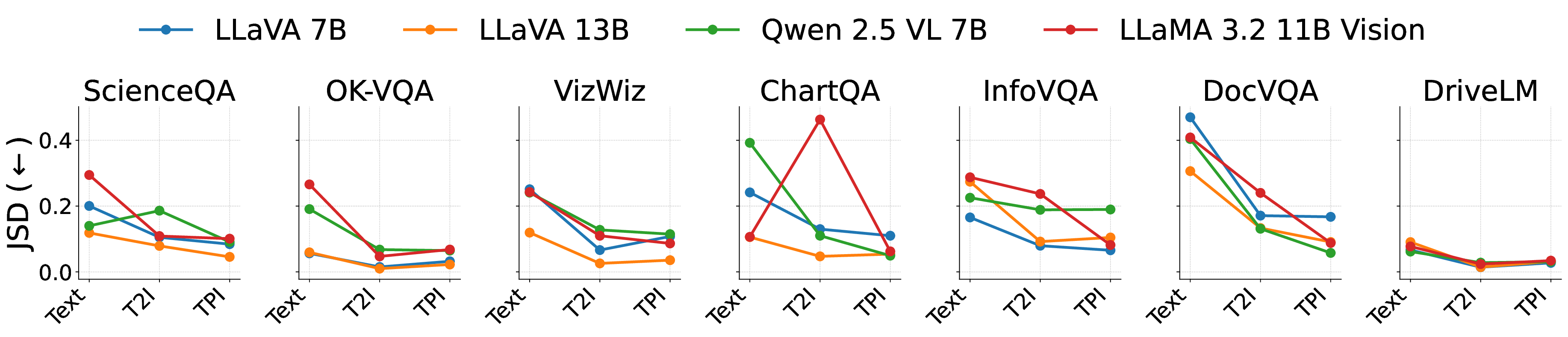
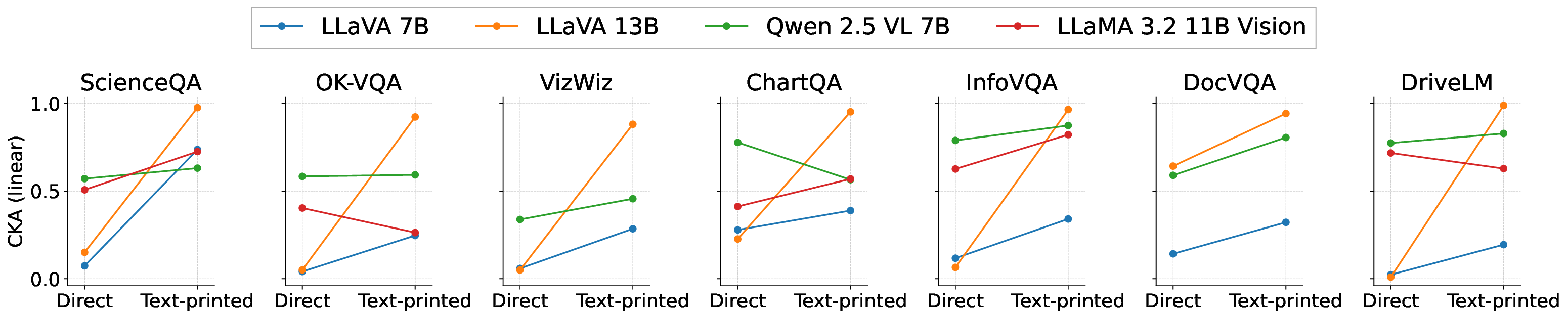
Recent large vision-language models (LVLMs) have been applied to diverse VQA tasks. However, achieving practical performance typically requires task-specific fine-tuning with large numbers of image-text pairs, which are costly to collect. In this work, we study text-centric training, a setting where only textual descriptions are available and no real images are provided, as a paradigm for low-cost data scaling. Unlike images, whose collection is often restricted by privacy constraints and scarcity in niche domains, text is widely available. Moreover, text is easily editable, enabling automatic diversification and expansion with LLMs at minimal human effort. While this offers clear advantages over image collection in terms of scalability and cost, training on raw text without images still yields limited gains on VQA tasks because of the image-text modality gap. To address this issue, we propose a Text-Printed Image (TPI), which generates synthetic images by directly rendering the given textual description on a plain white canvas. This simple rendering projects text into the image modality and can be integrated into arbitrary existing LVLM training pipelines at low cost. Moreover, TPI preserves the semantics of the text, whereas text-to-image models often fail to do. Across four models and seven benchmarks, our systematic experiments show that TPI enables more effective text-centric training than synthetic images generated by a diffusion model. We further explore TPI as a low-cost data-augmentation strategy and demonstrate its practical utility. Overall, our findings highlight the significant potential of text-centric training and, more broadly, chart a path toward fully automated data generation for LVLMs.
💡 Deep Analysis
📄 Full Content
Text-Printed Image: Bridging the Image-Text Modality Gap for Text-centric
Training of Large Vision-Language Models
Shojiro Yamabe1,2,†
Futa Waseda1,3
Daiki Shiono1,4
Tsubasa Takahashi1,‡
1Turing Inc.
2Institute of Science Tokyo
3The University of Tokyo
4Tohoku University
†yamabe.s.2fb0@m.isct.ac.jp
‡tsubasa.takahashi@turing-motors.com
Textual description
“A man wearing a
black suit and…”
Text-printed image (ours)
Q: Where is
the man?
A: At a media
event.
Text-to-Image
Collecting real images is costly and limited
Low Fidelity to Q&A
Image-Text
Modality Gap
Language Model
Image Encoder
Higher Fidelity to Q&A
Text-centric Training
Text-centric Training
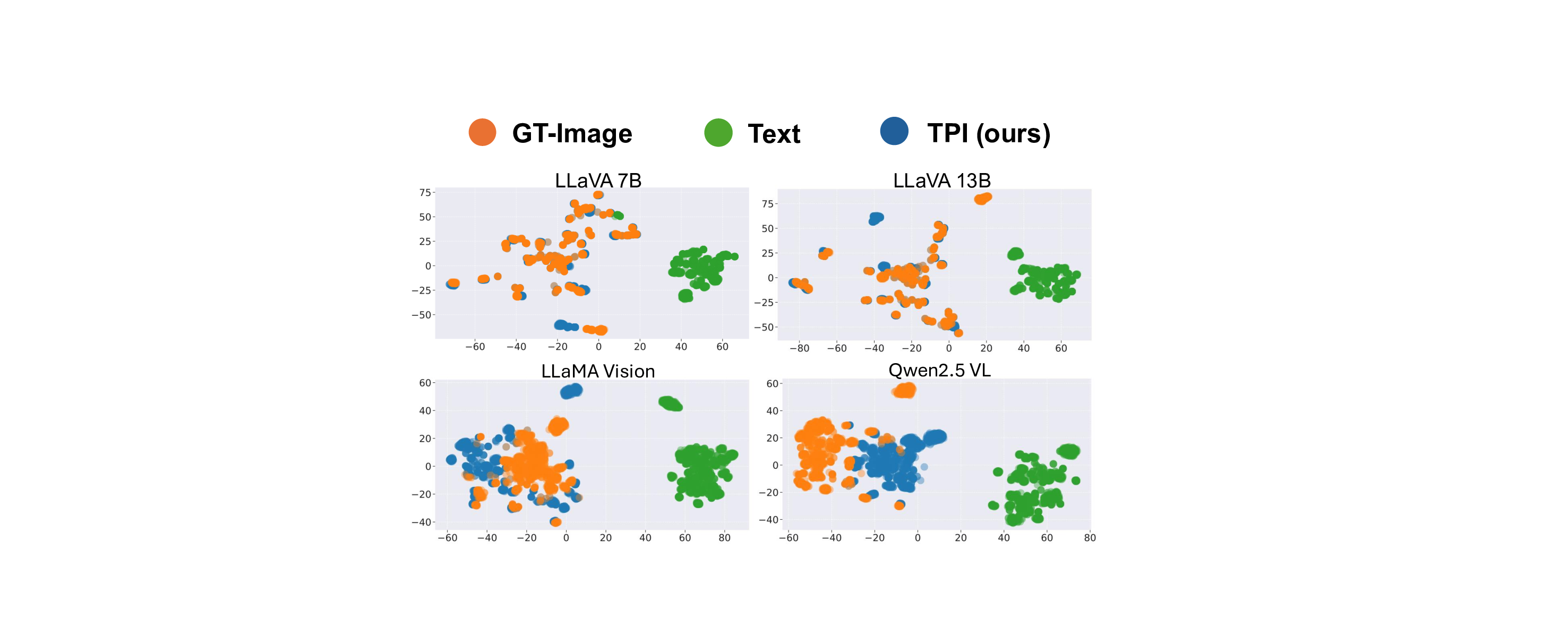
GT-image
t-SNE Visualization
of Hidden States
Modality Gap
TPI bridges the modality gap
Text
TPI (ours)
Image Encoder
Text Encoder
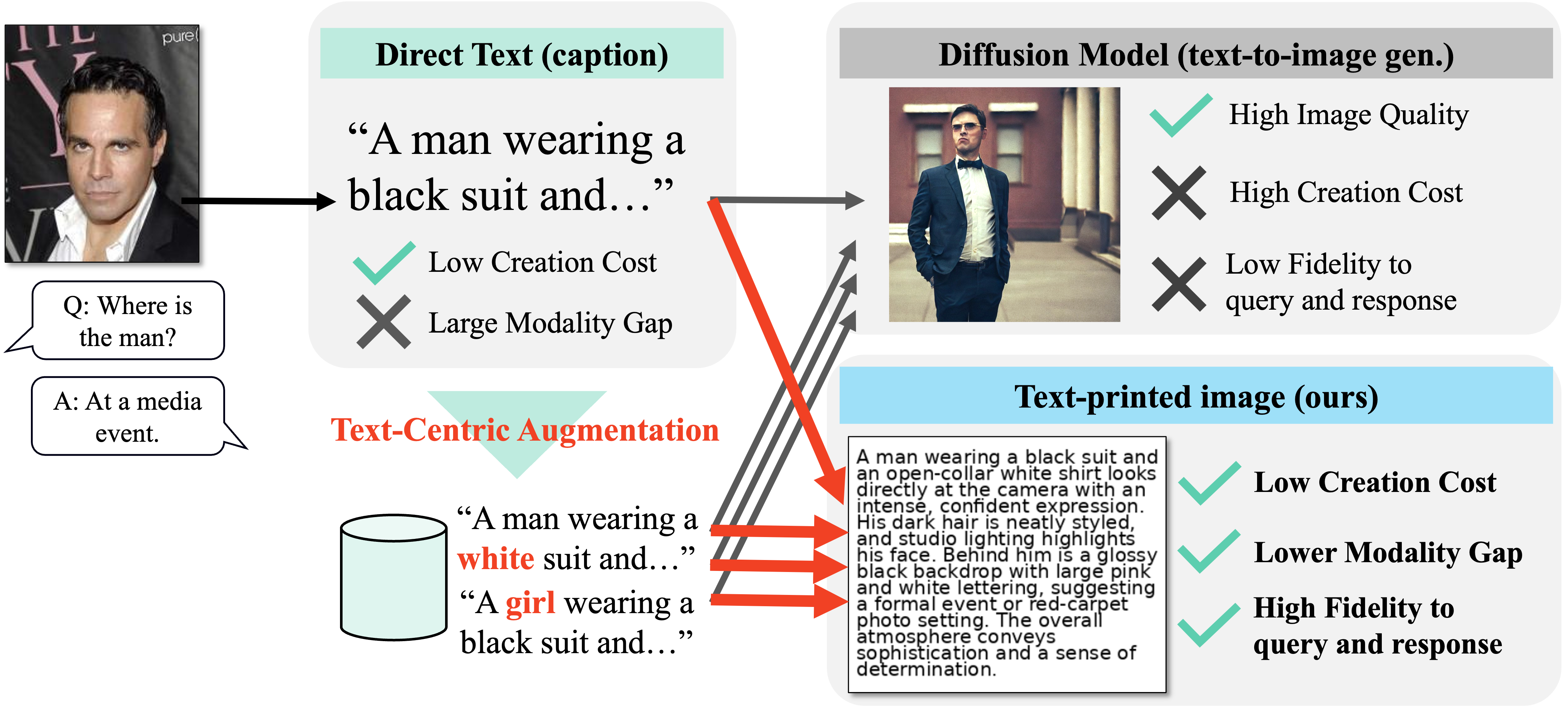
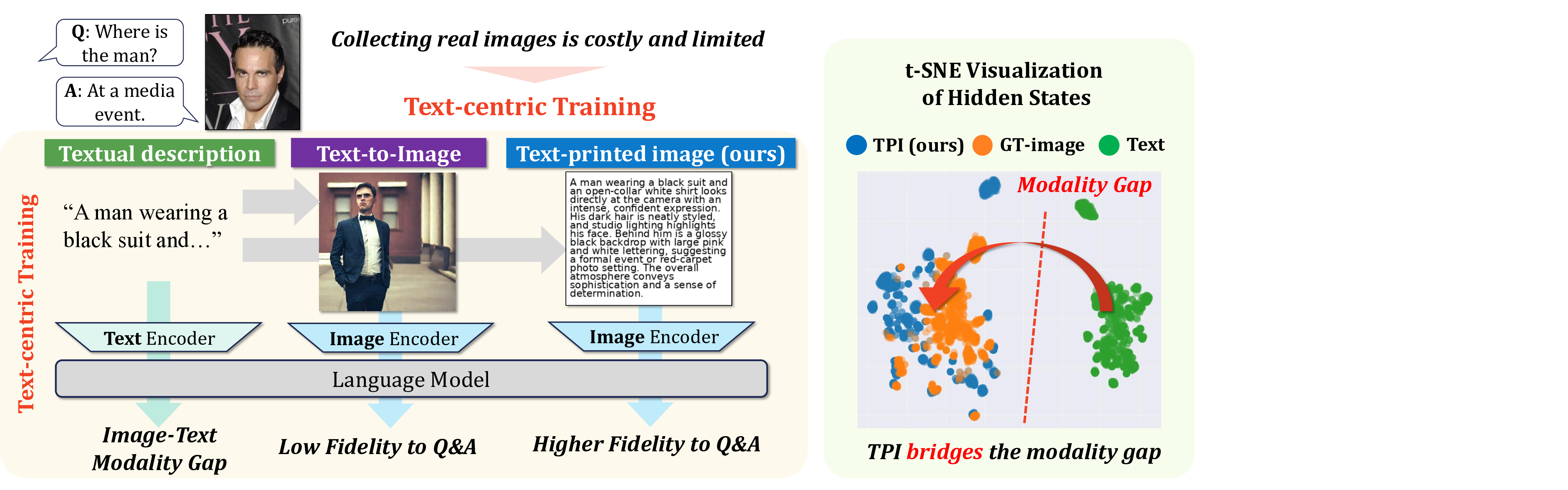
Figure 1. Text-Printed Image (TPI) provides an efficient and broadly applicable approach for text-centric training. While raw text
input suffers from an image-text modality gap and synthetic images generated by a text-to-image model lose fidelity to Q&A pairs, TPI
bridges this gap by embedding textual content into the visual pathway, achieving high fidelity to the ground-truth visual supervision.
Abstract
Recent large vision–language models (LVLMs) have been
applied to diverse VQA tasks. However, achieving practi-
cal performance typically requires task-specific fine-tuning
with large numbers of image-text pairs, which are costly to
collect. In this work, we study text-centric training, a set-
ting where only textual descriptions are available and no
real images are provided, as a paradigm for low-cost data
scaling. Unlike images, whose collection is often restricted
by privacy constraints and scarcity in niche domains, text is
widely available. Moreover, text is easily editable, enabling
automatic diversification and expansion with LLMs at min-
imal human effort. While this offers clear advantages over
image collection in terms of scalability and cost, training
on raw text without images still yields limited gains on VQA
tasks because of the image–text modality gap. To address
this issue, we propose a Text-Printed Image (TPI), which
generates synthetic images by directly rendering the given
textual description on a plain white canvas. This simple ren-
dering projects text into the image modality and can be in-
tegrated into arbitrary existing LVLM training pipelines at
low cost. Moreover, TPI preserves the semantics of the text,
whereas text-to-image models often fail to do. Across four
models and seven benchmarks, our systematic experiments
show that TPI enables more effective text-centric training
than synthetic images generated by a diffusion model. We
further explore TPI as a low-cost data-augmentation strat-
egy and demonstrate its practical utility. Overall, our find-
ings highlight the significant potential of text-centric train-
ing and, more broadly, chart a path toward fully automated
data generation for LVLMs.
1. Introduction
Large
Vision-Language
Models
(LVLMs)
[38]
have
emerged as a powerful extension of Large Language Mod-
els (LLMs). Building on strong foundational capabilities,
they have been applied across diverse VQA tasks, includ-
1
arXiv:2512.03463v1 [cs.CV] 3 Dec 2025
ing autonomous driving [72] and healthcare [21]. To at-
tain practical performance on these downstream tasks, task-
specific fine-tuning is typically required.
However, constructing a large-scale dataset remains
challenging for such training, as practical SFT typically re-
quires vast amounts of image–text instructions [38, 61, 62].
In contrast to LLM training, which benefits from abundant
text corpora [5], LVLM training requires image-conditioned
instruction data, and constructing such data is substantially
more costly [31, 38].
Although automated methods for
scraping web images and pairing them with correspond-
ing text have been proposed [10, 12, 30, 52, 67], their
applicability is often limited in specialized or niche do-
mains [32, 51].
In this work, we consider text-centric training, where
only textual descriptions are available and no images are
provided. Our premise is that text is abundant and easy to
prepare compared to images. Rich text corpora and struc-
tured lexical resources make it possible to synthesize de-
scriptions from class names and concept taxonomies [16,
20, 58]. Moreover, text is much easier to modify than im-
ages. While changing a small detail in an image is dif-
ficult [22], textual descriptions can be edited or expanded
with little effort, and LLMs can automatically generate di-
verse variants [57]. Recent advances in LLM-based data
augmentation [13, 56] further enhance this potential, en-
abling scalable and diverse text synthesis at low cost. Taken
together, these factors make text-centric training a promis-
ing yet underexplored direction for advancing LVLMs when
images are scarce or unavailable.
A primary challenge for effective text-centric training is
the image-text modality gap [17, 35, 66, 68], which is a