AdmTree: Compressing Lengthy Context with Adaptive Semantic Trees
Reading time: 5 minute
...
📝 Original Info
Title: AdmTree: Compressing Lengthy Context with Adaptive Semantic Trees
ArXiv ID: 2512.04550
Date: 2025-12-04
Authors: Yangning Li, Shaoshen Chen, Yinghui Li, Yankai Chen, Hai-Tao Zheng, Hui Wang, Wenhao Jiang, Philip S. Yu
📝 Abstract
The quadratic complexity of self-attention constrains Large Language Models (LLMs) in processing long contexts, a capability essential for many advanced applications. Context compression aims to alleviate this computational bottleneck while retaining critical semantic information. However, existing approaches often fall short: explicit methods may compromise local detail, whereas implicit methods can suffer from positional biases, information degradation, or an inability to capture long-range semantic dependencies. We propose AdmTree, a novel framework for adaptive, hierarchical context compression with a central focus on preserving high semantic fidelity while maintaining efficiency. AdmTree dynamically segments input based on information density, utilizing gist tokens to summarize variable-length segments as the leaves of a semantic binary tree. This structure, together with a lightweight aggregation mechanism and a frozen backbone LLM (thereby minimizing new trainable parameters), enables efficient hierarchical abstraction of the context. By preserving fine-grained details alongside global semantic coherence, mitigating positional bias, and dynamically adapting to content, AdmTree robustly retains the semantic information of long contexts.
💡 Deep Analysis
📄 Full Content
AdmTree: Compressing Lengthy Context with
Adaptive Semantic Trees
Yangning Li1,2∗, Shaoshen Chen1∗, Yinghui Li1‡, Yankai Chen3,
Hai-Tao Zheng1,2‡, Hui Wang2, Wenhao Jiang4‡, Philip S. Yu3
1Shenzhen International Graduate School, Tsinghua University
2Peng Cheng Laboratory
3University of Illinois Chicago
4Guangdong Laboratory of Artificial Intelligence and Digital Economy (SZ)
Abstract
The quadratic complexity of self-attention constrains Large Language Models
(LLMs) in processing long contexts—a capability essential for many advanced
applications. Context compression aims to alleviate this computational bottleneck
while retaining critical semantic information. However, existing approaches often
fall short: explicit methods may compromise local detail, whereas implicit methods
can suffer from positional biases, information degradation, or an inability to capture
long-range semantic dependencies. We propose AdmTree, a novel framework for
adaptive, hierarchical context compression with a central focus on preserving high
semantic fidelity while maintaining efficiency. AdmTree dynamically segments
input based on information density, utilizing gist tokens to summarize variable-
length segments as the leaves of a semantic binary tree. This structure, together
with a lightweight aggregation mechanism and a frozen backbone LLM (thereby
minimizing new trainable parameters), enables efficient hierarchical abstraction of
the context. By preserving fine-grained details alongside global semantic coherence,
mitigating positional bias, and dynamically adapting to content, AdmTree robustly
retains the semantic information of long contexts.
1
Introduction
Large Language Models (LLMs) [2, 3, 37, 38, 46, 50, 68, 75] have demonstrated remarkable profi-
ciency in processing and understanding long contexts [9, 10, 59, 60], enabling advances in retrieval-
augmented generation [47, 61, 78] and agentic system [39, 77], etc. However, handling long contexts
remains computationally intensive due to the quadratic complexity of self-attention with input token
length. This leads to high memory consumption and inference latency. Consequently, context com-
pression has emerged as a critical technique, aiming to reduce input token length while preserving
maximal semantic integrity.
Despite promising results, most existing methods fail to simultaneously preserve information
across multiple semantic dimensions, such as global versus local semantics, or information across
positions. This inability in preserving different information dimensions may leads to poor general-
ization across real-world tasks, which demand distinct types of semantic information. Specifically,
existing methods can be divided into two main categories. Explicit methods [30, 79, 82] directly
shorten text by removing content deemed less essential for overall understanding. Although these
methods effectively capture global meaning, they often disrupt local coherence due to excessive
omission, leading to the loss of fine-grained details. In contrast, implicit methods [18, 23, 42, 62]
encode long contexts into compact latent vectors (also called “gist tokens”) in a flat manner. These
methods achieve higher compression ratios, but exhibit different compression efficiency to context at
∗Equal Contribution. ‡: Corresponding Author. This work was primarily conducted at GML under the
leadership of Wenhao.
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2512.04550v1 [cs.CL] 4 Dec 2025
12
14
16
18
20
22
Beginning
Middle
End
Beginning
Middle
End
LongLLMLingua
SnapKV
Beacon
AdmTree (Ours)
Book Level
Chapter Level
Paragraph Level
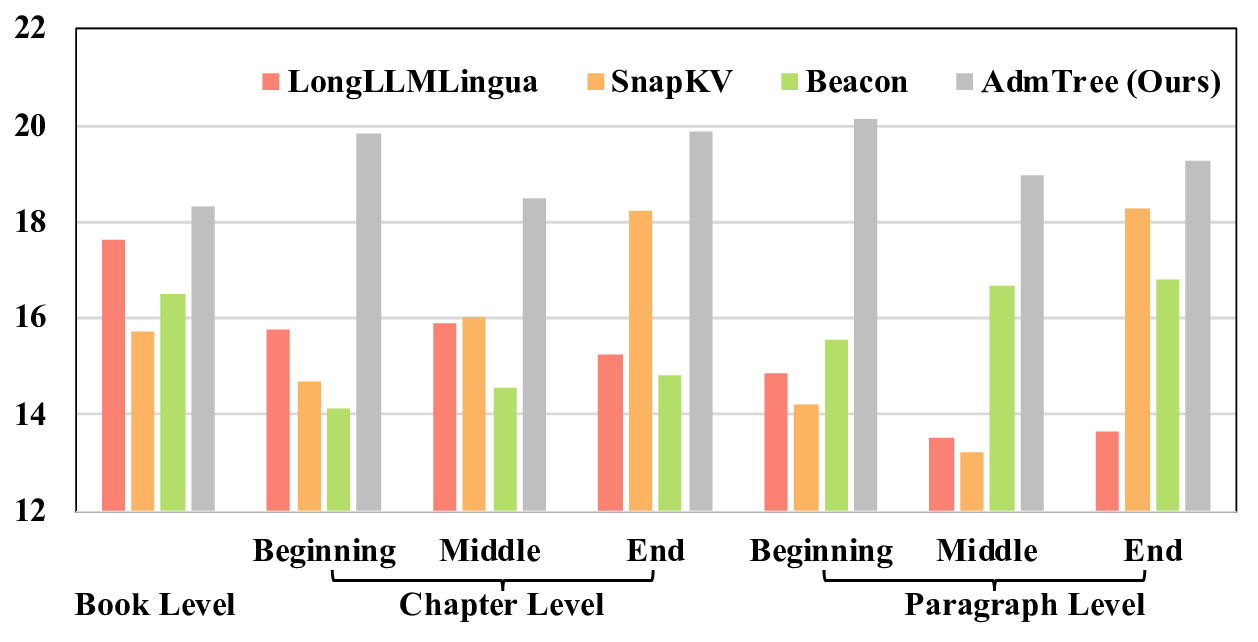
(a) Multi-Granularity Summarization. Implicit methods tend
to prioritize the preservation of global information.
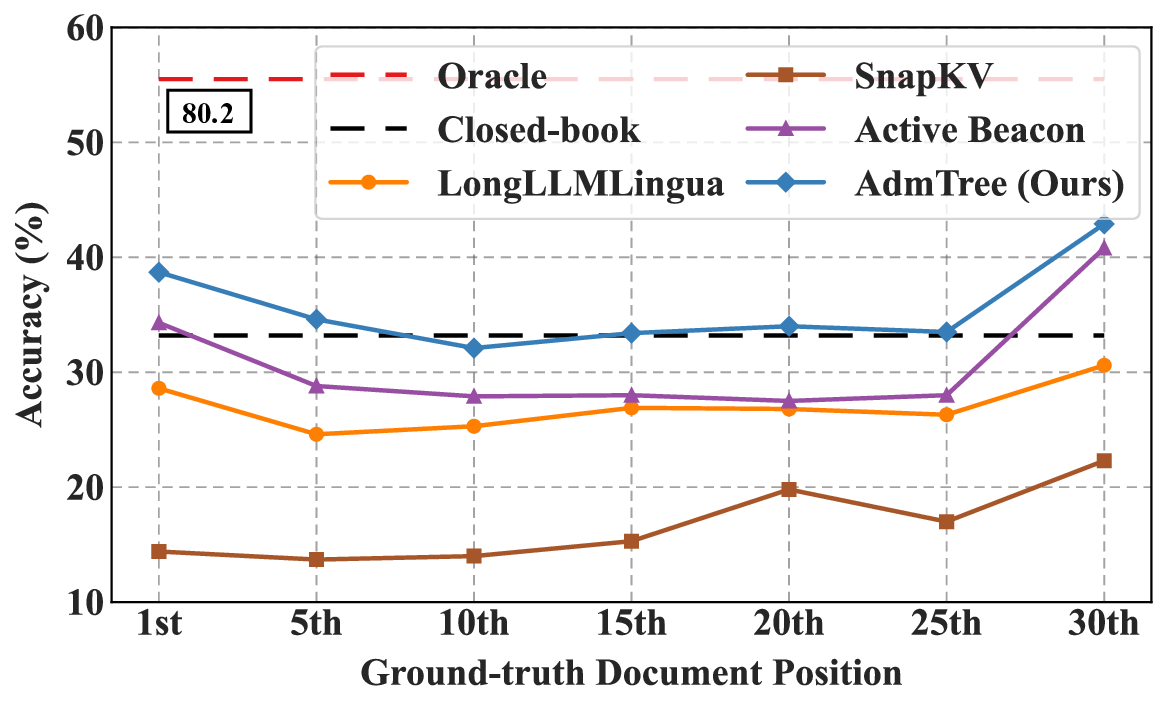
80.2
(b) Multi-Document Question Answering. Explicit
methods exhibit varying compression effectiveness
across content at different positions.
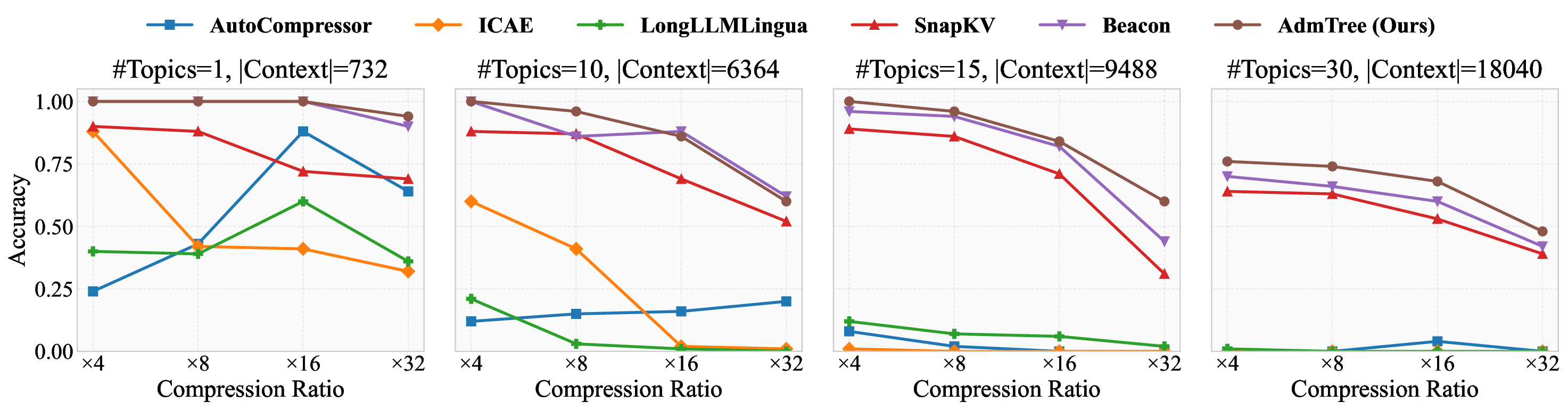
Figure 1: Pre-experiments demonstrate that existing methods struggle to balance semantic information
of different dimensions for different types of tasks.
distinct positions. As evidenced by [7, 27, 57], implicit compression methods are prone to positional
bias, often overlooking information from the earlier or middle parts of the context. In other words,
less salient information is easily overshadowed by more prominent content.
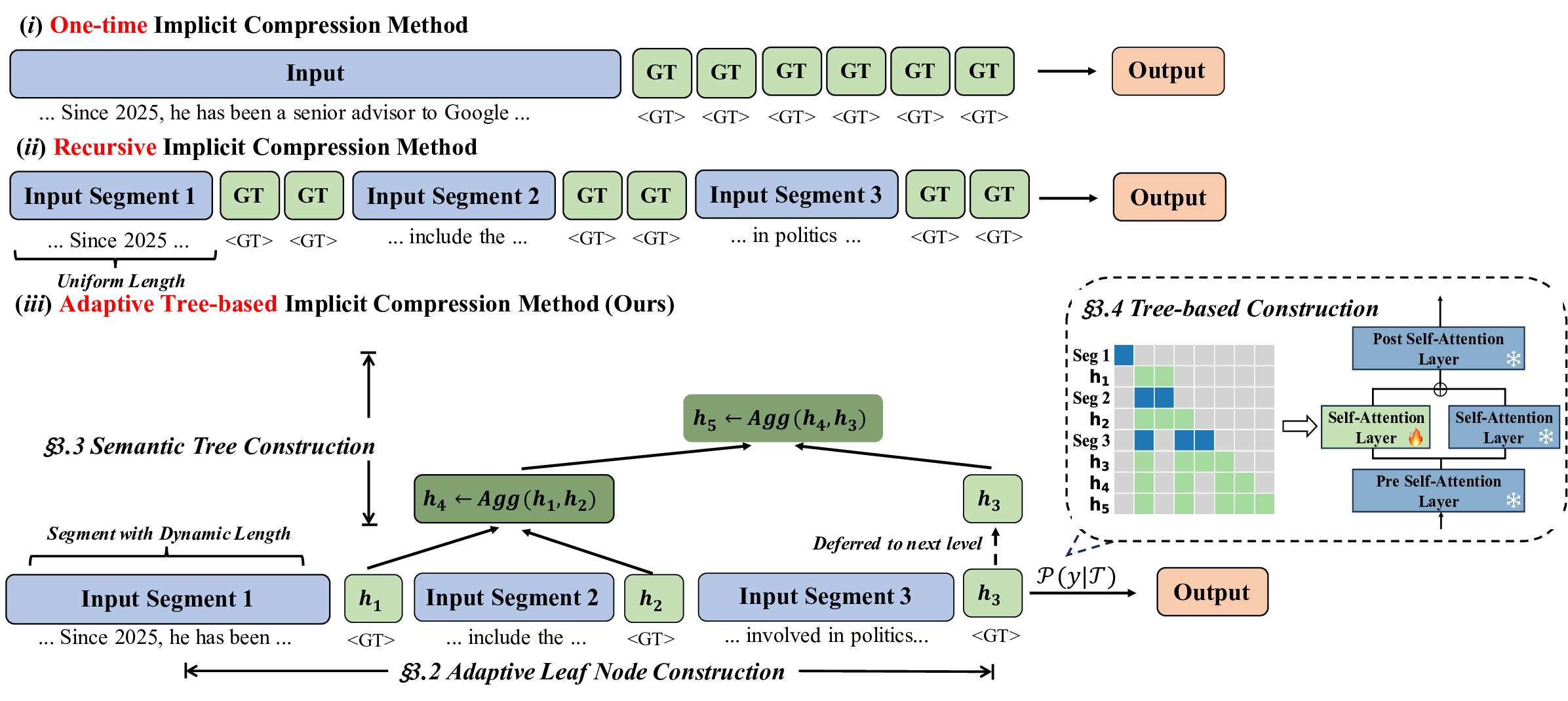
To mitigate semantic loss caused by position bias, some implicit methods also explored recursive
compression [14, 24, 83]. These methods progressively condense segmented contexts into serialized
gist tokens. However, they often rely on fixed-size segments without considering variations in
information density, leading to imbalanced compression loads across different input regions. More-
over, such linear manner still causes semantic information to degrade progressively during recursive
compression, making it difficult to capture long-range dependencies and maintain global coherence.
To overcome these limitations, we draw inspiration from cognitive science,