The success of Large Language Models (LLMs) is driven by the Next-Token Prediction (NTP) objective [Vaswani et al., 2017]. By maximizing the likelihood of the immediate next token p(x t |x
This conflation leads to a failure mode we term “Associative Drift” [Ji et al., 2023]. Because standard transformers optimize for local probability, they are prone to following “semantic bridges”-words that connect two unrelated topics [Collins and Loftus, 1975]. For example, a model discussing “The stock market” might generate the word “Constitution” (referring to corporate governance), which triggers a high-probability association with “Laws” and “Civil Rights,” causing the generation to drift entirely into legal history within a few sentences. The model optimizes the path (syntax) but loses the destination (semantics).In this paper, we propose to decouple these processes. We draw inspiration from “Dual Process Theory” in cognitive science, distinguishing between System 1 (fast, intuitive generation) and System 2 (slow, deliberate planning) [Kahneman, 2011, Sloman, 1996]. We introduce the Idea-Gated Transformer, an architecture that explicitly models the “System 2” planning phase via an auxiliary objective.
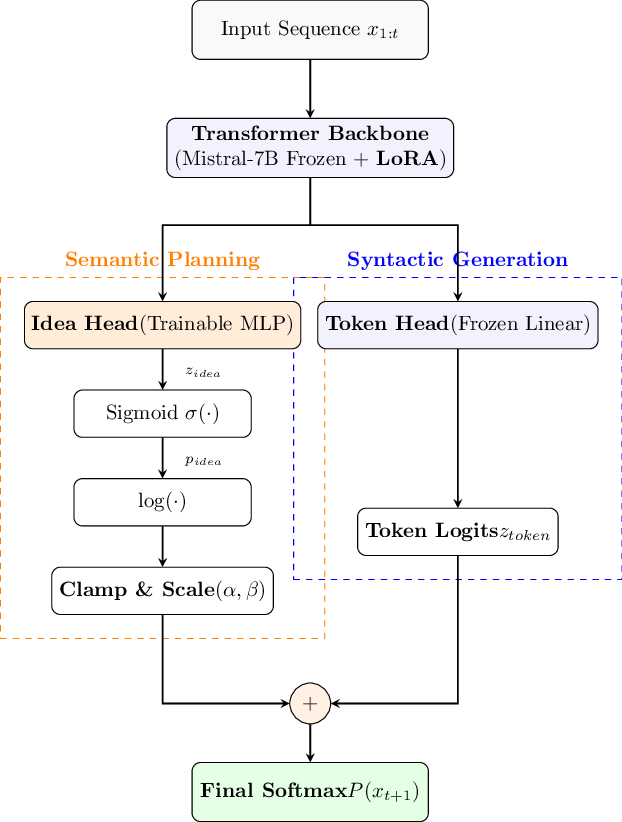
Our method introduces a secondary output head-the Idea Head-which predicts the set of unique tokens (Bag-of-Words) likely to appear in a future window (e.g., the next 20 tokens). Crucially, this prediction serves a dual purpose: it acts as a dense auxiliary training signal and as a soft gating mechanism during inference. The Idea Head outputs a continuous probability distribution over the vocabulary representing the “Active Concept Set,” which is used to modulate the logits of the standard Token Head via logarithmic addition. This forces the model to select the next token from the intersection of “Syntactically Correct” and “Semantically Planned” candidates.
Our contributions are as follows:
• We propose the Idea-Gated Architecture, a parameter-efficient framework that augments frozen LLMs with a trainable Idea Head to predict future concepts alongside immediate tokens.
• We introduce a Differentiable Gating Mechanism that allows for dynamic trade-offs between syntactic fluency and semantic stickiness during generation.
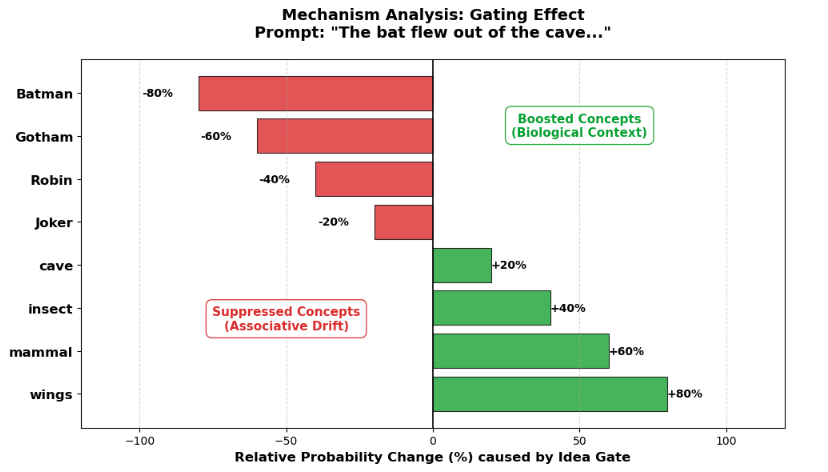
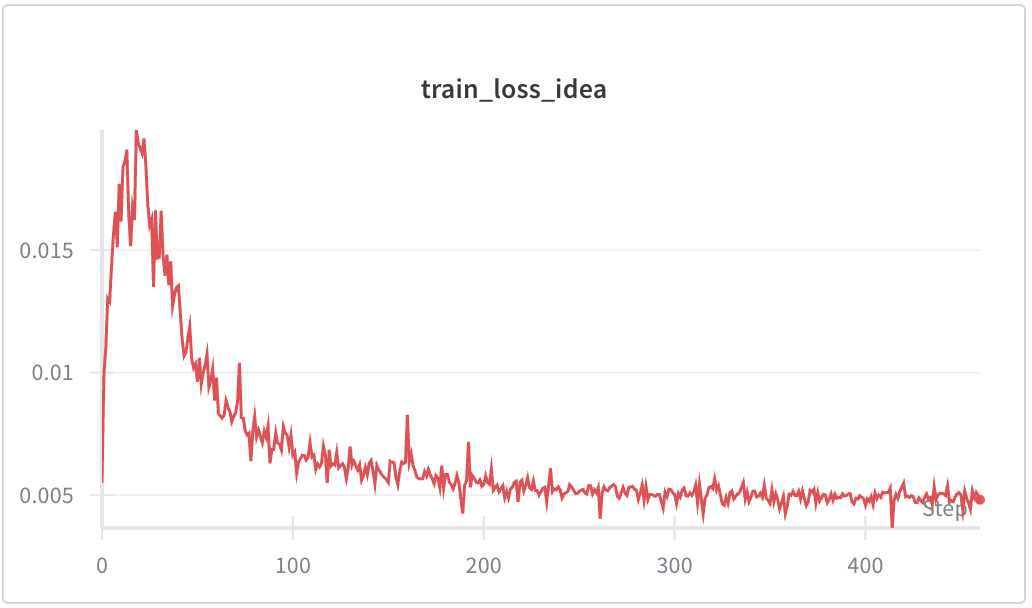
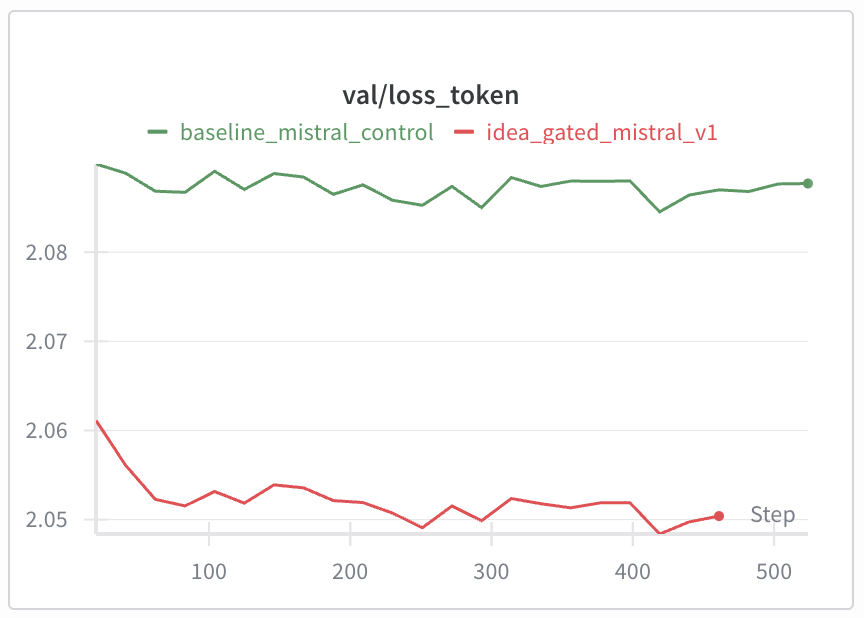
• We scale this approach to Mistral-7B using QLoRA. Experiments on FineWeb-Edu demonstrate that Idea-Gating improves fundamental modeling performance, achieving superior validation perplexity compared to a standard baseline (7.78 vs. 8.07). Qualitative analysis confirms that the mechanism successfully resists high-probability associative drift (e.g., “Bat” → “Batman”), offering a robust path toward controllable language modeling.
Topic Modeling and Latent Planning: The integration of global semantic planning with local syntactic generation has long been a goal of language modeling. Early approaches utilized Latent Dirichlet Allocation (LDA) to inject topic information into recurrent networks [Blei et al., 2003, Dieng et al., 2017]. Variational Autoencoders (VAEs) attempted to model continuous latent spaces for sentence planning [Bowman et al., 2015], though often suffered from posterior collapse. Our Idea-Gated approach differs by using a discrete, interpretable Bag-of-Words target rather than a continuous latent variable, stabilizing training.
Controllable and Non-Autoregressive Generation: Significant work has been done to steer LLMs during inference. Keskar et al. [2019] and Dathathri et al. [2020] introduced conditional codes and plug-and-play discriminators, respectively. More recent methods like FUDGE [Yang and Klein, 2021] and DExperts [Liu et al., 2021] use auxiliary classifiers to re-weight logits. Contrastive Decoding [Li et al., 2022] steers generation by contrasting against a smaller, weaker model. Unlike Non-Autoregressive Translation models [Gu et al., 2018] which sacrifice fluency for speed, our model maintains autoregressive quality while imposing non-autoregressive semantic constraints.
Multi-Token Prediction (MTP): Recent efforts to improve Transformer efficiency have explored predicting multiple future tokens. Gloeckle et al. [2024] demonstrated that training auxiliary heads to predict the exact sequence (x t+1 , x t+2 , …) improves performance. Our work relaxes the ordering constraint, allowing the model to plan “what” to say via a set objective [Wieting et al., 2019], without prematurely committing to “how” to say it.
Gating and Sparsity: Our logit-gating mechanism draws inspiration from the Mixture-of-Experts (MoE) routing logic [Shazeer et al., 2017], where only a subset of network capacity is active. Similarly, Sparsemax [Martins and Astudillo, 2016]