Title: State Space Models for Bioacoustics: A comparative Evaluation with Transformers
ArXiv ID: 2512.03563
Date: 2025-12-03
Authors: Chengyu Tang, Sanjeev Baskiyar
📝 Abstract
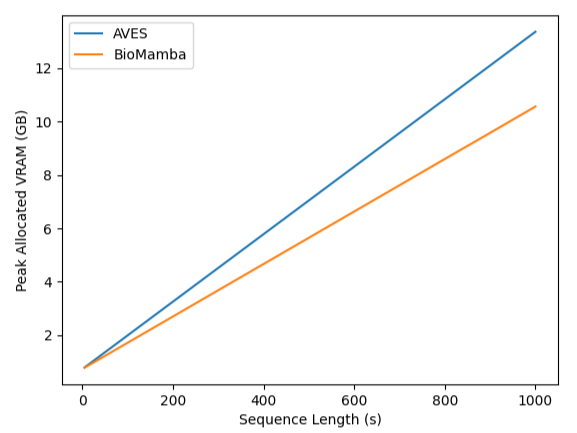
In this study, we evaluate the efficacy of the Mamba model in the field of bioacoustics. We first pretrain a Mamba-based audio large language model (LLM) on a large corpus of audio data using self-supervised learning. We fine-tune and evaluate BioMamba on the BEANS benchmark, a collection of diverse bioacoustic tasks including classification and detection, and compare its performance and efficiency with multiple baseline models, including AVES, a state-of-the-art Transformer-based model. The results show that BioMamba achieves comparable performance with AVES while consumption significantly less VRAM, demonstrating its potential in this domain.
💡 Deep Analysis
📄 Full Content
State Space Models for Bioacoustics: A comparative
Evaluation with Transformers
Chengyu Tang∗
Auburn University
Auburn, AL 36849
tangcy@auburn.edu
Sanjeev Baskiyar
Auburn University
Auburn, AL 36849
baskisa@auburn.edu
Abstract
In this study, we evaluate the efficacy of the Mamba model in the field of bioacous-
tics. We first pretrain a Mamba-based audio large language model (LLM) on a large
corpus of audio data using self-supervised learning. We fine-tune and evaluate
BioMamba on the BEANS benchmark, a collection of diverse bioacoustic tasks
including classification and detection, and compare its performance and efficiency
with multiple baseline models, including AVES, a state-of-the-art Transformer-
based model. The results show that BioMamba achieves comparable performance
with AVES while consumption significantly less VRAM, demonstrating its poten-
tial in this domain.
1
Motivation
In recent decades, deep learning has emerged as a powerful methodology, finding widespread
applications across diverse domains and data modalities. Typically, deep learning models are
trained using large amounts of annotated data. However, acquiring high-quality annotated data
remains challenging, particularly due to the extensive resources and human effort required for
labeling. Transformer-based models, such as BERT [8], ViT [9], have achieved remarkable progress
through self-supervised pre-training. Nevertheless, Transformer models inherently possess quadratic
computational complexity due to the self-attention mechanism
In bioacoustics, labeled data is particularly limited. Bioacoustic data poses unique challenges, includ-
ing the need for computationally efficient models capable of handling long-term audio sequences
effectively. While some studies, such as AVES [13], have begun to address bioacoustic modeling,
the high computational demands of traditional Transformer models significantly limit their practical
utility in real-world bioacoustic scenarios. Although there have been various attempts to lower the
complexity of self-attention and increase its efficiency, such as the Reformer [20], Linformer [28], and
Flash Attention [6], they still do not fully overcome the fundamental efficiency limitations inherent to
self-attention mechanisms.
One of the latest attempts is the Mamba model [12], which is based on the State Space Model
(SSM). Mamba is able to achieve Transformer-level performance in various domains, including audio
representation learning [27, 18, 22] while significantly improving computational efficiency with its
linear complexity. Preliminary studies are exploring Mamba for bioacoustic applications that have
shown encouraging signs in bioacoustics [24], but they remain limited and small-scale.
Motivated by these observations and gaps, this study investigates the effectiveness of a Mamba-
based model for bioacoustic tasks. We trained a Mamba-based model, BioMamba, using self-
supervised learning for animal sound modeling and evaluated it on a comprehensive bioacoustic
benchmark, including animal sound classification and detection. We compared its performance with
∗Corresponding author.
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2512.03563v1 [cs.SD] 3 Dec 2025
multiple baseline models, from traditional machine learning models to a state-of-the-art Transformer-
based model. To our best knowledge, BioMamba is the first Mamba-based model trained on large-
scale audio datasets and comprehensively evaluated across multiple bioacoustic tasks. The results
demonstrate that the Mamba-based model can achieve comparable performance to a Transformer-
based model while consuming significantly less memory, which implies its potential in advancing
bioacoustic research and real-world environmental monitoring applications.
2
Related work
2.1
Transformer-based audio representation models
Recent years have seen a surge of transformer-based models for audio representation learning, inspired
by the success of transformers in NLP and vision. In speech processing, pioneering self-supervised
models like wav2vec 2.0 [2] and HuBERT [17] leverage unlabeled audio at scale to learn powerful
feature encoders. Wav2Vec 2.0 introduced a contrastive learning framework on masked speech
audio and demonstrated that pre-training on tens of thousands of hours of unlabeled speech enabled
automatic speech recognition (ASR) with very little labeled data. Building on this, HuBERT uses
masked prediction of latent acoustic units, where audio frames are clustered and a transformer model
is trained to predict these cluster labels for masked timesteps. HuBERT achieved state-of-the-art
performance on the SUPERB benchmark for speech tasks, demonstrating the efficacy of learning rich
acoustic representations from self-supervision. Beyond speech, similar transformer architectures have
been applied to general audio. For example, the Self-Supervised Audio Spectrogram Transformer
(SSAST) [11] extends masked spectrogram modeling