As healthcare increasingly turns to AI for scalable and trustworthy clinical decision support, ensuring reliability in model reasoning remains a critical challenge. Individual large language models (LLMs) are susceptible to hallucinations and inconsistency, whereas naive ensembles of models often fail to deliver stable and credible recommendations. Building on our previous work on LLM Chemistry, which quantifies the collaborative compatibility among LLMs, we apply this framework to improve the reliability in medication recommendation from brief clinical vignettes. Our approach leverages multi-LLM collaboration guided by Chemistry-inspired interaction modeling, enabling ensembles that are effective (exploiting complementary strengths), stable (producing consistent quality), and calibrated (minimizing interference and error amplification). We evaluate our Chemistry-based Multi-LLM collaboration strategy on real-world clinical scenarios to investigate whether such interaction-aware ensembles can generate credible, patient-specific medication recommendations. Preliminary results are encouraging, suggesting that LLM Chemistry-guided collaboration may offer a promising path toward reliable and trustworthy AI assistants in clinical practice.
Medication recommendation from unstructured clinical notes remains a challenging task due to the high variability and ambiguity of patient narratives (Eslami et al., 2025). While large language models (LLMs) have demonstrated remarkable success across many clinical and biomedical applications, their performance is uneven-no single model consistently excels across reasoning, generation, and domain-specific understanding (Chang et al., 2024). This inconsistency makes medica-* *Equal contribution tion recommendation error-prone, especially when relying on a single model's inductive biases.
Recent efforts to improve reliability through model ensembling and routing (Hu et al., 2024;Liu et al., 2024;Cloud et al., 2025) have focused primarily on selecting the best-performing individual models. However, these approaches often overlook the interaction dynamics between models -how their reasoning processes reinforce or interfere with each other. As a result, ensembles can exhibit unreliable synergy, where collaboration amplifies not only strengths but also errors and biases.
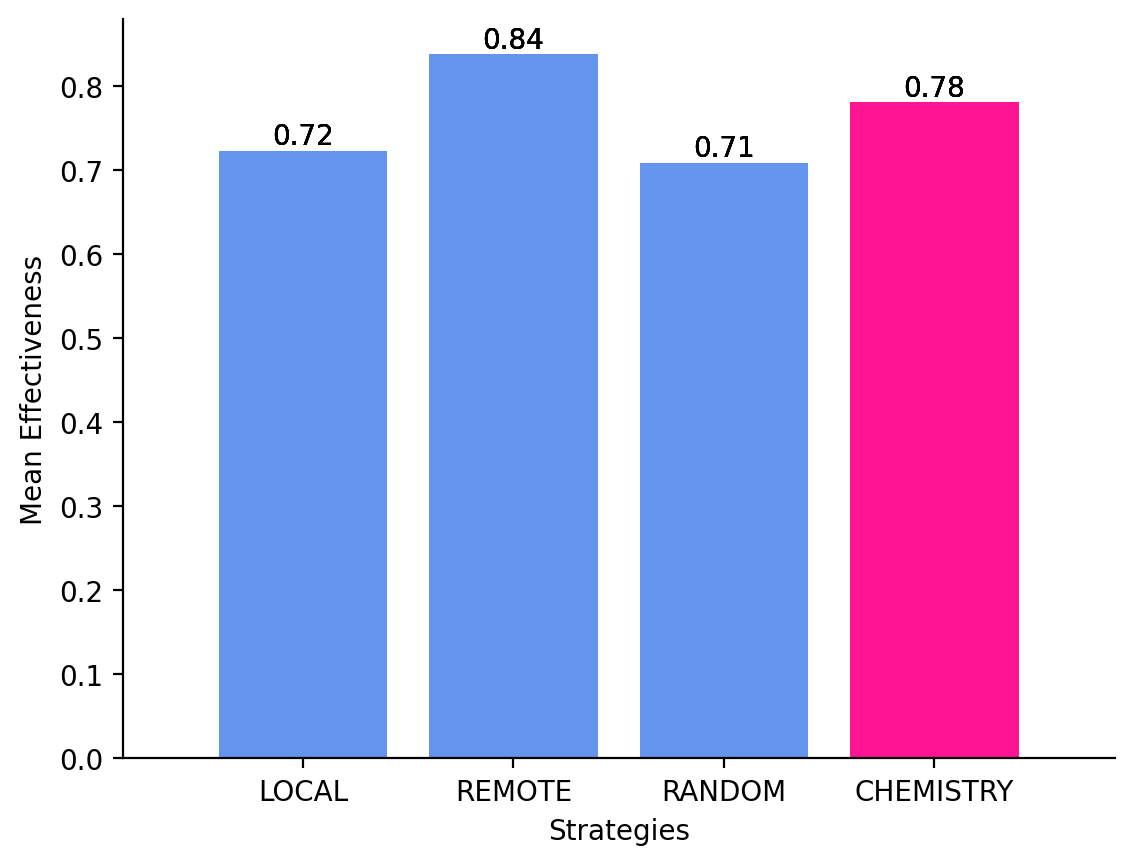
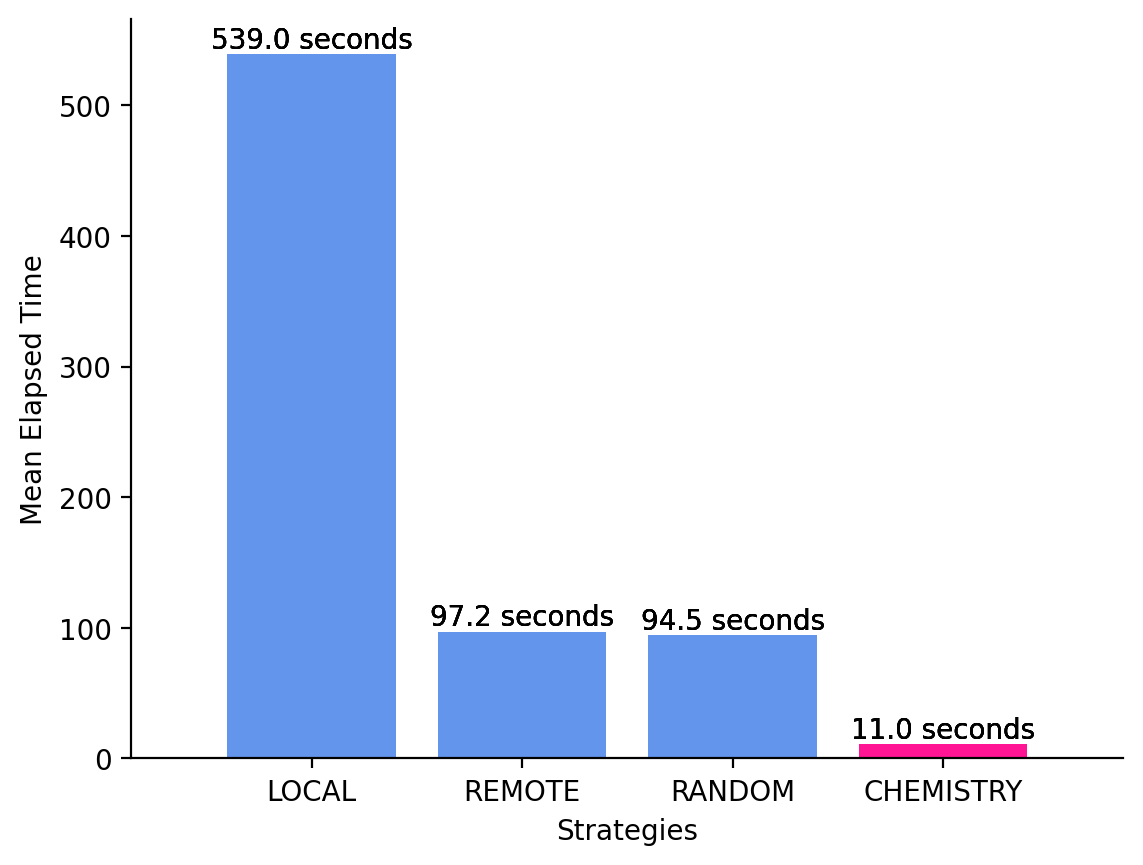
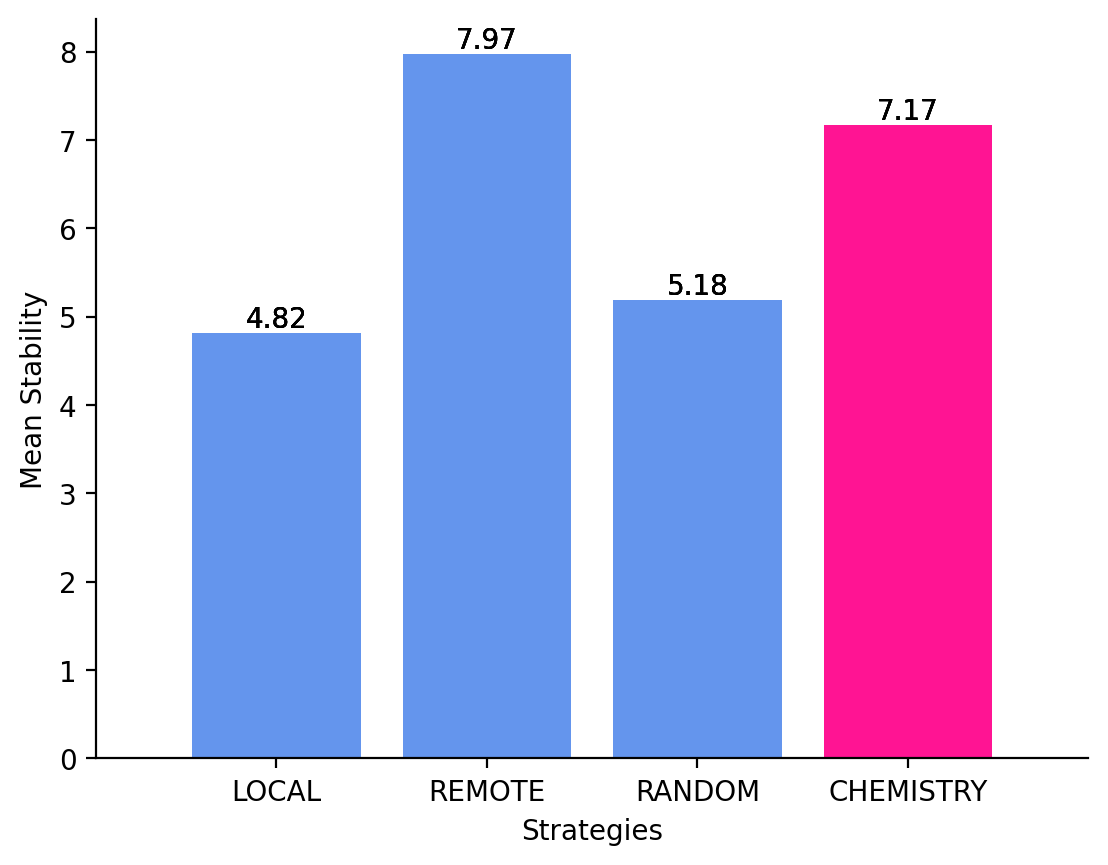
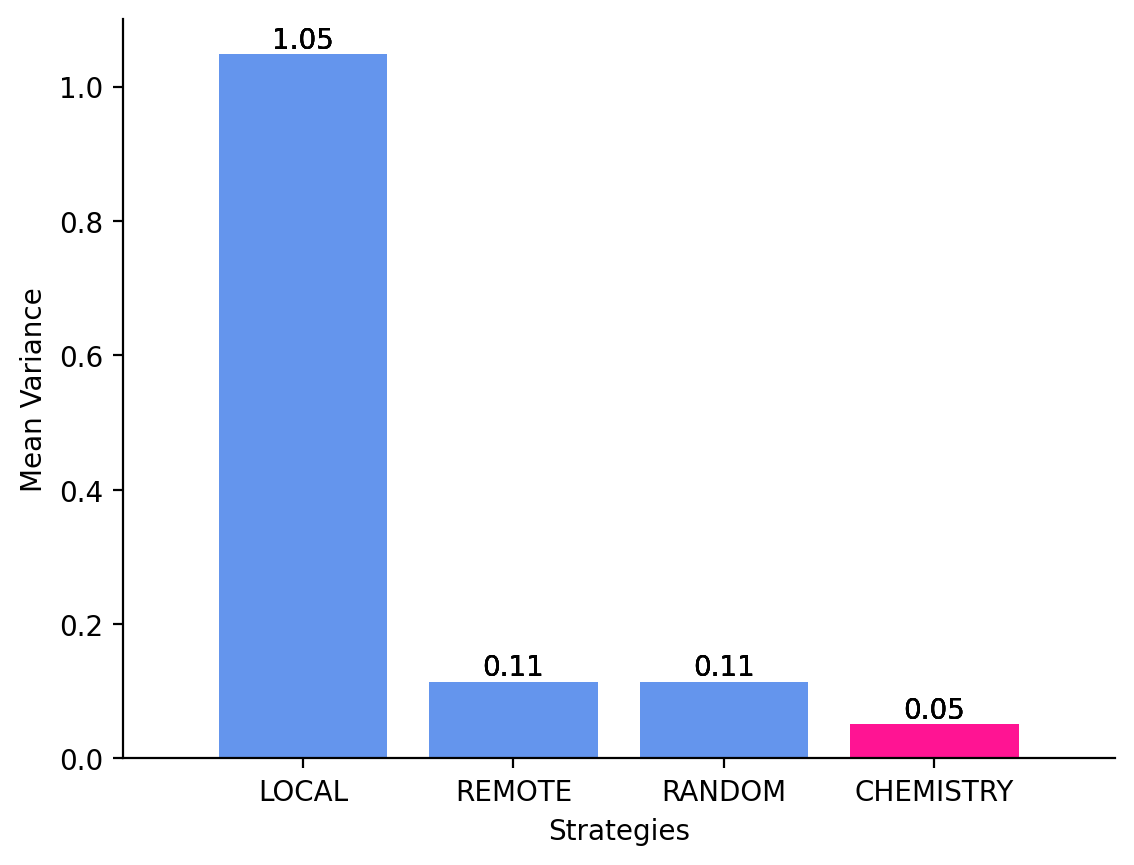
To address this limitation, we introduce a Multi-LLM Collaboration approach that leverages the notion of LLM Chemistry (Sanchez and Hitaj, 2025)a quantitative measure of collaborative compatibility among LLMs. Our approach explicitly models the synergistic and antagonistic relationships that emerge when multiple models reason together, enabling the formation of ensembles that are: (1) Effective: leveraging complementary strengths to improve recommendation accuracy; (2) Stable: maintaining consistent performance across diverse clinical inputs; and (3) Calibrated: minimizing interference and error amplification during collaboration, which translates to better task latency.
Building on this formulation, we evaluate how optimal multi-LLM collaboration can enhance reliability in clinical medication recommendation. Specifically, we investigate the following research question: Does our approach ensure efficient, effective, stable, and calibrated multi-LLM collaboration for the medication recommendation use-case? If so, which LLM sampling strategy yields the most accurate results?
While prior work has explored mixtures of LLMs -by sequentially feeding one model’s output into another to converge on a single aggregated result through majority voting (Wang et al., 2024), by employing cascades to reduce costs where stronger models are invoked only when weaker ones fail (Yue et al., 2024), by compensating for model deficiencies through meta-learning (Zhou et al., 2024), or by debating which model in a group is correct (Chen et al., 2025a)-we take a different approach. We introduce an inclusive and less restrictive collaboration framework in which any LLM, open-weight or proprietary, can participate. By leveraging diverse perspectives and complementary knowledge across models, our approach enhances answer consistency and mitigates individual model blind spots. This framework follows the intuition that LLMs should defend and refine their reasoning in group settings, where peer scrutiny fosters consensus on the quality and reliability of generated answers. Contributions. In this paper, we build upon and extend our previous work (Sanchez and Hitaj, 2025) to explore applications of multi-LLM collaboration in healthcare, leading to the following contributions:
• Optimal Multi-LLM Collaboration. We leverage the concept of LLM Chemistry to enable structured, interaction-aware, and optimal collaboration among multiple LLMs. • Two-stage Collaboration Mechanism. We build on an existing multi-LLM collaboration setup and extend its evaluation step with a consensus step, transforming diverse, sometimes conflicting, model outputs into a unified, and reliable decision. • Application to Medication Recommendation. We evaluate the proposed approach on the clinical task of medication recommendation from patient notes, demonstrating improved accuracy and stability over the other ensemble baselines.
Multi-LLM collaboration has emerged as a promising strategy for improving robustness, reasoning diversity, and interpretability in LLM-based systems. Instead of relying on a single model, collaborative frameworks such as LLM ensembles (Du et al., 2023;Yang et al., 2023;Chen et al., 2025b), Mixture-of-Agents (MoA) (Wang et al., 2024;Jang et al., 2025), Mixture-of-Domain Experts (MoDEM), and Mixture-of-Multimodal-Agents (MoMA) (Gao et al., 2025) combine multiple LLMs that exchange, critique, and refine outputs through structured interactions. Each model contributes distinct strengths-ranging from domain knowledge and factual precision to reasoning style and linguistic nuance-allowing the ensemble to achieve broader domain coverage and reliability than any individual component. Prior work has shown that multi-agent coordination enhances factuality and cross-domain reasoning through layered aggregation and verification mechanisms. However, these collaborative strategies still exhibit
This content is AI-processed based on open access ArXiv data.