Recent advances in generative video models have led to significant breakthroughs in high-fidelity video synthesis, specifically in controllable video generation where the generated video is conditioned on text and action inputs, e.g., in instruction-guided video editing and world modeling in robotics. Despite these exceptional capabilities, controllable video models often hallucinate - generating future video frames that are misaligned with physical reality - which raises serious concerns in many tasks such as robot policy evaluation and planning. However, state-of-the-art video models lack the ability to assess and express their confidence, impeding hallucination mitigation. To rigorously address this challenge, we propose C3, an uncertainty quantification (UQ) method for training continuous-scale calibrated controllable video models for dense confidence estimation at the subpatch level, precisely localizing the uncertainty in each generated video frame. Our UQ method introduces three core innovations to empower video models to estimate their uncertainty. First, our method develops a novel framework that trains video models for correctness and calibration via strictly proper scoring rules. Second, we estimate the video model's uncertainty in latent space, avoiding training instability and prohibitive training costs associated with pixel-space approaches. Third, we map the dense latent-space uncertainty to interpretable pixel-level uncertainty in the RGB space for intuitive visualization, providing high-resolution uncertainty heatmaps that identify untrustworthy regions. Through extensive experiments on large-scale robot learning datasets (Bridge and DROID) and real-world evaluations, we demonstrate that our method not only provides calibrated uncertainty estimates within the training distribution, but also enables effective out-of-distribution detection.
💡 Deep Analysis
📄 Full Content
World Models That Know When They Don’t Know:
Controllable Video Generation with Calibrated Uncertainty
Zhiting Mei1∗, Tenny Yin1, Micah Baker1, Ola Shorinwa1∗, Anirudha Majumdar1
1Princeton University
∗Equal contribution.
Recent advances in generative video models have led to significant breakthroughs in high-fidelity video
synthesis, specifically in controllable video generation where the generated video is conditioned on text
and action inputs, e.g., in instruction-guided video editing and world modeling in robotics. Despite
these exceptional capabilities, controllable video models often hallucinate—generating future video
frames that are misaligned with physical reality—which raises serious concerns in many tasks such as
robot policy evaluation and planning. However, state-of-the-art video models lack the ability to assess
and express their confidence, impeding hallucination mitigation. To rigorously address this challenge,
we propose C3, an uncertainty quantification (UQ) method for training continuous-scale calibrated
controllable video models for dense confidence estimation at the subpatch level, precisely localizing
the uncertainty in each generated video frame. Our UQ method introduces three core innovations to
empower video models to estimate their uncertainty. First, our method develops a novel framework
that trains video models for correctness and calibration via strictly proper scoring rules. Second, we
estimate the video model’s uncertainty in latent space, avoiding training instability and prohibitive
training costs associated with pixel-space approaches. Third, we map the dense latent-space uncertainty
to interpretable pixel-level uncertainty in the RGB space for intuitive visualization, providing high-
resolution uncertainty heatmaps that identify untrustworthy regions. Through extensive experiments
on large-scale robot learning datasets (Bridge and DROID) and real-world evaluations, we demonstrate
that our method not only provides calibrated uncertainty estimates within the training distribution,
but also enables effective out-of-distribution detection.
Keywords: Controllable Video Models, Uncertainty Quantification, Trustworthy Video Synthesis.
Website: c-cubed-uq.github.io
Code: github.com/irom-princeton/c-cubed
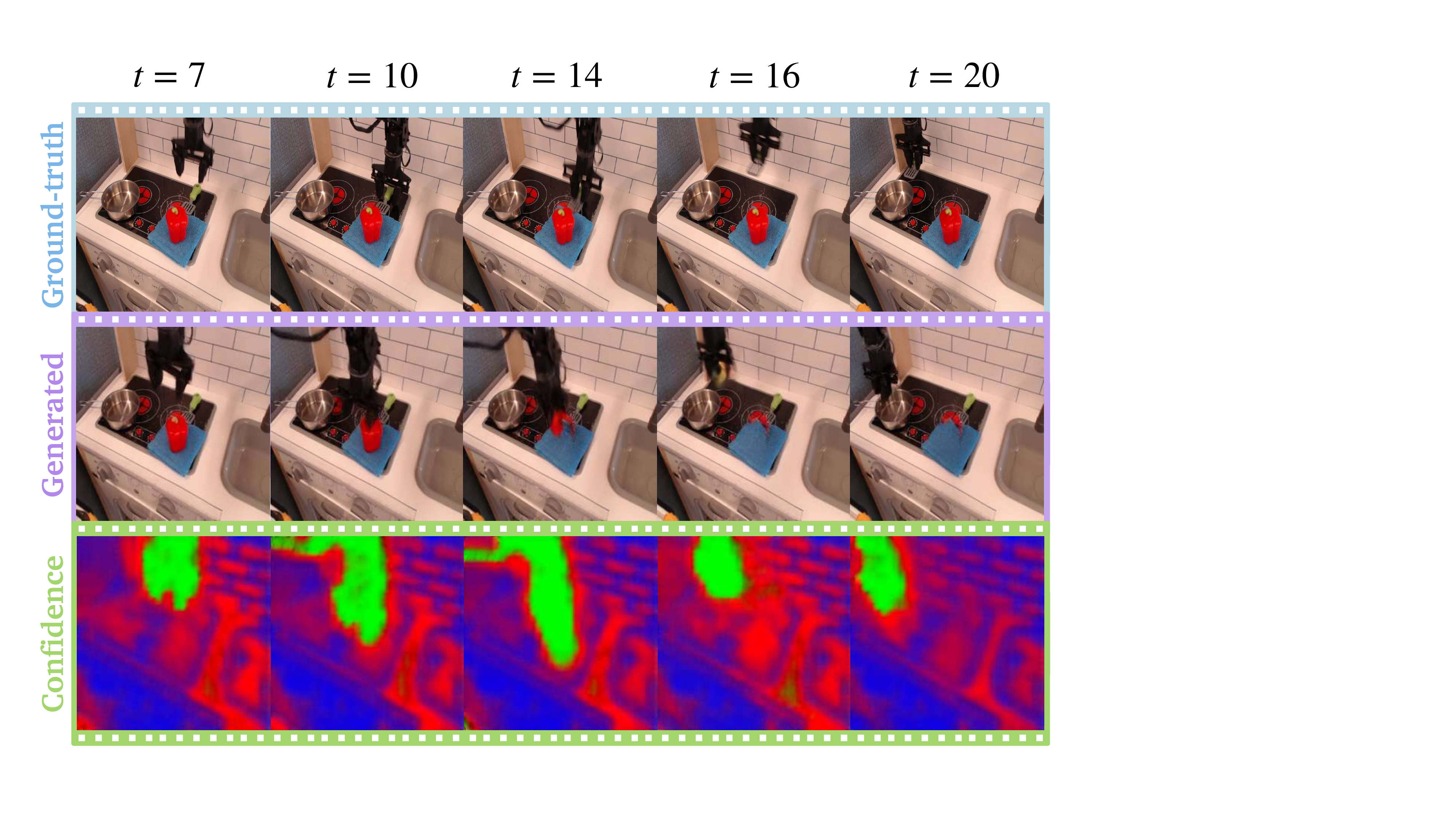
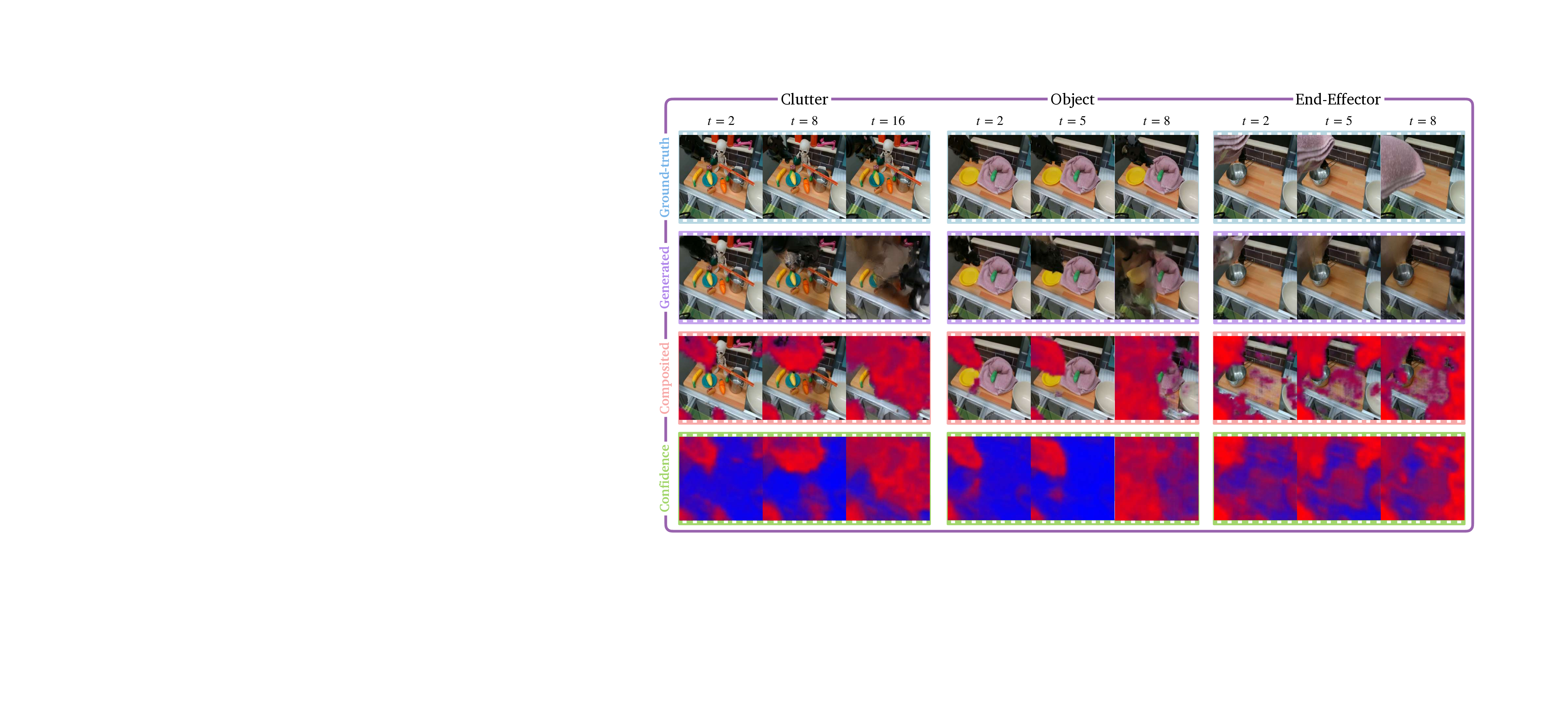
Figure 1 We present C3, the first method for training video models that know when they don’t know. Using proper
scoring rules, C3 generates dense confidence predictions at the subpatch (channel) level that are physically interpretable
and aligned with observations.
1
arXiv:2512.05927v1 [cs.CV] 5 Dec 2025
1
Introduction
Conditioned on text or action inputs, state-of-the-art (SOTA) controllable generative video models [1–4] are
capable of synthesizing high-fidelity videos with rich visual content across diverse task settings. However,
these models have a high propensity to hallucinate, i.e., to generate new video frames that are physically
inconsistent, posing a significant hurdle in applications that demand trustworthy video generation. For
example, such hallucinations prevent them from reliable integration in scalable evaluation of generalist robot
policies and visual planning [5–7]. Despite their tendency to hallucinate, video generation models lack the
fundamental capacity to express their uncertainty, which hinders their trustworthiness. To the best of our
knowledge, only one existing work attempts to quantify the uncertainty of video models [8]. However, the
resulting estimates only capture task-level uncertainty, failing to resolve the model’s uncertainty spatially and
temporally at the frame-level, which is essential for safe decision-making.
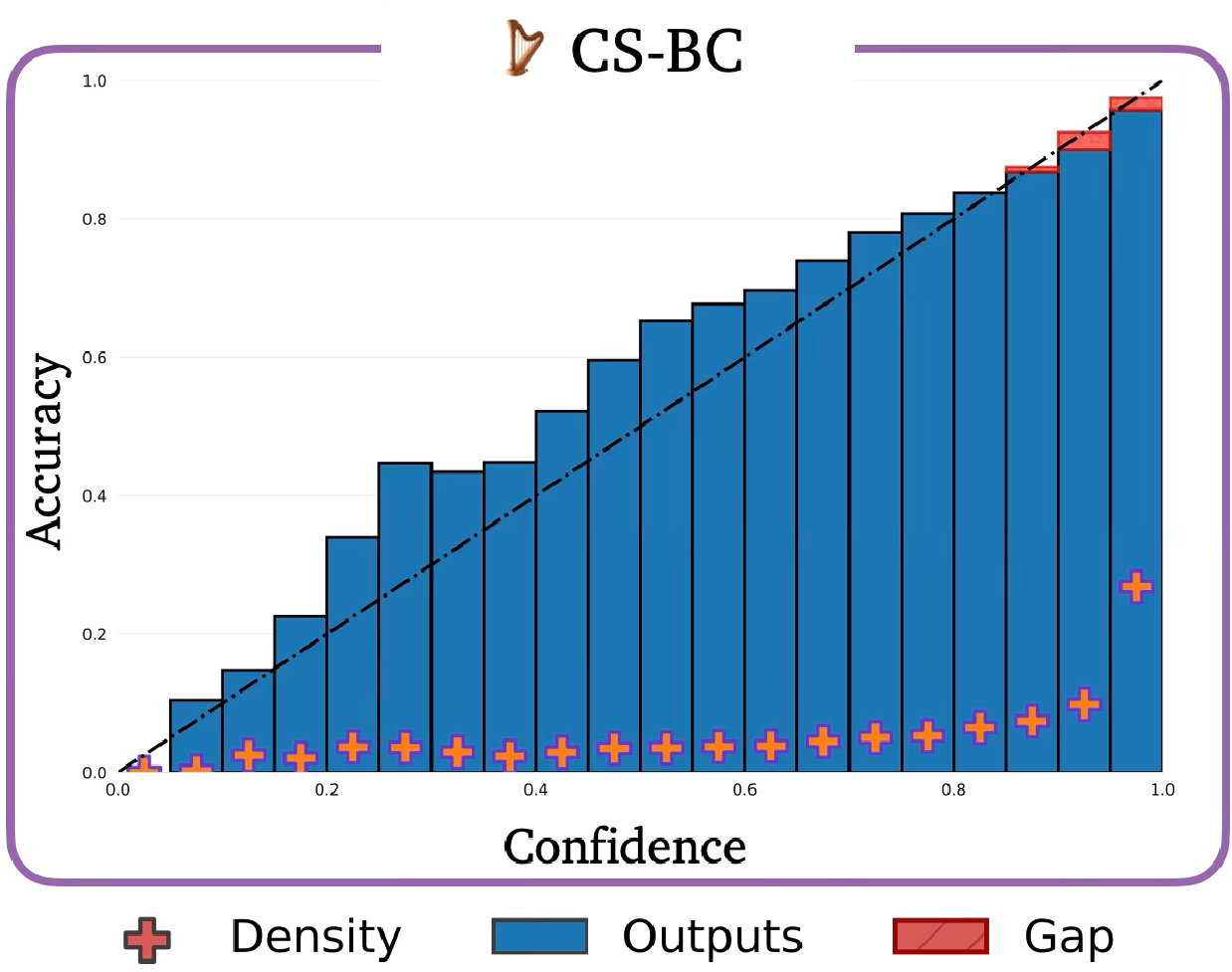
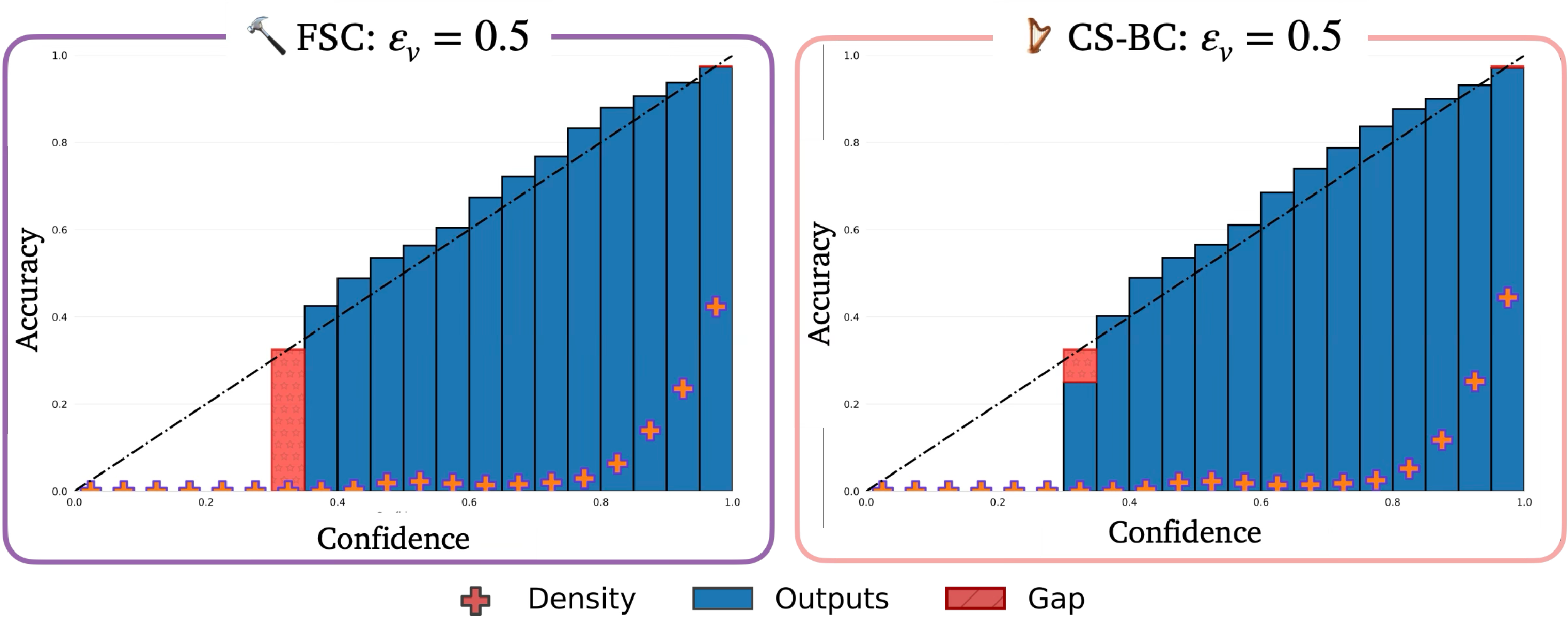
To address this critical challenge, we present C3, an uncertainty quantification (UQ) method for calibrated
controllable video synthesis, enabling subpatch-level confidence prediction at any resolution in video generation
accuracy, i.e., at continuous scales. We make three central contributions to derive continuous-scale calibrated
controllable video generation models. First, we introduce a novel framework for training video generation
models for both accuracy and calibration, founded on proper scoring rules as loss functions, effectively
teaching video models to quantify their uncertainty during the video generation process. We demonstrate
that the resulting uncertainty estimates are well-calibrated (i.e., neither underconfident nor overconfident)
using benchmark robot learning datasets, including the Bridge [9] and DROID [10] datasets.
Second, we derive our UQ method directly in the latent space of the video model. This key design choice
circumvents the high computation costs associated with video generation in the (higher-dimensional) pixel
space. Further, operating in the latent space streamlines applicability of our proposed method to a wide
range of SOTA latent-space video model architectures [1–3], without requiring specialized knowledge or
adaptation for implementation. Moreover, we compute dense uncertainty estimates at the s