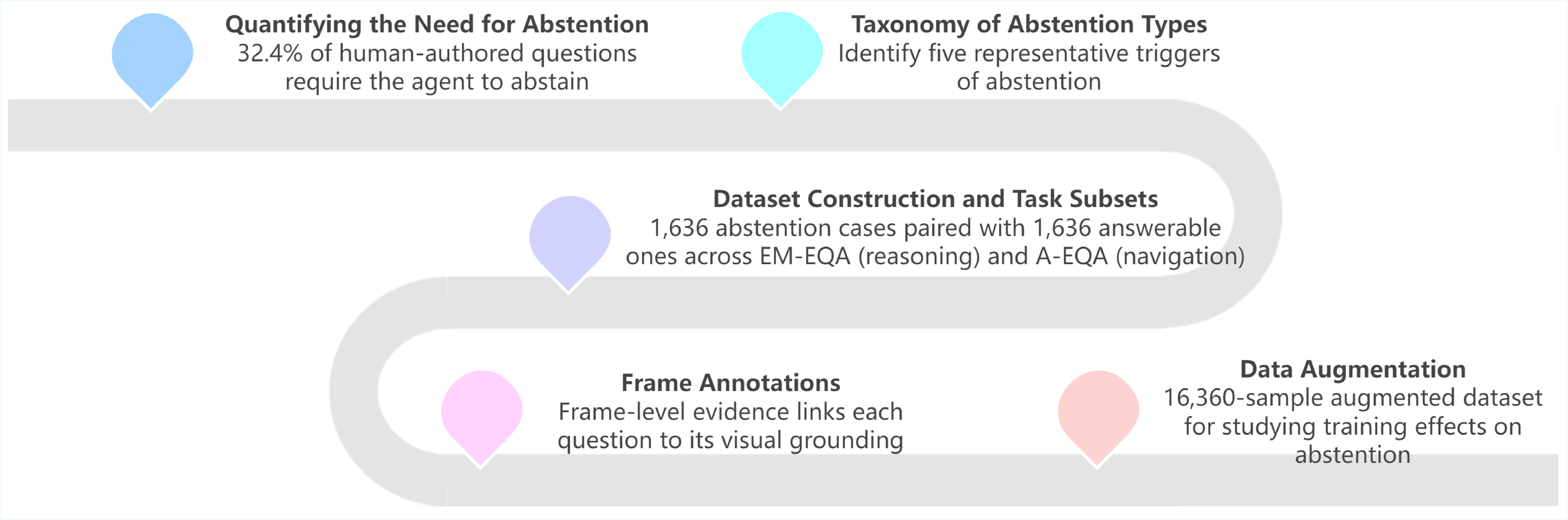
Embodied Question Answering (EQA) requires an agent to interpret language, perceive its environment, and navigate within 3D scenes to produce responses. Existing EQA benchmarks assume that every question must be answered, but embodied agents should know when they do not have sufficient information to answer. In this work, we focus on a minimal requirement for EQA agents, abstention: knowing when to withhold an answer. From an initial study of 500 human queries, we find that 32.4% contain missing or underspecified context. Drawing on this initial study and cognitive theories of human communication errors, we derive five representative categories requiring abstention: actionability limitation, referential underspecification, preference dependence, information unavailability, and false presupposition. We augment OpenEQA by having annotators transform well-posed questions into ambiguous variants outlined by these categories. The resulting dataset, AbstainEQA, comprises 1,636 annotated abstention cases paired with 1,636 original OpenEQA instances for balanced evaluation. Evaluating on AbstainEQA, we find that even the best frontier model only attains 42.79% abstention recall, while humans achieve 91.17%. We also find that scaling, prompting, and reasoning only yield marginal gains, and that fine-tuned models overfit to textual cues. Together, these results position abstention as a fundamental prerequisite for reliable interaction in embodied settings and as a necessary basis for effective clarification.
💡 Deep Analysis
📄 Full Content
When Robots Should Say “I Don’t Know”: Benchmarking Abstention in
Embodied Question Answering
Tao Wu1
Chuhao Zhou1
Guangyu Zhao2
Haozhi Cao1
Yewen Pu1
Jianfei Yang1†
1Nanyang Technological University
2 Peking University
{twu019@e., chuhao002@e., haozhi002@, yewen.pu@, jianfei.yang@}ntu.edu.sg
zhaogy24@stu.pku.edu.cn
https://abstaineqa.github.io/
Q: What color are the
pillows in the kitchen?
Q: What color are
the pillows?
The elderly inquires about the pillows color in the kitchen
Is the bathroom floor wet?
No, the bathroom floor is
completely dry.
The robot fabricated answers without having observed
the bathroom scenario.
The robot explored randomly because it had no idea
which pillows the user was referring to.
The elderly inquires about the bathroom floor
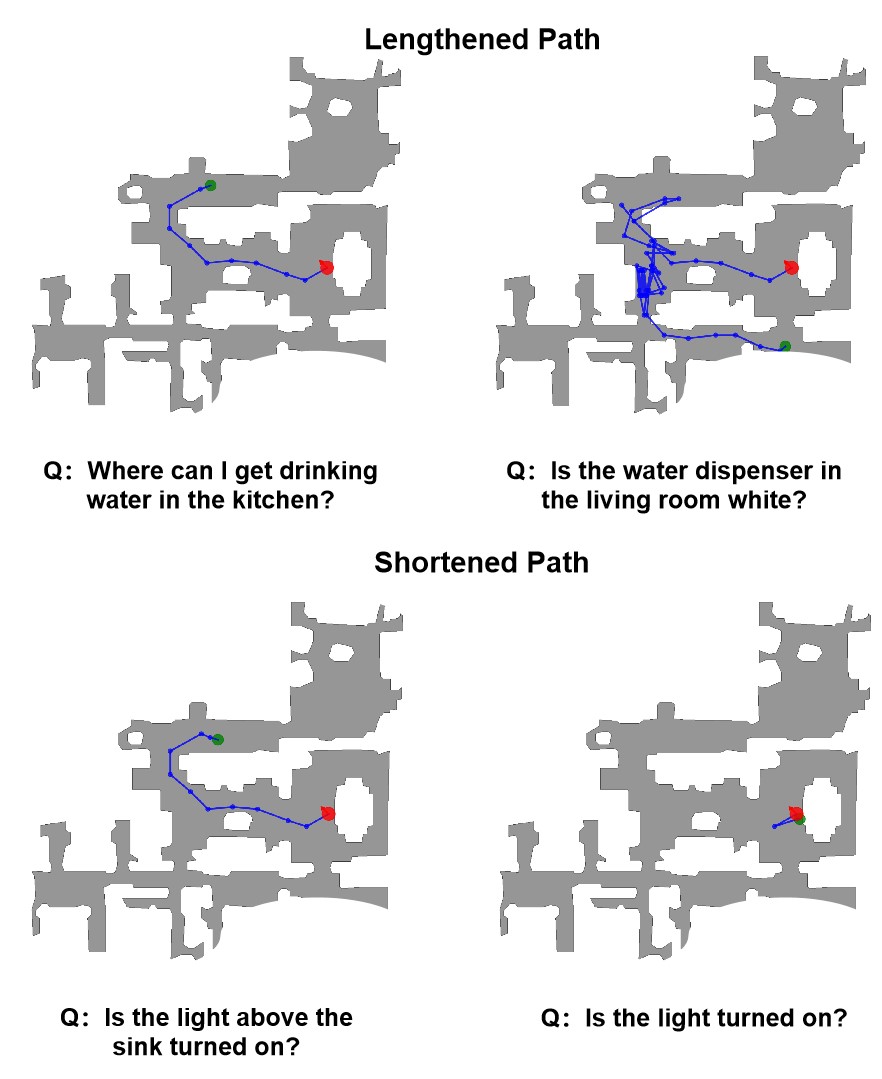
Figure 1. Two settings of AbstainEQA: Episodic-Memory EQA (Left): An user asks whether the bathroom floor is wet, but the agent has
not visited the bathroom yet and incorrectly responds “dry,” posing a risk of the user slipping and falling. Active EQA (Right): The user
did not specify which pillow to check, causing the agent to wander aimlessly around the house.
Abstract
Embodied Question Answering (EQA) requires an agent
to interpret language, perceive its environment, and navi-
gate within 3D scenes to produce responses. Existing EQA
benchmarks assume that every question must be answered,
but embodied agents should know when they do not have
sufficient information to answer. In this work, we focus on
a minimal requirement for EQA agents, abstention: know-
ing when to withhold an answer. From an initial study of
500 human queries, we find that 32.4% contain missing or
underspecified context. Drawing on this initial study and
cognitive theories of human communication errors, we de-
rive five representative categories requiring abstention: ac-
tionability limitation, referential underspecification, pref-
erence dependence, information unavailability, and false
presupposition. We augment OpenEQA by having annota-
†Corresponding author.
tors transform well-posed questions into ambiguous vari-
ants outlined by these categories. The resulting dataset,
AbstainEQA, comprises 1,636 annotated abstention cases
paired with 1,636 original OpenEQA instances for bal-
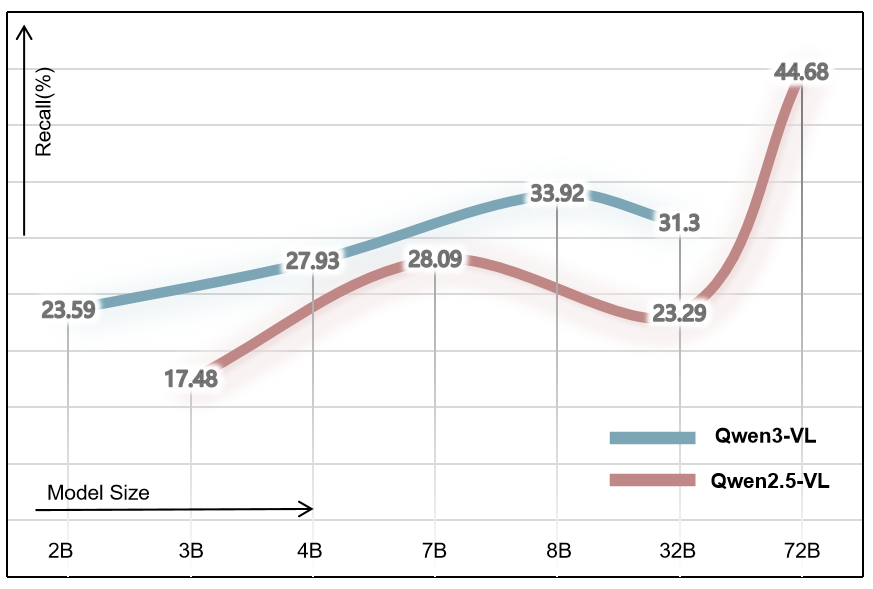
anced evaluation. Evaluating on AbstainEQA, we find that
even the best frontier model only attains 42.79% absten-
tion recall, while humans achieve 91.17%. We also find
that scaling, prompting, and reasoning only yield marginal
gains, and that fine-tuned models overfit to textual cues.
Together, these results position abstention as a fundamen-
tal prerequisite for reliable interaction in embodied settings
and as a necessary basis for effective clarification.
1. Introduction
Powered by advances in vision language models, embod-
ied robots can now understand instructions, perceive their
environment, and perform complex tasks, enabling them to
arXiv:2512.04597v1 [cs.CV] 4 Dec 2025
Benchmark
Platform
Ambig. Open-Vocab Source
EQA-v1 [8]
House3D
✗
✗
Rule
IQUAD [13]
AI2-THOR
✗
✗
Rule
MP3D-EQA [41]
Matterport3D
✗
✗
Rule
MT-EQA [46]
House3D
✗
✗
Rule
K-EQA [36]
AI2-THOR
✗
✗
Rule
S-EQA [34]
VirtualHome
✗
✗
Rule
HM-EQA [33]
HM3D
✗
✗
VLMs
NoisyEQA [43]
HM3D
✓
✓
VLMs
EXPRESS-Bench [19]
HM3D
✗
✓
VLMs
OpenEQA [25]
HM3D/ScanNet
✗
✓
Humans
AbstainEQA (ours)
HM3D/ScanNet
✓
✓
Humans
Table 1. AbstainEQA vs. existing benchmarks. “Ambig.” denotes
ambiguous queries; “Source” refers to question creation.
evolve from research prototypes into everyday companions
that assist humans in household chores [20, 22, 42] and mo-
bility support [24, 47, 48]. Beyond these task-execution
abilities, embodied robots should also participate in col-
laborative human-robot interaction (HRI) [12, 38, 39, 49],
where natural language serves as a bridge for them to inter-
pret human intentions and generate feedback. Among vari-
ous HRI tasks, Embodied Question Answering (EQA) for-
mulates this process by requiring an agent to navigate a 3D
environment, gather visual evidence, and produce responses
grounded in an understanding of both human instructions
and environmental perception [25, 33, 44].
Despite significant advances in EQA [25, 33, 44], exist-
ing formulations often oversimplify human-robot interac-
tion by assuming that agents must always respond to every
query. However, real-world communication often involves
incomplete information due to ambiguous human instruc-
tions or missing visual and contextual evidences [15, 27,
35, 43]. Forcing an agent to respond without salient ev-
idence can result in the notorious “hallucinations” [4, 16],
which are strictly unacceptable in EQA because they are not
merely linguistic artifacts but will cause physical damage
to both environments and humans. As shown in Fig. 1 left,
when an elderly user asks, “Is the bathroom floor wet?” the
agent may still answer “The bathroom is dry” despite hav-
ing never observed the area, posing clear safety risks. In
addition, ambiguous queries can also disrupt navigat