Reasoning from diverse observations is a fundamental capability for generalist robot policies to operate in a wide range of environments. Despite recent advancements, many large-scale robotic policies still remain sensitive to key sources of observational variation such as changes in camera perspective, lighting, and the presence of distractor objects. We posit that the limited generalizability of these models arises from the substantial diversity required to robustly cover these quasistatic axes, coupled with the current scarcity of large-scale robotic datasets that exhibit rich variation across them. In this work, we propose to systematically examine what robots need to generalize across these challenging axes by introducing two key auxiliary tasks, state similarity and invariance to observational perturbations, applied to both demonstration data and static visual data. We then show that via these auxiliary tasks, leveraging both more-expensive robotic demonstration data and less-expensive, visually rich synthetic images generated from non-physics-based simulation (for example, Unreal Engine) can lead to substantial increases in generalization to unseen camera viewpoints, lighting configurations, and distractor conditions. Our results demonstrate that co-training on this diverse data improves performance by 18 percent over existing generative augmentation methods. For more information and videos, please visit https://invariance-cotraining.github.io
Robotic foundation models have shown impressive progress in generalizing to everyday scenarios by leveraging large-scale datasets spanning multiple embodiments, environments, and tasks [1], [2]. However, despite their breadth, the resulting models often remain brittle in realworld settings-failing to handle unseen spatial configurations of objects or adapt to drastic visual changes such as lighting and viewpoint shifts. We hypothesize that the brittleness of current robotic policies stems from insufficient coverage of key observational factors during training. For example, many large-scale datasets provide only one or two third-person perspectives per scene, limiting robustness to viewpoint shifts. Similarly, combinatorially covering all possible spatial configurations of objects is difficult in purely real-world datasets.
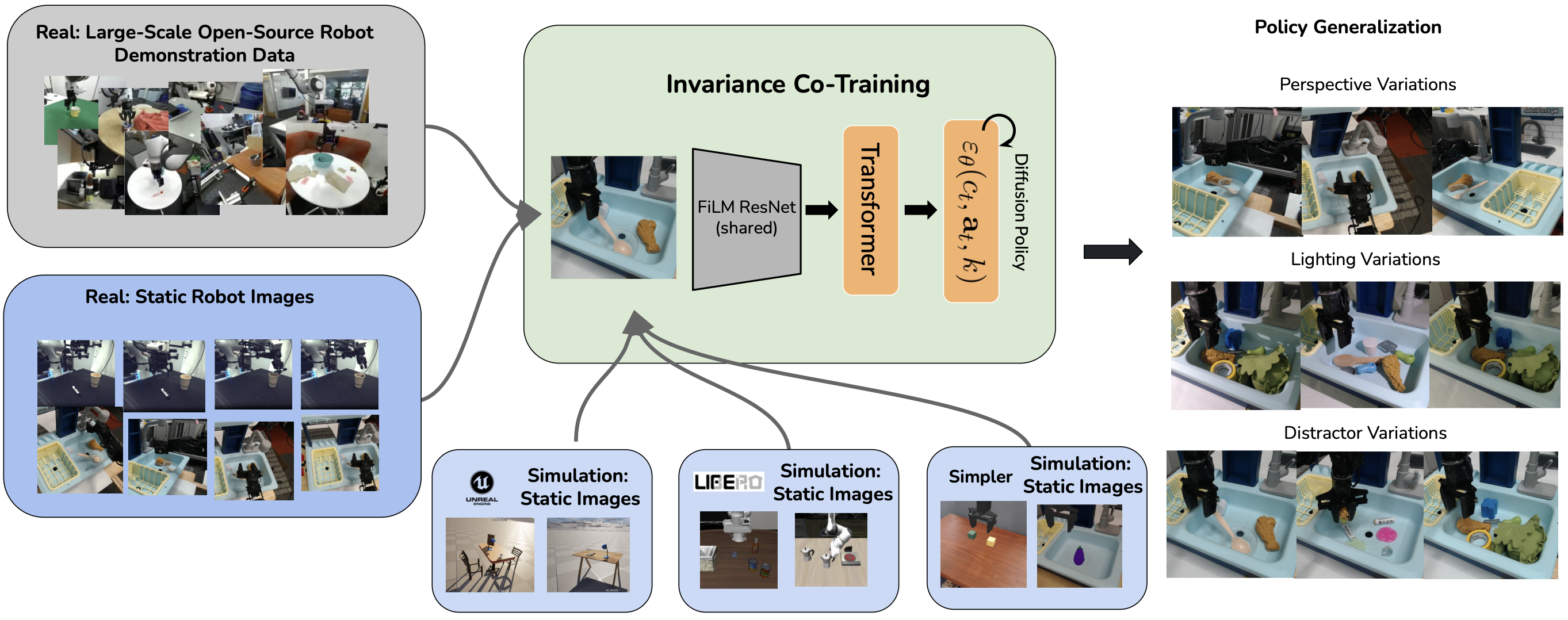
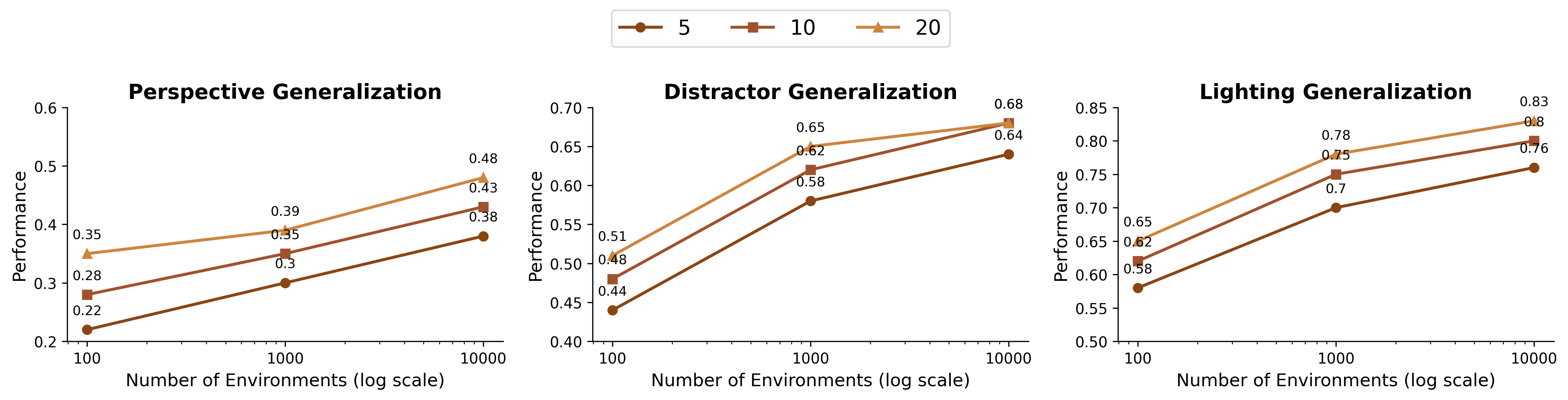
Prior work has attempted to solve this coverage issue by leveraging simulation as a low-cost alternative to expensive real-world data collection. Such efforts include automating the generation of assets, scenes, and tasks within simulation [3] and developing methods for bringing real-world data into simulation [4]. Despite these advances, creating diverse, high-fidelity simulated environments is expensive, particularly when each environment must have both accurate physics and visuals. Our key insight is that many difficult axes of real-world generalization in robotics can be effectively addressed using only static image data, by learning representations invariant to perturbations in robotic observation given a (state, goal) pair. Robots can learn the desired state-goal representations efficiently using diverse observations generated from quasistatic scenes, rather than physical simulations. By focusing on quasi-static scenes, simulation data can be scaled more easily to cover critical visual variations without the complexity and computational burden of modeling realistic dynamics. In this work, we investigate how co-training robot policies with large-scale, visually diverse synthetic data can improve generalization along three important axes: camera perspective, distractor clutter, and lighting variation.
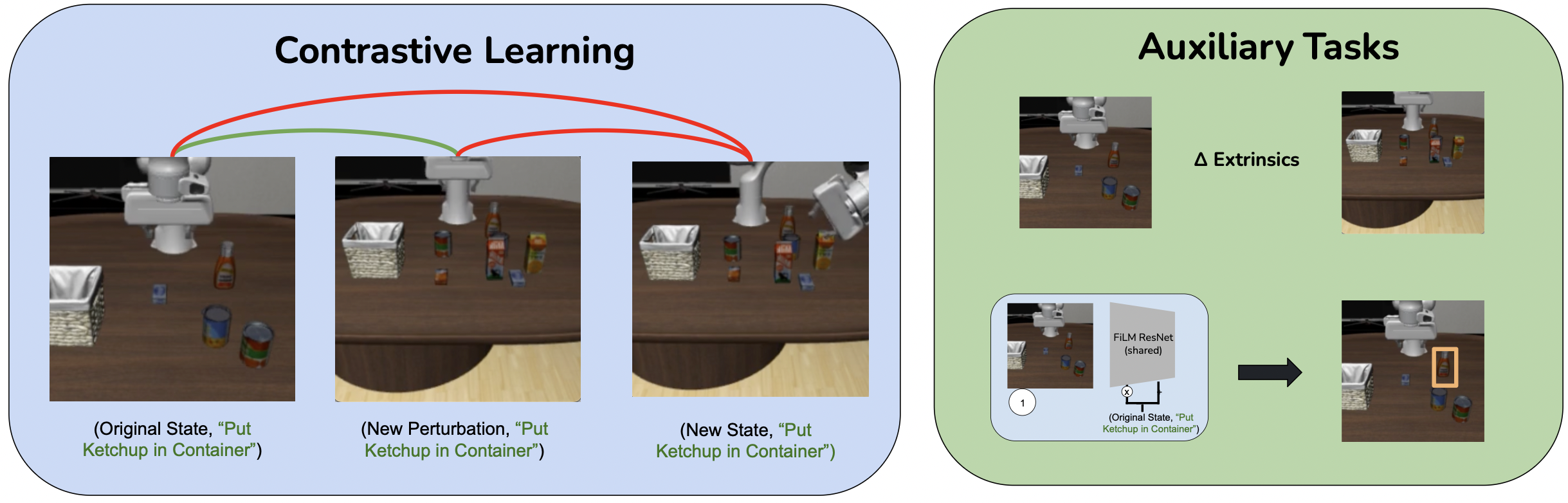
How can we learn the desired state-goal invariances from static or quasi-static data? We identify two crucial capabilities for the learned representation: state similarity recognition, which involves mapping varied observation configurations (differing in viewpoint, lighting, etc.) to the same underlying state, and relative observation disentanglement, which involves understanding whether a change in observation was induced by a change in state or a (state, goal)-invariant observation perturbation. To learn representations exhibiting these properties, we employ a contrastive learning framework that encourages invariant embeddings, and utilizes our diverse quasi-static dataset to provide the necessary examples of observational variations. To further ground the learned representation and ensure it focuses on relevant physical entities, we supplement this framework with auxiliary supervised learning losses, such as predicting bounding boxes for key objects that define the task state.
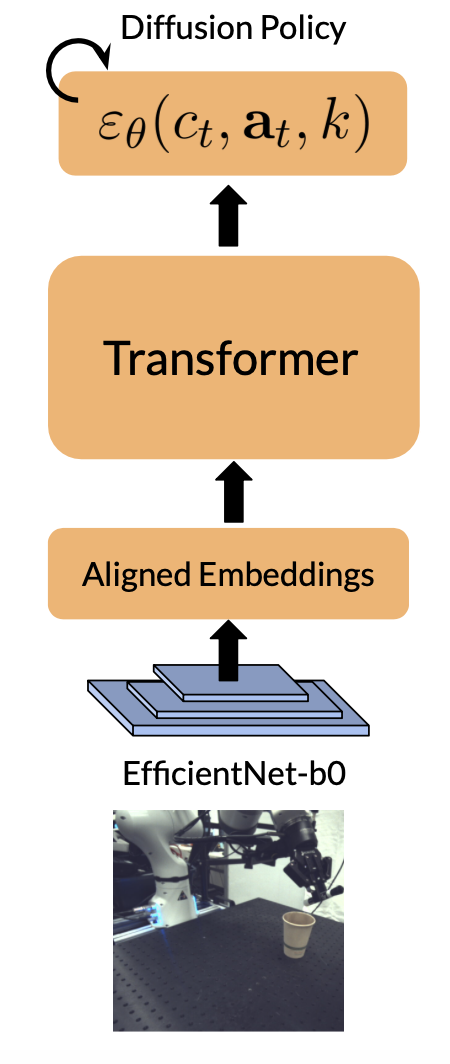
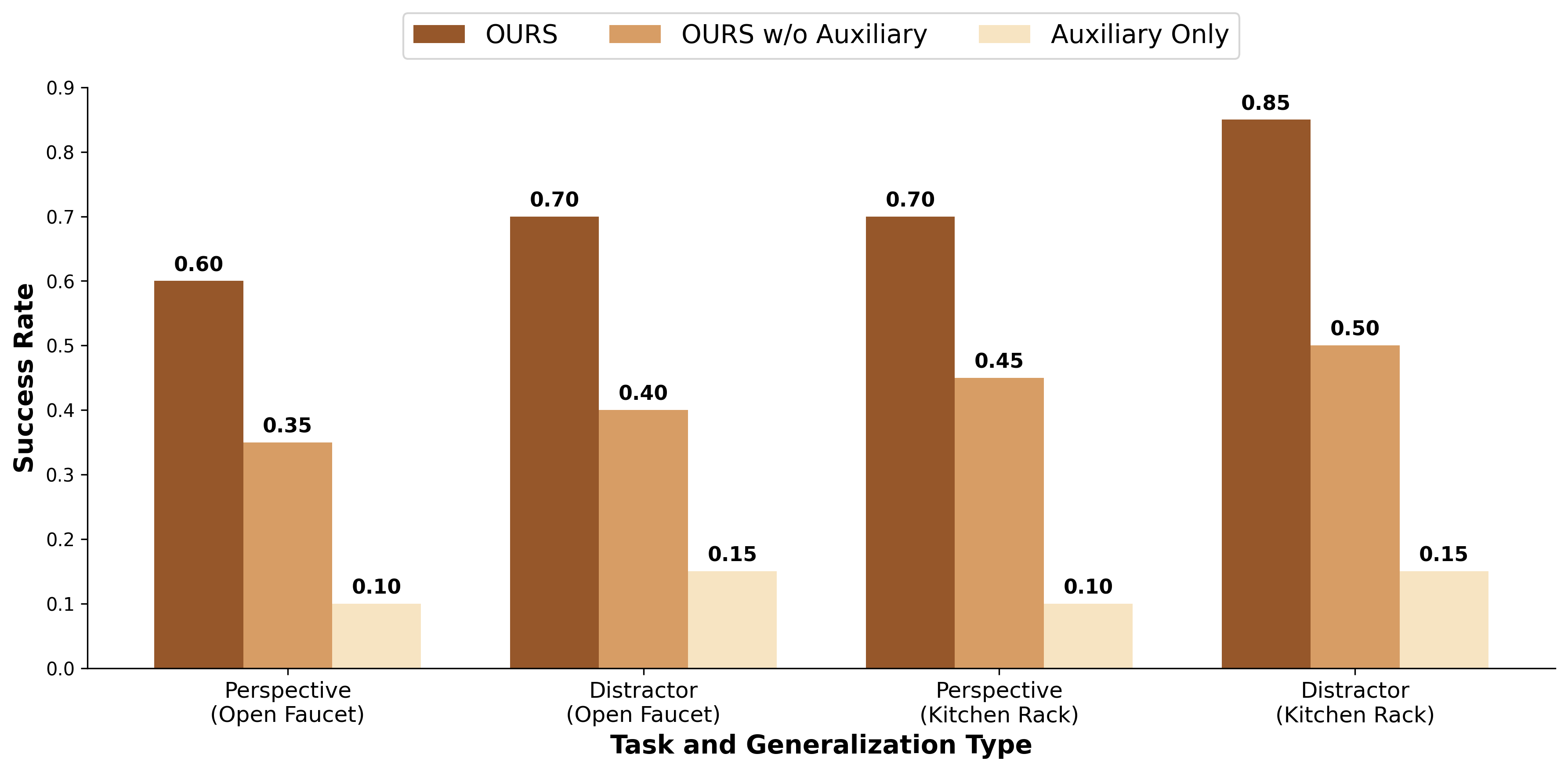
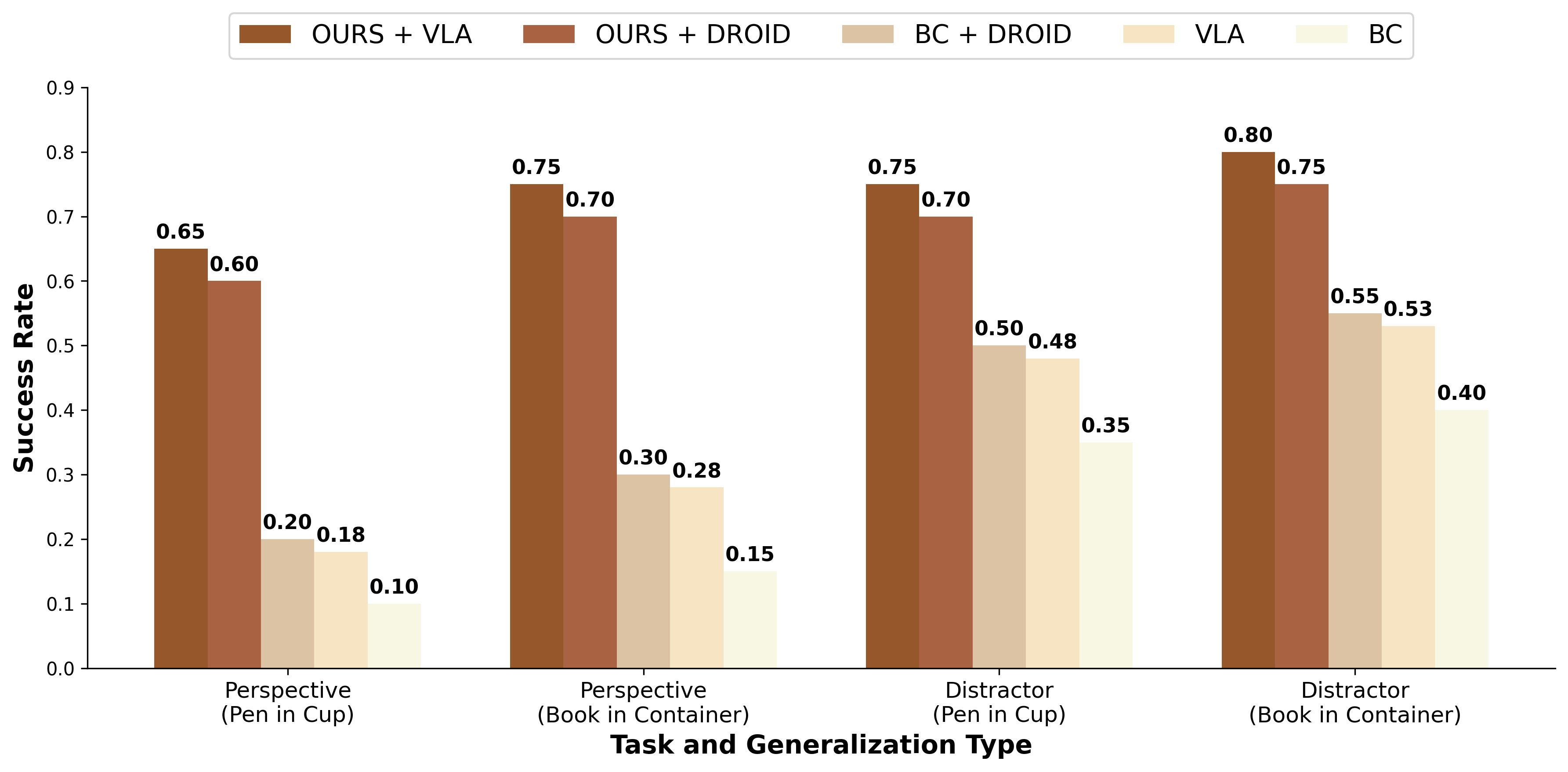
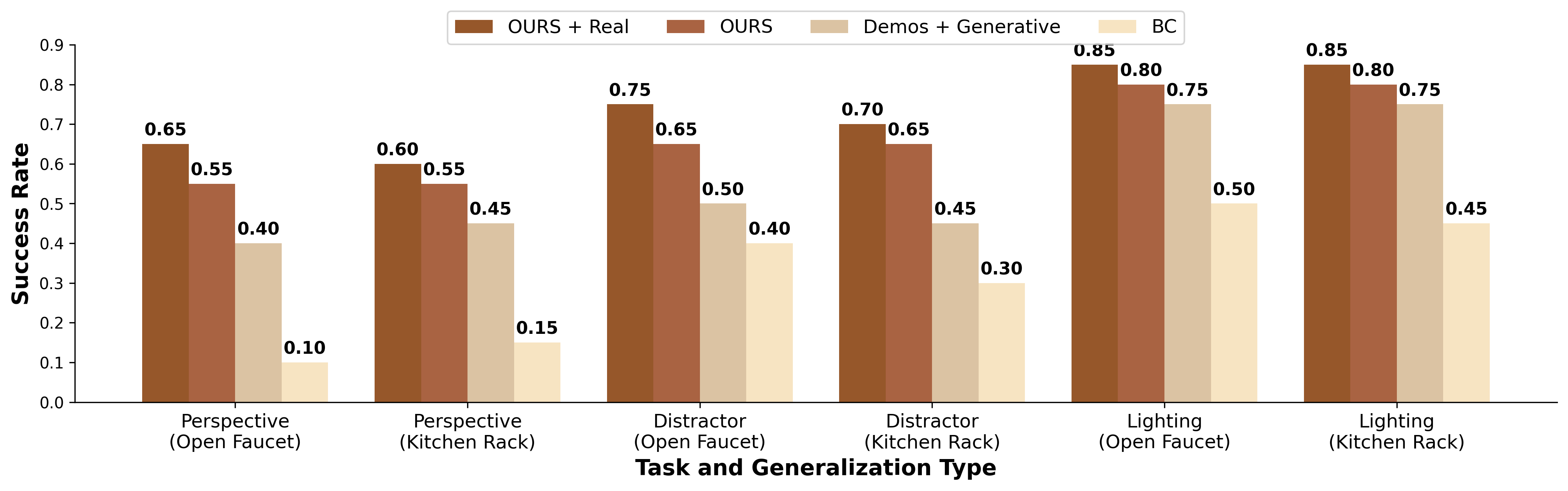
Our main contribution is a scalable method for aligning robot policy encoder representations to improve generalization across multiple observational axes-specifically camera viewpoint, lighting variation, and distractor clutter-without relying on accurate physical simulation, which we coin as invariance co-training. Unlike prior work that focuses on precise dynamics modeling or task-specific data augmentation, we demonstrate that learning structured invariances from synthetic, visually diverse images alone is sufficient to significantly improve generalization. Our method trains vision encoders on diverse synthetic data, combined with real videos of static scenes and real robot demonstration data, to enable real robot policies to generalize more broadly. Experimentally, our invariance co-training approach significantly outperforms baseline Behavioral Cloning (BC), improving average success rates by approximately 40% across key variations. Furthermore, it yields 18% higher success rates compared to variants relying only on simulation or generative Fig. 1: Invariance Co-training. Our method leverages diverse synthetic images, large-scale open-source datasets, and videos of static scenes to train a 2D vision encoder that generalizes to new camera viewpoints, lighting conditions, and background clutter. This encoder is co-trained with robot demonstration data to enable the policy to generalize effectively to novel visual conditions. models.
Sim-to-real Transfer. Sim-to-real transfer harnesses simulation as a cost-effective means to supply training data for robotic policies. However, mismatches in visual appearance and physics accuracy can create a sim-to-real gap that can lead to difficulty in utilizing this data. To solve this issue, prior works have either utilized domain randomization [5], [6], [7], [8] or im
This content is AI-processed based on open access ArXiv data.