Title: Language Models as Semantic Teachers: Post-Training Alignment for Medical Audio Understanding
ArXiv ID: 2512.04847
Date: 2025-12-04
Authors: ** - Tsai‑Ning Wang (Eindhoven University of Technology, 네덜란드) - Lin‑Lin Chen (Eindhoven University of Technology, 네덜란드) - Neil Zeghidour (Kyutai, 프랑스) - Aaqib Saeed (Eindhoven University of Technology & Eindhoven Artificial Intelligence Systems Institute, 네덜란드) **
📝 Abstract
Pre-trained audio models excel at detecting acoustic patterns in auscultation sounds but often fail to grasp their clinical significance, limiting their use and performance in diagnostic tasks. To bridge this gap, we introduce AcuLa (Audio-Clinical Understanding via Language Alignment), a lightweight post-training framework that instills semantic understanding into any audio encoder by aligning it with a medical language model, which acts as a "semantic teacher." To enable alignment at scale, we construct a large-scale dataset by leveraging off-the-shelf large language models to translate the rich, structured metadata accompanying existing audio recordings into coherent clinical reports. Our alignment strategy combines a representation-level contrastive objective with a self-supervised modeling, ensuring that the model learns clinical semantics while preserving fine-grained temporal cues. AcuLa achieves state-of-the-art results across 18 diverse cardio-respiratory tasks from 10 different datasets, improving the mean AUROC on classification benchmarks from 0.68 to 0.79 and, on the most challenging COVID-19 cough detection task, boosting the AUROC from 0.55 to 0.89. Our work demonstrates that this audio-language alignment transforms purely acoustic models into clinically-aware diagnostic tools, establishing a novel paradigm for enhancing physiological understanding in audio-based health monitoring.
💡 Deep Analysis
📄 Full Content
1
Language Models as Semantic Teachers: Post-Training Alignment for
Medical Audio Understanding
Tsai-Ning Wang, Lin-Lin Chen, Neil Zeghidour, and Aaqib Saeed
Abstract—Pre-trained audio models excel at detecting acoustic
patterns in auscultation sounds but often fail to grasp their clini-
cal significance, limiting their use and performance in diagnostic
tasks. To bridge this gap, we introduce AcuLa (Audio–Clinical
Understanding via Language Alignment), a lightweight post-
training framework that instills semantic understanding into
any audio encoder by aligning it with a medical language
model, which acts as a “semantic teacher.” To enable alignment
at scale, we construct a large-scale dataset by leveraging off-
the-shelf large language models to translate the rich, struc-
tured metadata accompanying existing audio recordings into
coherent clinical reports. Our alignment strategy combines a
representation-level contrastive objective with a self-supervised
modeling, ensuring that the model learns clinical semantics while
preserving fine-grained temporal cues. AcuLa achieves state-of-
the-art results across 18 diverse cardio-respiratory tasks from 10
different datasets, improving the mean AUROC on classification
benchmarks from 0.68 to 0.79 and, on the most challenging
COVID-19 cough detection task, boosting the AUROC from
0.55 to 0.89. Our work demonstrates that this audio-language
alignment transforms purely acoustic models into clinically-aware
diagnostic tools, establishing a novel paradigm for enhancing
physiological understanding in audio-based health monitoring.
Index Terms—Audio understanding, Large language models,
Cross-modal alignment, Knowledge distillation
I. INTRODUCTION
Existing audio encoders capture subtle temporal and spectral
patterns in auscultation sounds but still lack explicit clinical
semantics. This capability gap renders them “semantically
blind,” limiting their utility in high-stakes diagnostic tasks.
This creates a fundamental paradox: while large language
models (LLMs) possess deep, contextual knowledge of med-
ical terminology like “systolic murmurs” or “wheezes,” this
understanding remains disconnected from the audio models
that process the raw signals. Digital stethoscopes and other
sensors may capture a wealth of acoustic data, but without a
bridge to semantic meaning, this information remains under-
utilized.
Multimodal
contrastive
learning,
popularized
by
frameworks like CLIP [1], aims to bridge such divides
by aligning heterogeneous modalities in a shared embedding
space. This approach has enabled powerful cross-modal
retrieval
and
classification
capabilities.
However,
these
methods often suffer from a persistent ’modality gap,’ where
embeddings from different sources form distinct clusters,
Tsai-Ning Wang and Lin-Lin Chen are with Eindhoven University of
Technology, The Netherlands (e-mail: t.n.wang@tue.nl; l.chen@tue.nl).
Neil Zeghidour is with Kyutai, France (e-mail: neil@kyutai.org).
Aaqib Saeed is with the Eindhoven University of Technology, The Nether-
lands and the Eindhoven Artificial Intelligence Systems Institute, The Nether-
lands. (e-mail: a.saeed@tue.nl).
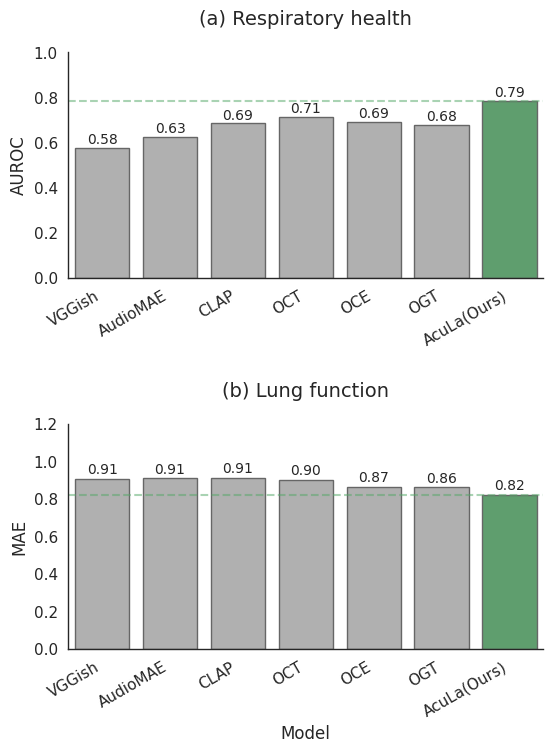
Fig. 1: Performance comparison of audio-based models. (a) Average
AUROC for respiratory classification tasks (T1-T9). (b) Average
MAE for lung function estimation tasks (T10-T16). Our model (pink)
outperforms all baselines, achieving the highest AUROC (0.79) and
lowest MAE (0.82).
hindering fine-grained alignment and interpretability [2], [3].
This issue is particularly acute in clinical applications, where
subtle acoustic variations carry significant diagnostic weight
and demand precise semantic grounding.
While existing methods have sought to bridge this gap
through architectural modifications [4], auxiliary objectives
[5], or post-training alignment [6], their focus has been on
aligning two perceptual modalities. Even recent advances in
knowledge transfer, such as [7], operate under this paradigm,
enhancing language models by injecting knowledge from
vision models. These approaches share a common directional
assumption: knowledge flows from concrete perception to
abstract representation. Our work fundamentally diverges by
arXiv:2512.04847v1 [cs.SD] 4 Dec 2025
2
Murmur, Symptomatic, ....
FVC, Respiratory Rate, ....
Audio
Encoder
Cardiac and Respiratory Sounds
Clinical Textual Reports
Audio
Embeddings
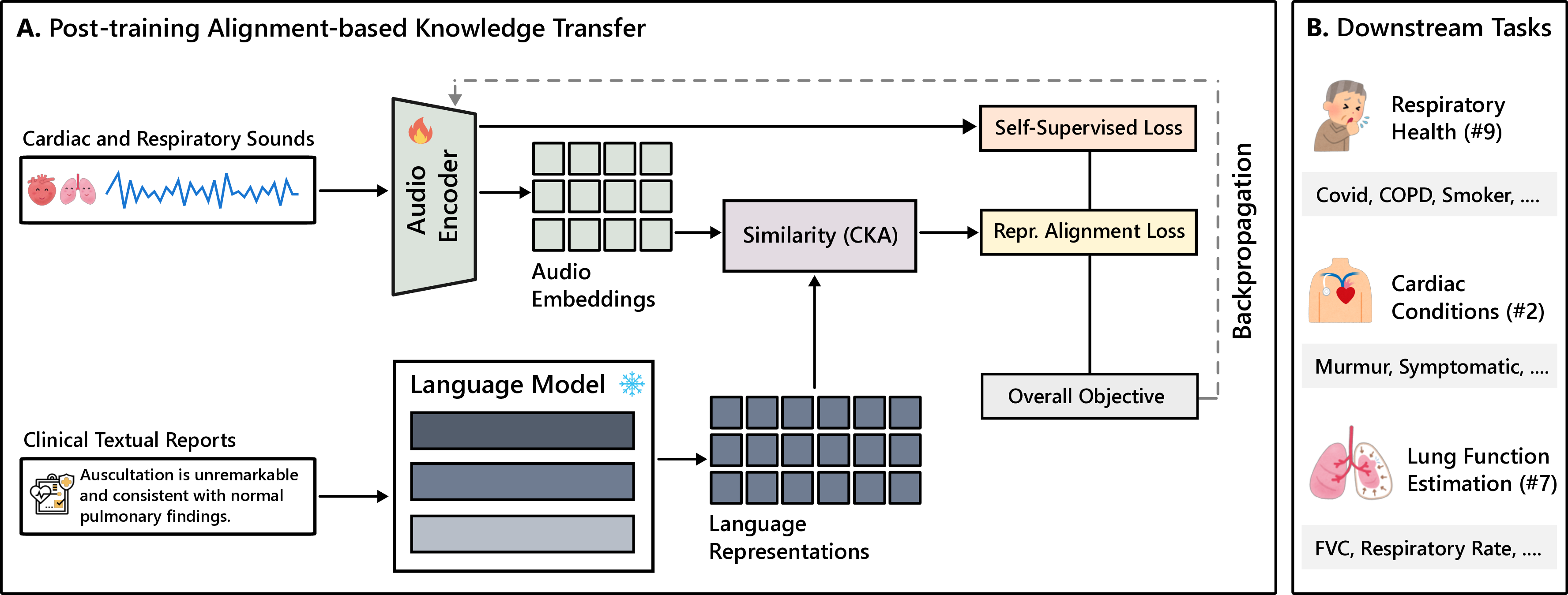
A. Post-training Alignment-based Knowledge Transfer
B. Downstream Tasks
Lung Function
Estimation (#7)
Cardiac
Conditions (#2)
Respiratory
Health (#9)
Auscultation is unremarkable
and consistent with normal
pulmonary findings.
Language
Representations
Repr. Alignment Loss
Self-Supervised Loss
Overall Objective
Language Model
Similarity (CKA)
Backpropagation
Covid, COPD, Smoker, ....
Fig. 2: Architecture of the audio-language alignment framework. (A) Audio encoders extract features from clinical recordings, which
are aligned with language representations via similarity matching. (B) Down-stream tasks en