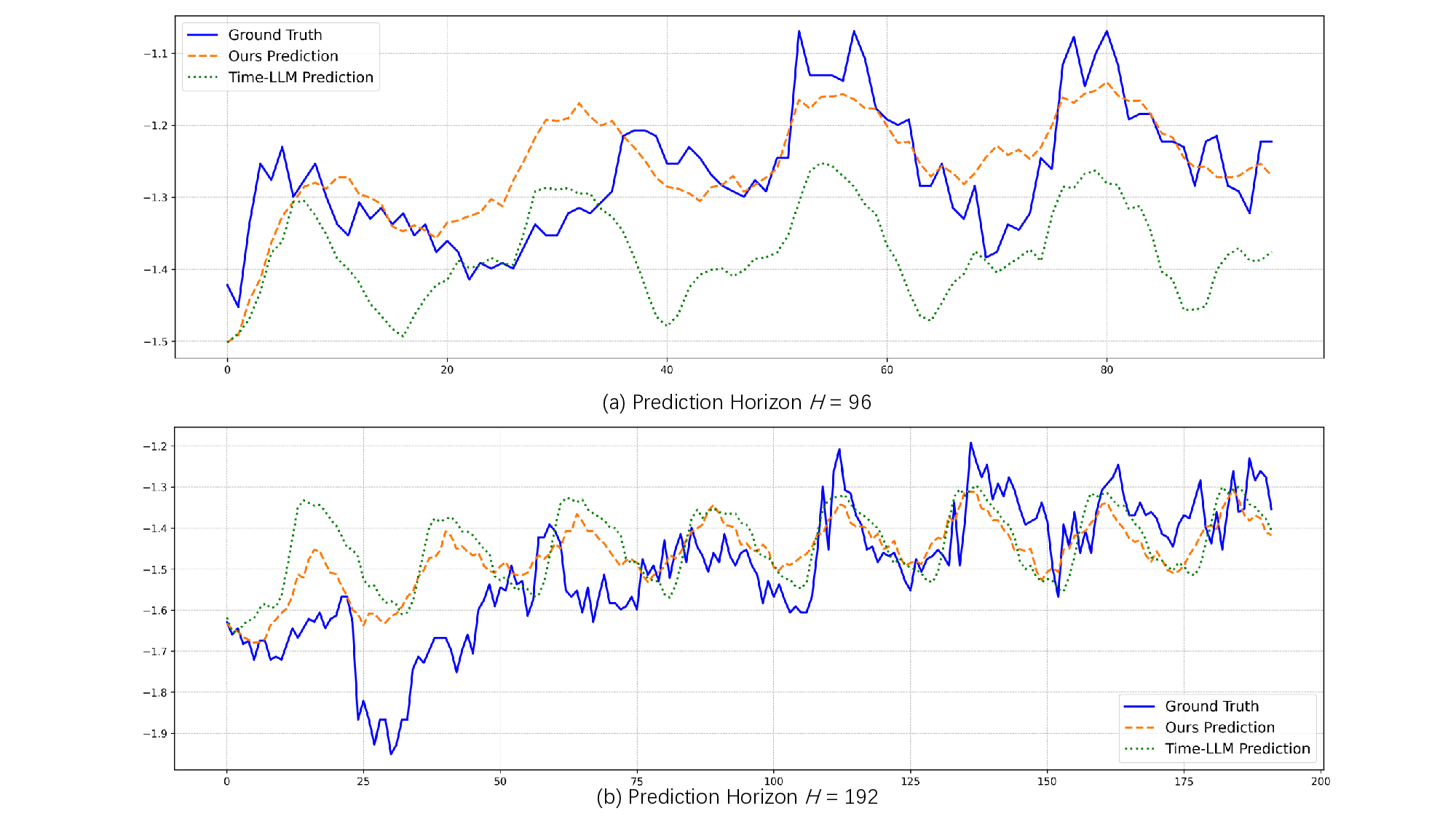
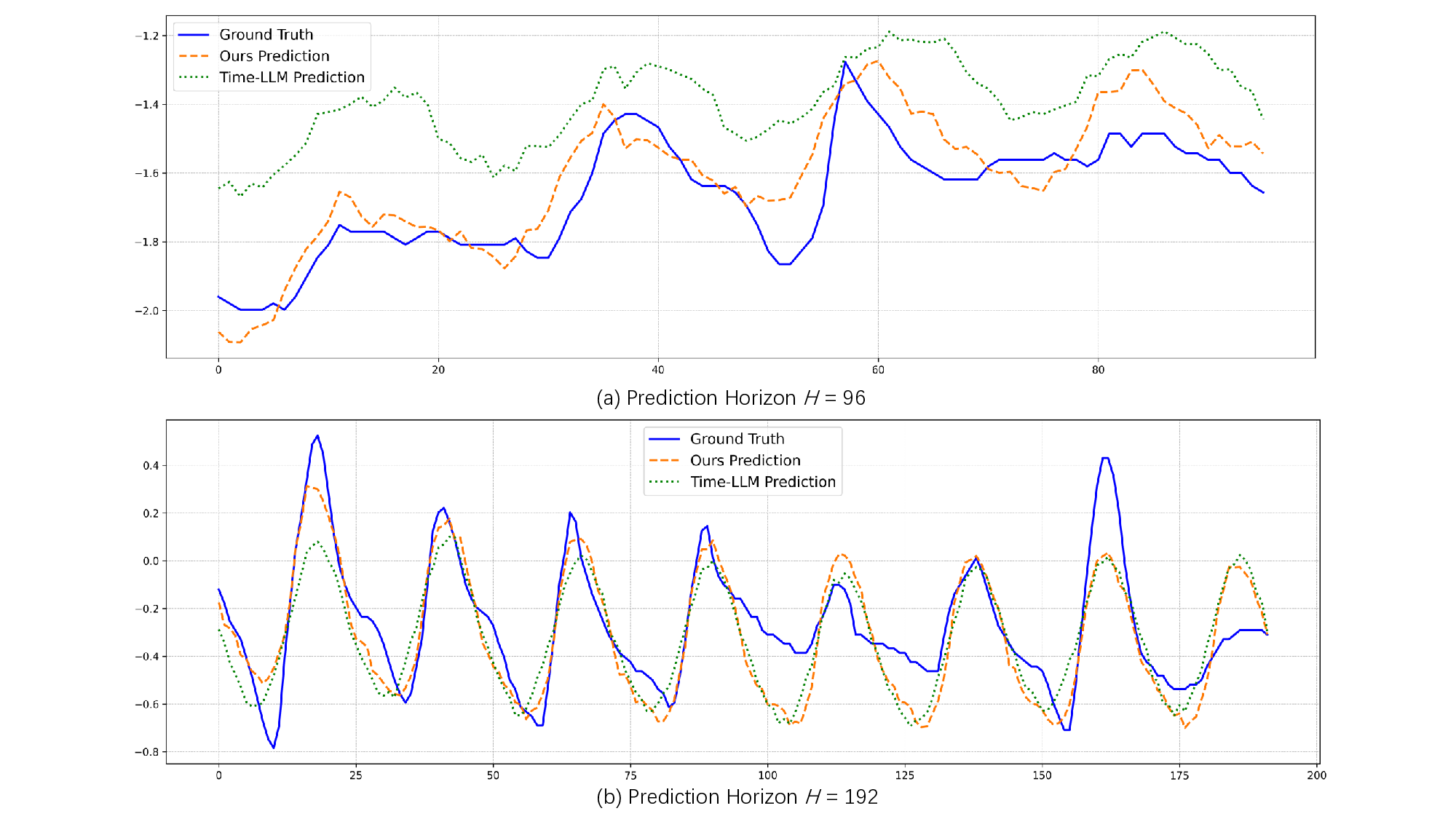
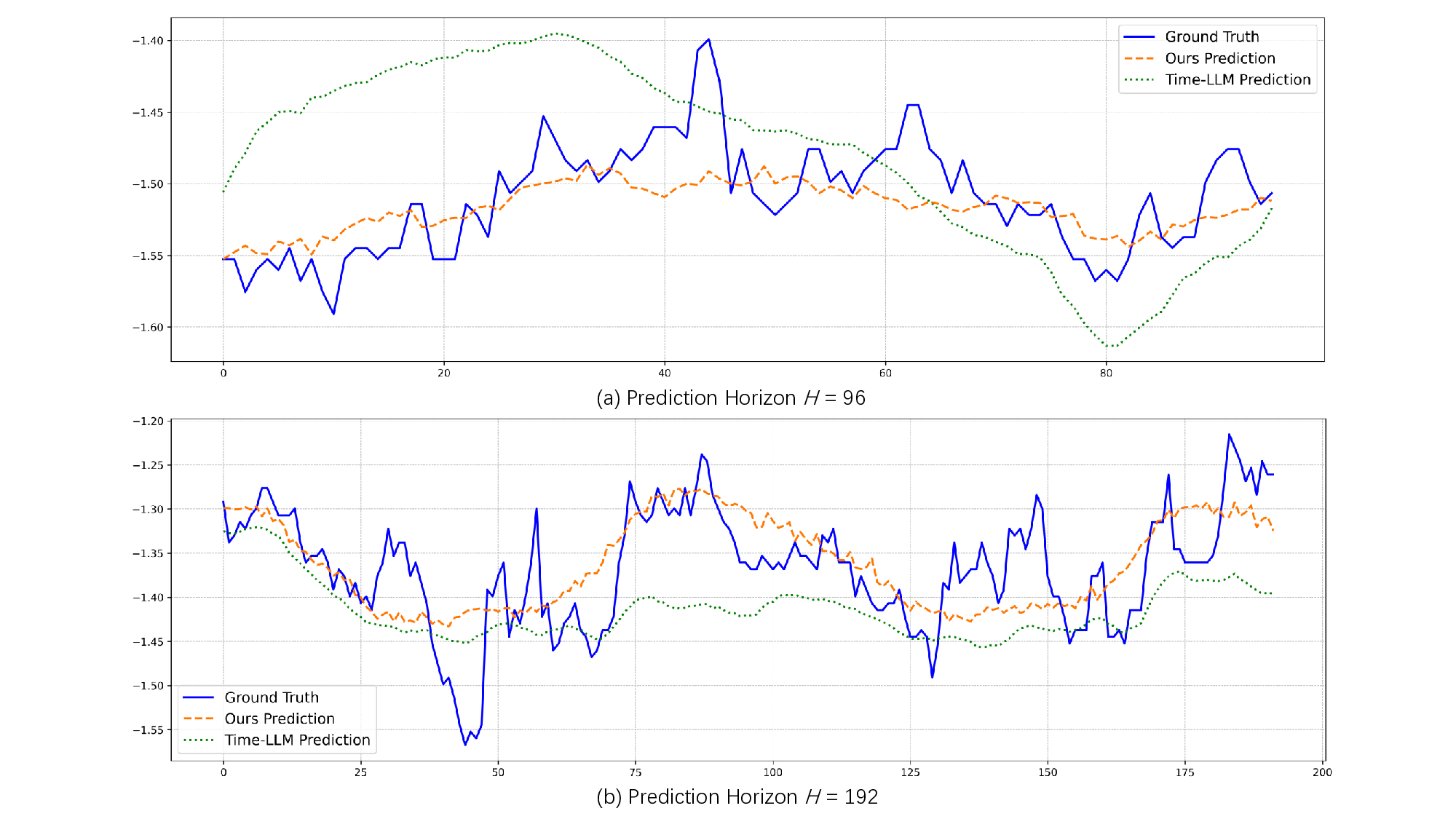
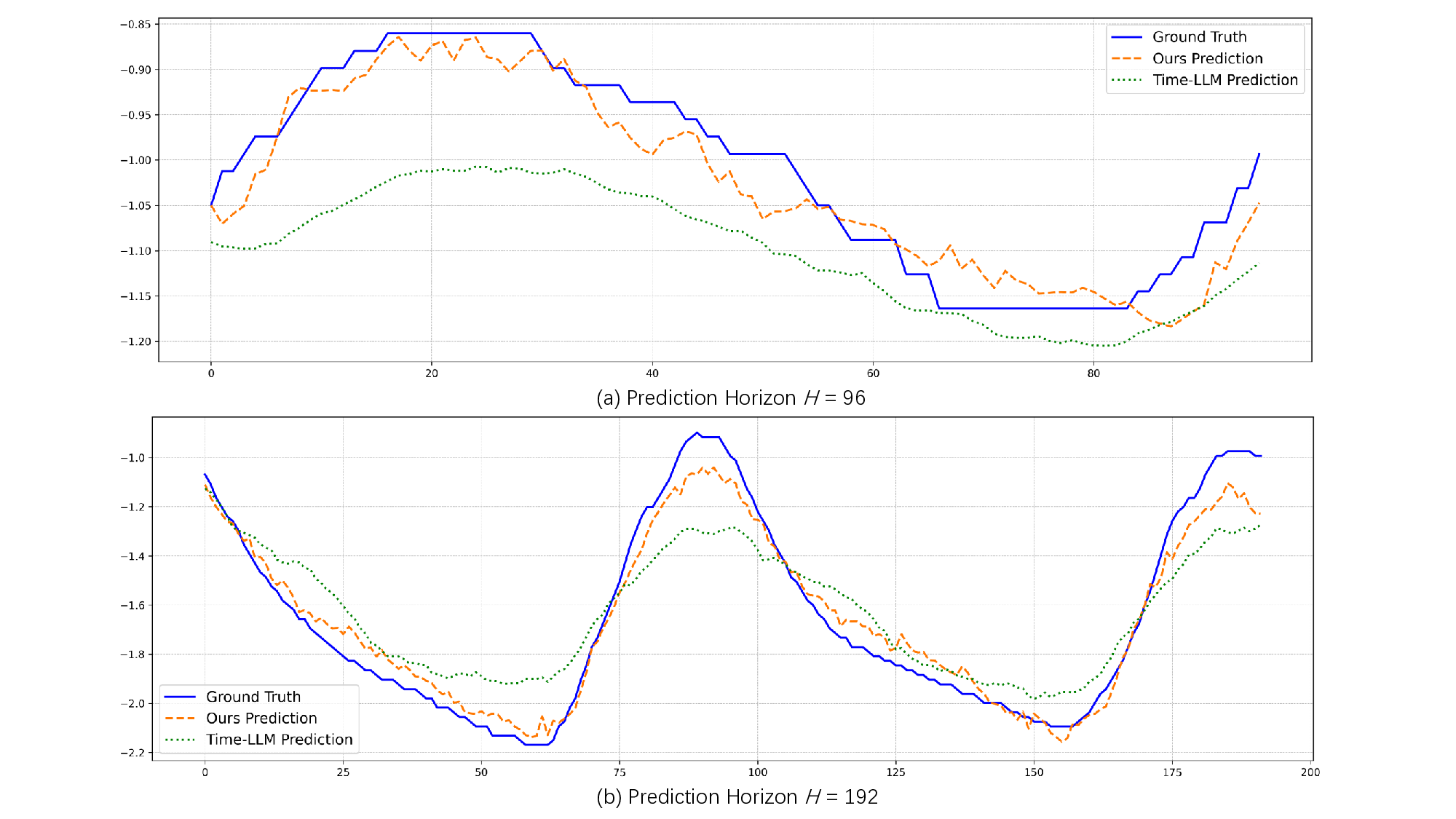
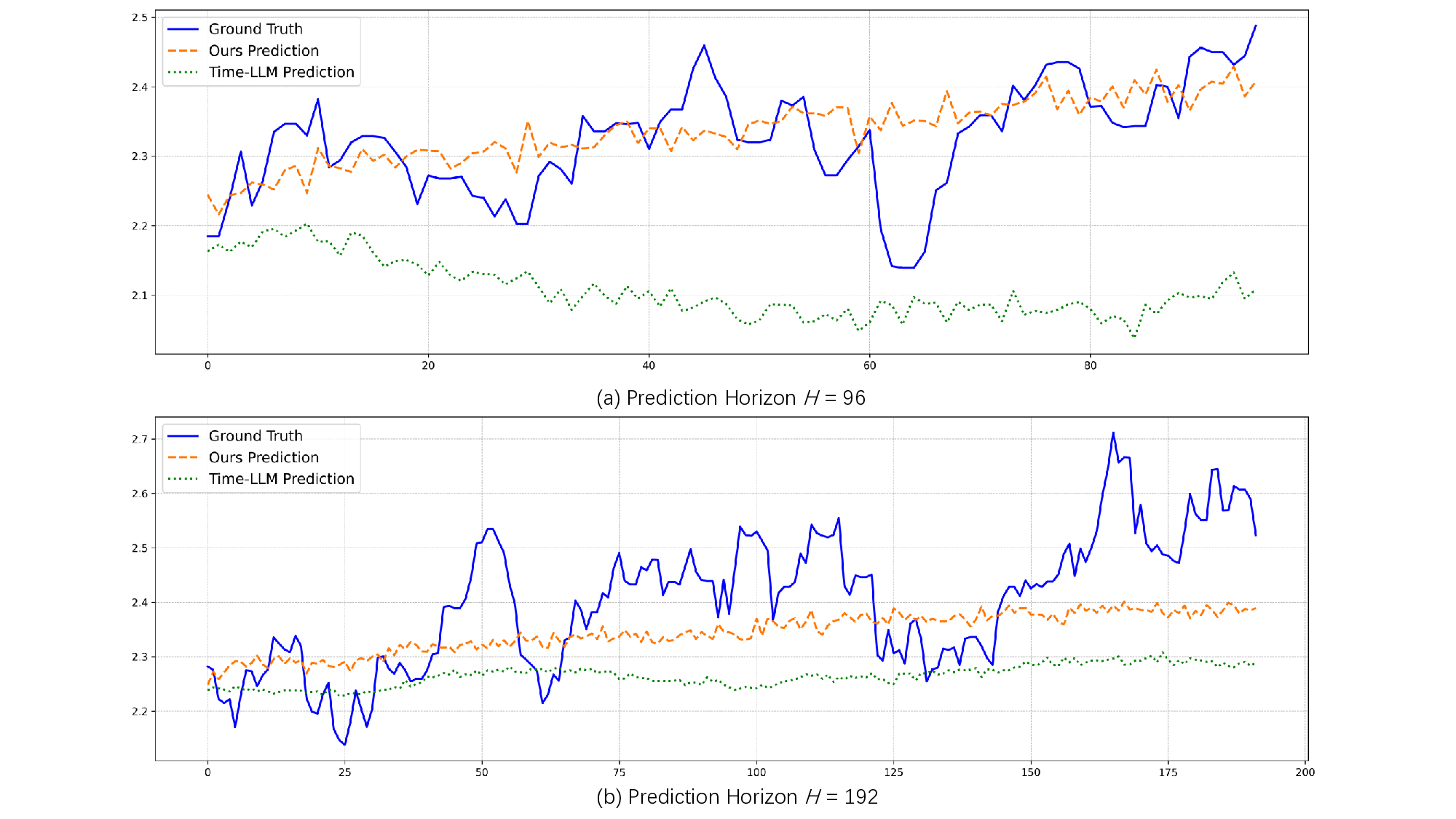
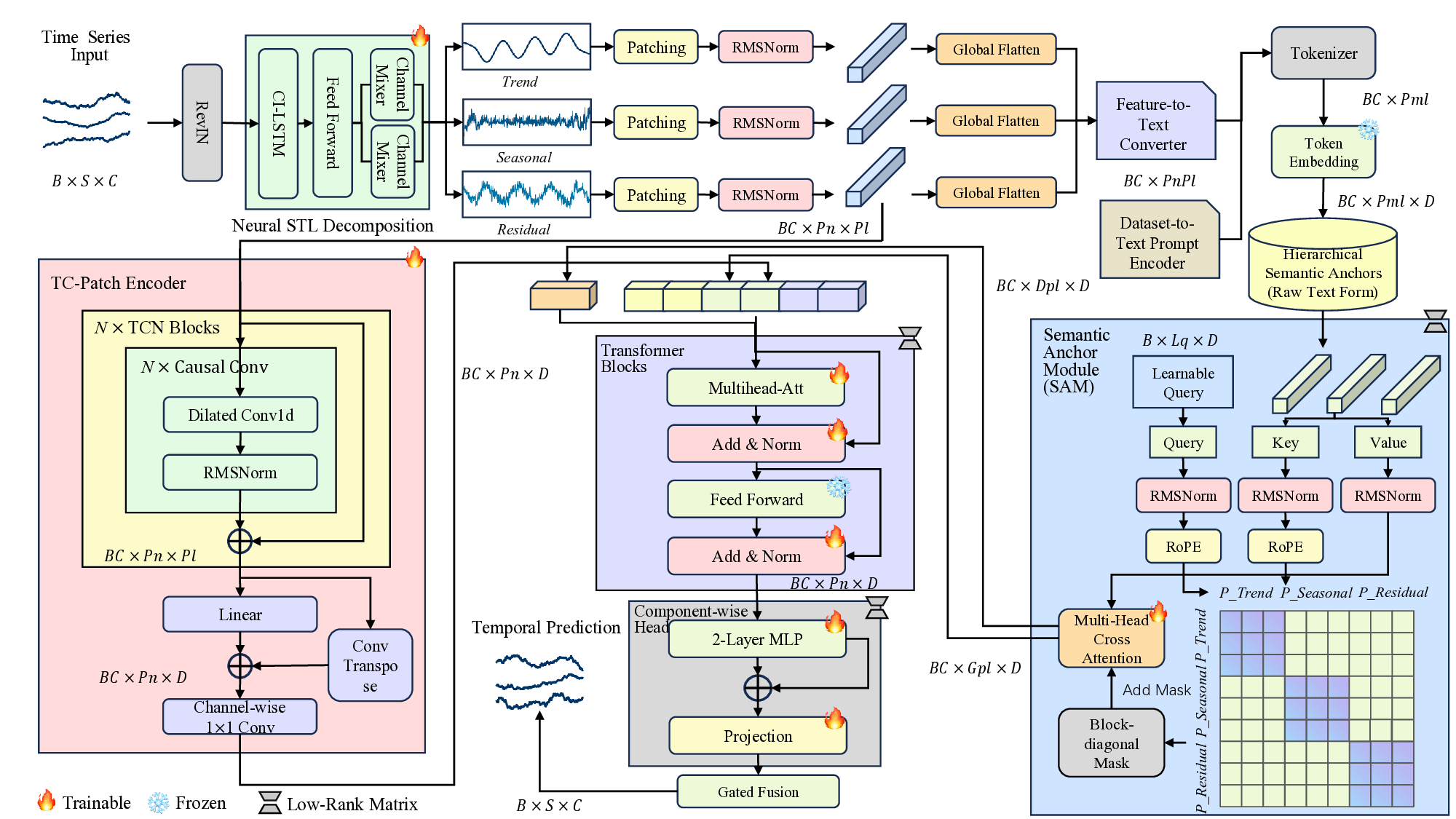
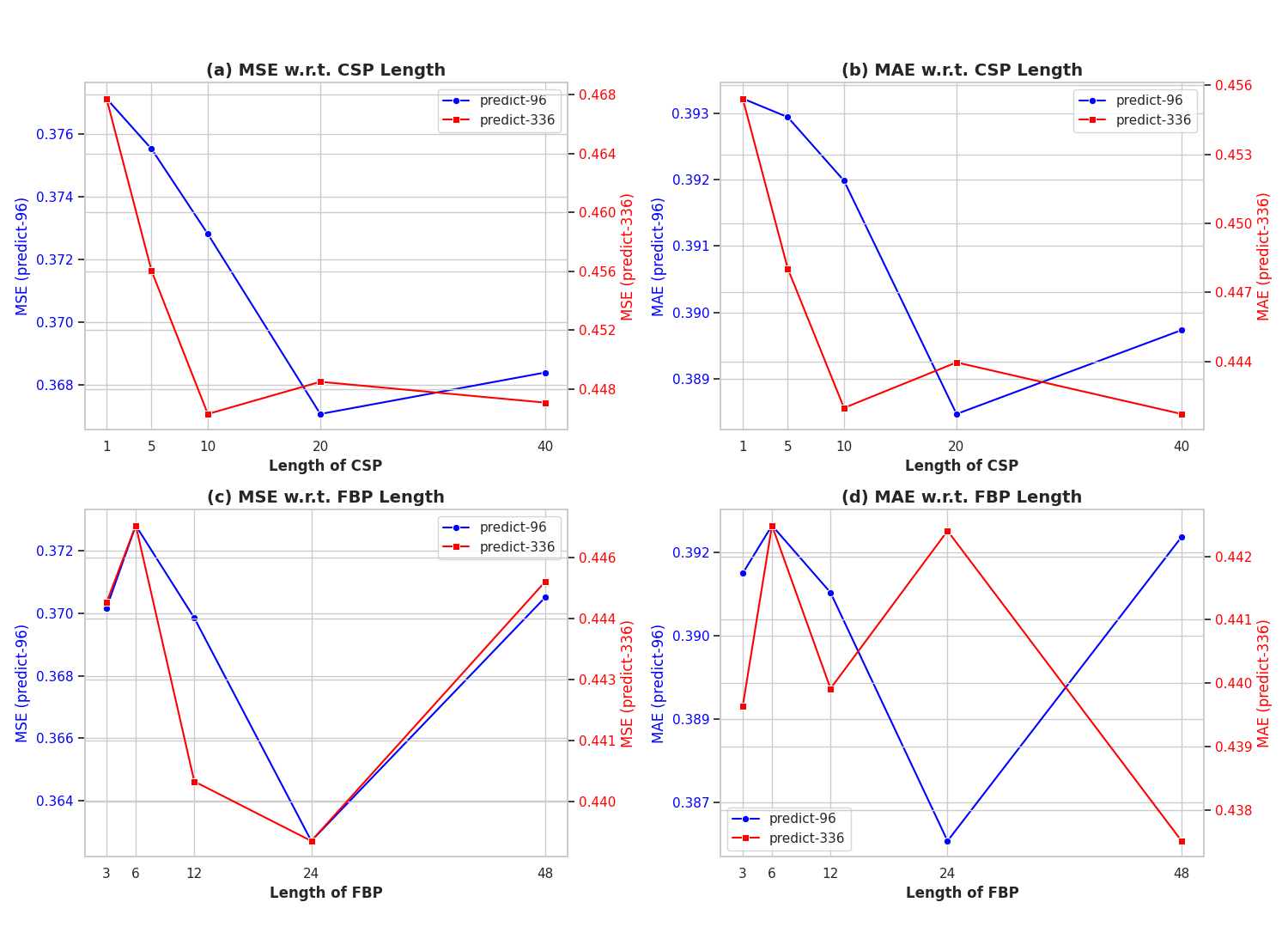
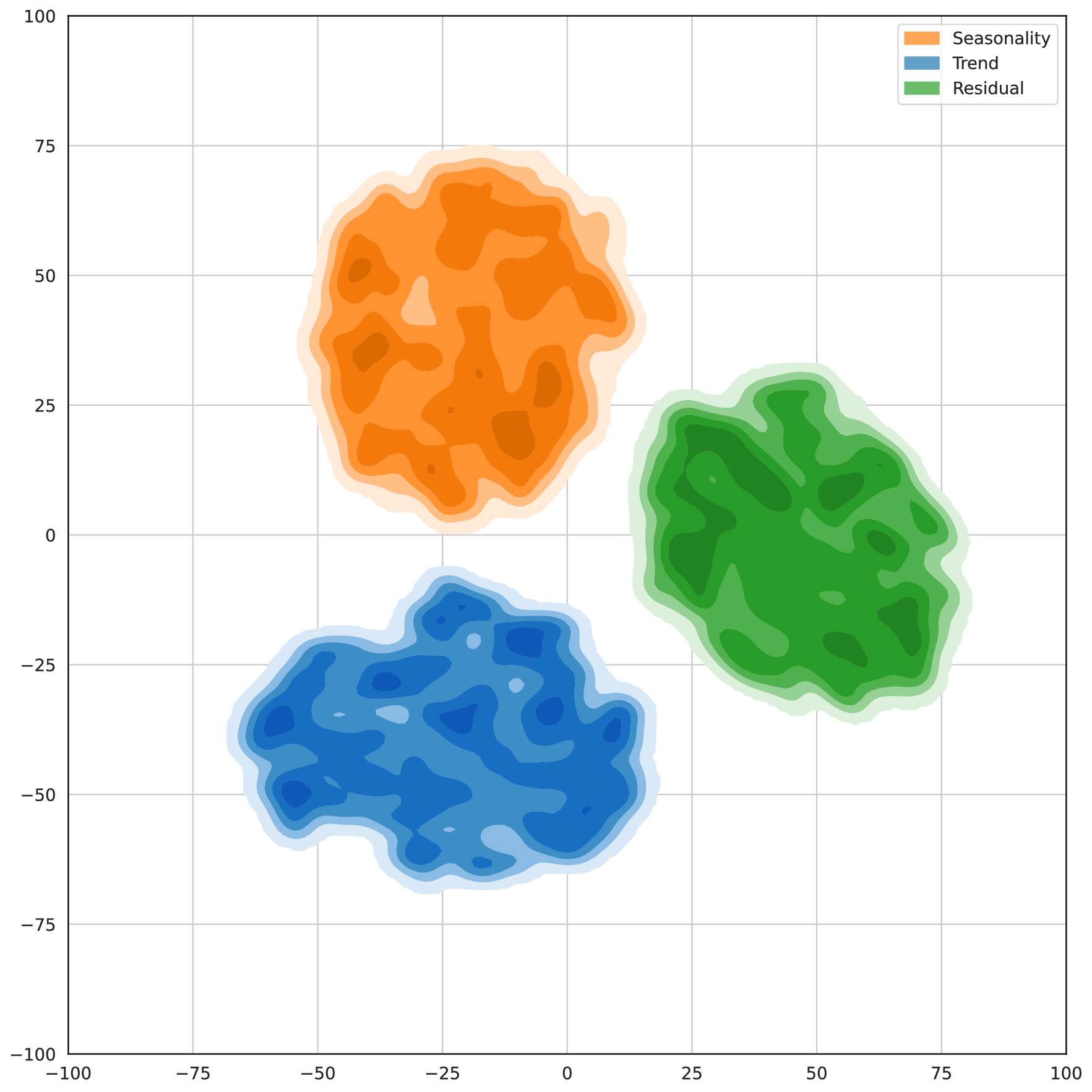
Recent adaptations of Large Language Models (LLMs) for time series forecasting often fail to effectively enhance information for raw series, leaving LLM reasoning capabilities underutilized. Existing prompting strategies rely on static correlations rather than generative interpretations of dynamic behavior, lacking critical global and instance-specific context. To address this, we propose STELLA (Semantic-Temporal Alignment with Language Abstractions), a framework that systematically mines and injects structured supplementary and complementary information. STELLA employs a dynamic semantic abstraction mechanism that decouples input series into trend, seasonality, and residual components. It then translates intrinsic behavioral features of these components into Hierarchical Semantic Anchors: a Corpus-level Semantic Prior (CSP) for global context and a Fine-grained Behavioral Prompt (FBP) for instance-level patterns. Using these anchors as prefix-prompts, STELLA guides the LLM to model intrinsic dynamics. Experiments on eight benchmark datasets demonstrate that STELLA outperforms state-of-the-art methods in long- and short-term forecasting, showing superior generalization in zero-shot and few-shot settings. Ablation studies further validate the effectiveness of our dynamically generated semantic anchors.
In recent years, foundation models, particularly Large Language Models (LLMs), have achieved revolutionary breakthroughs in natural language processing [1], [2], [3]. Their powerful sequence modeling and contextual reasoning capabilities are driving a paradigm shift across numerous related fields, demonstrating immense potential in complex, structured domains such as finance, healthcare, and beyond [4], [5], [6]. Time series forecasting, a critical task for applications like energy management, traffic planning, and meteorology [7], [8], [9], [10], [11], is at the forefront of this transformation. At present, the academic community is exploring two primary paths for developing foundation models for time series.
The first path involves building general-purpose foundation models for time series analysis from scratch. Significant efforts have been made in this direction [12], [13], [14],
• J. Fan and Y. Qi are with the School of Intellectual Property, Nanjing University of Science and Technology, Xiaolingwei 200, Nanjing, 210094, China. Email: junjiefan.edu@gmail.com, qyong@njust.edu.cn • H. Zhao, L. Wei, and J. Yuan are with the School of Economics and Management, Nanjing University of Science and Technology, Xiaolingwei 200, Nanjing, 210094, China. Email: 323107010199@njust.edu.cn, weilinduo@njust.edu.cn, 318107010178@njust.edu.cn • J. Rao, G. Li, and W. Xu are with the School of Computer Science and Engineering, Nanjing University of Science and Technology, Xiaolingwei 200, Nanjing, 210094, China. Email: jiayurao@njust.edu.cn, 124106010774@njust.edu.cn, 546153140@qq.com • Yong Qi is the corresponding author.
with works like TimesNet [12] and TimeGPT-1 [13] attempting to design universal backbones to handle time series from diverse domains. However, this path is fraught with formidable challenges: time series data exhibit a wide variety of formats and domains, and are ubiquitously affected by non-stationarity and concept drift. These factors make it exceedingly difficult to construct a single pre-trained model that can generalize across all scenarios.
The second, and increasingly prominent, path is to adapt existing pre-trained LLMs. Leveraging the robust knowledge base acquired from massive text corpora, LLMs are expected to become proficient at time series analysis with minimal fine-tuning or prompt-based learning [15]. Despite its promise, we argue that current adaptation methods suffer from a series of deep-seated issues. First, many approaches fail to leverage the core intrinsic patterns-such as seasonality, trend, and residuals-that distinguish time series from generic sequential data [16]. Indeed, the backbone architectures and prompting techniques in existing language models are not inherently designed to capture the evolution of these temporal patterns, unlike specialized models such as N-BEATS [17] and AutoFormer [18], which treat them as fundamental. This deficiency manifests in several ways. The prevalent practice of applying a patching operation on the raw series [19] not only struggles to capture the subtle variations of these key components but also leads to a significant distributional discrepancy between the resulting numerical tokens and the LLM’s native text tokens. Second, while prompting has proven to be an effective paradigm for guiding LLMs [20], existing strategies remain coarse in their generation of semantic information. For instance, recent work like S²IP-LLM [21] attempts to generate soft prompts by aligning time series embeddings with predefined “semantic anchors.” However, this retrieval-based method, which relies on similarity matching, essentially finds the most relevant tag from a static semantic pool. It establishes a correlational context rather than a generative interpretation. Consequently, it fails to generate true complementary information-a fine-grained, semantic description dynamically abstracted from the unique behavior of each individual time series instance.
These shortcomings point to a more fundamental problem: the failure to effectively augment information for the raw time series. Multimodal research has long established that a model’s powerful performance often stems from the effective fusion of different modalities of information, particularly when the model can leverage both supplementary information (providing independent context) and complementary information (offering different perspectives on the same subject) [22]. As noted by [22], leveraging complementary information allows for the capture of patterns invisible in a single modality, while building models that effectively utilize supplementary information is even more challenging. We posit that the performance bottleneck of current LLM-based forecasters is rooted in this information-level deficit. This gives rise to the central question of our work: Can we design a unified framework that systematically mines and injects structured supplementary and complementary information from the text modality to
This content is AI-processed based on open access ArXiv data.