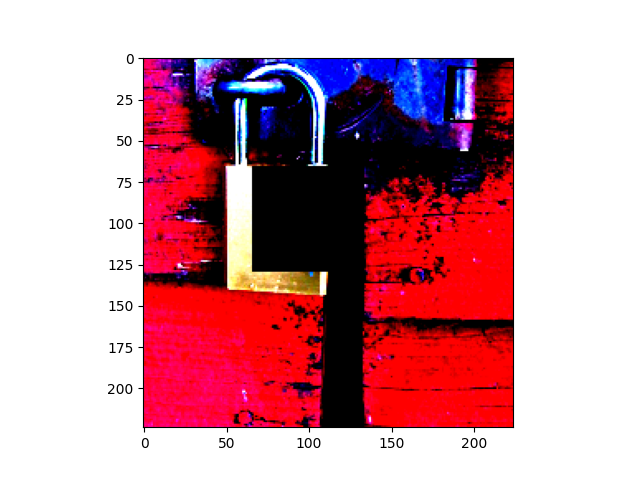
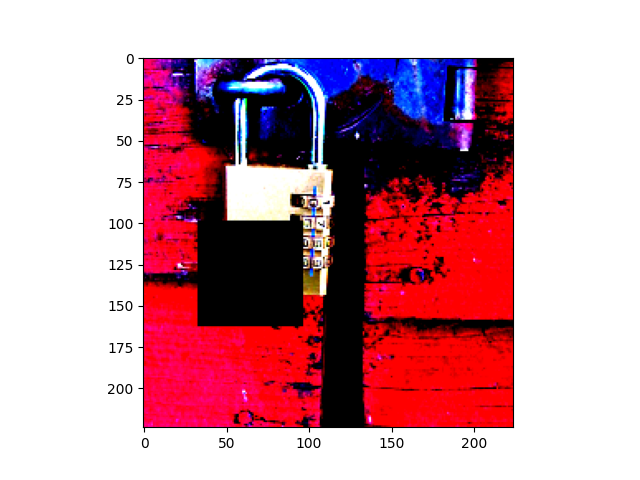
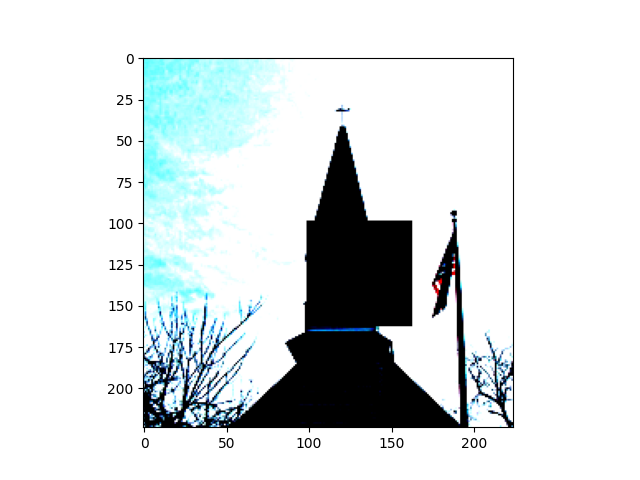
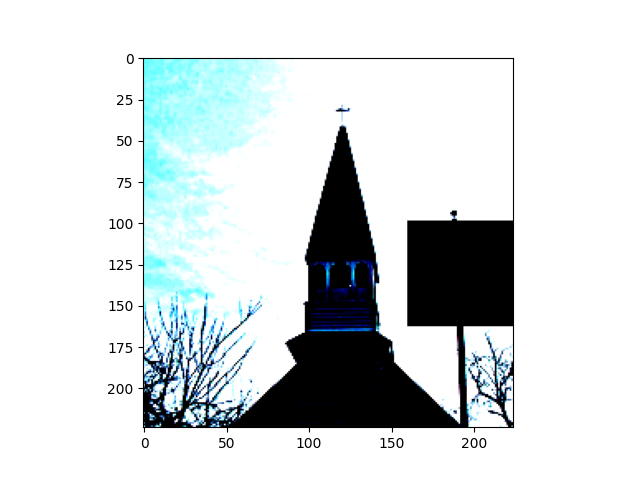
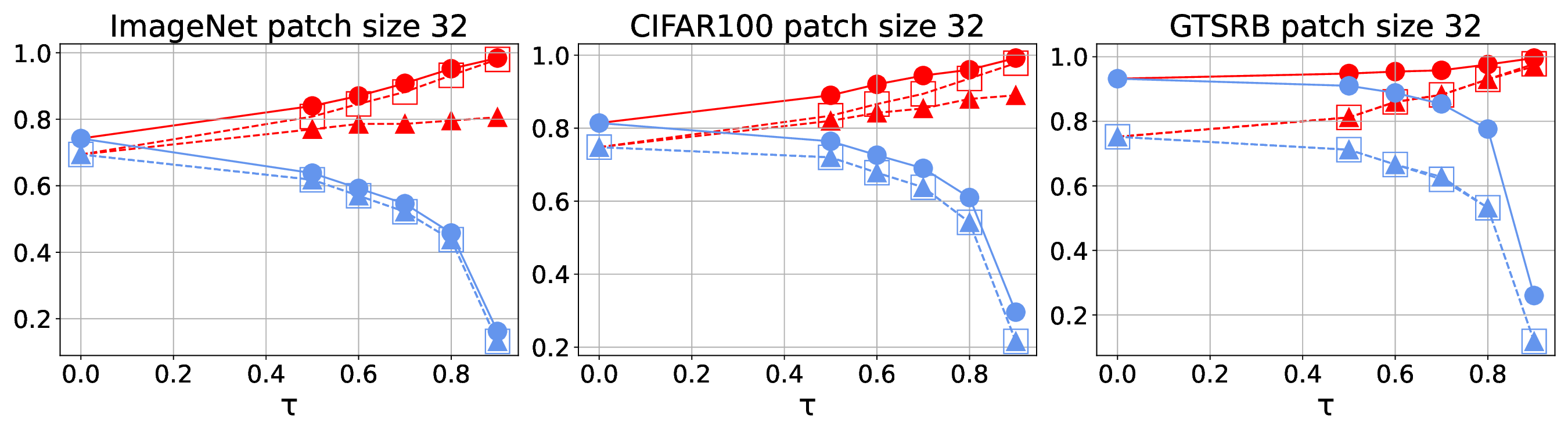
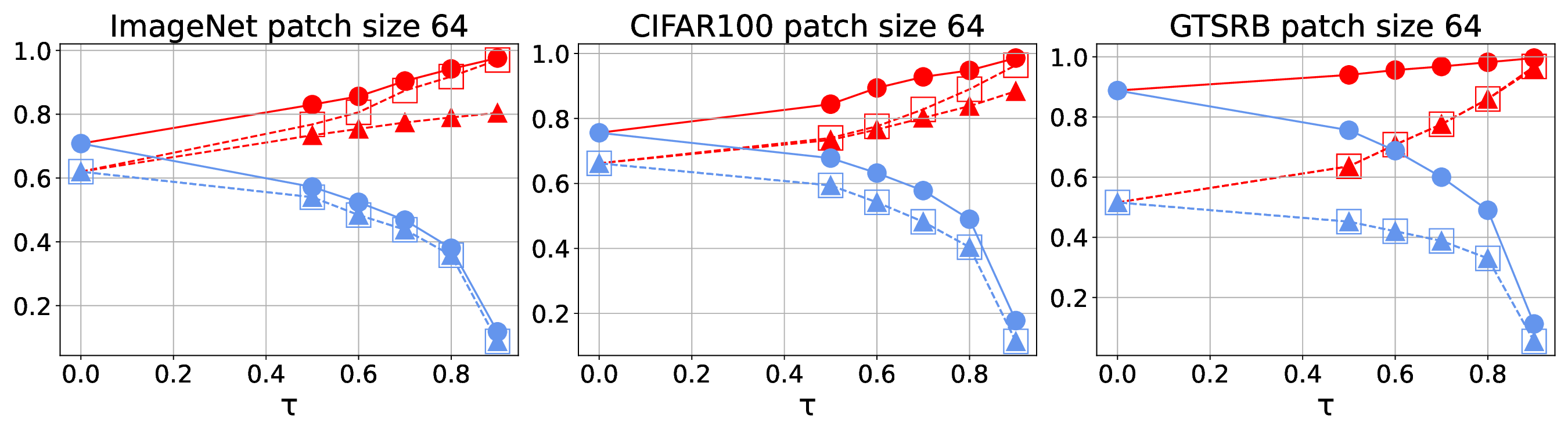
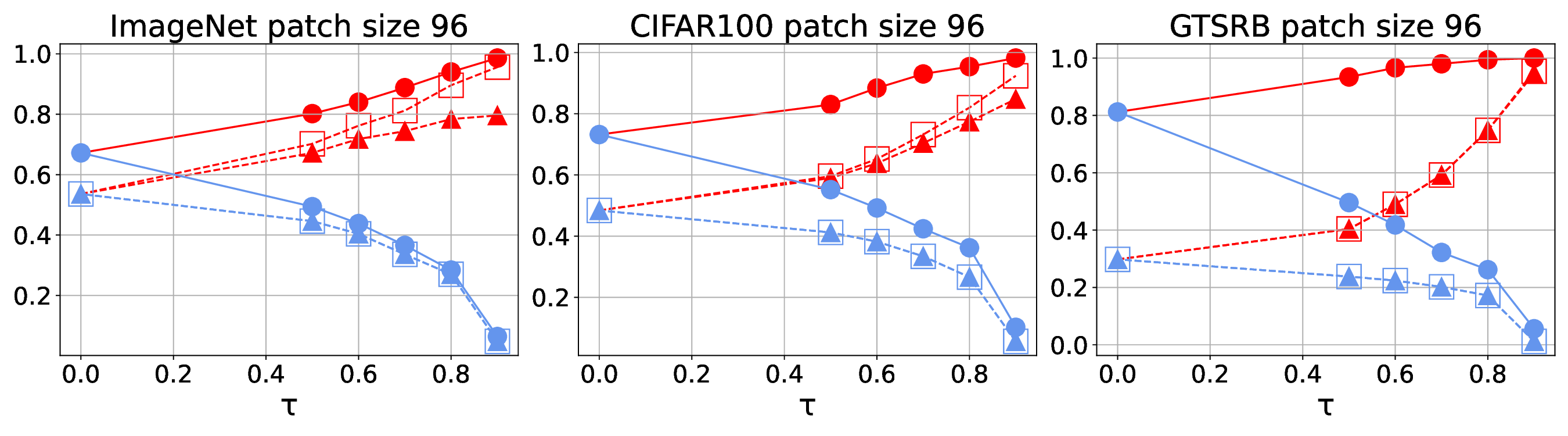
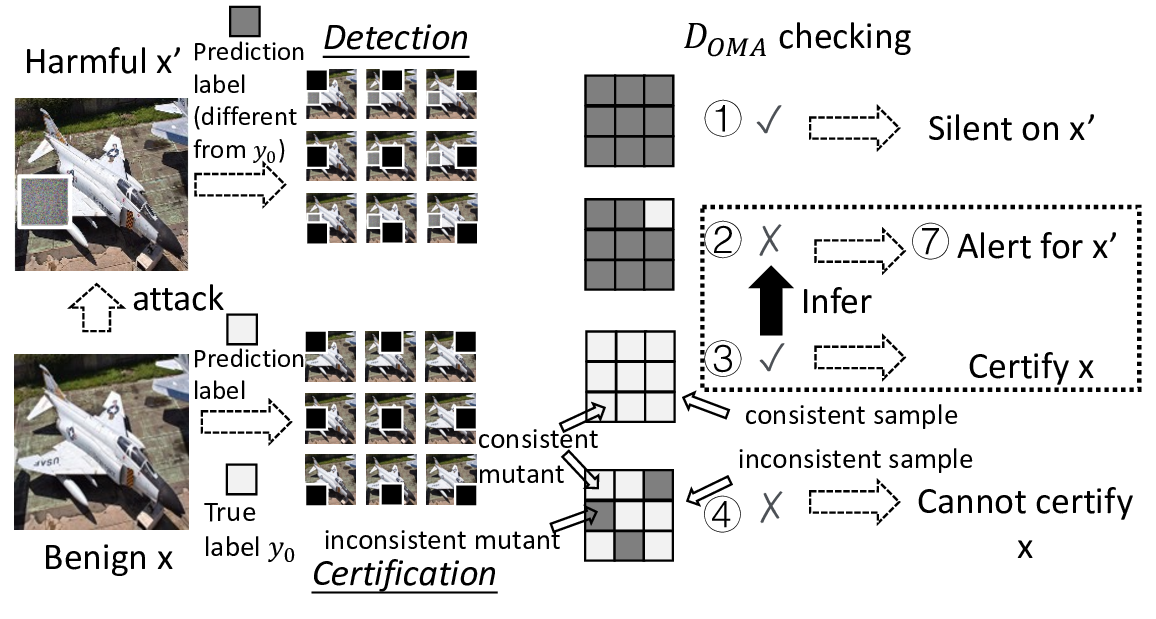
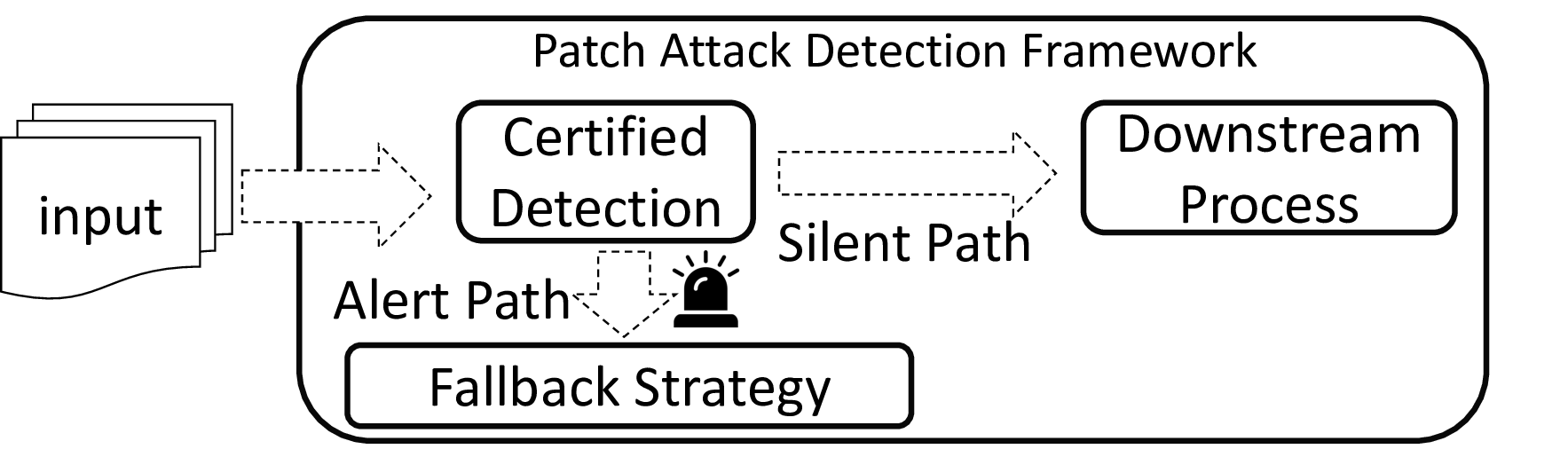
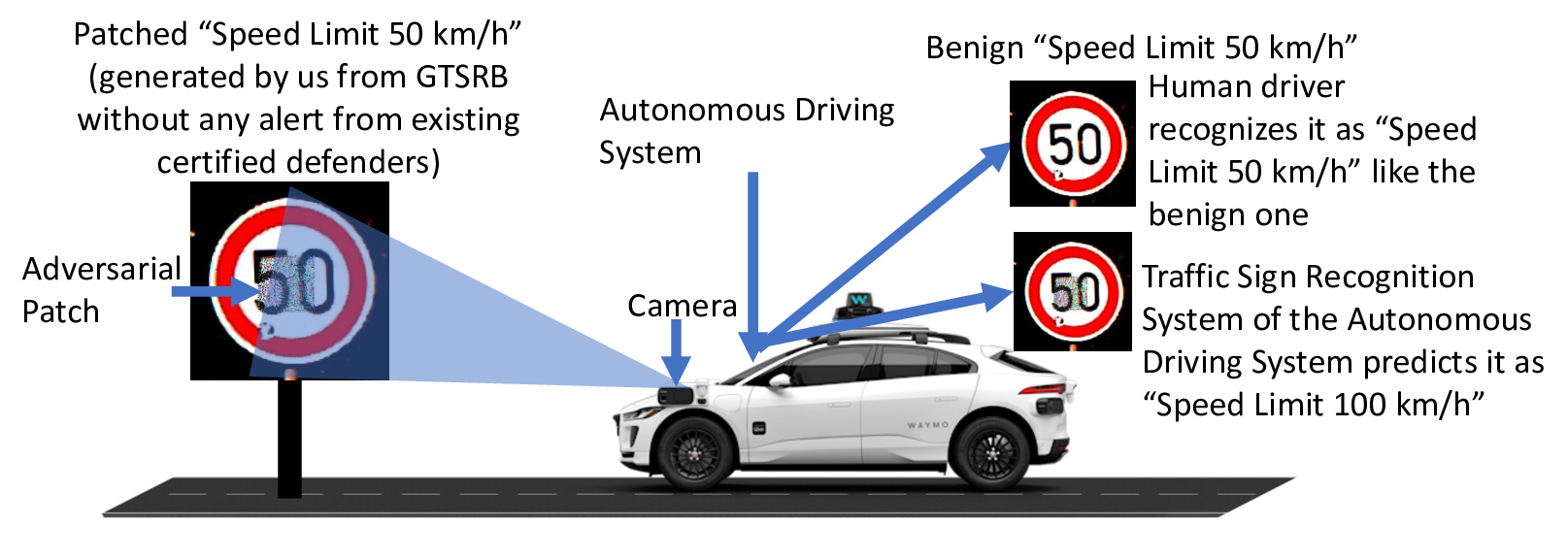
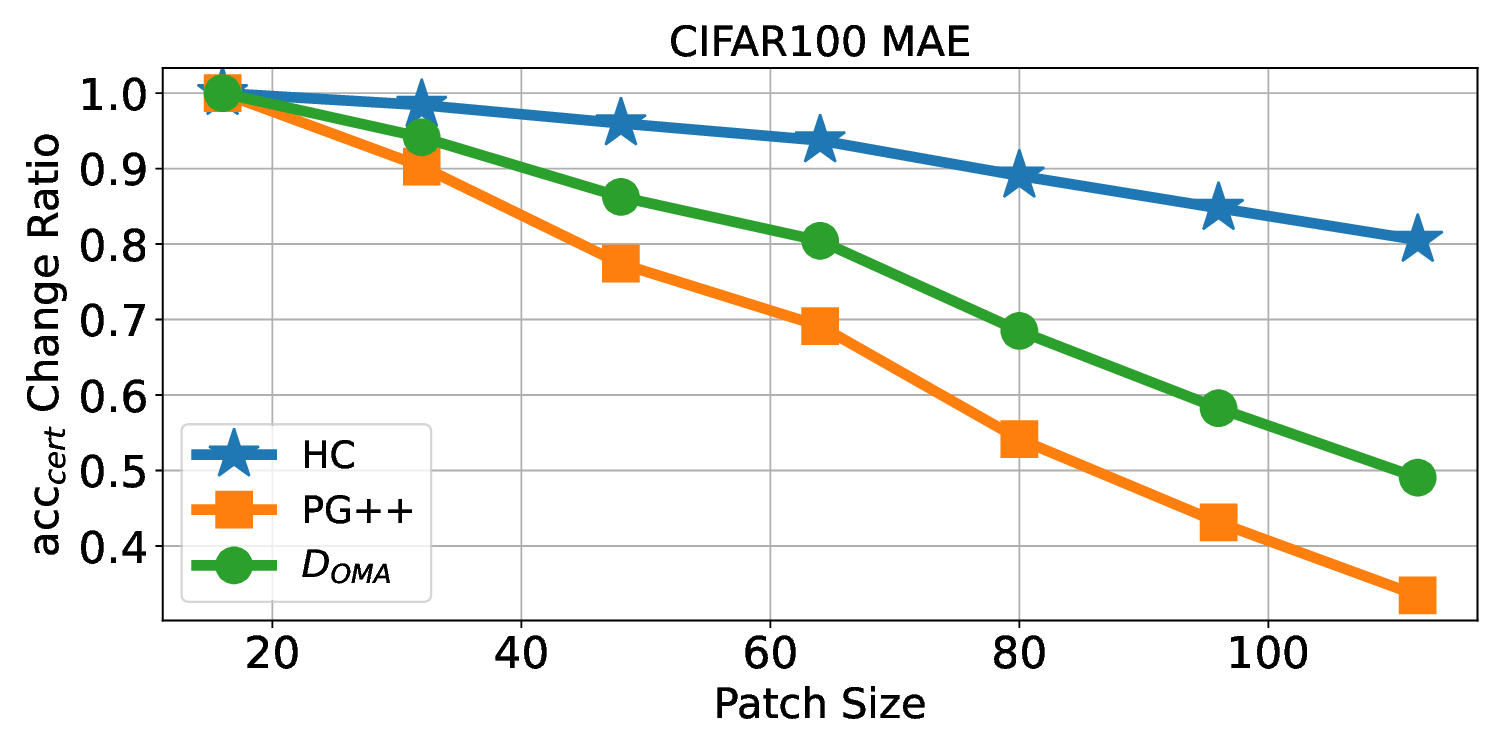
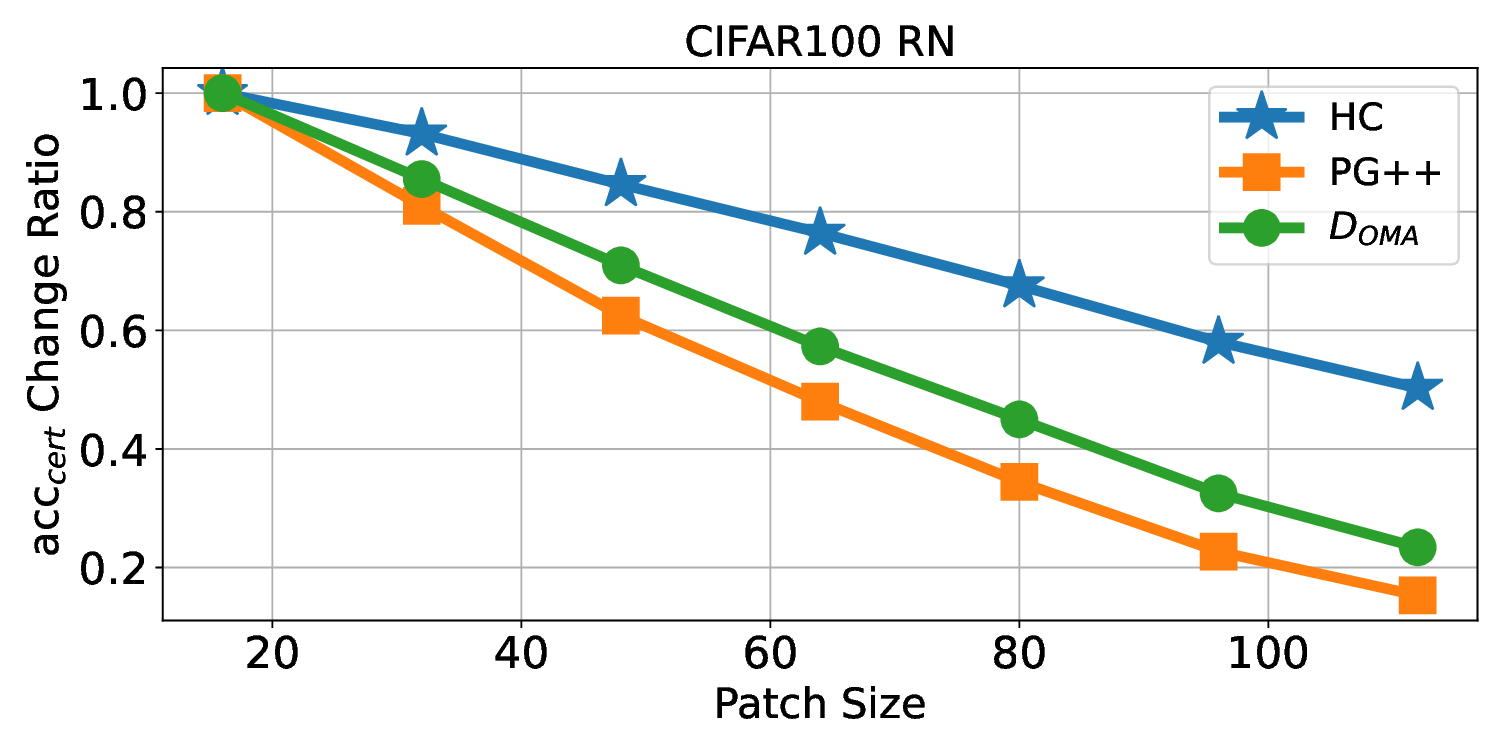
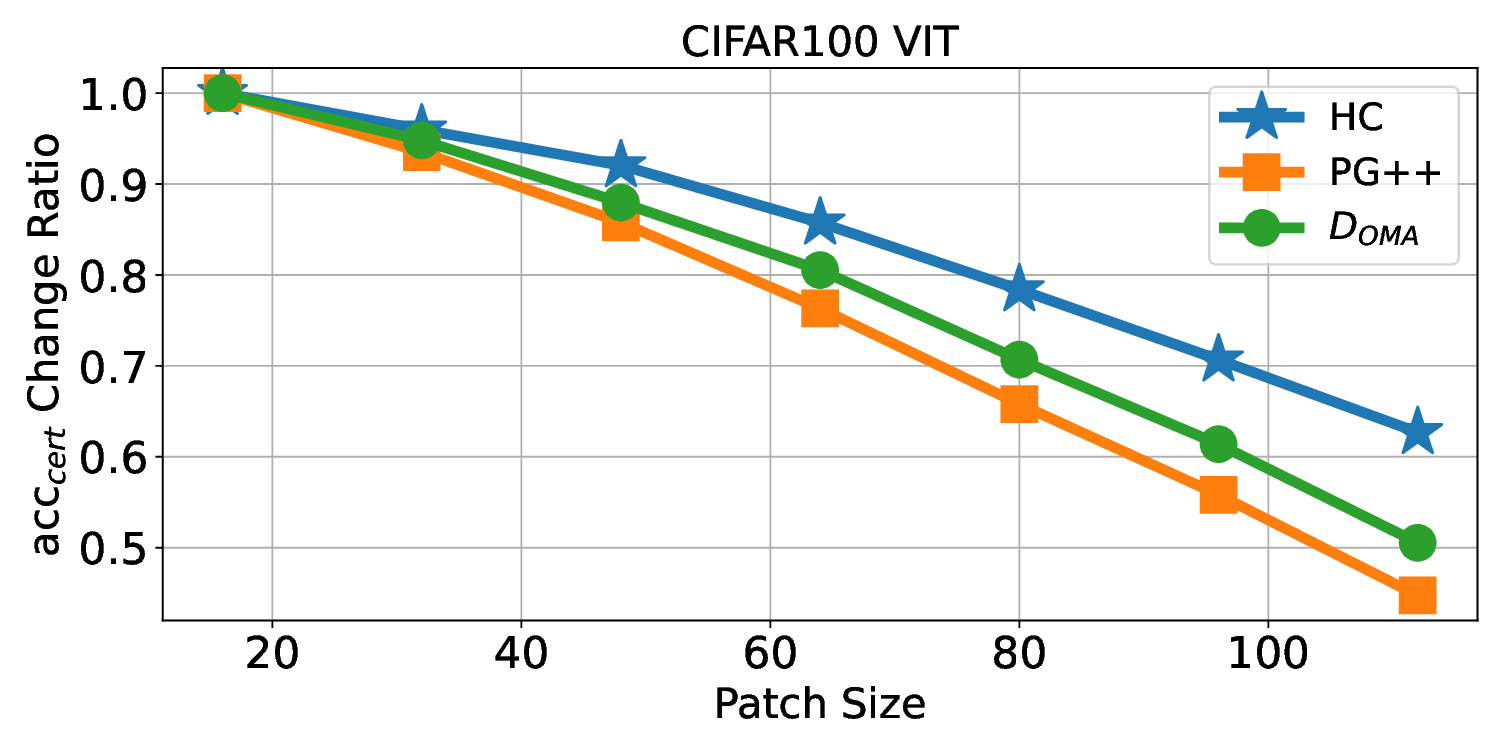
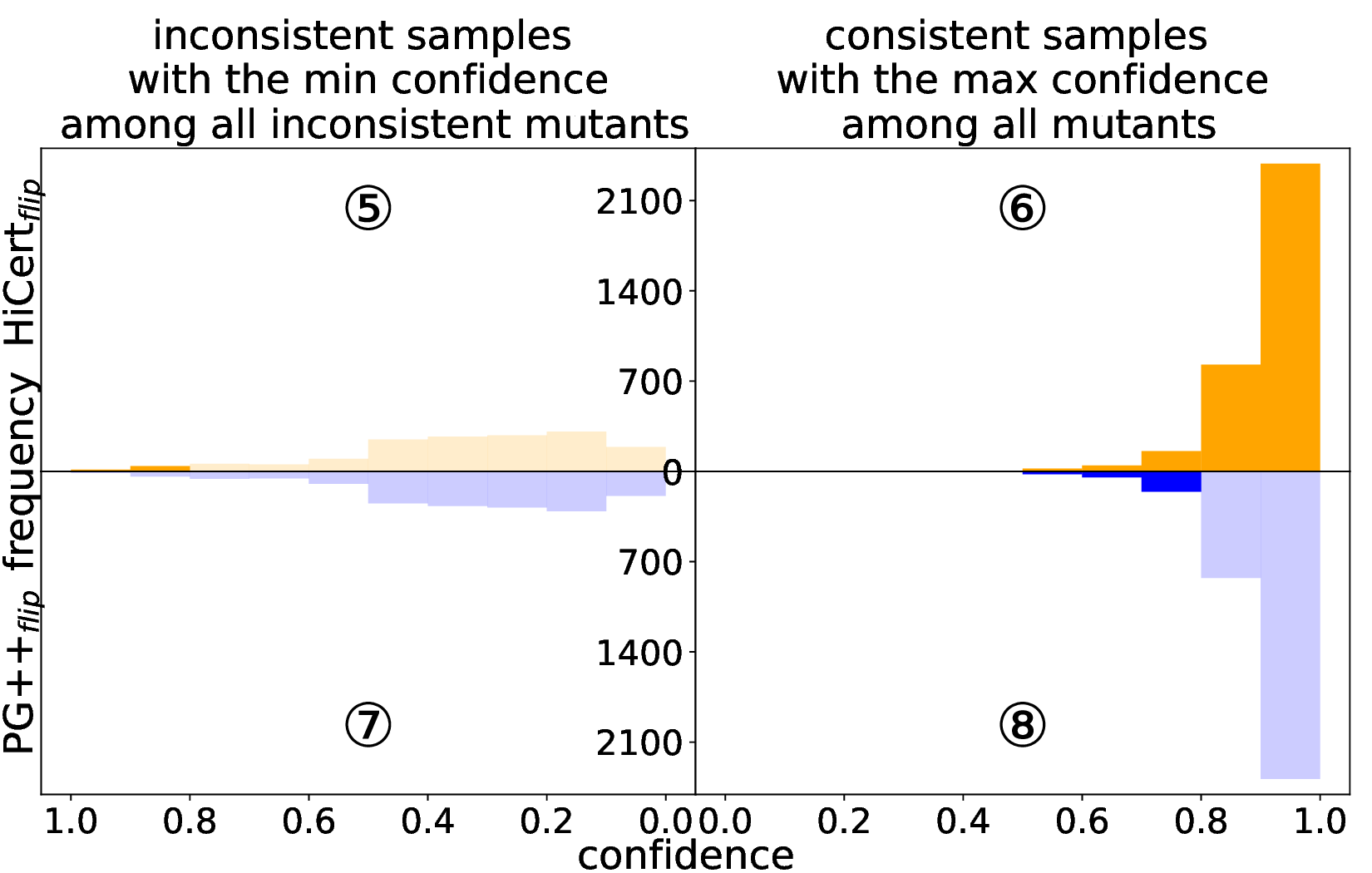
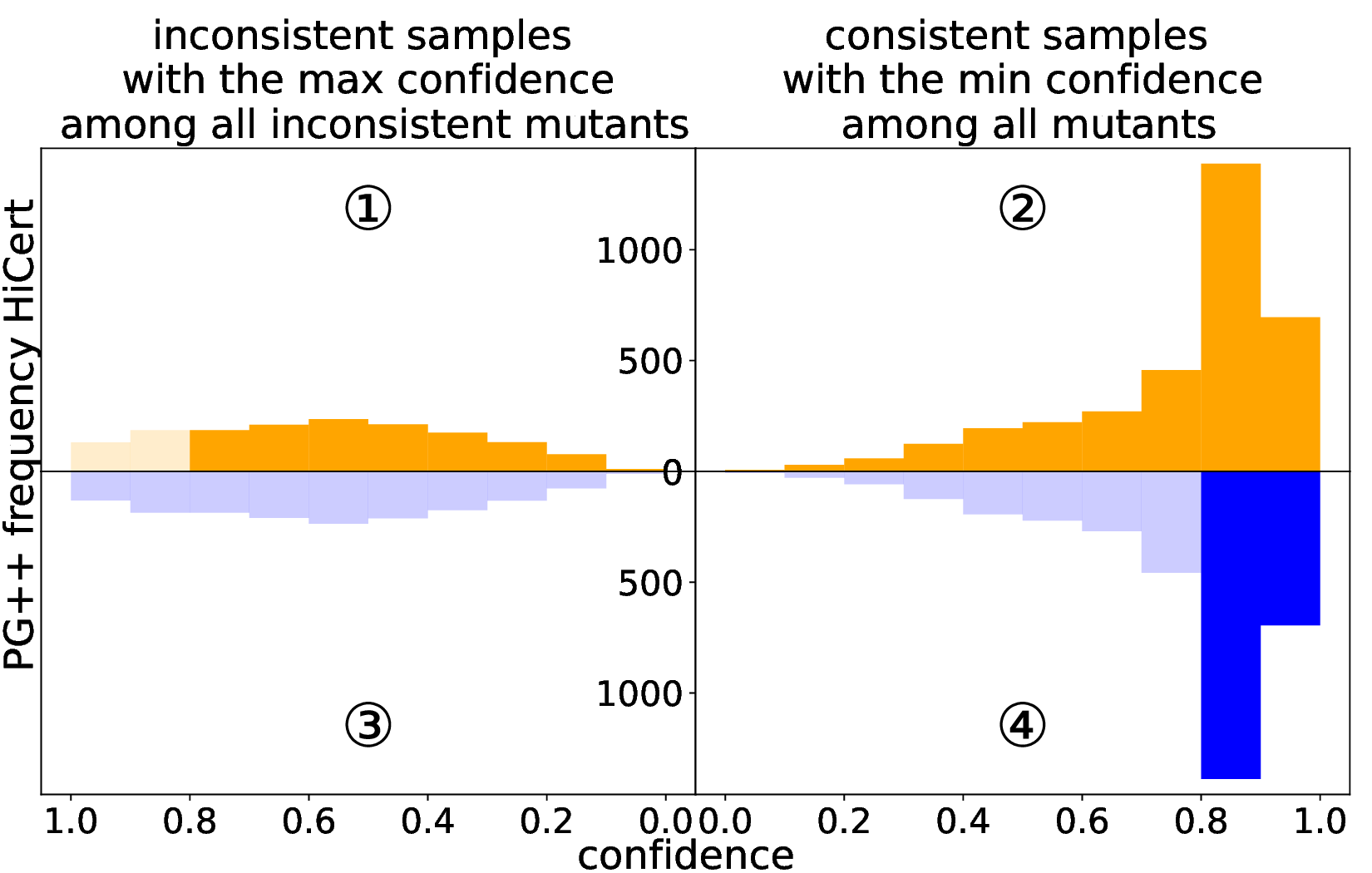
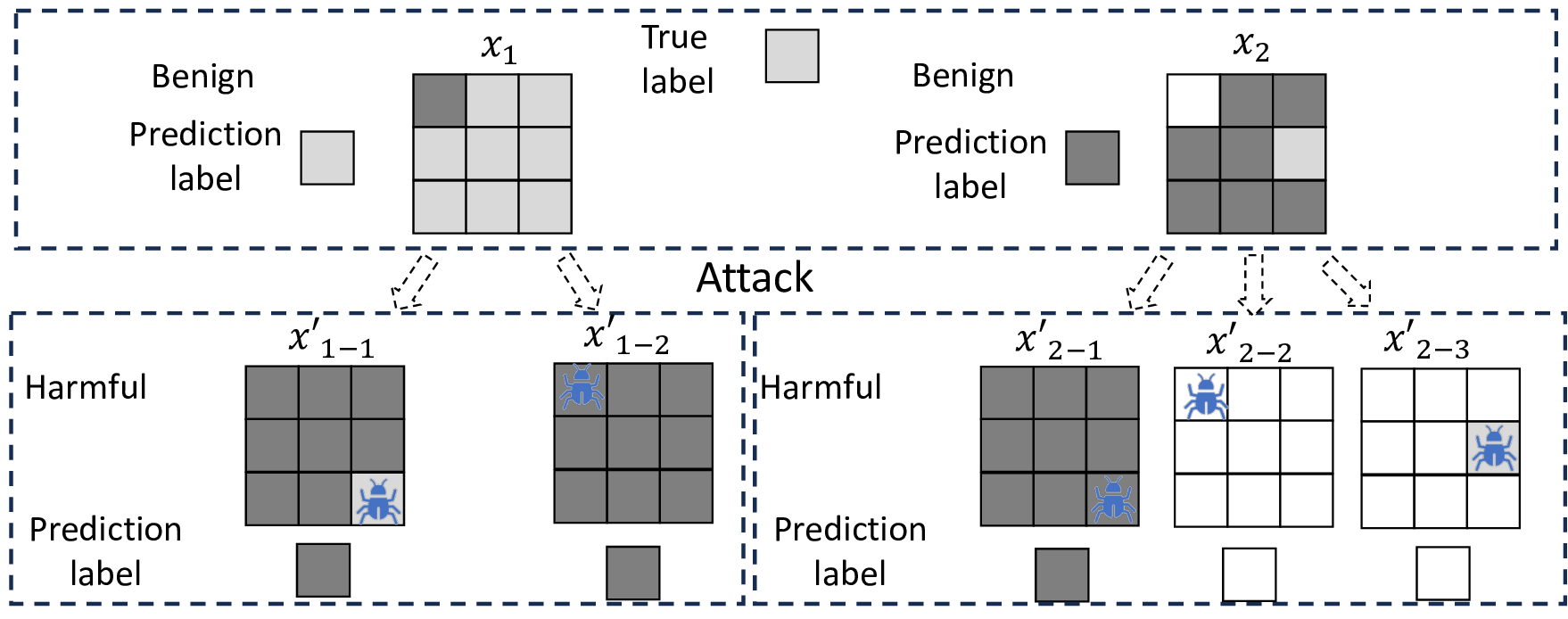
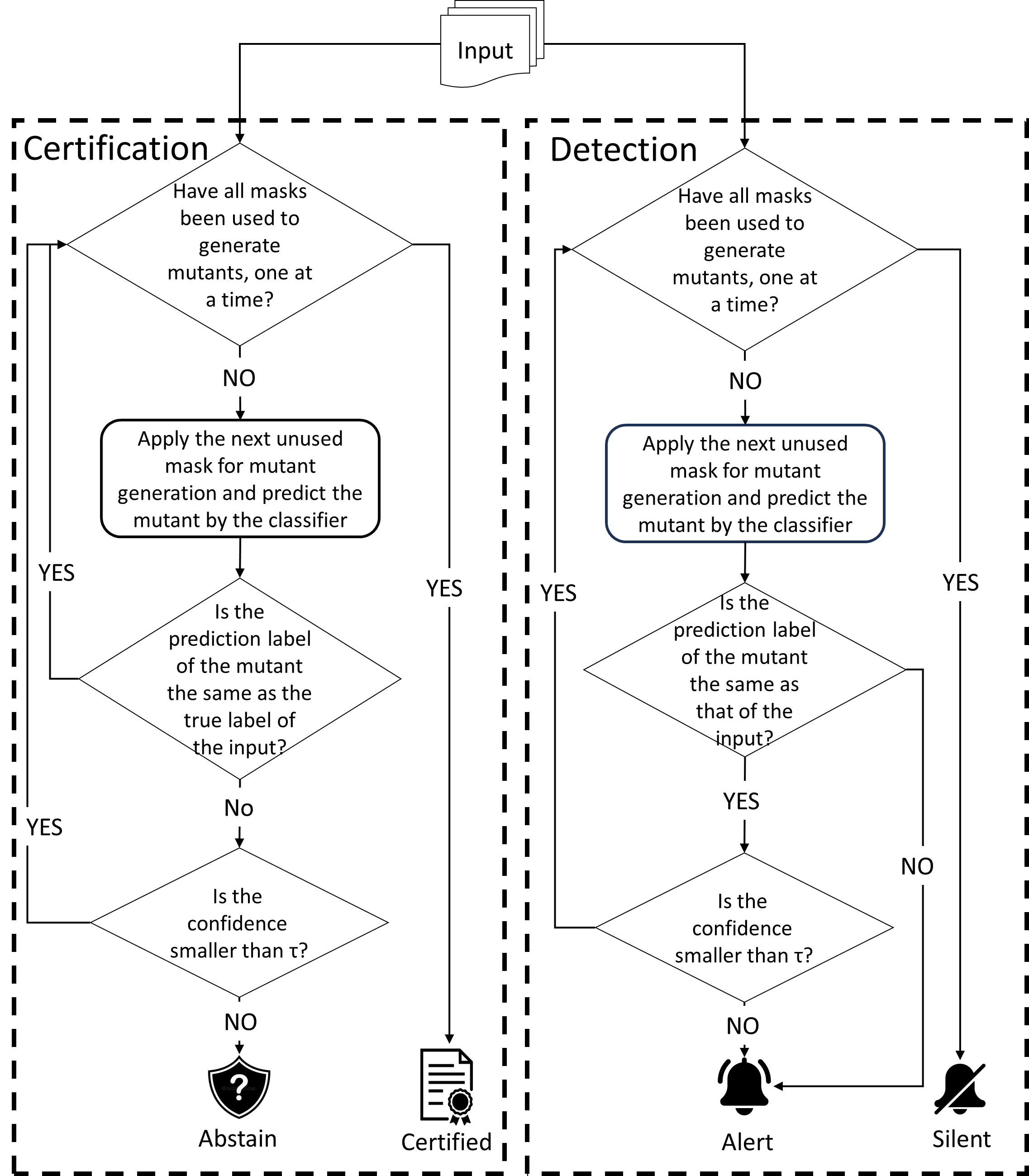
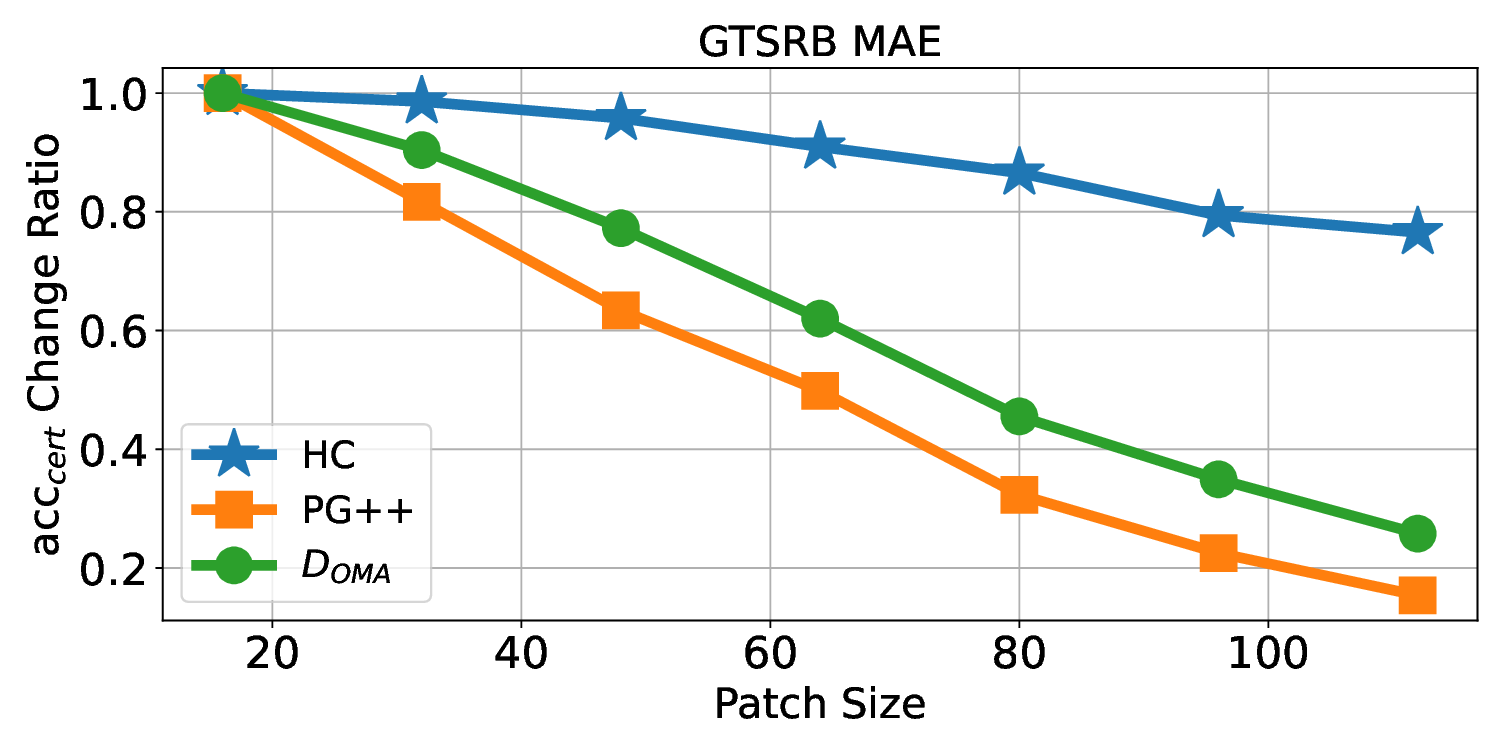
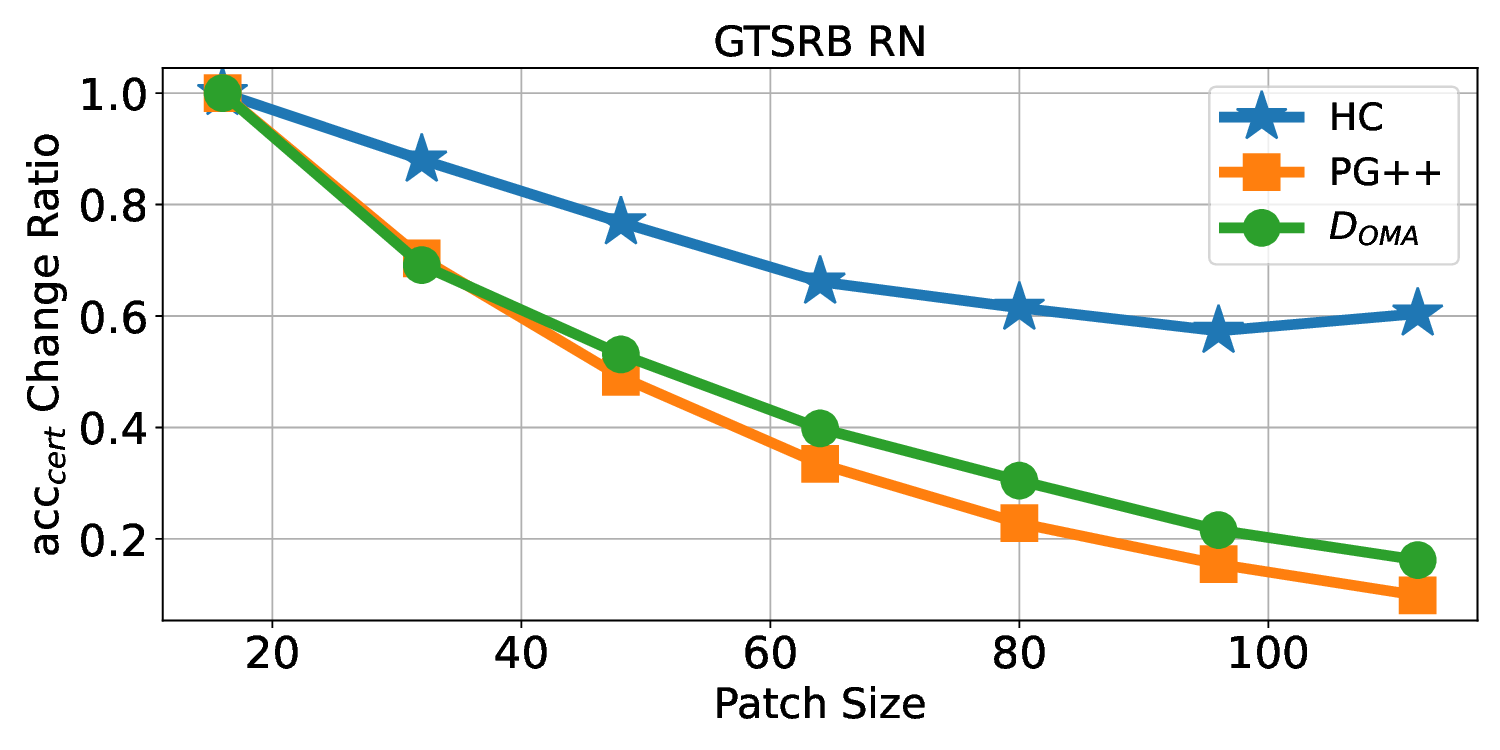
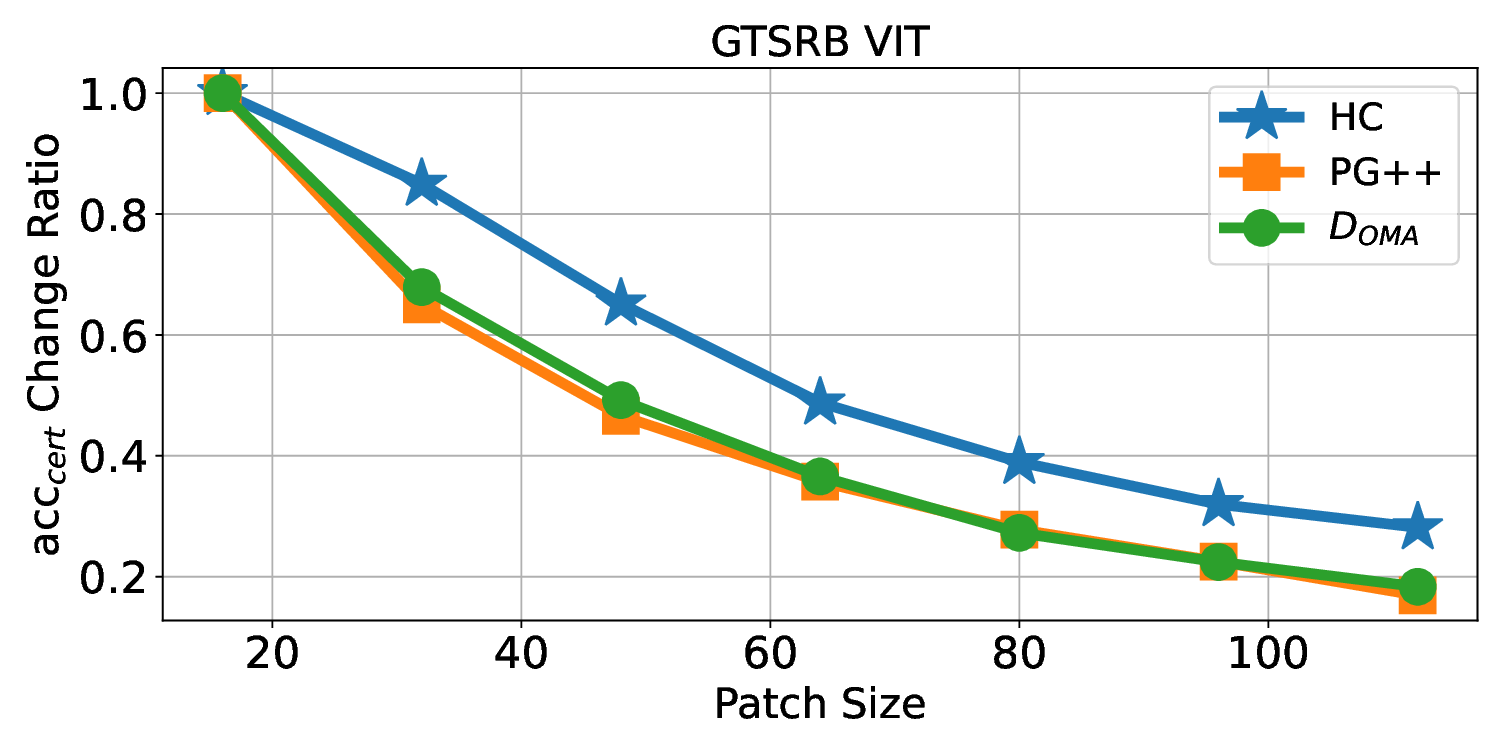
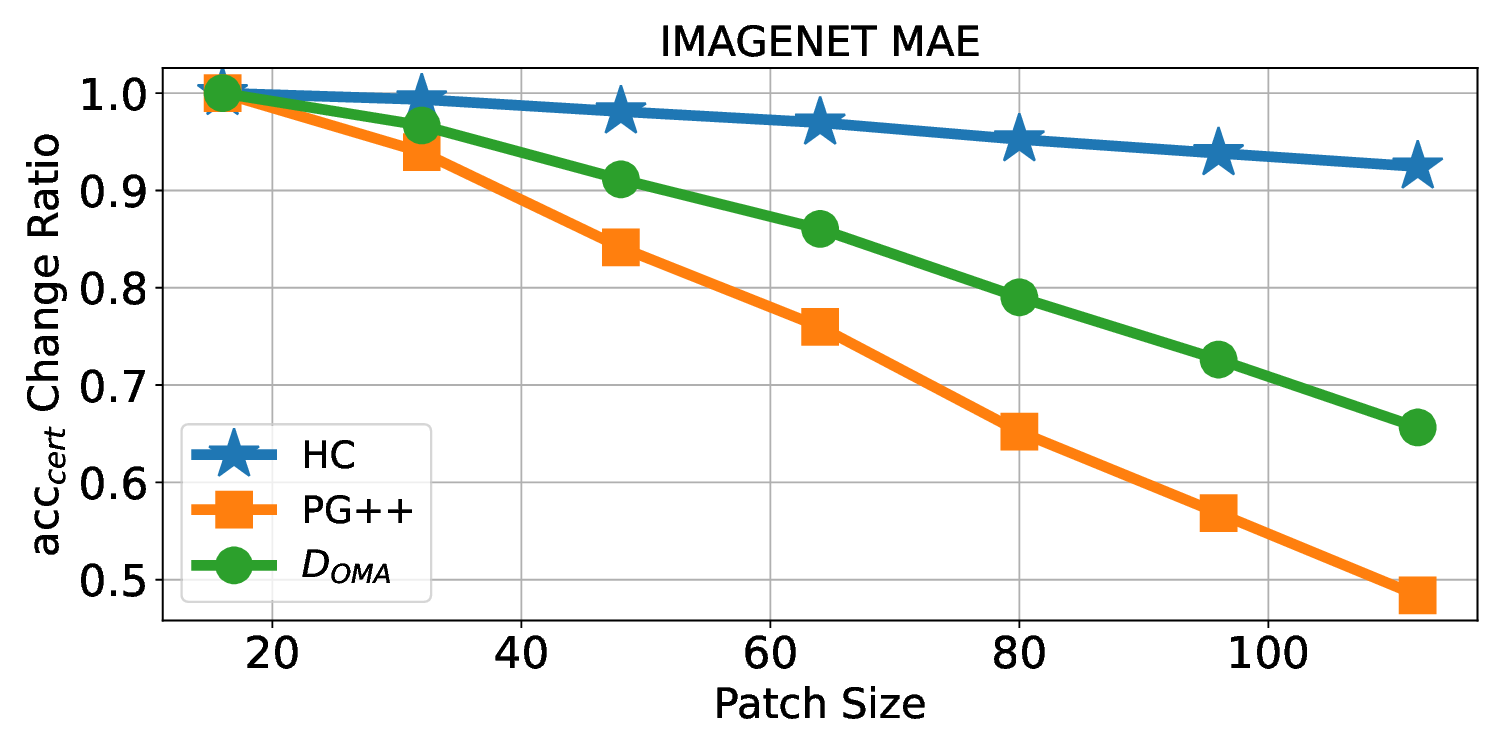
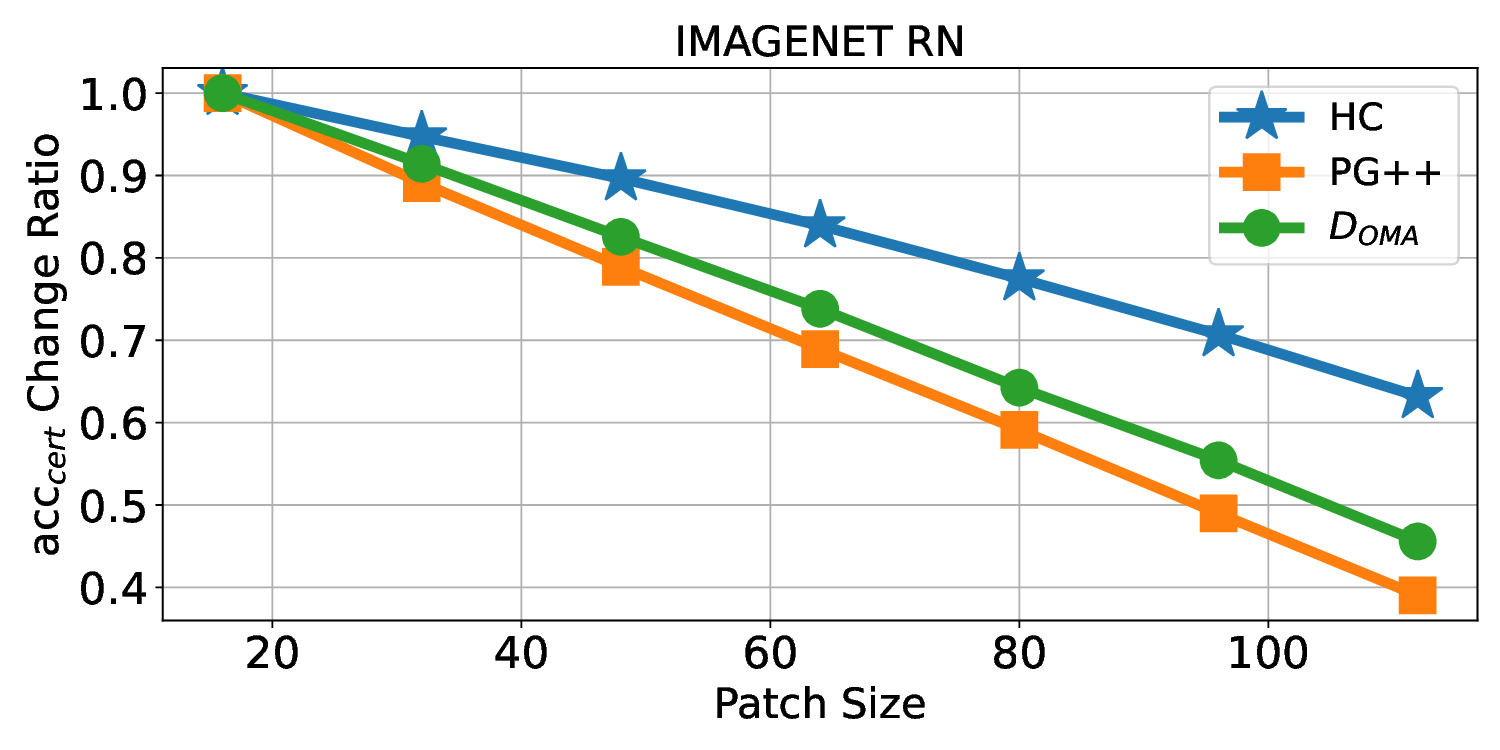
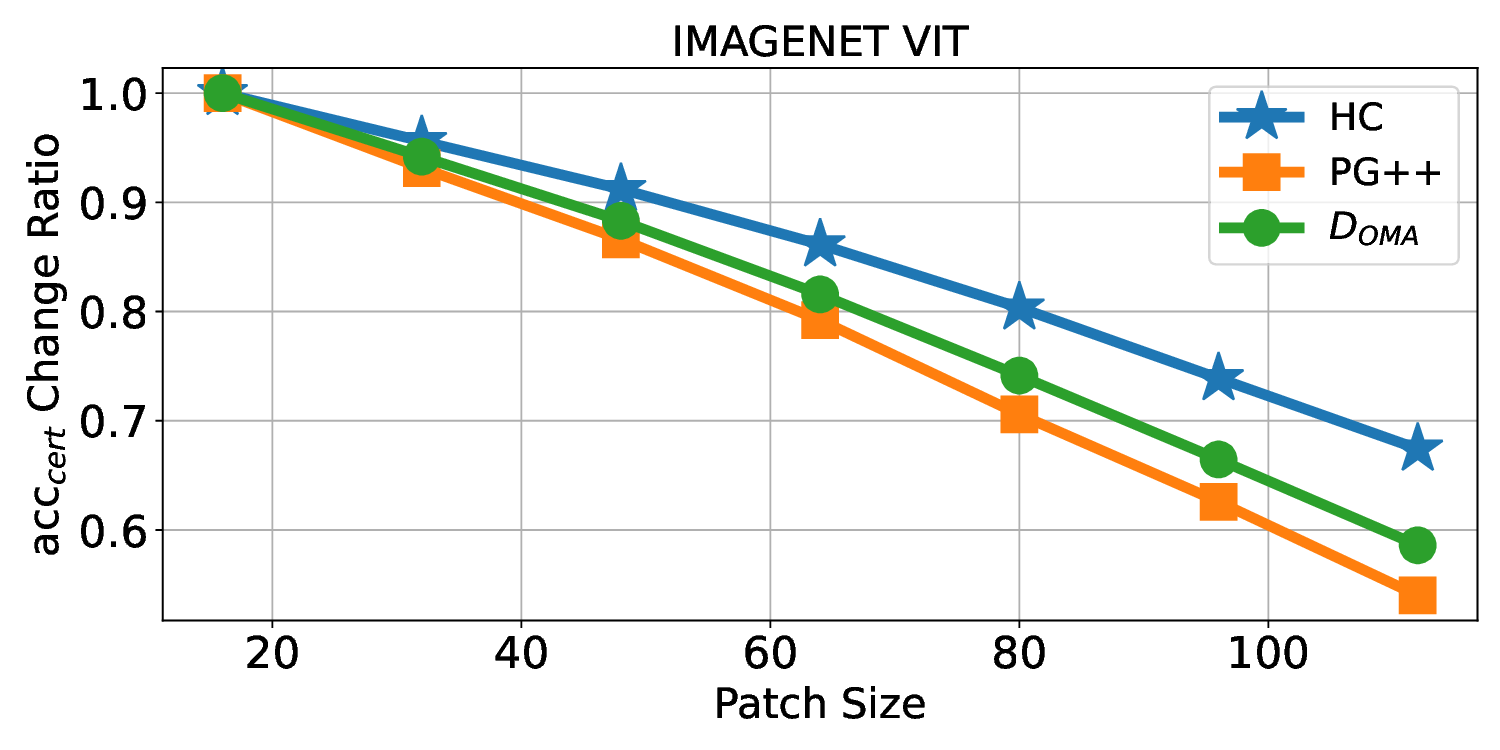
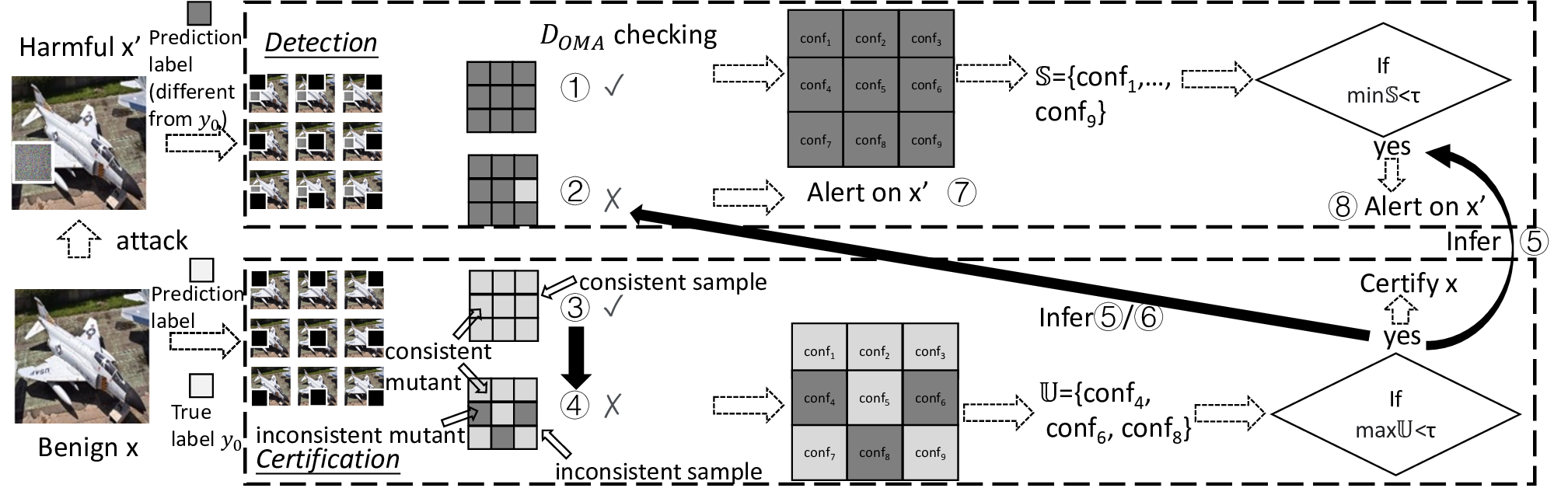
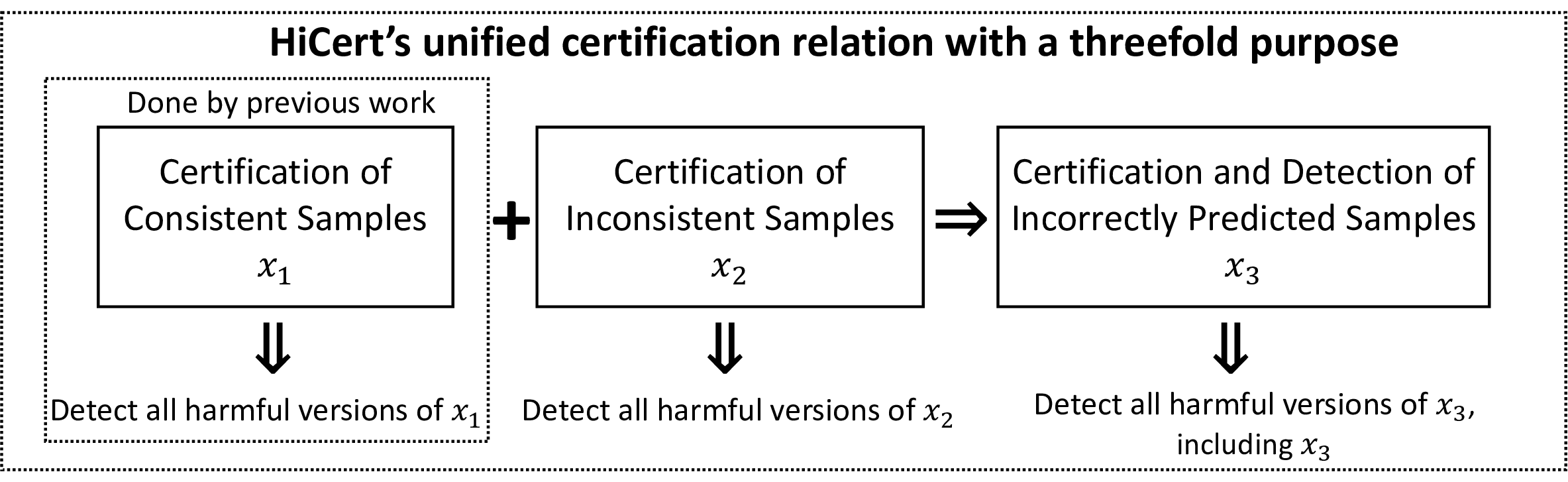
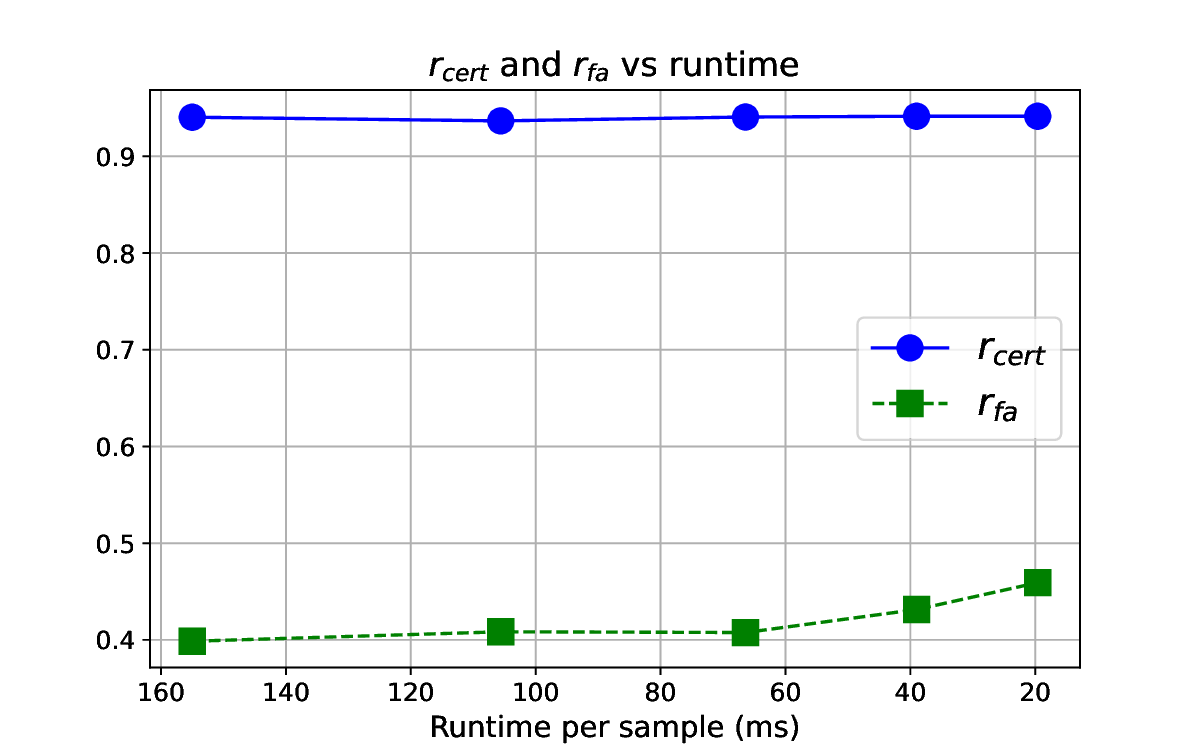
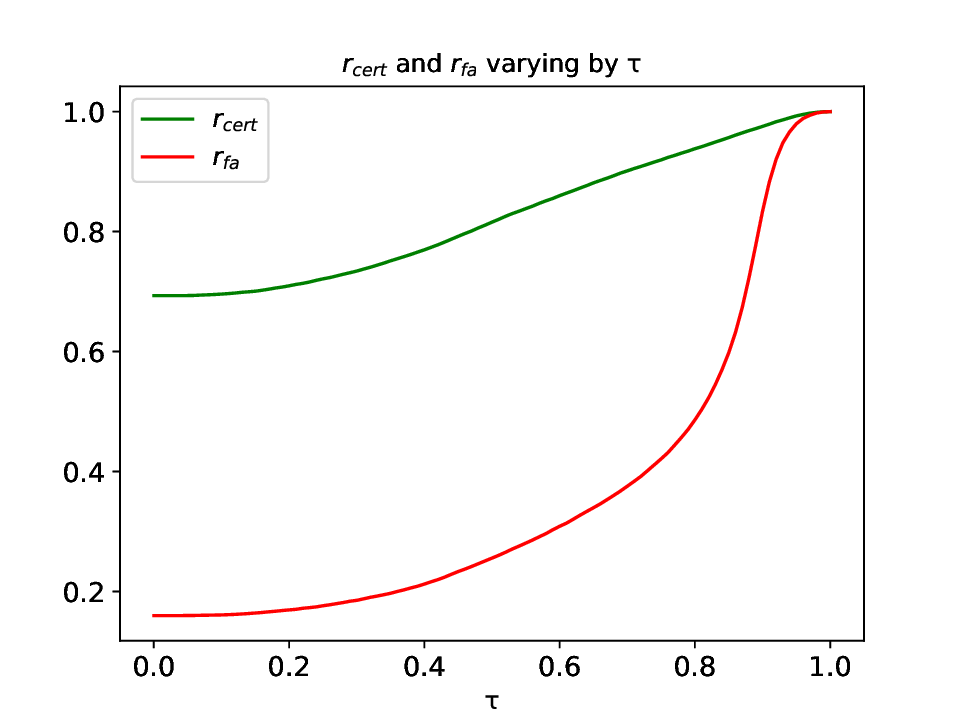
Patch robustness certification is an emerging kind of provable defense technique against adversarial patch attacks for deep learning systems. Certified detection ensures the detection of all patched harmful versions of certified samples, which mitigates the failures of empirical defense techniques that could (easily) be compromised. However, existing certified detection methods are ineffective in certifying samples that are misclassified or whose mutants are inconsistently pre icted to different labels. This paper proposes HiCert, a novel masking-based certified detection technique. By focusing on the problem of mutants predicted with a label different from the true label with our formal analysis, HiCert formulates a novel formal relation between harmful samples generated by identified loopholes and their benign counterparts. By checking the bound of the maximum confidence among these potentially harmful (i.e., inconsistent) mutants of each benign sample, HiCert ensures that each harmful sample either has the minimum confidence among mutants that are predicted the same as the harmful sample itself below this bound, or has at least one mutant predicted with a label different from the harmful sample itself, formulated after two novel insights. As such, HiCert systematically certifies those inconsistent samples and consistent samples to a large extent. To our knowledge, HiCert is the first work capable of providing such a comprehensive patch robustness certification for certified detection. Our experiments show the high effectiveness of HiCert with a new state-of the-art performance: It certifies significantly more benign samples, including those inconsistent and consistent, and achieves significantly higher accuracy on those samples without warnings and a significantly lower false silent ratio.