Diffusion models have emerged as a widely utilized and successful methodology in human motion synthesis. Task-oriented diffusion models have significantly advanced action-to-motion, text-to-motion, and audio-to-motion applications. In this paper, we investigate fundamental questions regarding motion representations and loss functions in a controlled study, and we enumerate the impacts of various decisions in the workflow of the generative motion diffusion model. To answer these questions, we conduct empirical studies based on a proxy motion diffusion model (MDM). We apply v loss as the prediction objective on MDM (vMDM), where v is the weighted sum of motion data and noise. We aim to enhance the understanding of latent data distributions and provide a foundation for improving the state of conditional motion diffusion models. First, we evaluate the six common motion representations in the literature and compare their performance in terms of quality and diversity metrics. Second, we compare the training time under various configurations to shed light on how to speed up the training process of motion diffusion models. Finally, we also conduct evaluation analysis on a large motion dataset. The results of our experiments indicate clear performance differences across motion representations in diverse datasets. Our results also demonstrate the impacts of distinct configurations on model training and suggest the importance and effectiveness of these decisions on the outcomes of motion diffusion models.
In recent years, Denoised Diffusion Probabilistic Model (DDPM) has been widely applied in human motion synthesis due to its ability to learn latent data distributions. Human motion synthesis can be mainly categorized into human motion prediction (Holden et al., 2017;Pavllo et al., 2018;Aksan et al., 2021;Guo et al., 2022b;Wang et al., 2023;Hou et al., 2023) and human motion generation (Chang et al., 2022;Shi et al., 2024;Tevet et al., 2022a;Zhang et al., 2024a;Chen et al., 2024;Guo et al., 2020;Karunratanakul et al., 2023;Zhang et al., 2024b). These methods have shown great promise in exploring animation styles and qualities through a controlled generative process.
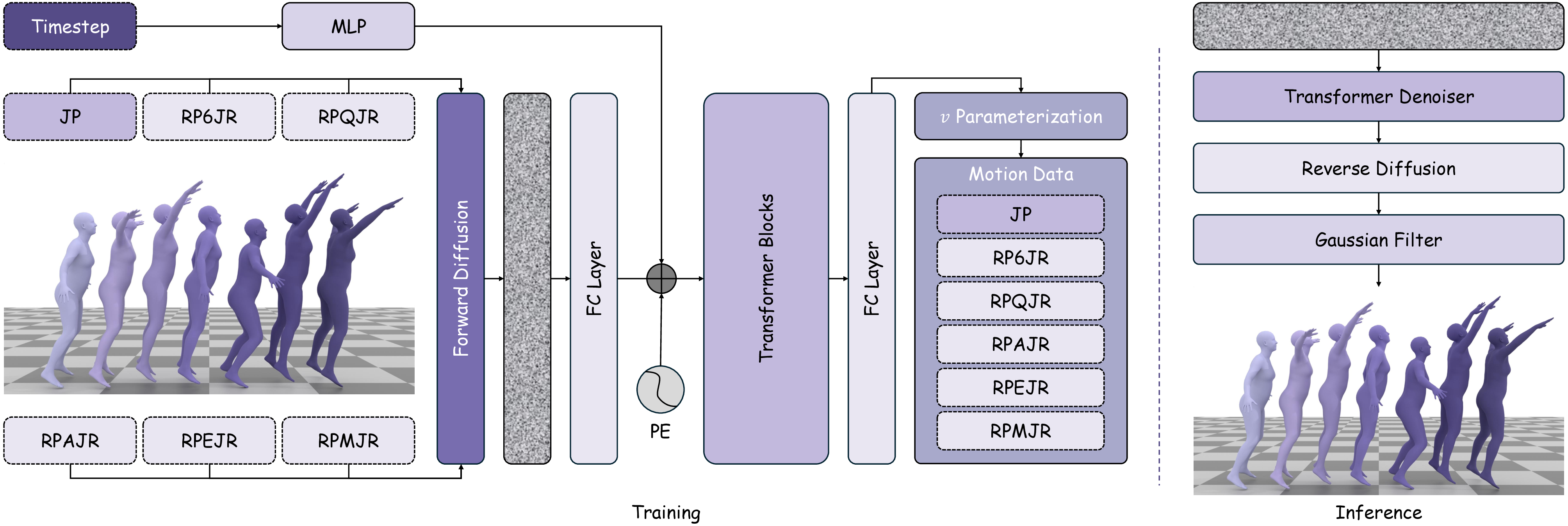
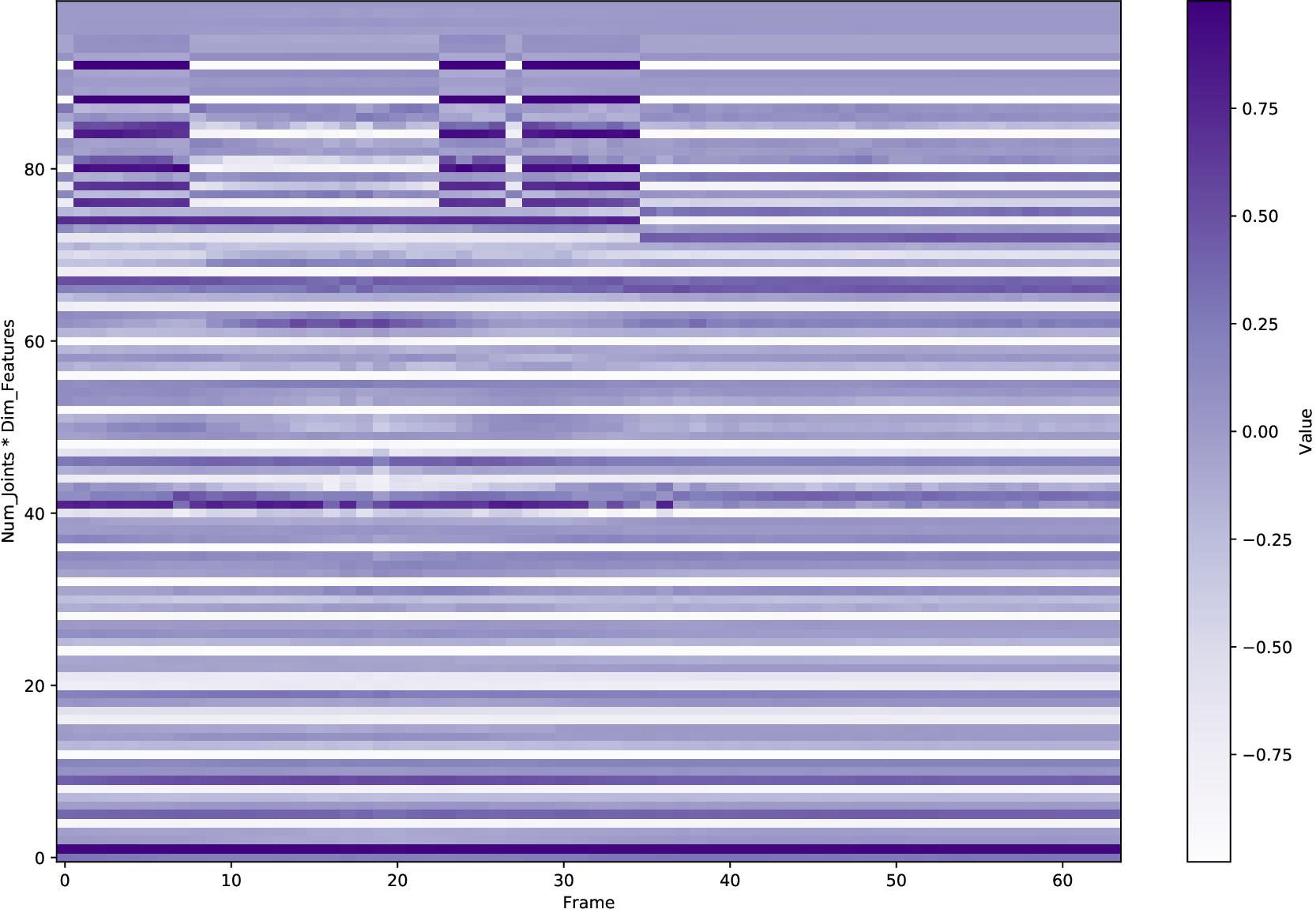
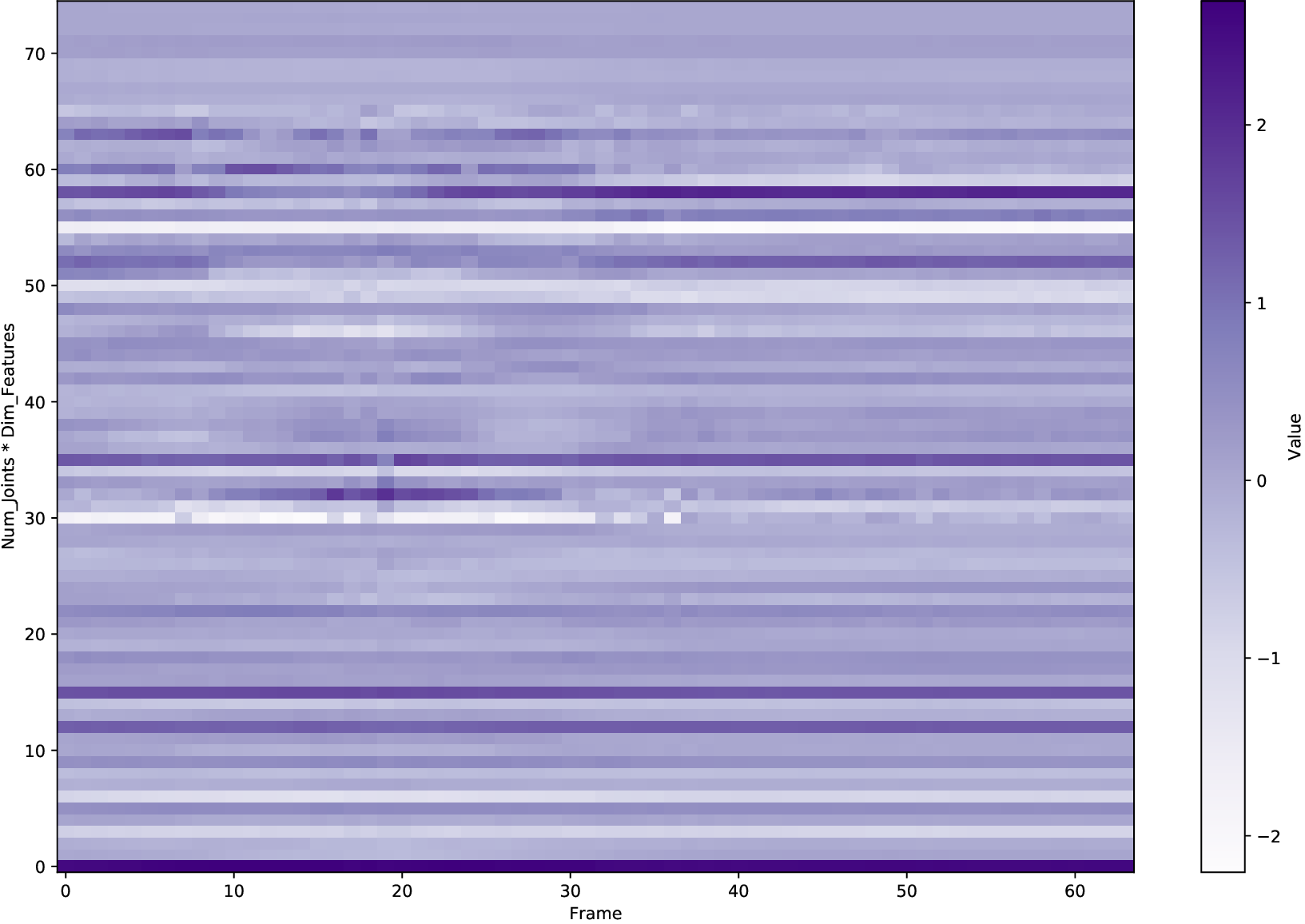
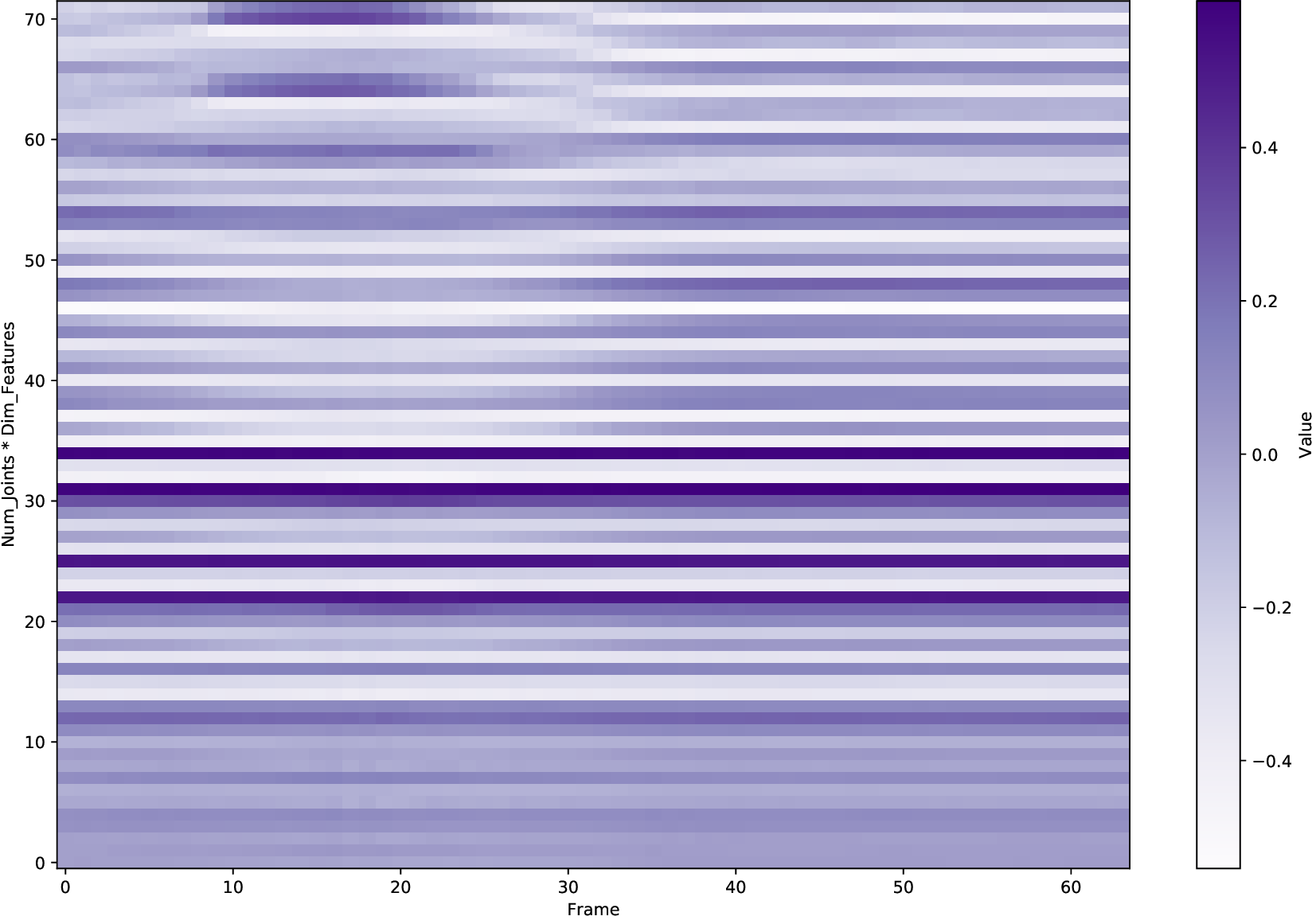
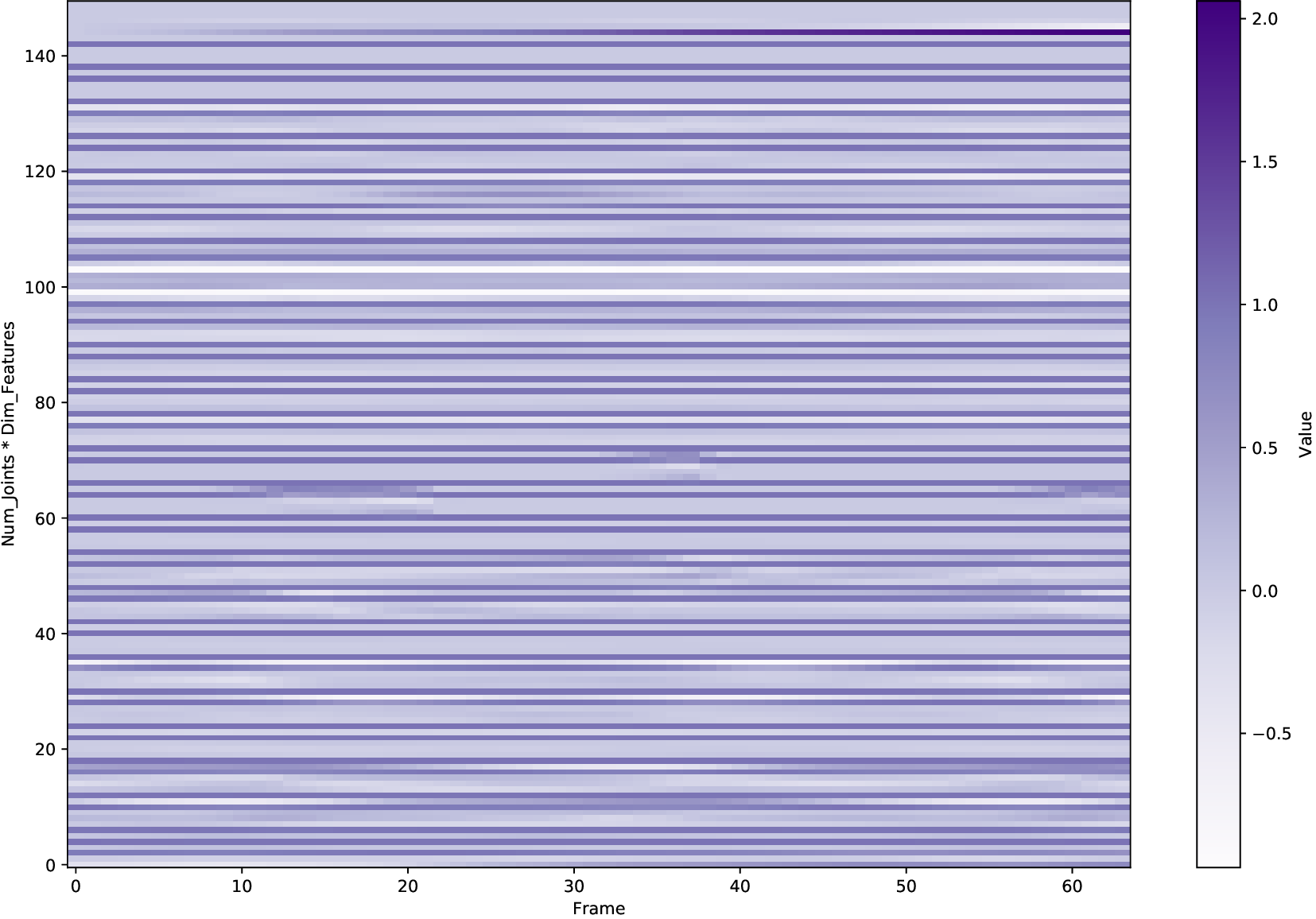
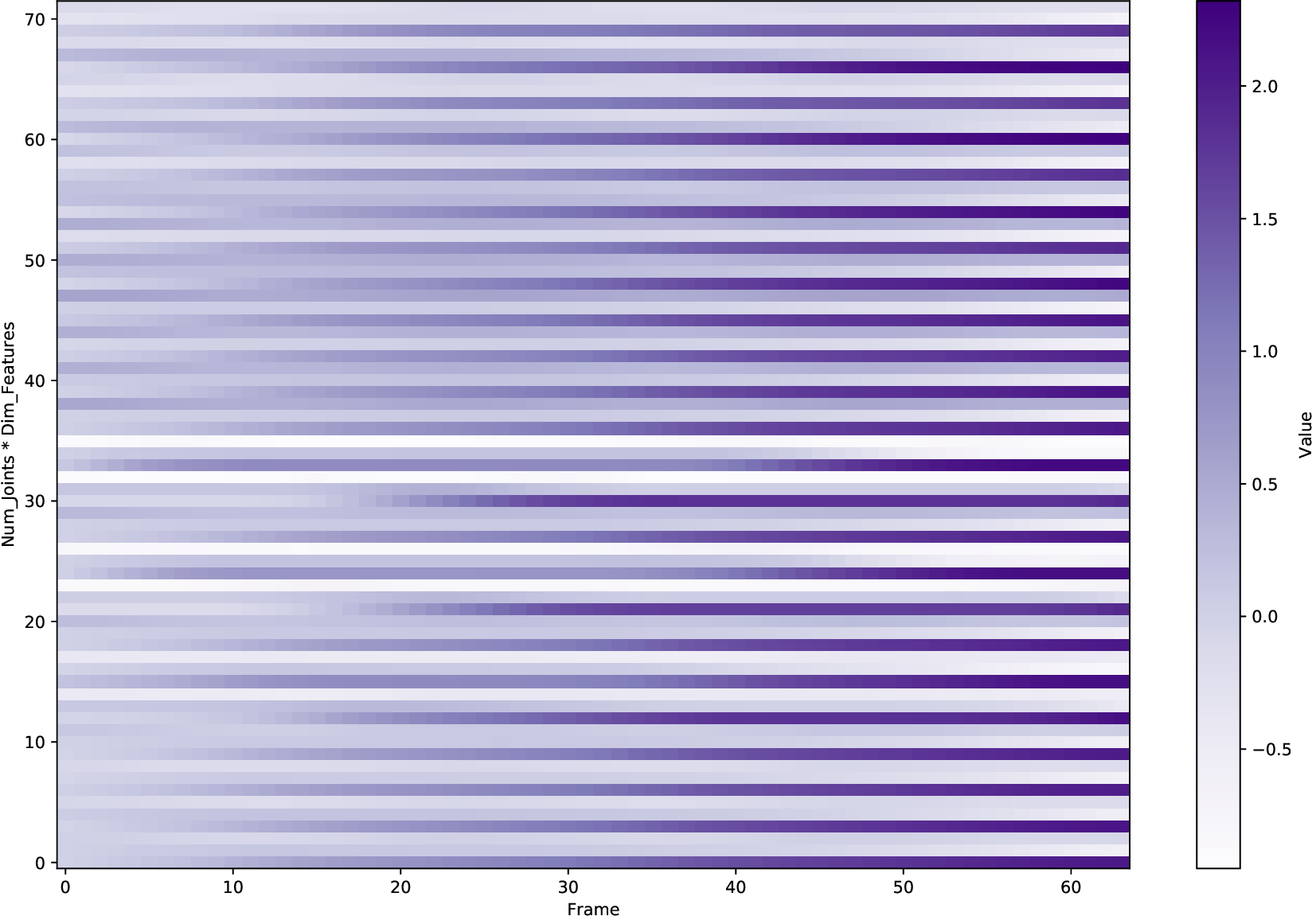
In human motion synthesis, the Motion Diffusion Model (MDM) is capable of denoising noisy samples to produce clean samples along the time steps iteratively based on a parameterized Markov chain trained using variational inference (Ho et al., 2020). Inspired by image generation, human motion sequences within fixed frames can be encoded as feature maps similar to image encoding. A motion sequence can be represented by continuous pose features per frame. A large amount of work uses conditional diffusion models to implement downstream tasks with user control. A conditional diffusion model conditions the diffusion model for specific tasks. At the heart of these steps is the representation of the motion itself. Going back to basics, investigating motion representations is crucial for determining the factors that affect the quality of human motion generation when using a diffusion model.
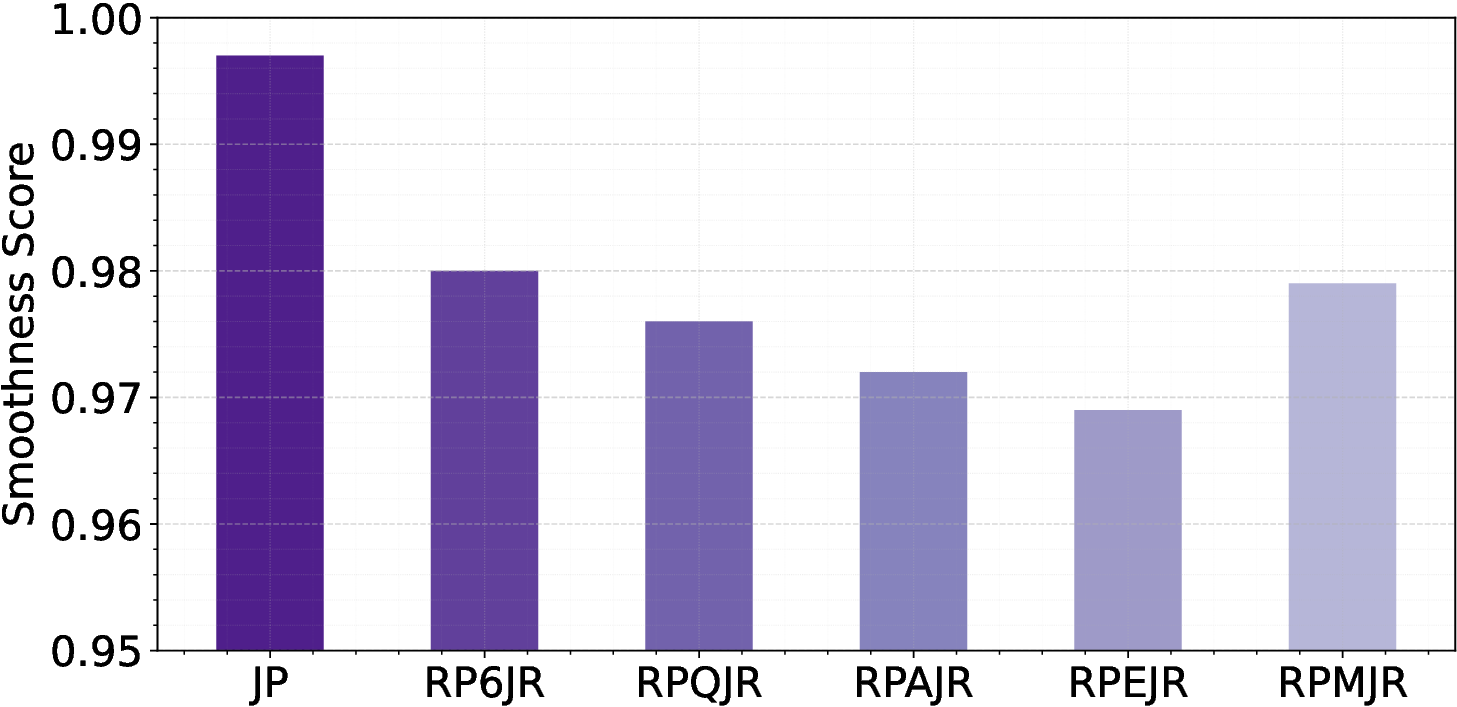
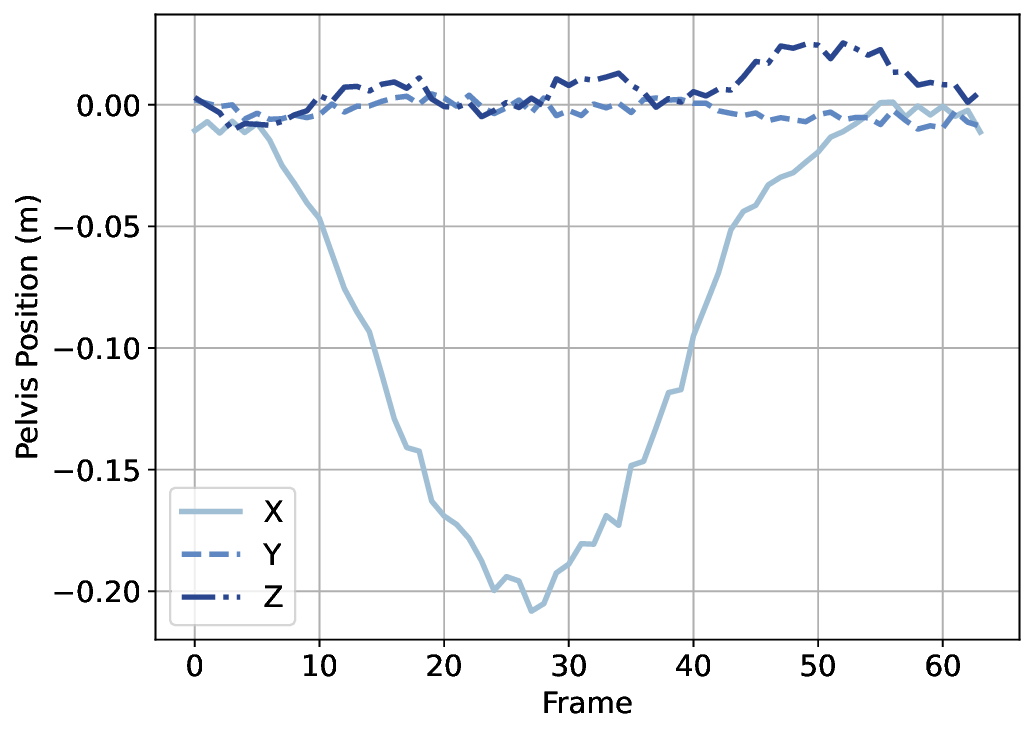
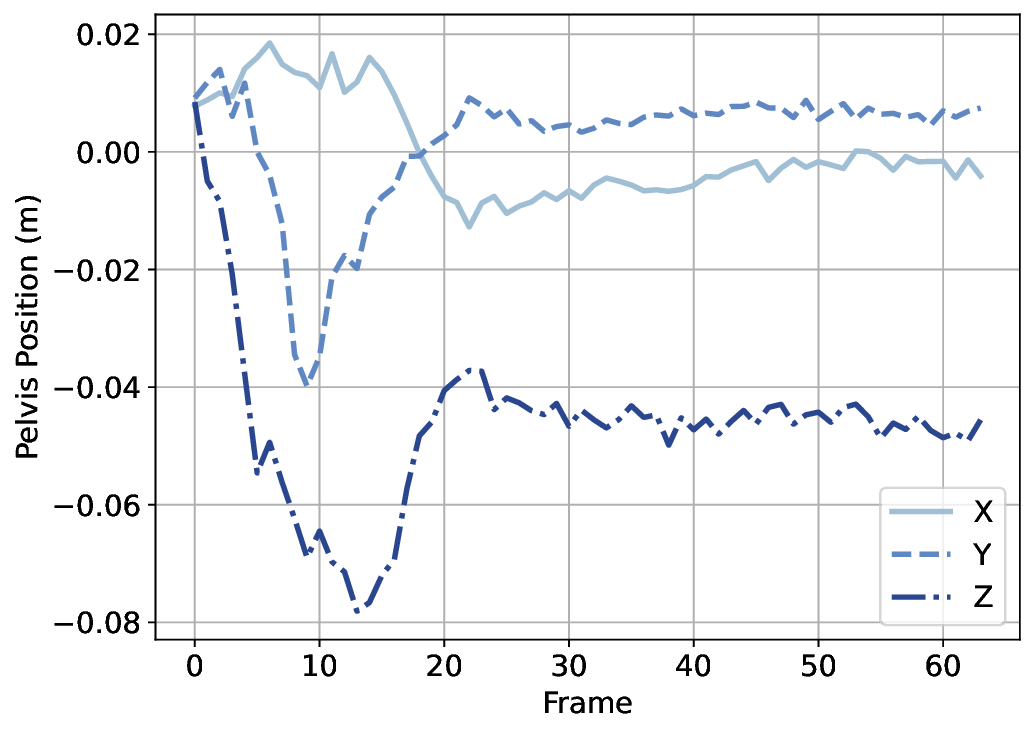
A variety of motion representations have been proposed in both motion prediction and motion generation to improve the quality of the synthesized motion sequences. Motion representation is com-monly some permutation of joint positions or joint rotations, and occasionally with some other features (Zhu et al., 2023). These representations often impact the construction of the underlying methodology and the quality of the outcomes. However, the use of a particular motion representation is not standardized. This leaves open a fundamental question: What kind of motion representation is more impactful in human motion generation when using a diffusion model? To answer this question, we investigate six motion representations from the literature: Joint positions (JP), Root Positions and 6D Joint Rotations (RP6JR), Root Positions and Quaternion Joint Rotations (RPQJR), Root Positions and Axis-angle Joint Rotations (RPAJR), Root Positions and Euler Joint Rotations (RPEJR), and Root Positions and Matrix Joint Rotations (RPMJR). We compare the human motion generation performances based on the above motion representations using our framework. The results indicate that the position-based motion representation (JP) outperforms in terms of diversity, fidelity, and training efficiency when training in MDM with v loss (vMDM). Compared to rotation-based motion representation (RP6JR, RPQJR, RPAJR, RPEJR, and RPMJR), the 3D coordinates of joints are more straightforward to capture and have great potential in various scenarios. However, continuous rotation representation is superior with regard to motion stability.
Our contributions are as follows: We first explore various motion representation training in vMDM and MDM, including position-based motion representation (JP) and rotation-based motion representation (RP6JR, RPQJR, RPAJR, RPEJR, and RPMJR) to assess whether they allow the motion diffusion model to learn the latent distribution of human motion more effectively. Second, we empirically study that the integration of the v loss function can trade off motion generation performance and training efficiency. Similar to SMooDi (Zhong et al., 2024), we retarget a large-scale motion dataset (100STYLE) to the SMPL skeleton to test the robustness of our framework. Third, we can generate seamless, natural human motion sequences efficiently using a diffusion model with a concise motion representation, based on two motion datasets (HumanAct12, 100STYLE, and Hu-manML3D) that cover limited and extensive motion ranges.
Human motion synthesis is still a challenging problem due to the complexity of human motion data. Human motion synthesis consists of human motion prediction and generation. Human motion prediction focuses on forecasting future motion sequences based on past motion sequences, considering the presence/absence of current environments. Human motion generation aims to generate realistic and seamless human motion sequences, enhancing utilities for real-world applications (Zhu et al., 2023). Whether in human motion prediction or generation, the motion representation is crucial in determining the quality of synthesized human motions in data-driven approaches. In the meantime, with the development of biped animation technology and the increasing popularity of generative models, considerable strides have been made in human motion diffusion models in recent years. Therefore, we analyze the vario
This content is AI-processed based on open access ArXiv data.