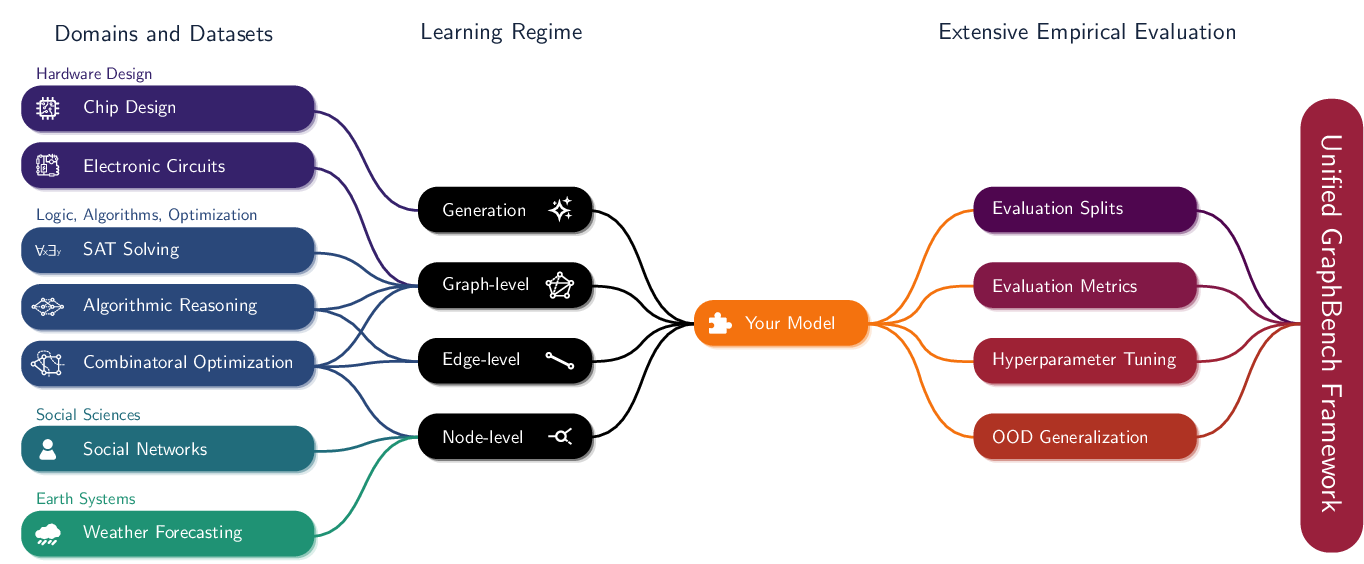
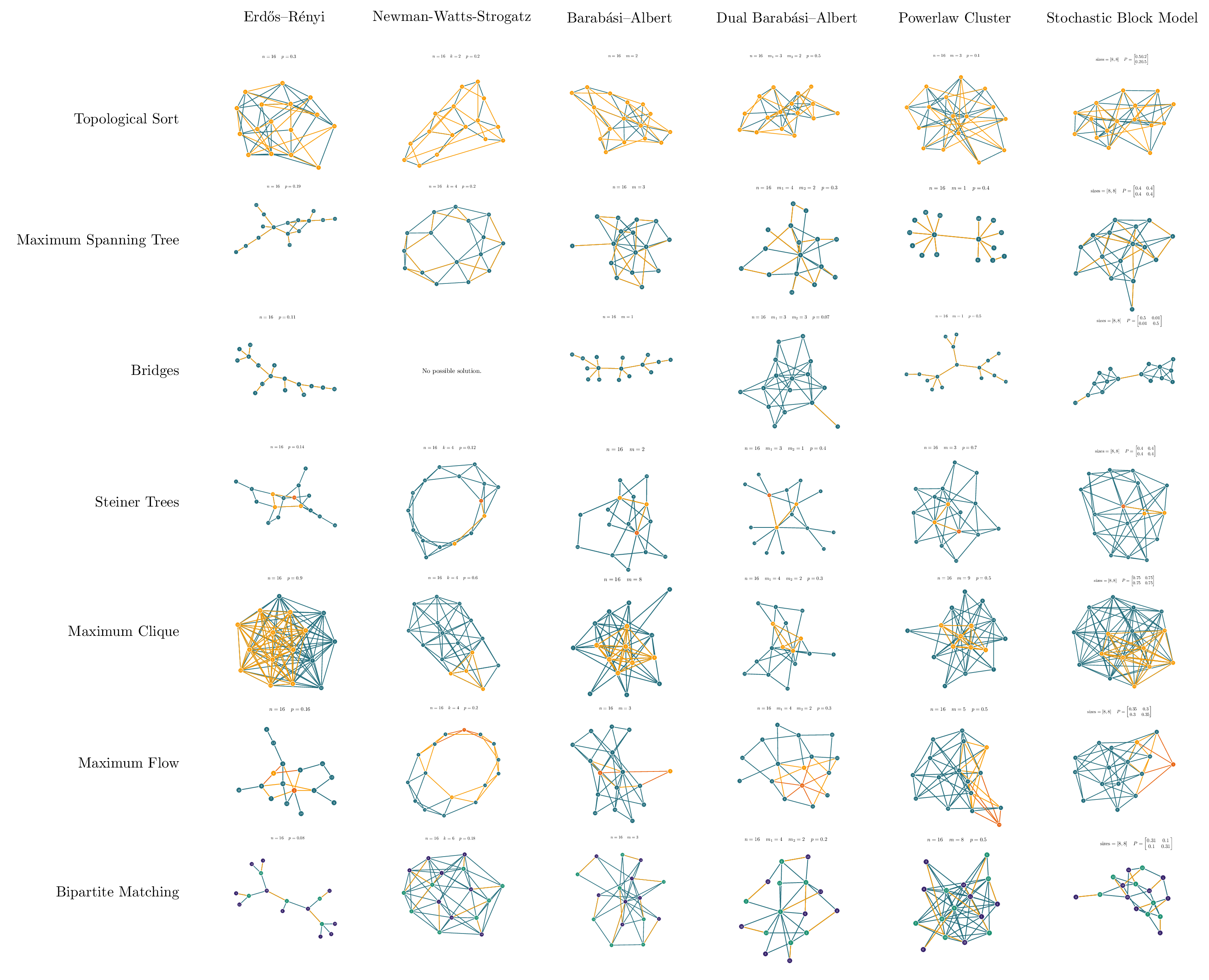Machine learning on graphs has recently achieved impressive progress in various domains, including molecular property prediction and chip design. However, benchmarking practices remain fragmented, often relying on narrow, task-specific datasets and inconsistent evaluation protocols, which hampers reproducibility and broader progress. To address this, we introduce GraphBench, a comprehensive benchmarking suite that spans diverse domains and prediction tasks, including node-level, edge-level, graph-level, and generative settings. GraphBench provides standardized evaluation protocols -- with consistent dataset splits and performance metrics that account for out-of-distribution generalization -- as well as a unified hyperparameter tuning framework. Additionally, we benchmark GraphBench using message-passing neural networks and graph transformer models, providing principled baselines and establishing a reference performance. See www.graphbench.io for further details.
Machine learning on graphs using graph neural networks (GNNs), specifically message-passing neural networks (MPNNs) (Gilmer et al., 2017;Scarselli et al., 2009) and graph transformers (GTs) (Müller et al., 2024a), has become a cornerstone of modern machine learning research, spanning applications in drug design (Wong et al., 2023), recommender systems (Ying et al., 2018), chip design (Zheng et al., 2025), and combinatorial optimization (Cappart et al., 2021). Despite these advances, benchmarking in the field remains highly fragmented. Narrow, task-specific datasets and inconsistent evaluation protocols limit reproducibility and hinder meaningful comparison across tasks and domains (Bechler-Speicher et al., 2025). As Bechler-Speicher et al. (2025) argue, current benchmarks tend to emphasize specific domains-such as 2D molecular graphs-while overlooking more impactful, real-world applications like relational databases, chip design, and combinatorial optimization. Many benchmark datasets fail to accurately reflect the complexity of real-world structures, resulting in inadequate abstractions and misaligned use cases. In addition, the field's heavy reliance on accuracy as a primary metric encourages overfitting, rather than fostering generalizable, robust models. As a result, these limitations have significantly hindered progress in graph learning. datasets-ranging from social sciences and hardware design to logic, optimization, and earth systems-into different learning regimes (node-, edge-, graph-level prediction and generative tasks). GraphBench offers extensive empirical evaluation via standardized splits, metrics, hyperparameter tuning scripts, and out-of-distribution (OOD) generalization tests, all within a unified evaluation pipeline.
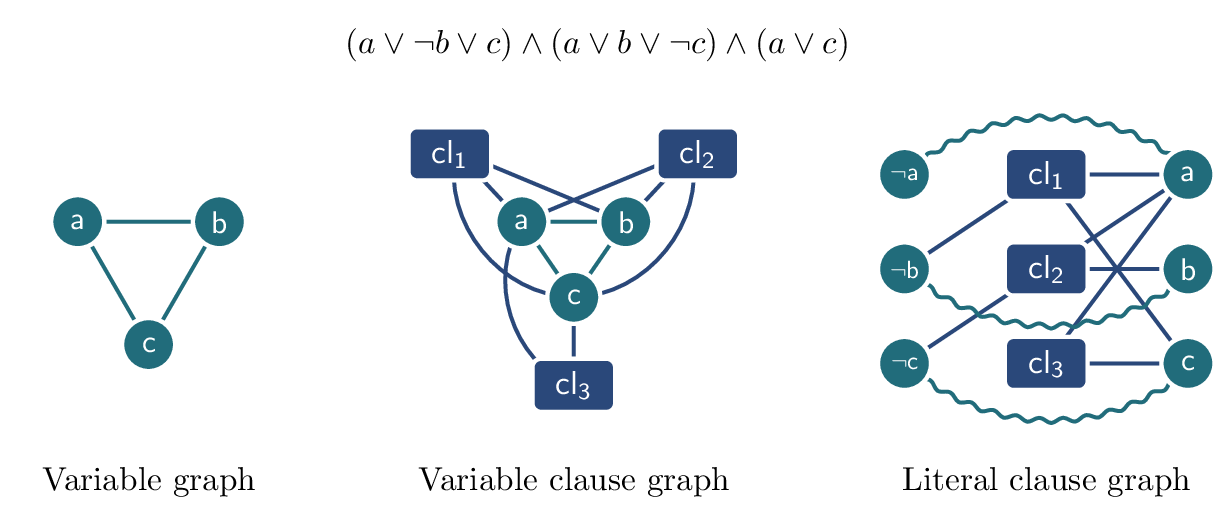
The goal of GraphBench is to support the next generation of graph learning research by addressing key shortcomings of existing benchmarks. Here, we provide an overview of the design and features of GraphBench. GraphBench provides a unified framework for evaluating models across diverse graph tasks, domains, and data scales. Unlike previous benchmarks that focus narrowly on specific applications (e.g., molecular graphs or citation networks), with little (industrial or real-world) impact, GraphBench includes datasets from social networks, chip design, combinatorial optimization, SAT solving, and more. GraphBench is designed around the following core principles.
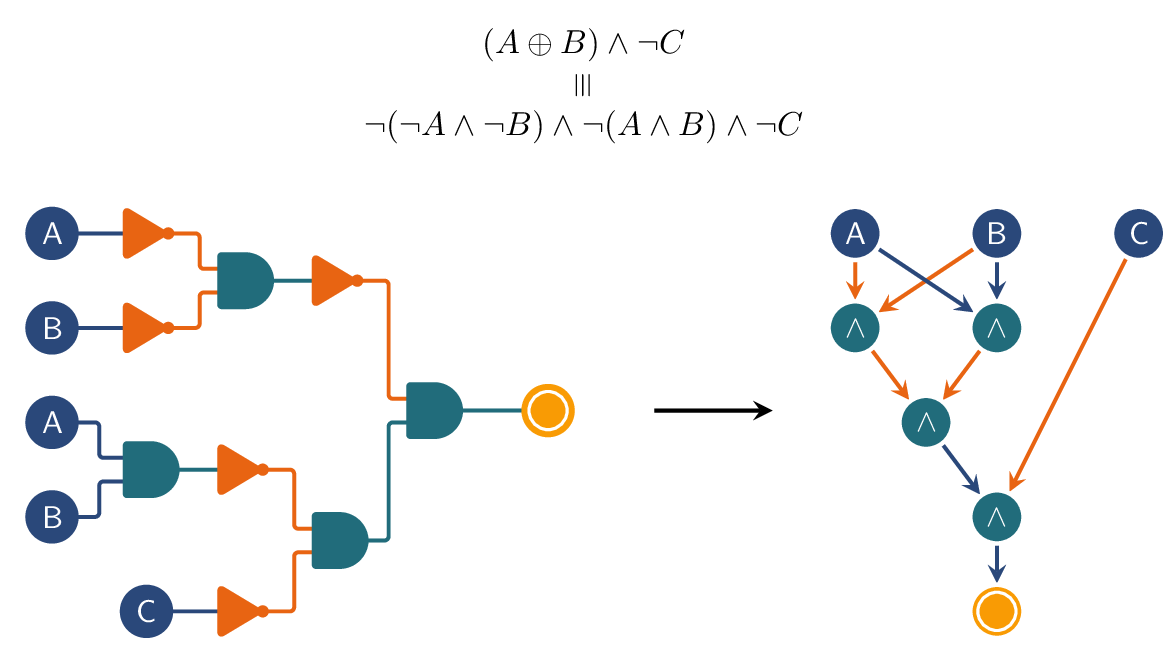
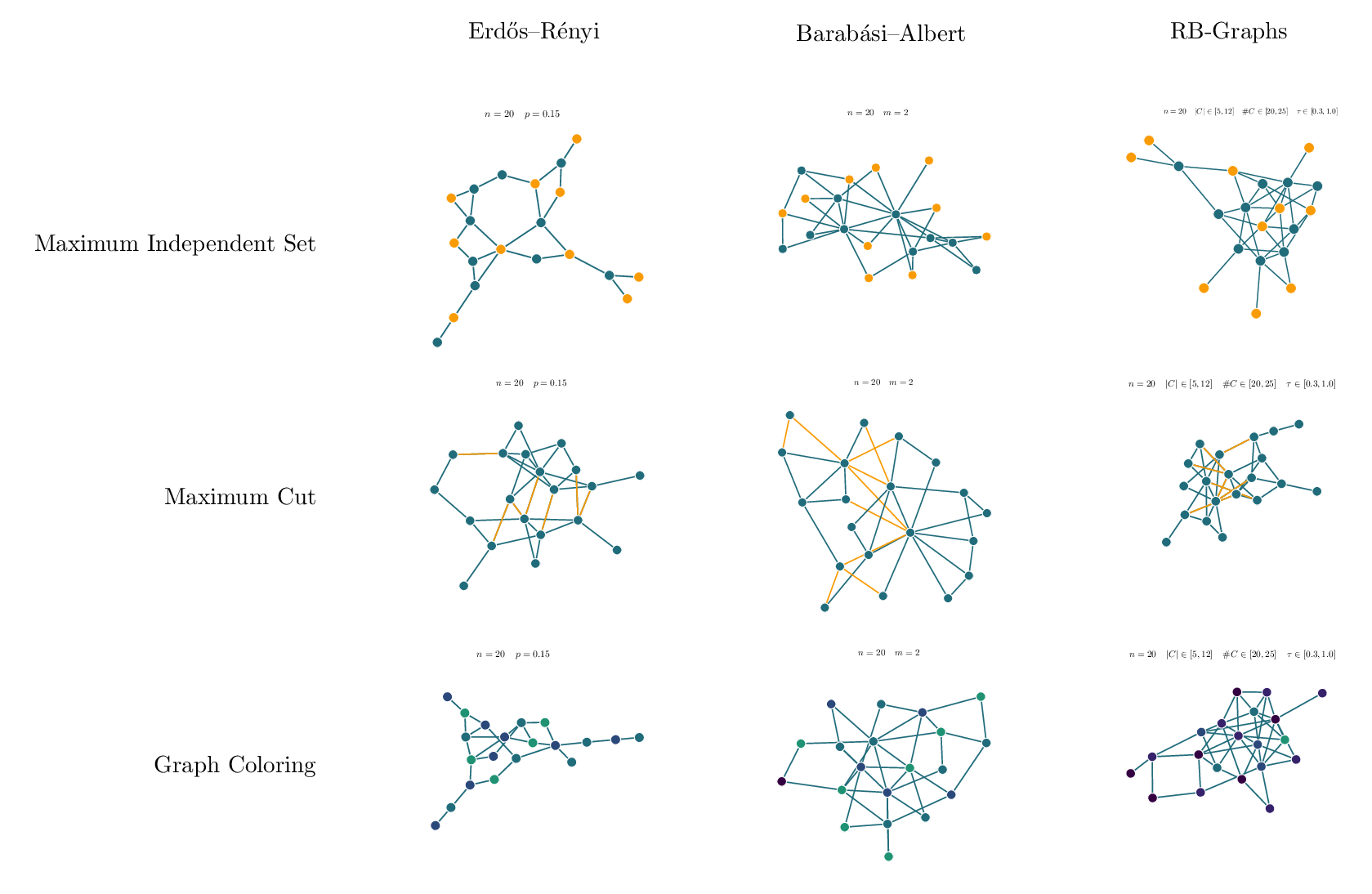
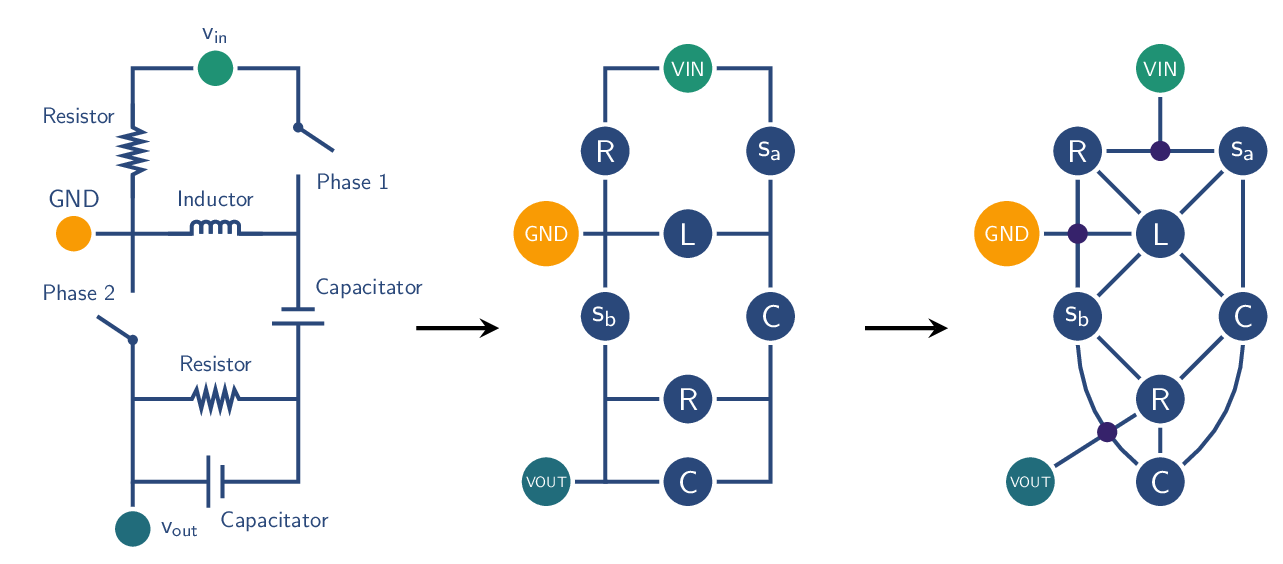
Diverse tasks and domains GraphBench supports node-, edge-, and graph-level prediction, as well as generative tasks. Datasets span diverse domains, including social networks, chip and analog circuit design, algorithm performance prediction, and weather forecasting. This diversity enables the evaluation of models in both traditional and emerging graph learning applications.
Real-world impact Many existing benchmark suites focus on small-scale graphs or domains that have limited applicability to current real-world challenges. In contrast, GraphBench emphasizes datasets and tasks that are more representative of modern real-world use cases, such as large-scale chip design, weather forecasting, and combinatorial optimization. By moving beyond the citation network-and molecular-dominated domains of prior benchmarks, GraphBench offers scenarios that better align with the needs of industry and emerging research areas.
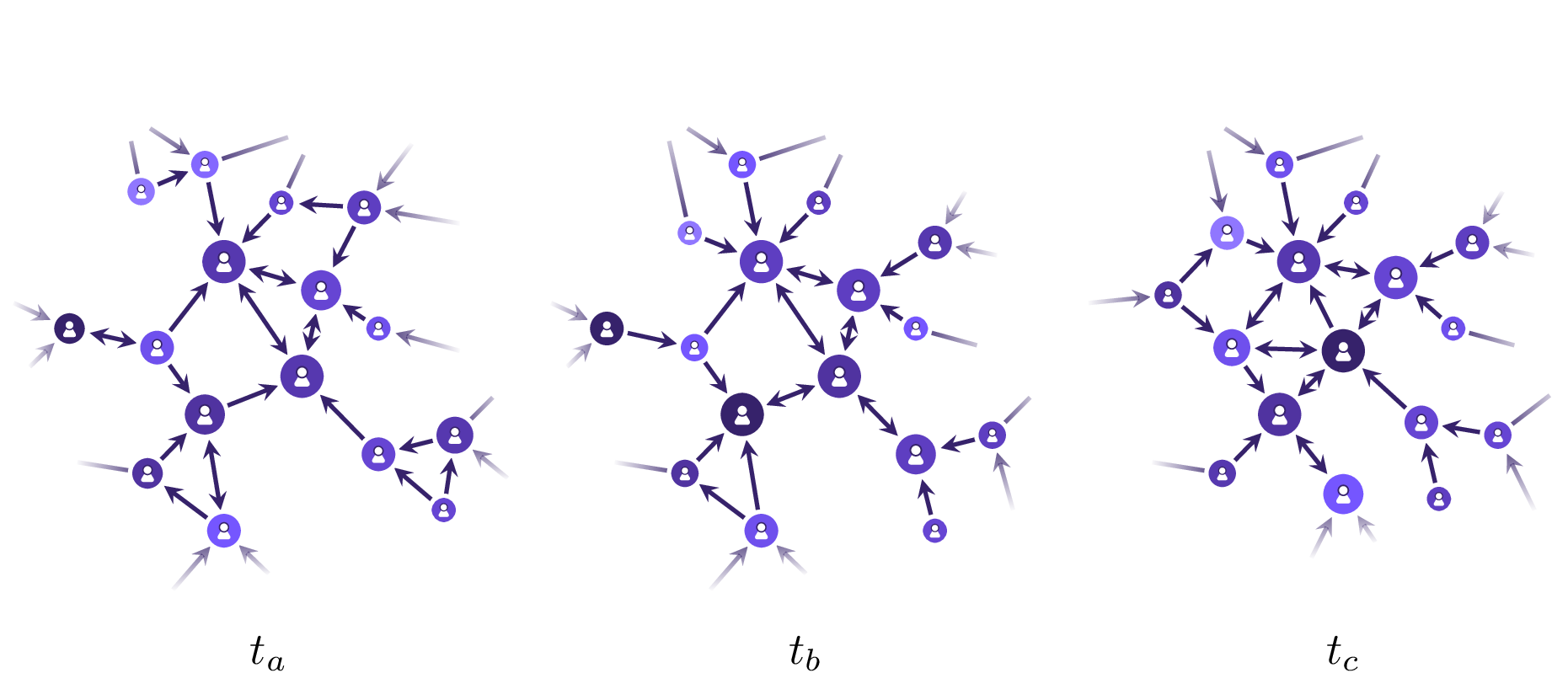
OOD generalization Several datasets in GraphBench are explicitly split by time or problem size to test a model’s ability to generalize beyond the training distribution. For instance, social network benchmarks assess future interaction prediction using only past data, while circuit 4. Meaningful evaluation GraphBench provides evaluation splits, meaningful domain-specific evaluation metrics, and state-of-the-art hyperparameter tuning scripts. In addition, we offer out-of-distribution generalization evaluation for selected datasets, focusing on size generalization abilities, paving the way for graph foundation models.
Task-relevant evaluation metric GraphBench provides metrics tailored to each task that capture models’ real-world performance. These measures extend beyond classical metrics such as mean-squared error and accuracy, which may not accurately reflect practical utility in real-world scenarios.
To facilitate fair and reproducible comparisons, GraphBench offers a comprehensive benchmarking protocol for each dataset, including (i) a clearly defined prediction or generation task (e.g., node-, link-, or graph-level classification/regression, or graph generation), (ii) a realistic and domain-appropriate data split strategy (e.g., temporal splits for social networks, cross-size splits for electronic circuits), (iii) standardized input features and labels to ensure consistency across models, and (iv) evaluation scripts implementing task-specific metrics (e.g., RMSE, ROC-AUC, closed gap) along with state-of-the-art hyperparameter tuning scripts. This standardized setup enables researchers to compar
This content is AI-processed based on open access ArXiv data.