Title: Quantifying Memory Use in Reinforcement Learning with Temporal Range
ArXiv ID: 2512.06204
Date: 2025-12-05
Authors: Rodney Lafuente-Mercado, Daniela Rus, T. Konstantin Rusch
📝 Abstract
How much does a trained RL policy actually use its past observations? We propose \emph{Temporal Range}, a model-agnostic metric that treats first-order sensitivities of multiple vector outputs across a temporal window to the input sequence as a temporal influence profile and summarizes it by the magnitude-weighted average lag. Temporal Range is computed via reverse-mode automatic differentiation from the Jacobian blocks $\partial y_s/\partial x_t\in\mathbb{R}^{c\times d}$ averaged over final timesteps $s\in\{t+1,\dots,T\}$ and is well-characterized in the linear setting by a small set of natural axioms. Across diagnostic and control tasks (POPGym; flicker/occlusion; Copy-$k$) and architectures (MLPs, RNNs, SSMs), Temporal Range (i) remains small in fully observed control, (ii) scales with the task's ground-truth lag in Copy-$k$, and (iii) aligns with the minimum history window required for near-optimal return as confirmed by window ablations. We also report Temporal Range for a compact Long Expressive Memory (LEM) policy trained on the task, using it as a proxy readout of task-level memory. Our axiomatic treatment draws on recent work on range measures, specialized here to temporal lag and extended to vector-valued outputs in the RL setting. Temporal Range thus offers a practical per-sequence readout of memory dependence for comparing agents and environments and for selecting the shortest sufficient context.
💡 Deep Analysis
📄 Full Content
QUANTIFYING MEMORY USE
IN REINFORCEMENT
LEARNING WITH TEMPORAL RANGE
Rodney Lafuente-Mercado
MIT Lincoln Laboratory
Rodney.LafuenteMercado@ll.mit.edu
Daniela Rus
CSAIL, MIT
rus@csail.mit.edu
T. Konstantin Rusch
ELLIS Institute T¨ubingen &
Max Planck Institute for Intelligent Systems &
T¨ubingen AI Center
tkrusch@tue.ellis.eu
ABSTRACT
How much does a trained RL policy actually use its past observations? We propose
Temporal Range, a model-agnostic metric that treats first-order sensitivities of
multiple vector outputs across a temporal window to the input sequence as a tem-
poral influence profile and summarizes it by the magnitude-weighted average lag.
Temporal Range is computed via reverse-mode automatic differentiation from the
Jacobian blocks ∂ys/∂xt ∈Rc×d averaged over final timesteps s ∈{t+1, . . . , T}
and is well-characterized in the linear setting by a small set of natural axioms.
Across diagnostic and control tasks (POPGym; flicker/occlusion; Copy-k) and
architectures (MLPs, RNNs, SSMs), Temporal Range (i) remains small in fully
observed control, (ii) scales with the task’s ground-truth lag in Copy-k, and (iii)
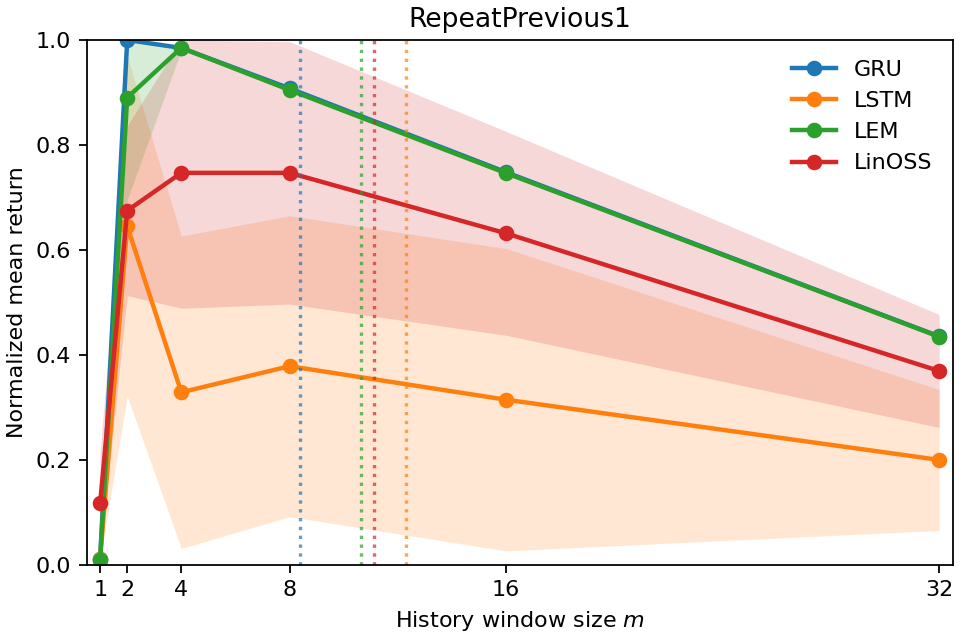
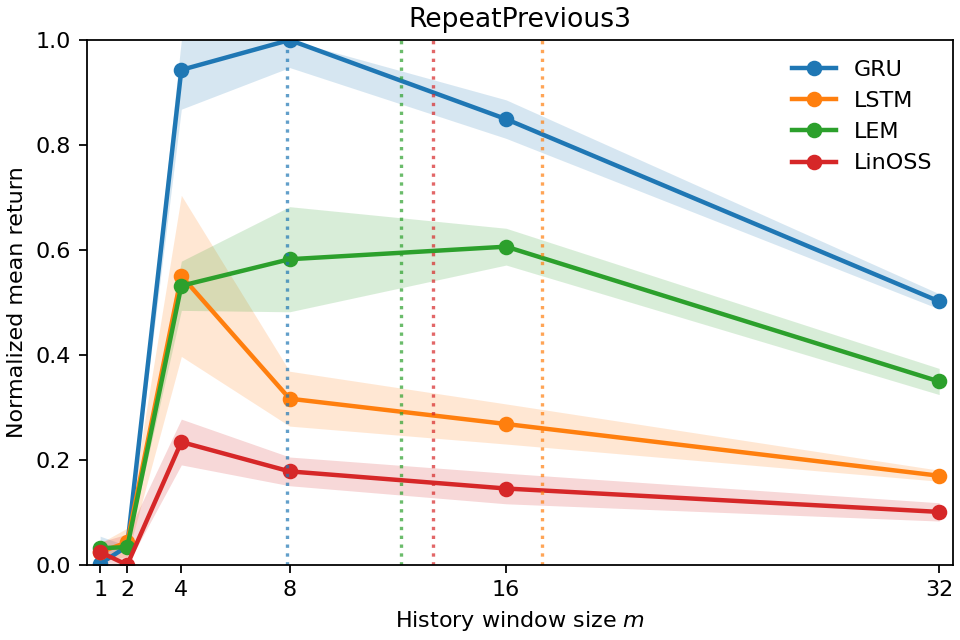
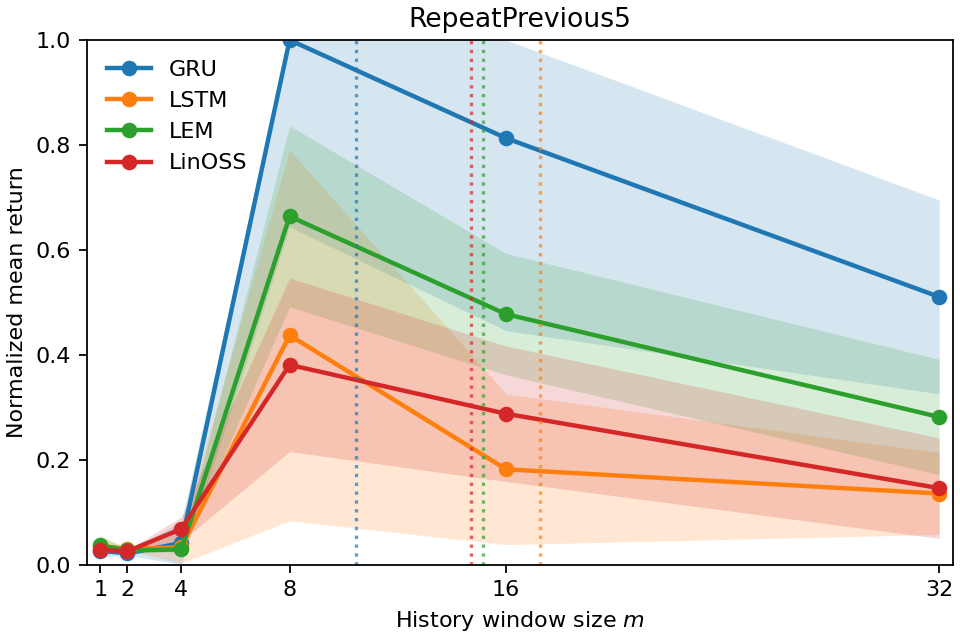
aligns with the minimum history window required for near-optimal return as con-
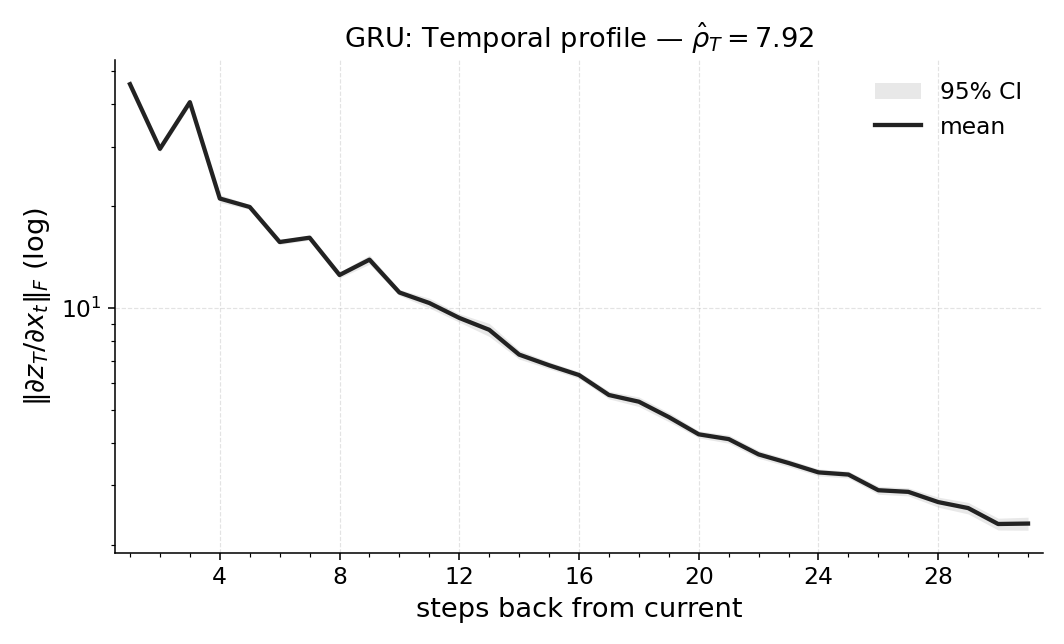
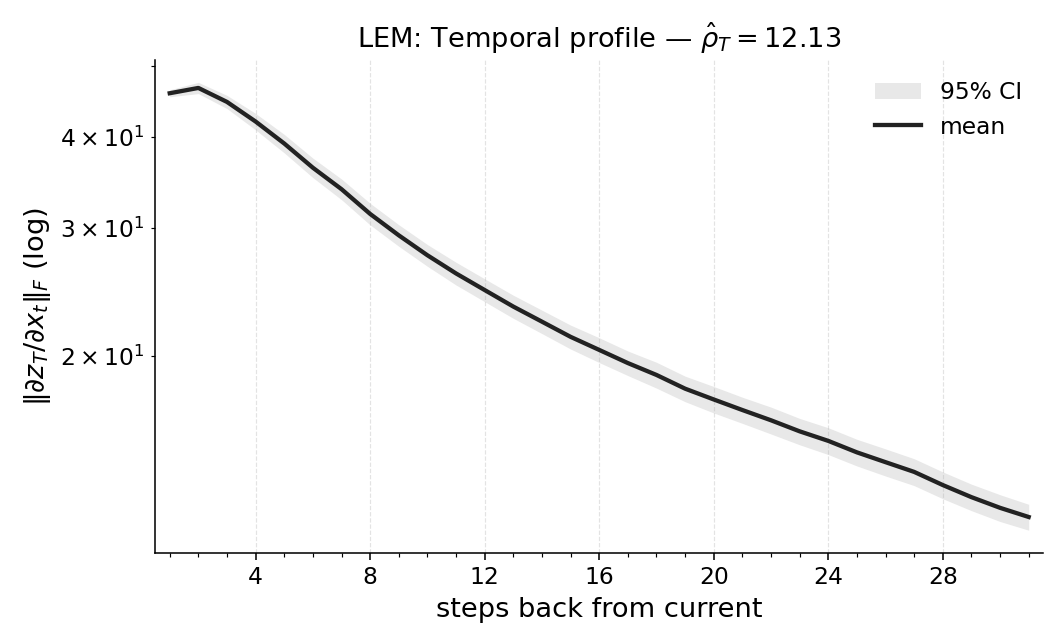
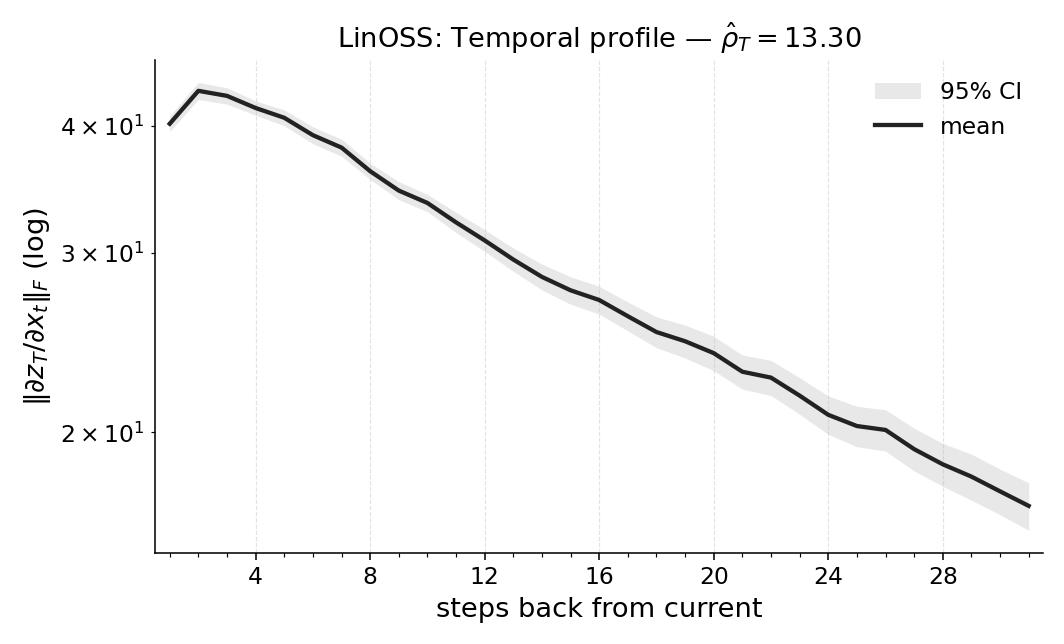
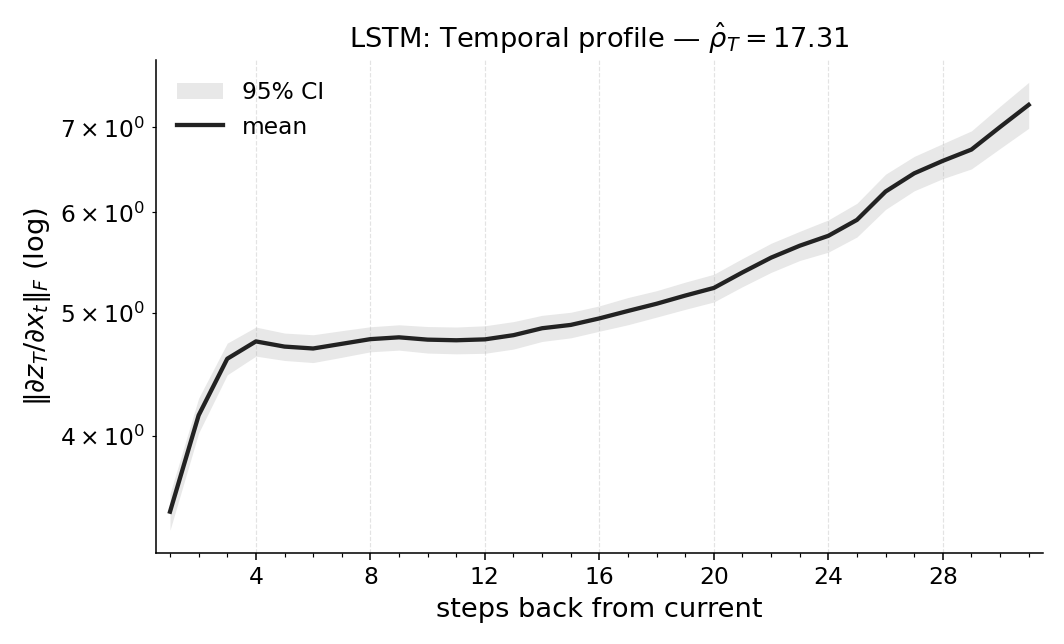
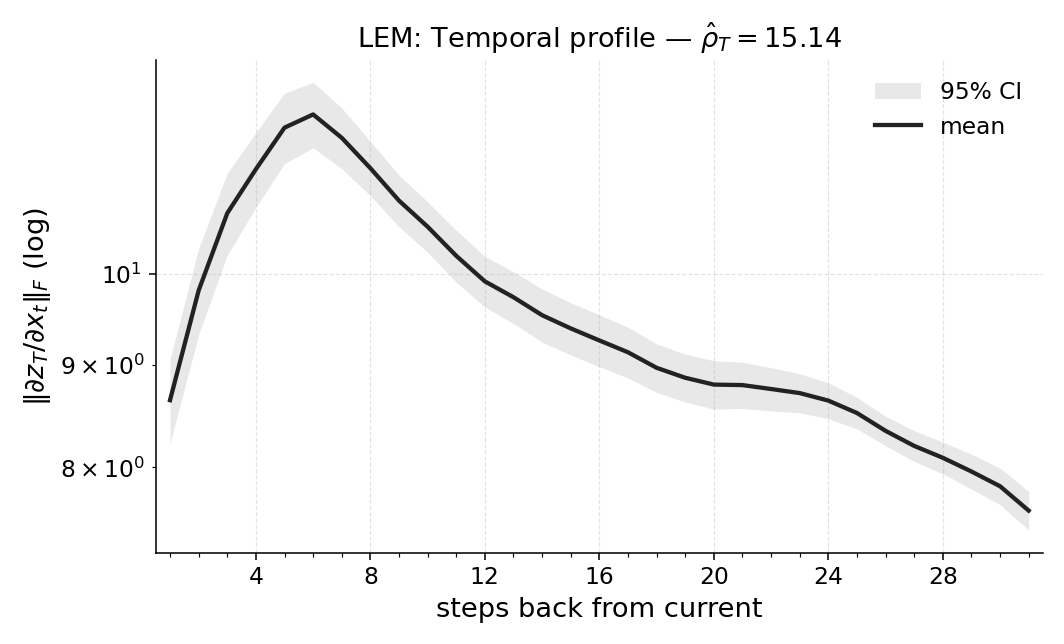
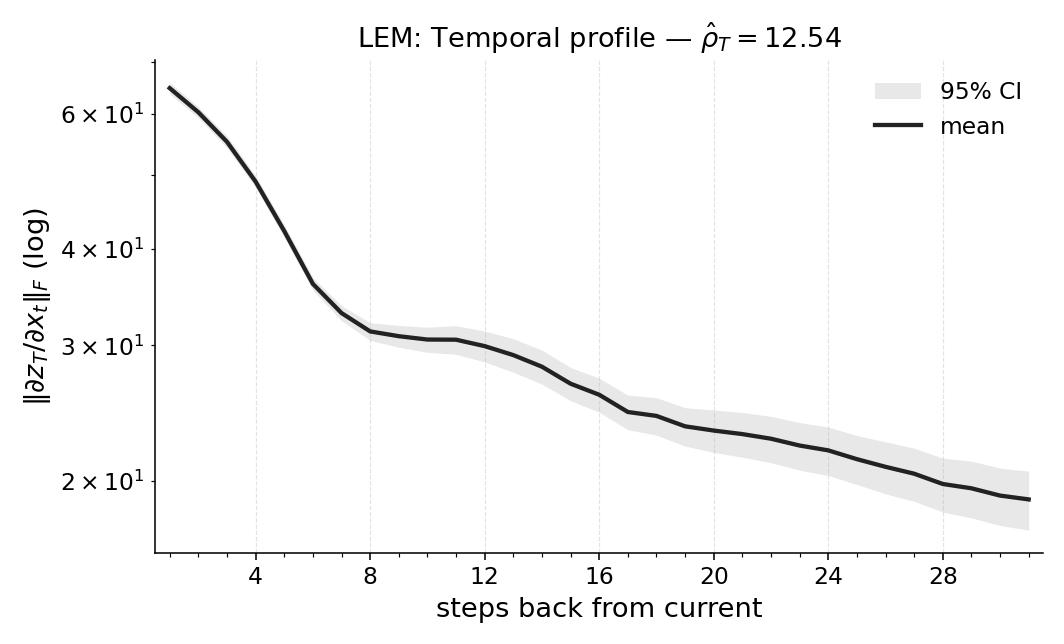
firmed by window ablations. We also report Temporal Range for a compact Long
Expressive Memory (LEM) policy trained on the task, using it as a proxy readout
of task-level memory. Our axiomatic treatment draws on recent work on range
measures, specialized here to temporal lag and extended to vector-valued outputs
in the RL setting. Temporal Range thus offers a practical per-sequence readout of
memory dependence for comparing agents and environments and for selecting the
shortest sufficient context.
1
INTRODUCTION
Reinforcement learning (RL) has a long-standing history of utilizing memory to improve perfor-
mance in complex environments (Hausknecht & Stone, 2015; Berner et al., 2019; Chen et al., 2021;
Lu et al., 2023). Examples of machine learning models that incorporate memory include classical
Recurrent Neural Networks (RNNs) such as Long Short-Term Memory (LSTM) models (Hochre-
iter & Schmidhuber, 1997), Transformer (Vaswani et al., 2017), and recently State-Space Models
(SSMs) (Gu et al., 2021; Gu & Dao, 2023). However, a rigorous analysis and quantitative measure
of the extent to which a trained policy utilizes historical information remains largely absent. This
matters in partially observed settings: if effective history dependence is short, simpler architectures
or shorter contexts suffice; if it is long, we should see it directly in the learned policy rather than infer
it from task design or model choice. Current practice relies on indirect signals, such as model class
comparisons, environment-specific probes, or sample-complexity bounds (Williams, 2009; Efroni
et al., 2022; Morad et al., 2023). These conflate optimization, inductive bias, and true memory
demand, and they do not yield a comparable, sequence-level number.
To address this, we formalize a Temporal Range metric that aggregates vector-output Jacobians
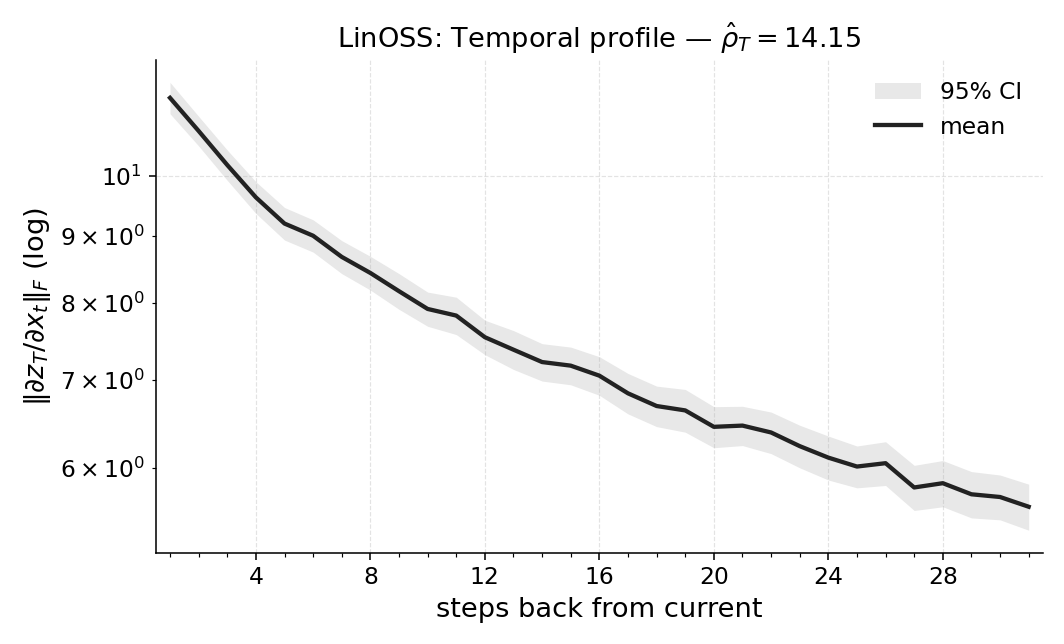
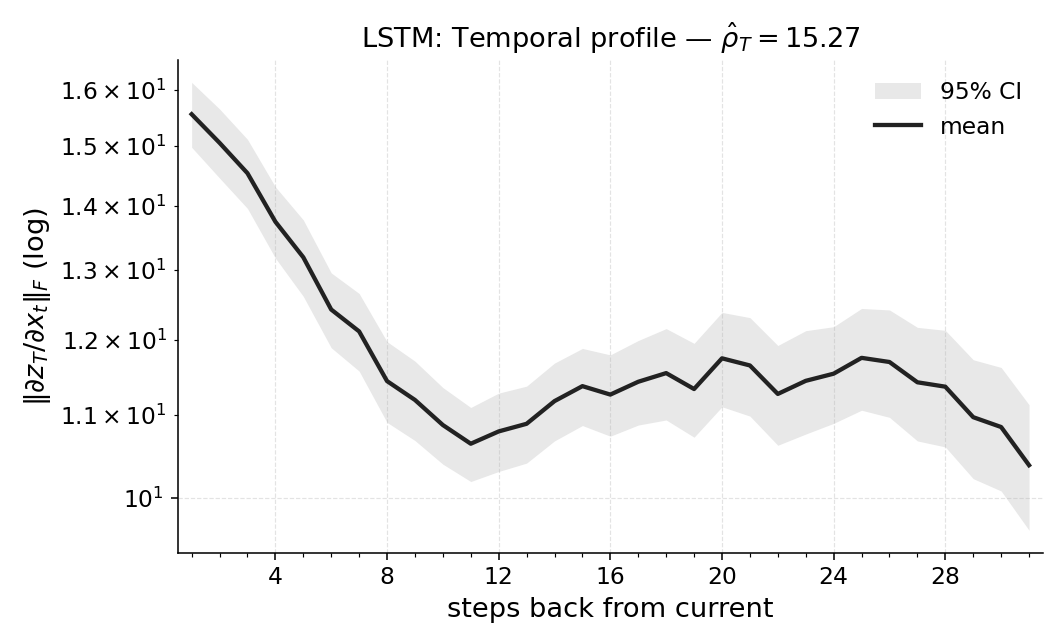
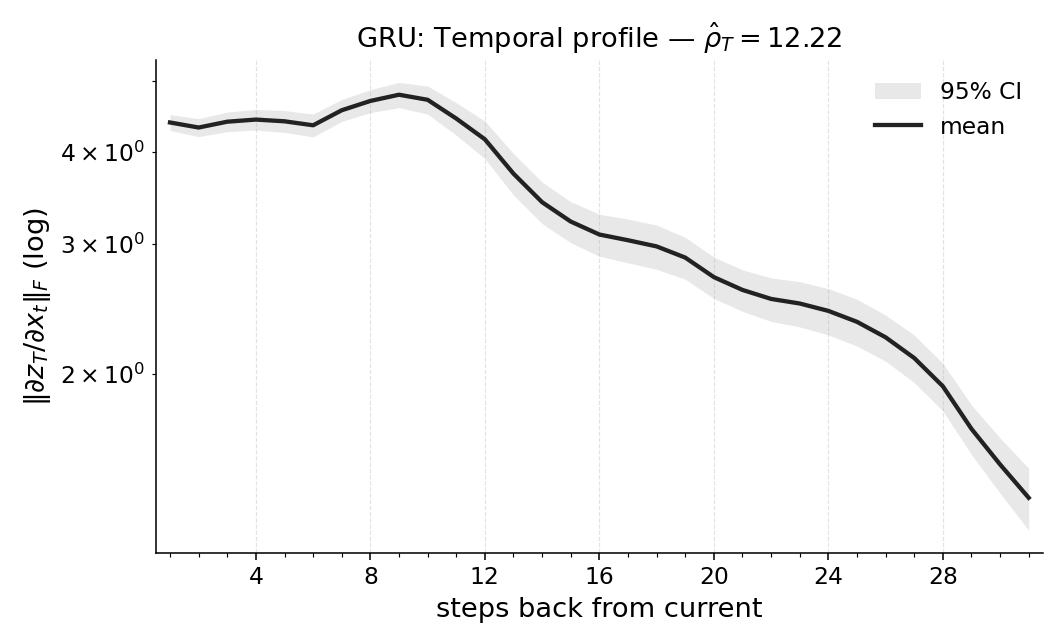
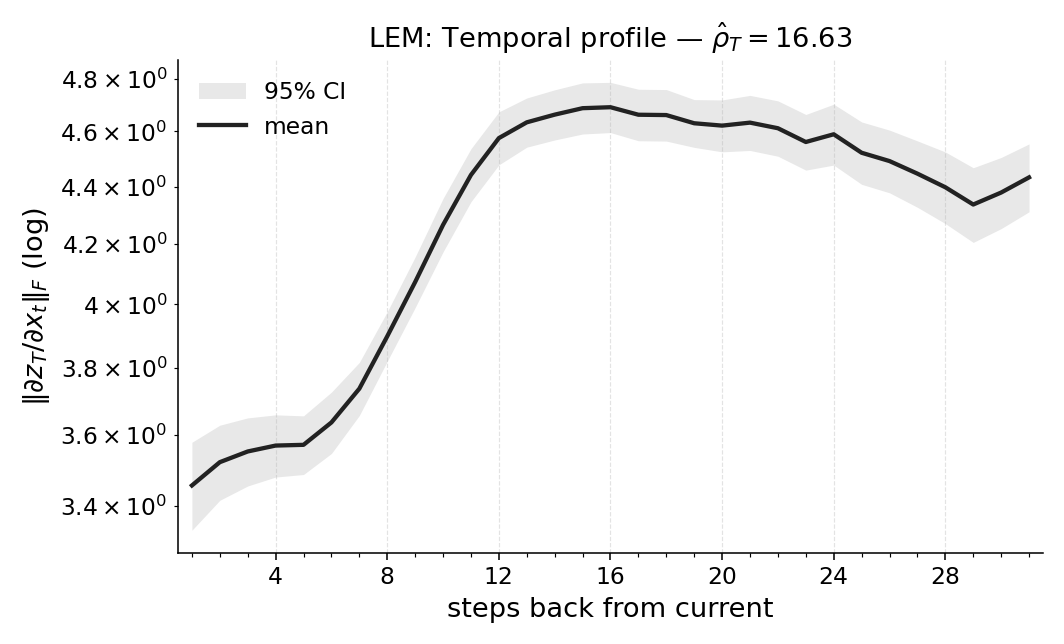
over lags into a magnitude-weighted average look-back, axiomatized for uniqueness. Concretely,
for each position t we average Jacobian norms ∥Js,t∥mat over all subsequent final timesteps s ∈
1
arXiv:2512.06204v1 [cs.LG] 5 Dec 2025
{t + 1, . . . , T}, forming per-step weights wt =
1
T −t
PT
s=t+1 ∥Js,t∥mat, and report
ˆρT =
PT
t=1 wt (T −t)
PT
t=1 wt
∈[0, T−1],
with
T
X
t=1
wt > 0.
Thus ˆρT answers “how far back is this policy looking here?” at the level of a specific rollout and
timestep. Our theoretical starting point is the axioms of range from Bamberger et al. (2025); we
specialize them to temporal lag, extend to vector-valued outputs, and study their consequences for
reinforcement learning agents.
For vector-output linear maps we give a short axiomatic derivation that fixes both the unnormalized
and normalized forms: single-step calibration, additivity over disjoint time indices (or magnitude-
weighted averaging), and absolute homogeneity identify the unique matrix-norm–weighted lag
sums/averages. The same formulas applied to the local linearization yield our nonlinear policy
metric. The normalized form is invariant to uniform input rescaling (change of units) and uniform
output rescaling, making cross-agent and cross-environment comparisons straightforward.
Computationally, Temporal Range is inexpensive. The required Jacobian blocks are policy deriva-
tives with respect to observation inputs and can be obtained with standard reverse-mode automatic
differentiation on the policy alone. When direct auto-differentiation on a given model is impractical,
we train a compact LEM policy on the same task and compute the same quantities on this proxy.
We validate Temporal Range across POPGym diagnostics and classic control with Multi-Layer Per-
ceptrons (MLPs), gated RNNs (e.g., LSTMs, Gated Recurrent Units (GRUs) (Chung et al., 2014),
and LEM), as well as SSMs. The metric (i) stays near zero in fully