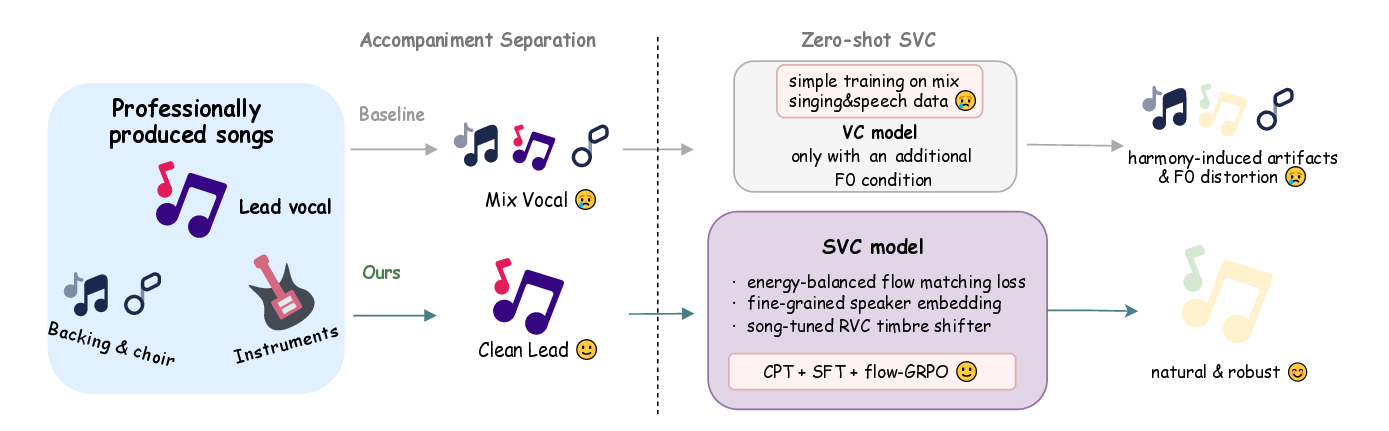
Singing voice conversion (SVC) aims to render the target singer's timbre while preserving melody and lyrics. However, existing zero-shot SVC systems remain fragile in real songs due to harmony interference, F0 errors, and the lack of inductive biases for singing. We propose YingMusic-SVC, a robust zero-shot framework that unifies continuous pre-training, robust supervised fine-tuning, and Flow-GRPO reinforcement learning. Our model introduces a singing-trained RVC timbre shifter for timbre-content disentanglement, an F0-aware timbre adaptor for dynamic vocal expression, and an energy-balanced rectified flow matching loss to enhance high-frequency fidelity. Experiments on a graded multi-track benchmark show that YingMusic-SVC achieves consistent improvements over strong open-source baselines in timbre similarity, intelligibility, and perceptual naturalness, especially under accompanied and harmony-contaminated conditions, demonstrating its effectiveness for real-world SVC deployment.
Singing voice conversion (SVC) (Bai et al., 2024;Zhou et al., 2025;Chen et al., 2019;Mohammadi and Kain, 2017;Engel et al., 2019) aims to transform the vocal timbre of a source singer into that of a target singer while preserving the original musical content. This technique has promising applications in creative music production, virtual singers, and social media content creation. Recently, any-to-many SVC works such as So-VITS-SVC (Team, 2023b) and RVC (Team, 2023a) have been able to achieve realistic conversion effects, but they lack robustness and require fine-tuning using target speaker data; The zero-shot SVC model (Liu, 2024) has achieved good conversion results on the pure vocal test set under laboratory conditions. However, there remains a substantial gap between current research prototypes and the requirements of real-world industrial applications. On one hand, most SVC systems are evaluated on ideal clean vocals and struggle when faced with full songs that include background accompaniment. In practical pipelines, due to the scarcity of available a cappella vocal tracks, a music source separation module is typically applied upfront to isolate vocals from the mixed audio (Chen et al., 2024b(Chen et al., , 2025)). This two-stage approach introduces new challenges: contemporary music productions often add backing vocals or harmony layers to the lead vocal (Hennequin et al., 2020), which means the separated "vocals" track may still contain residual artifacts. Converting such imperfect vocals can lead to audible artifacts in the output; furthermore, any inaccuracies in fundamental frequency (F0) extraction (Kim et al., 2018;Wei et al., 2023) under noisy conditions can result in off-key or distorted converted singing. On the other hand, most zero-shot voice conversion approaches simply incorporate an F0 conditioning on top of a speech VC architecture, without imparting inductive biases tailored for singing. These generic designs fail to account for key characteristics of singing voices -for example, singing vocals exhibit much larger dynamics and timbral variability, and their spectral content contains richer high-frequency harmonic components than normal speech (Sundberg, 1987;Lundy et al., 2000;Blaauw and Bonada, 2017;Gupta et al., 2022). Consequently, vanilla zero-shot VC models often underperform on singing data, as they do not sufficiently emphasize the high-frequency details and other singing-specific attributes.
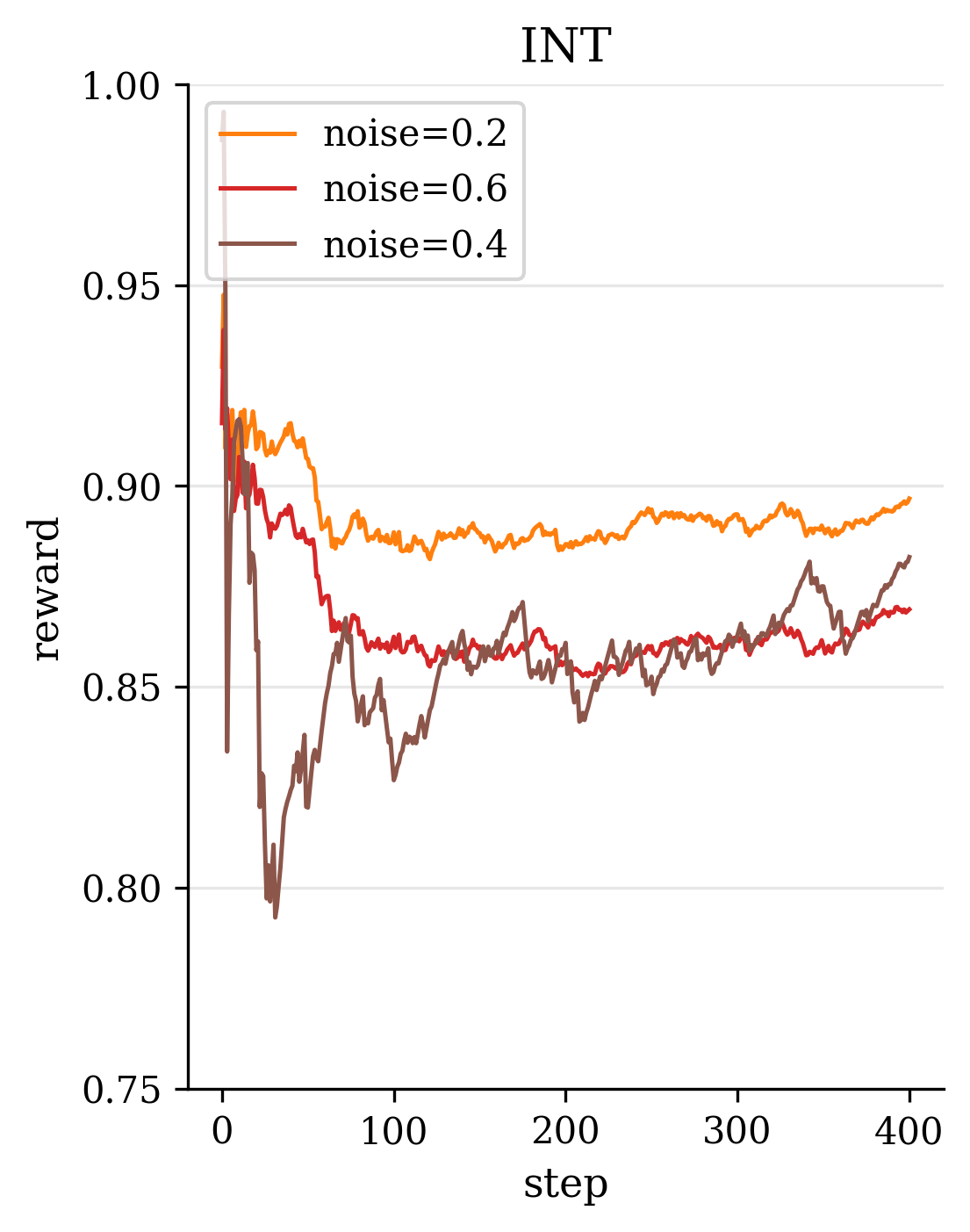
As illustrated in Figure 1, these limitations frequently manifest as harmony leakage, F0 instability, and spectral artifacts when current zero-shot SVC models are applied to professionally produced songs.
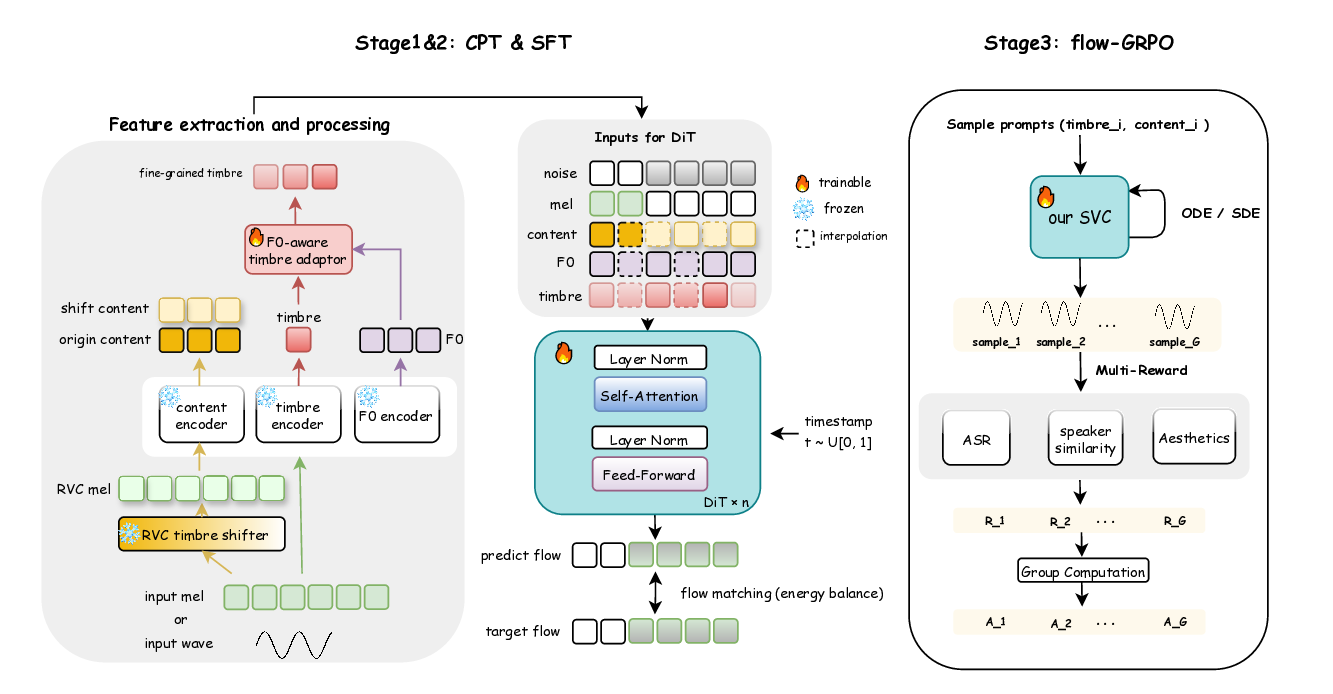
To bridge these gaps, we propose a comprehensive set of improvements for robust zero-shot SVC in industrial scenarios. First, regarding pipeline robustness, we enhance the vocal separation front-end using internal multi-track data, yielding cleaner vocal stems free of harmony bleed. In parallel, we devise a robust fine-tuning (SFT) training strategy for the SVC model: by augmenting training with lightly distorted and harmony-contaminated vocals, we improve the model’s resilience to real-world noisy inputs, thereby mitigating artifacts like voice cracking and residual harmony in the conversions.
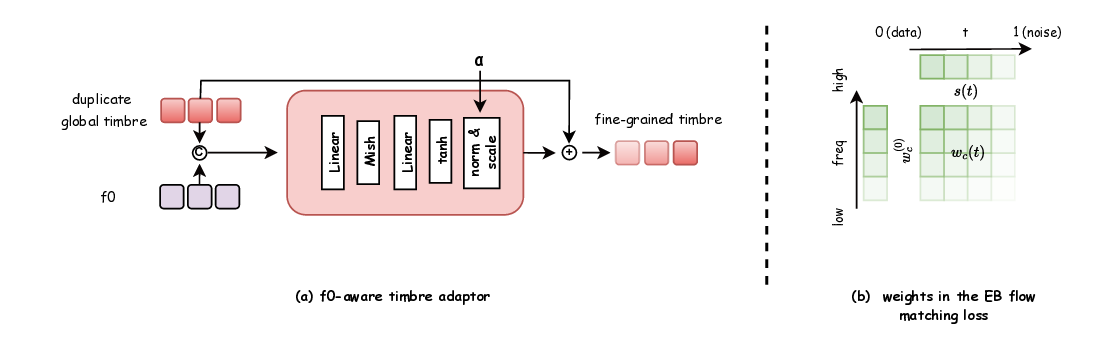
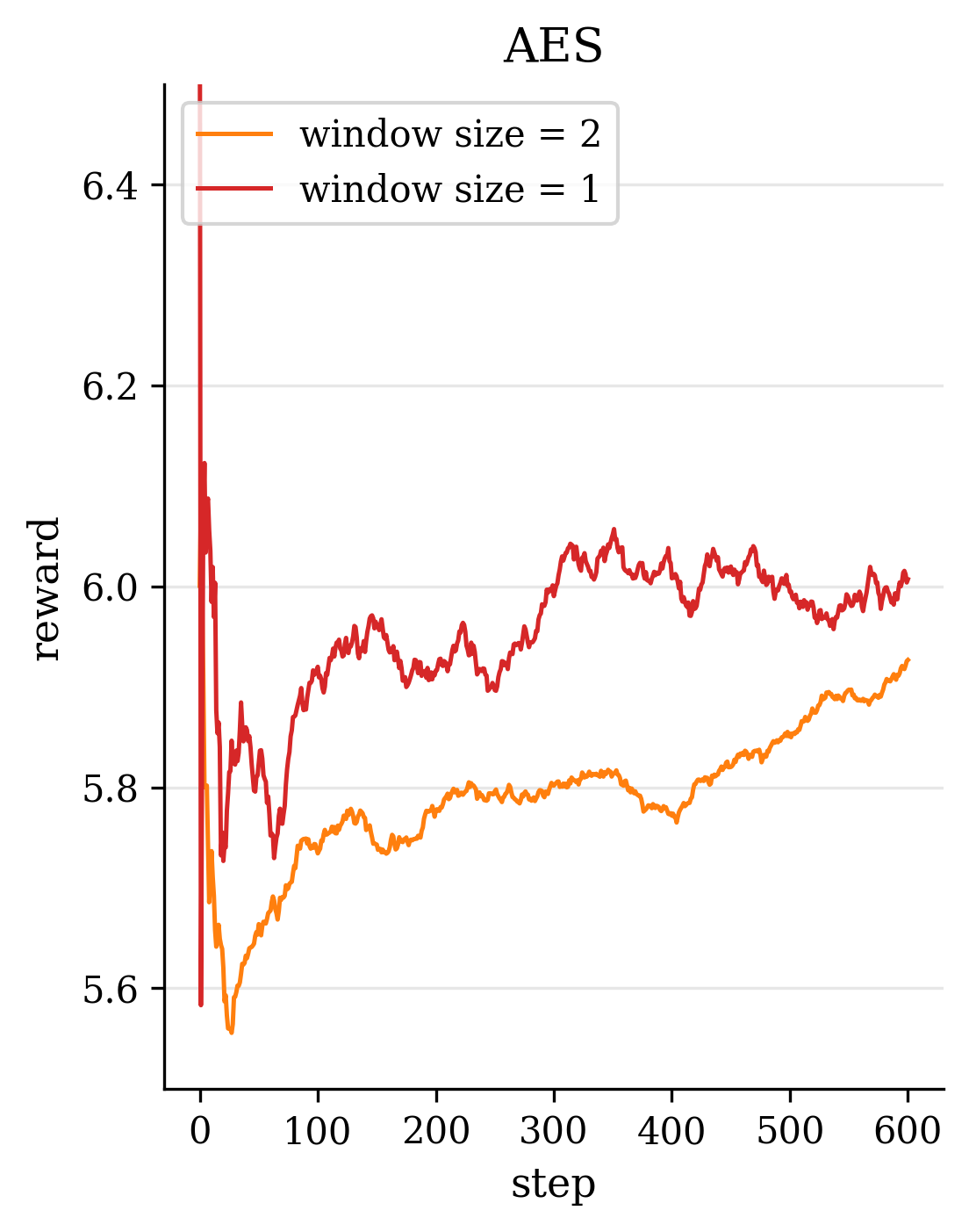
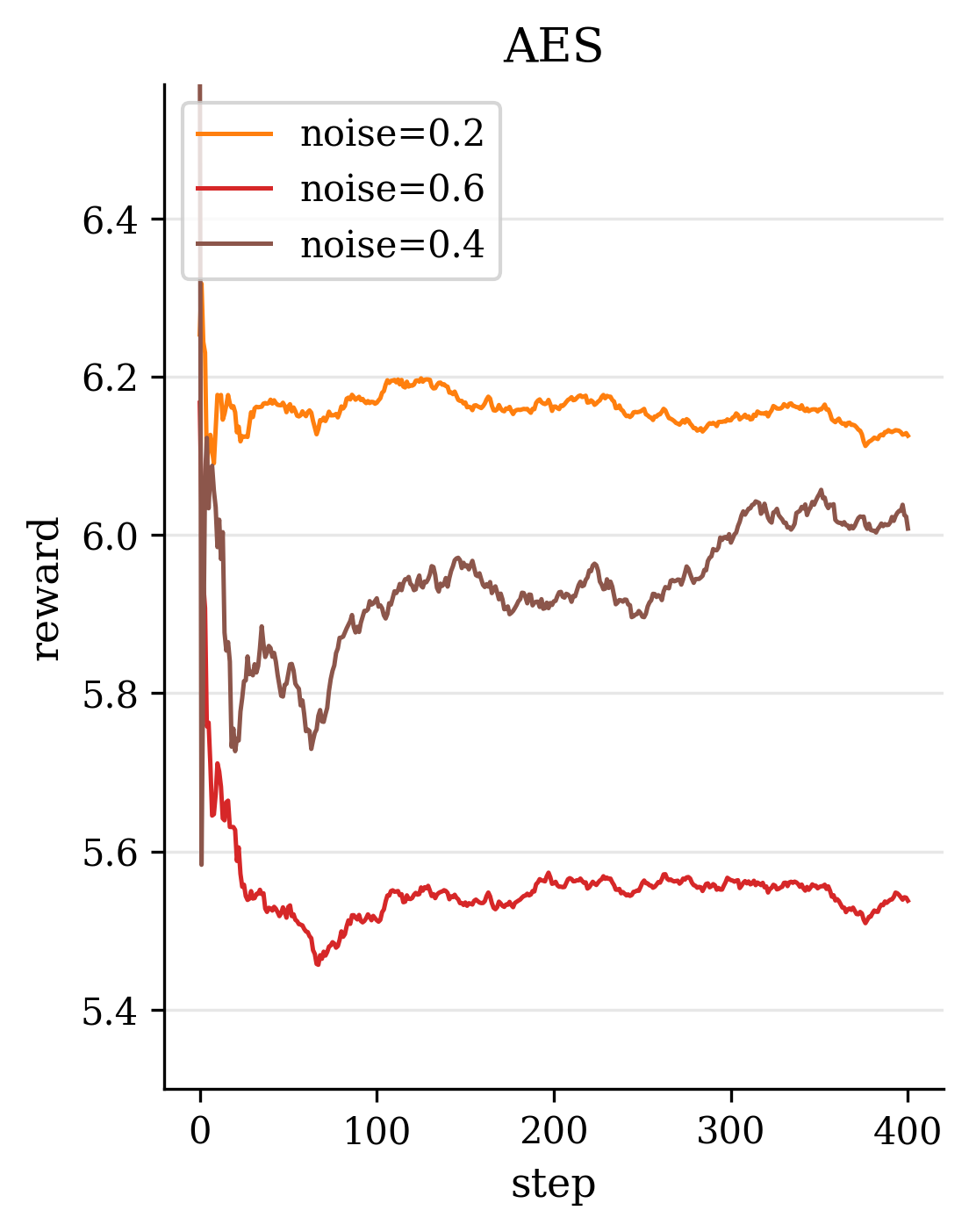
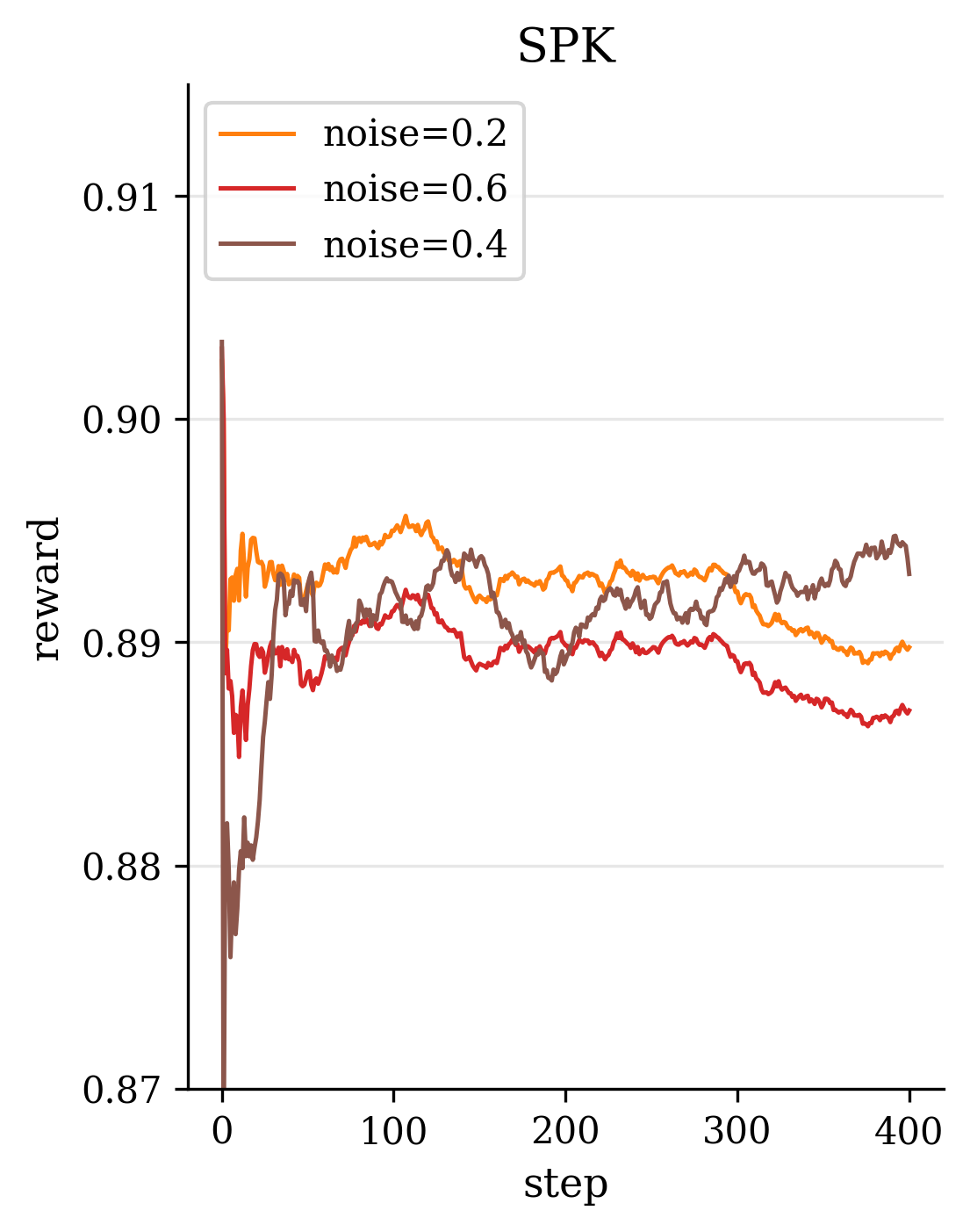
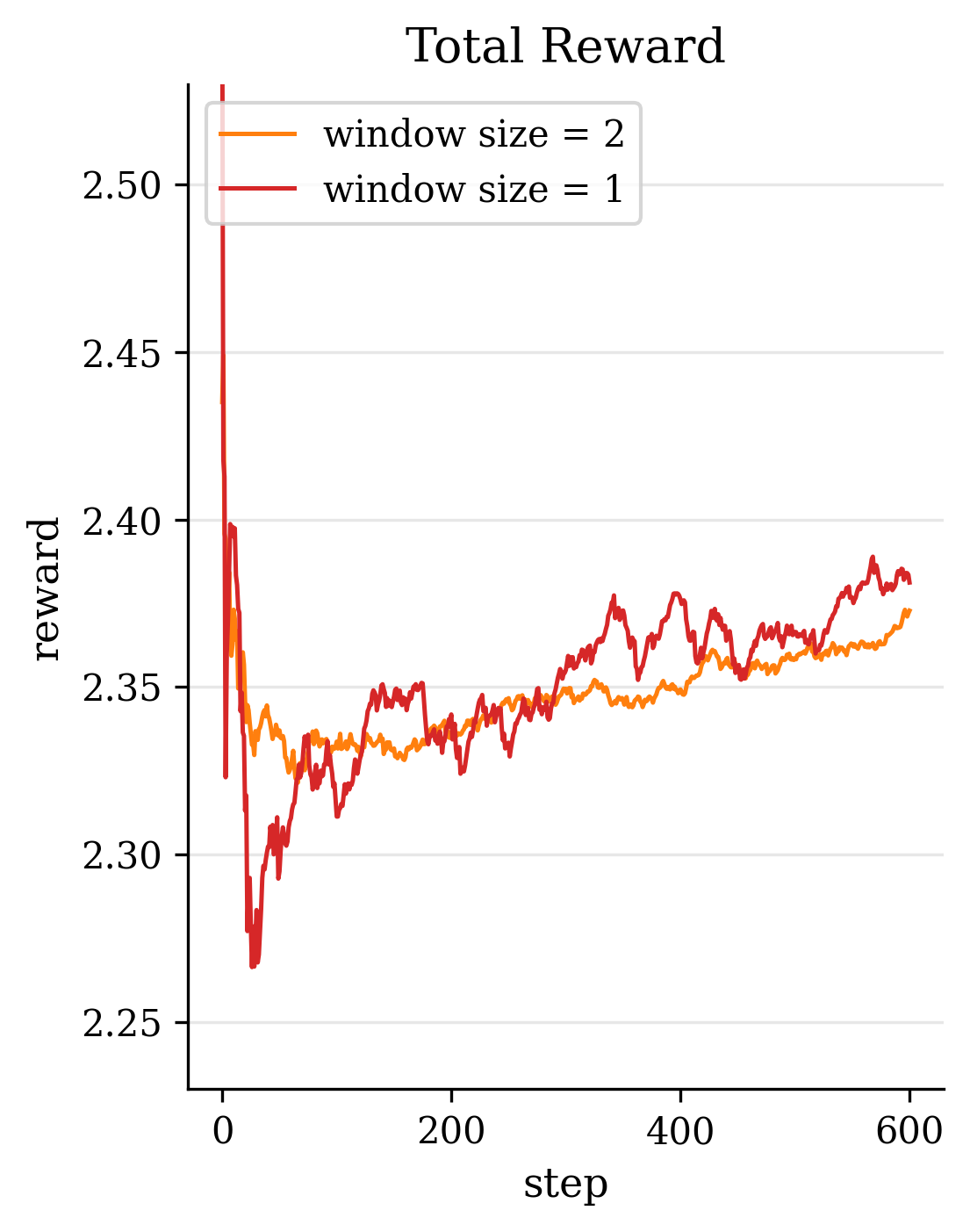
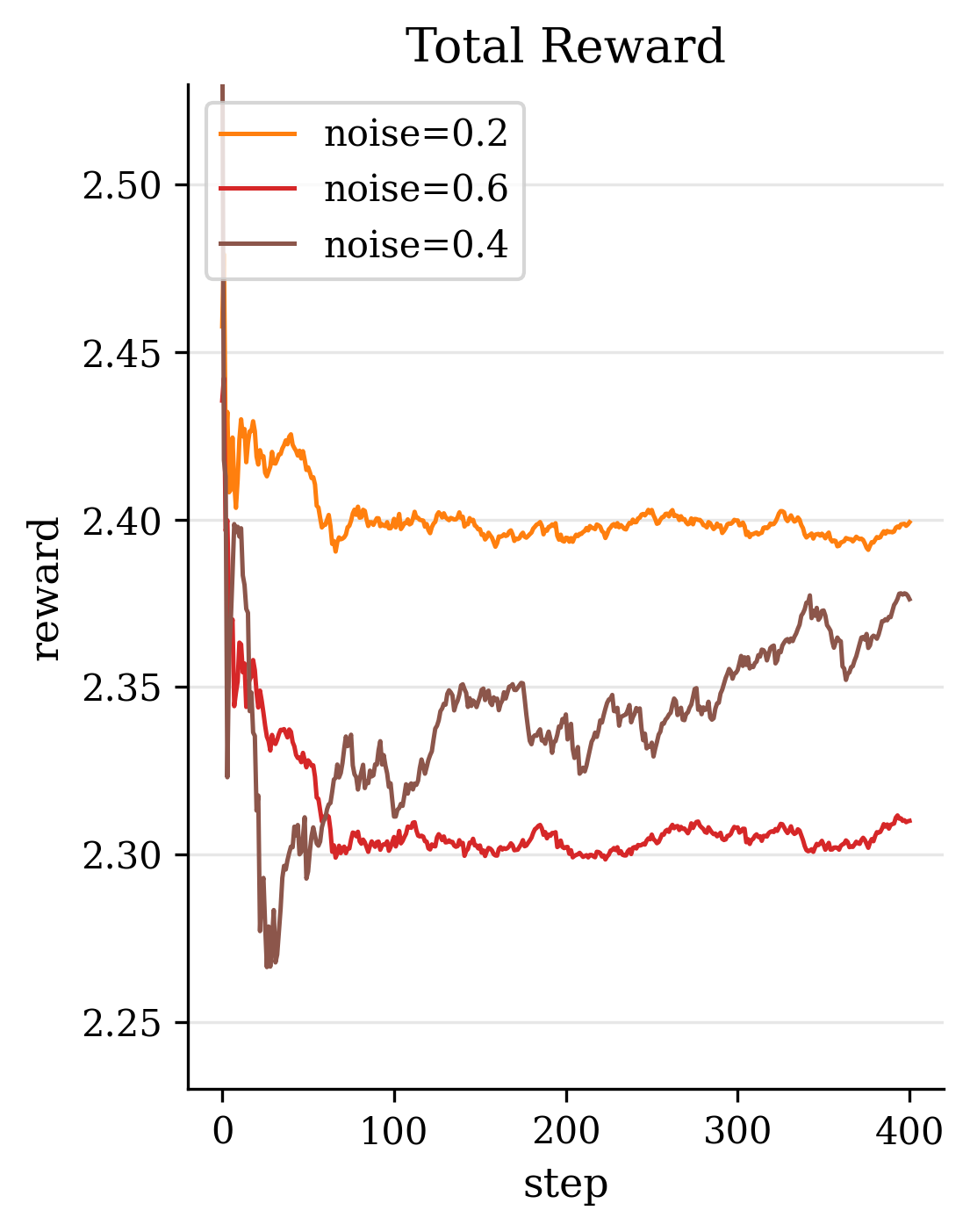
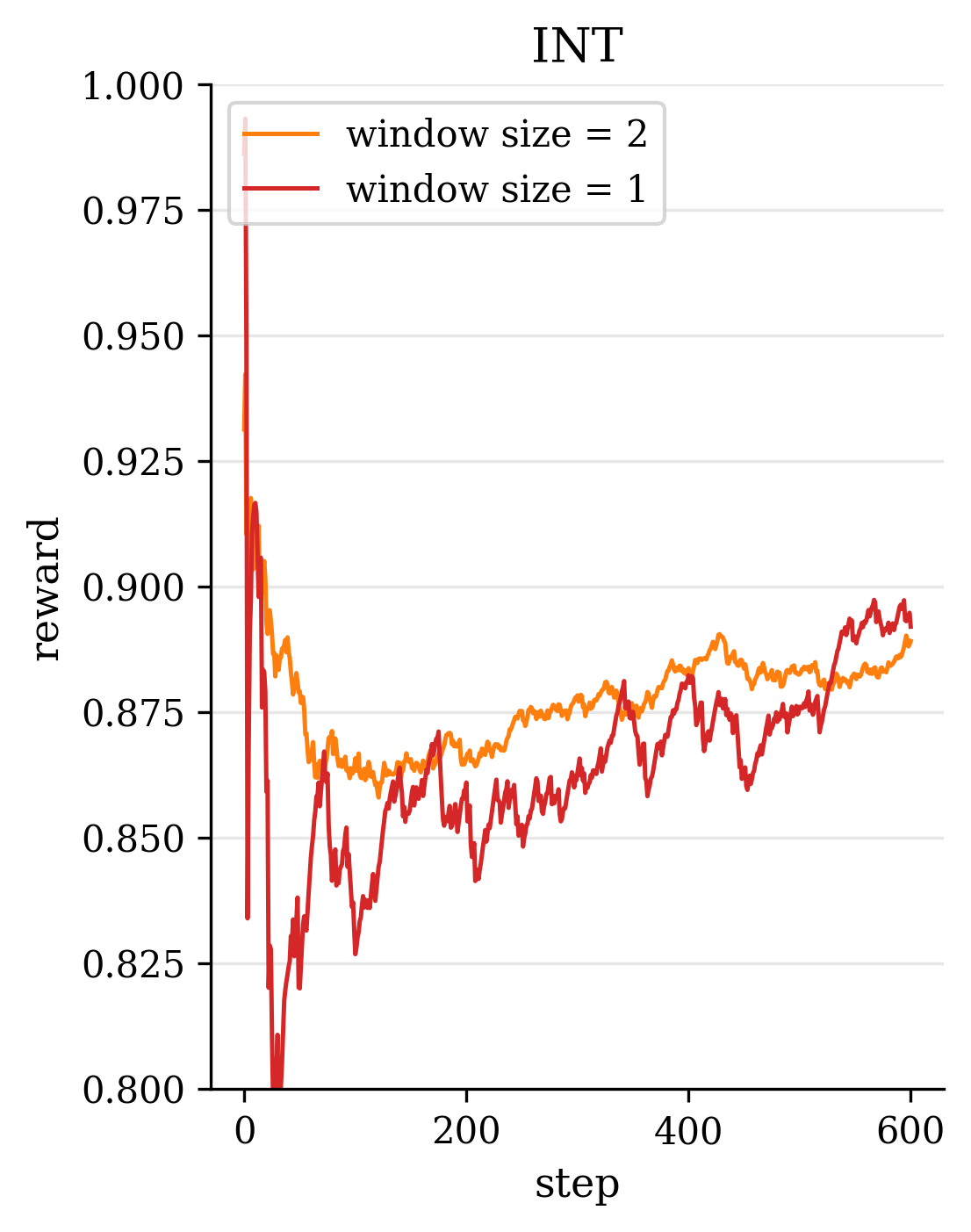
Second, in terms of model design, we introduce novel modules and loss functions tailored to singing audio. We incorporate an F0-aware fine-grained timbre adaptation module that allows the model to dynamically adjust timbre features conditioned on pitch, enhancing the expressive dynamics of the converted singing. Furthermore, in order to neither lose high-frequency information nor leak timbre features during content feature extraction, we adopted the RVC model trained with singing data as the timbre shifter. We also design an energy-balanced flow matching loss (Lipman et al., 2022) that rebalances the training objective to give more emphasis to high-frequency, low-energy regions of the spectrum, encouraging the model to pay extra attention to fine high-frequency details of the singing voice. Finally, we explore a reinforcement learning (RL) (Sutton et al., 1998) based post-training paradigm for SVC by applying a Flow-GRPO algorithm (Liu et al., 2025a) to refine the model. We formulate a multi-objective reward that combines speech quality metrics with aesthetic style measures, thereby simultaneously improving the converted singing’s technical quality and artistic expressiveness.
Our main contributions are summarized as follows:
• An end-to-end robust SVC pipeline for industrial use. We develop an improved accompaniment separation model and a robustness-enhanced SVC training process, which together significantly improve conversion quality on songs with accompaniment, reducing artifacts from residual harmonies and F0 extraction errors. A benchmark and difficulty classification test set for real scenarios was also designed and a comprehensive assessment was conducted.
• Singing-specific modeling e
This content is AI-processed based on open access ArXiv data.