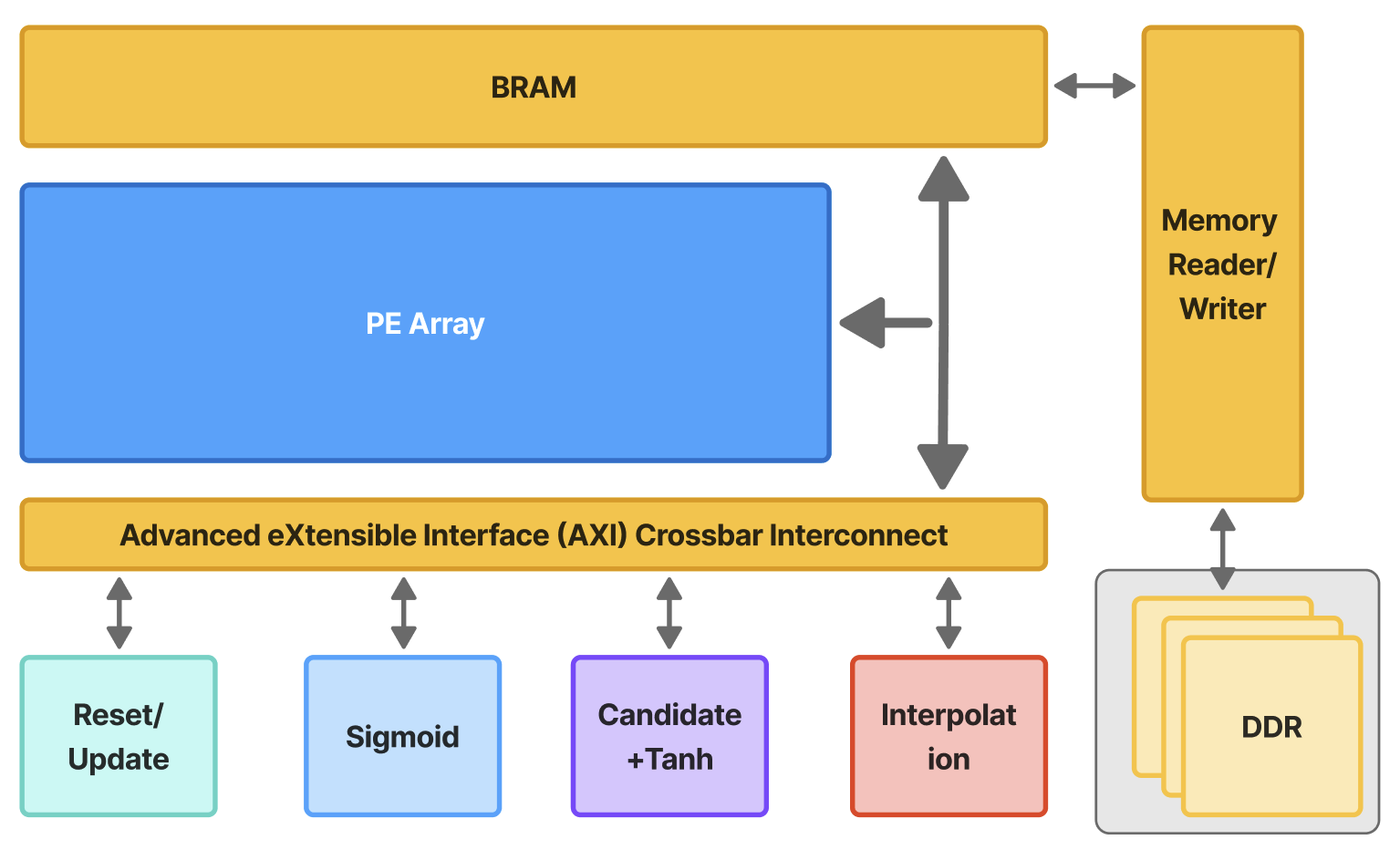
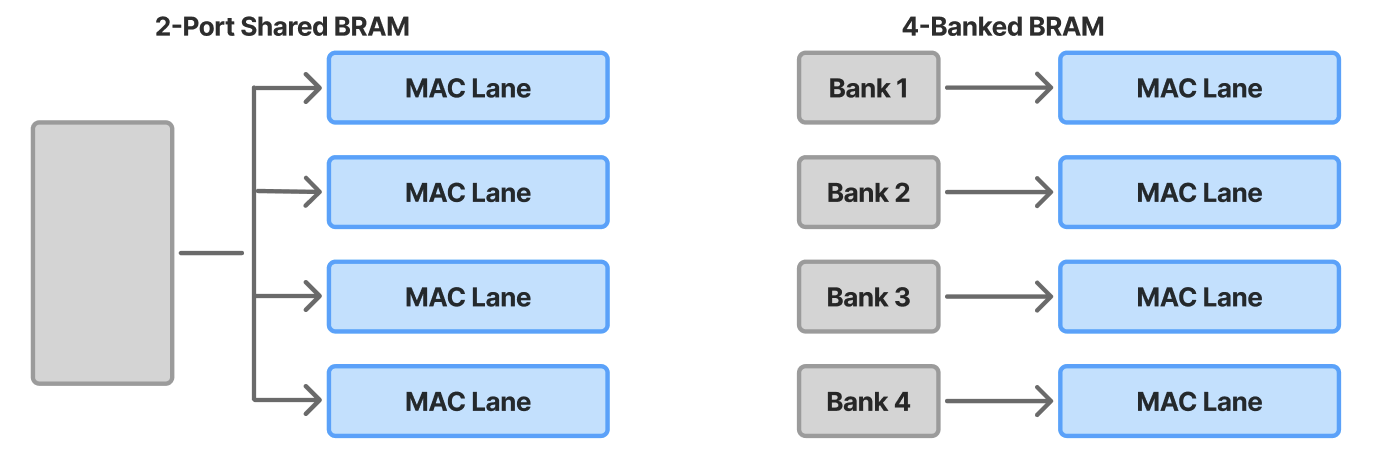
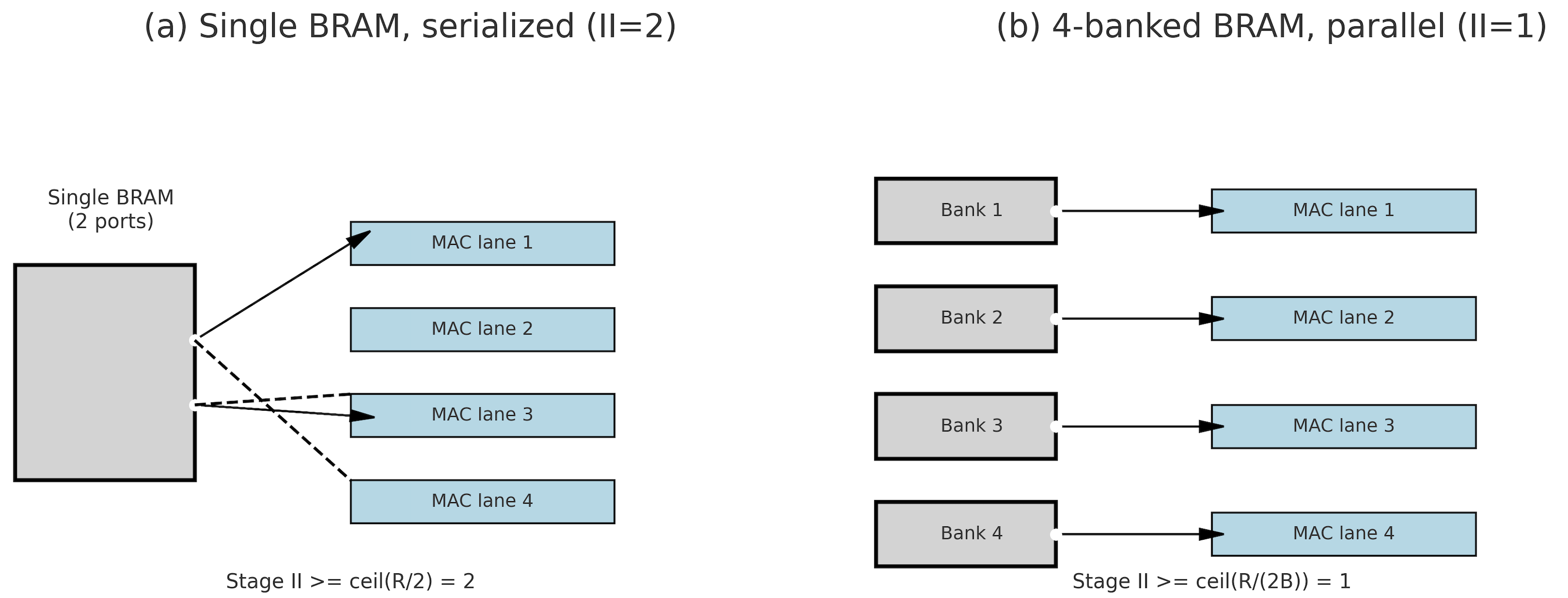
Moving MR learning onto FPGAs can reduce data-transfer volume, cut end-to-end latency, and lower both storage and energy overheads by exploiting on-chip locality and streaming execution. However, this shift introduces its own challenges: unlike cloud GPUs, FPGAs provide more limited raw compute throughput, have far smaller on-chip and external memory capacity, and lack the mature software ecosystem of GPU platforms. These disparities raise fundamental questions about whether MR workloads-traditionally designed for GPU-friendly dense linear algebra-can meet real-time latency, energy, and memory constraints when deployed at the edge on FPGA-based systems. FPGA toolchains (synthesis, mapping, placement, and routing) typically compile high-level designs into hardware by automatically mapping them onto computational and memory resources such as LUTs, DSPs, and adders. However, this automatic routing and mapping often yields suboptimal performance for streaming workloads such as GRU, due to inefficient memory access patterns and long routing paths [10]. To address this, we introduce a custom datamapping strategy that aligns memory layout with compute parallelism in the GRU architecture, ensuring each unrolled DSP MAC lane is supplied with operands every cycle. Furthermore, to sustain high throughput across pipeline stages, we apply BRAM optimizations-including partitioning, banking, and reshaping-to maximize on-chip bandwidth and reduce contention, thereby improving data movement efficiency for concurrent DATAFLOW execution.
Building on neural-flow theory [11], we present MERINDA (Model Recovery in Dynamic Architecture): a hardware-conscious reformulation of NODE layers (as used in EMILY, PiNODE, and PINN+SR) expressly tailored for FPGA accelera
This content is AI-processed based on open access ArXiv data.