Title: KH-FUNSD: A Hierarchical and Fine-Grained Layout Analysis Dataset for Low-Resource Khmer Business Document
ArXiv ID: 2512.11849
Date: 2025-12-04
Authors: Nimol Thuon, Jun Du
📝 Abstract
Automated document layout analysis remains a major challenge for low-resource, non-Latin scripts. Khmer is a language spoken daily by over 17 million people in Cambodia, receiving little attention in the development of document AI tools. The lack of dedicated resources is particularly acute for business documents, which are critical for both public administration and private enterprise. To address this gap, we present \textbf{KH-FUNSD}, the first publicly available, hierarchically annotated dataset for Khmer form document understanding, including receipts, invoices, and quotations. Our annotation framework features a three-level design: (1) region detection that divides each document into core zones such as header, form field, and footer; (2) FUNSD-style annotation that distinguishes questions, answers, headers, and other key entities, together with their relationships; and (3) fine-grained classification that assigns specific semantic roles, such as field labels, values, headers, footers, and symbols. This multi-level approach supports both comprehensive layout analysis and precise information extraction. We benchmark several leading models, providing the first set of baseline results for Khmer business documents, and discuss the distinct challenges posed by non-Latin, low-resource scripts. The KH-FUNSD dataset and documentation will be available at URL.
💡 Deep Analysis
📄 Full Content
2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
KH-FUNSD: A Hierarchical and Fine-Grained
Layout Analysis Dataset for Low-Resource Khmer
Business Document
Nimol Thuon∗and Jun Du∗†
∗National Engineering Research Center of Speech and Language Information Processing (NERC-SLIP)
University of Science and Technology of China, Hefei, Anhui, 230027, China
E-mail: tnimol@mail.ustc.edu.cn, jundu@ustc.edu.cn
Abstract—Automated document layout analysis remains a ma-
jor challenge for low-resource, non-Latin scripts. Khmer is a
language spoken daily by over 17 million people in Cambodia,
receiving little attention in the development of document AI tools.
The lack of dedicated resources is particularly acute for business
documents, which are critical for both public administration
and private enterprise. To address this gap, we present KH-
FUNSD, the first publicly available, hierarchically annotated
dataset for Khmer form document understanding, including
receipts, invoices, and quotations. Our annotation framework
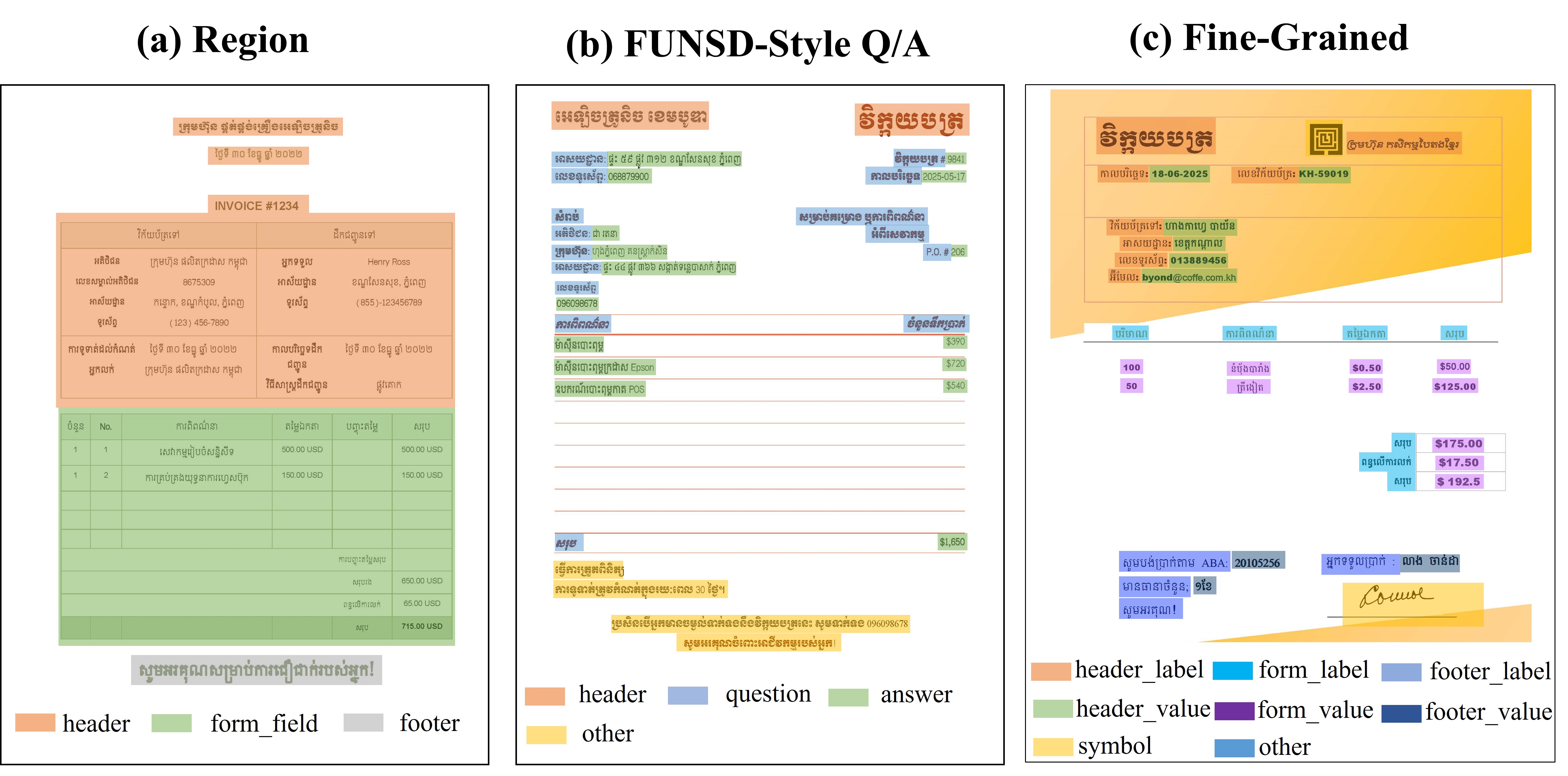
features a three-level design: (1) region detection that divides
each document into core zones such as header, form field, and
footer; (2) FUNSD-style annotation that distinguishes questions,
answers, headers, and other key entities, together with their
relationships; and (3) fine-grained classification that assigns
specific semantic roles, such as field labels, values, headers,
footers, and symbols. This multi-level approach supports both
comprehensive layout analysis and precise information extraction.
We benchmark several leading models, providing the first set
of baseline results for Khmer business documents, and discuss
the distinct challenges posed by non-Latin, low-resource scripts.
The KH-FUNSD dataset and documentation will be available at
https://github.com/back-kh/KH-FUNSD.
I. INTRODUCTION
The extraction of structured information from form-like doc-
uments is fundamental to digital transformation across sectors
[1], [2], [3]. Automated document layout analysis, understand-
ing both the spatial and semantic structure of documents such
as receipts and invoices, enables efficient data entry, large-scale
digitization, business analytics, and regulatory compliance.
Recent advances in layout-aware deep learning models, such
as LayoutLM and its successors, have significantly improved
performance in this field [4], [5], [6]. However, these models
and their associated benchmarks have been developed primar-
ily for high-resource, Latin-script languages, leaving non-Latin
and low-resource scripts underrepresented.
Khmer, the official and most widely spoken language of
Cambodia, is used daily by over 17 million people [7], [8], [9].
As Cambodia undergoes rapid digitalization, the demand for
Khmer-language AI tools and resources has become increas-
ingly urgent. Business documents such as receipts, invoices,
†Corresponding author
and quotations play a critical role in commerce, public ad-
ministration, taxation, and archival systems, yet remain largely
underserved by existing document analysis technologies [10].
Most current tools and datasets are tailored to English or
other high-resource languages, making it challenging to di-
rectly apply state-of-the-art models to Khmer. The script
itself presents unique challenges, including complex ligatures,
stacked characters, and the lack of whitespace between words,
all of which significantly hinder OCR and layout analysis [11],
[12]. Furthermore, the absence of publicly available annotated
datasets for Khmer business documents further limits both
research progress and practical deployment [13], [14].
To address these challenges, we introduce KH-FUNSD, the
first publicly available, hierarchically annotated dataset and
evaluation benchmark for Khmer business documents. Our
annotation scheme adopts a three-level framework, consisting
of region-level detection, FUNSD-style entity linking, and
fine-grained semantic labeling, which together capture both
structural and semantic aspects of business documents.
The main contributions of this work are as follows:
• We introduce KH-FUNSD, the first dataset and bench-
mark for Khmer Form Document Understanding, with
comprehensive region annotations, FUNSD-style Q&A,
and hierarchical annotations for layout analysis.
• We provide baseline evaluations using state-of-the-art
models (YOLO, DETR, LayoutLM) for region detection
and semantic role prediction.
• We make all dataset, guidelines publicly available to
support further research and development in this field.
This multi-level annotation approach enables robust struc-
tural layout modeling and precise semantic information extrac-
tion. By providing the first standardized evaluation for Khmer
receipts and invoices, our work aims to bridge the gap in
low-resource document AI and promote inclusive research for
underrepresented languages across Southeast Asia.
II. RELATED WORK
A. Layout Analysis and Document Understanding
Doc