Agentic reasoning models trained with multimodal reinforcement learning (MMRL) have become increasingly capable, yet they are almost universally optimized using sparse, outcome-based rewards computed based on the final answers. Richer rewards computed from the reasoning tokens can improve learning significantly by providing more fine-grained guidance. However, it is challenging to compute more informative rewards in MMRL beyond those based on outcomes since different samples may require different scoring functions and teacher models may provide noisy reward signals too. In this paper, we introduce the Argos (Agentic Reward for Grounded & Objective Scoring), a principled reward agent to train multimodal reasoning models for agentic tasks. For each sample, Argos selects from a pool of teacher-model derived and rule-based scoring functions to simultaneously evaluate: (i) final response accuracy, (ii) spatiotemporal localization of referred entities and actions, and (iii) the quality of the reasoning process. We find that by leveraging our agentic verifier across both SFT data curation and RL training, our model achieves state-of-the-art results across multiple agentic tasks such as spatial reasoning, visual hallucination as well as robotics and embodied AI benchmarks. Critically, we demonstrate that just relying on SFT post-training on highly curated reasoning data is insufficient, as agents invariably collapse to ungrounded solutions during RL without our online verification. We also show that our agentic verifier can help to reduce reward-hacking in MMRL. Finally, we also provide a theoretical justification for the effectiveness of Argos through the concept of pareto-optimality.
Agentic reasoning models trained with multimodal reinforcement learning (MMRL) have become increasingly capable, yet they are almost universally optimized using sparse, outcome-based rewards computed based on the final answers. Richer rewards computed from the reasoning tokens can improve learning significantly by providing more fine-grained guidance. However, it is challenging to compute more informative rewards in MMRL beyond those based on outcomes since different samples may require different scoring functions and teacher models may provide noisy reward signals too. In this paper, we introduce the Ar-gos (Agentic Reward for Grounded & Objective Scoring), a principled reward agent to train multimodal reasoning models for agentic tasks. For each sample, Argos selects from a pool of teacher-model derived and rule-based scoring functions to simultaneously evaluate: (i) final response accuracy, (ii) spatiotemporal localization of referred entities and actions, and (iii) the quality of the reasoning process. We find that by leveraging our agentic verifier across both SFT data curation and RL training, our model achieves state-of-the-art results across multiple agentic tasks such as spatial reasoning, visual hallucination as well as robotics and embodied AI benchmarks. Critically, we demonstrate that just relying on SFT post-training on highly curated rea-
Intelligent beings seamlessly integrate perception, language, and action. With a goal in mind, they first observe a scene, interpret it in context, and then formulate and execute a plan. To emulate this ability, researchers have been shifting from static perception to agentic multimodal models that can reason about observations, plan and use tools [9,11,31,34,58]. Such agentic models for multimodal reasoning have wide-ranging applications, including AI agents that collaborate with humans, interactive GUI [39] and tool-using [55] assistants, and systems such as robots and self-driving cars. In particular, reinforcement learning, including the recent GRPO [52] and DAPO [67] algorithms, has been crucial in driving this progress. Verifiable outcome rewards help align such reasoning models with downstream tasks. However, using only outcome rewards provides limited guidance on the quality of the reasoning process and can cause hallucination [22]. While RL for text-only reasoning has been extensively studied, approaches for computing richer rewards in multimodal RL (MMRL) remain comparatively under-explored and introduce unique challenges, such as selecting appropriate scoring functions per sample, mitigating noisy signals from teacher models, and maintaining consistency between perception and language throughout the reasoning process.
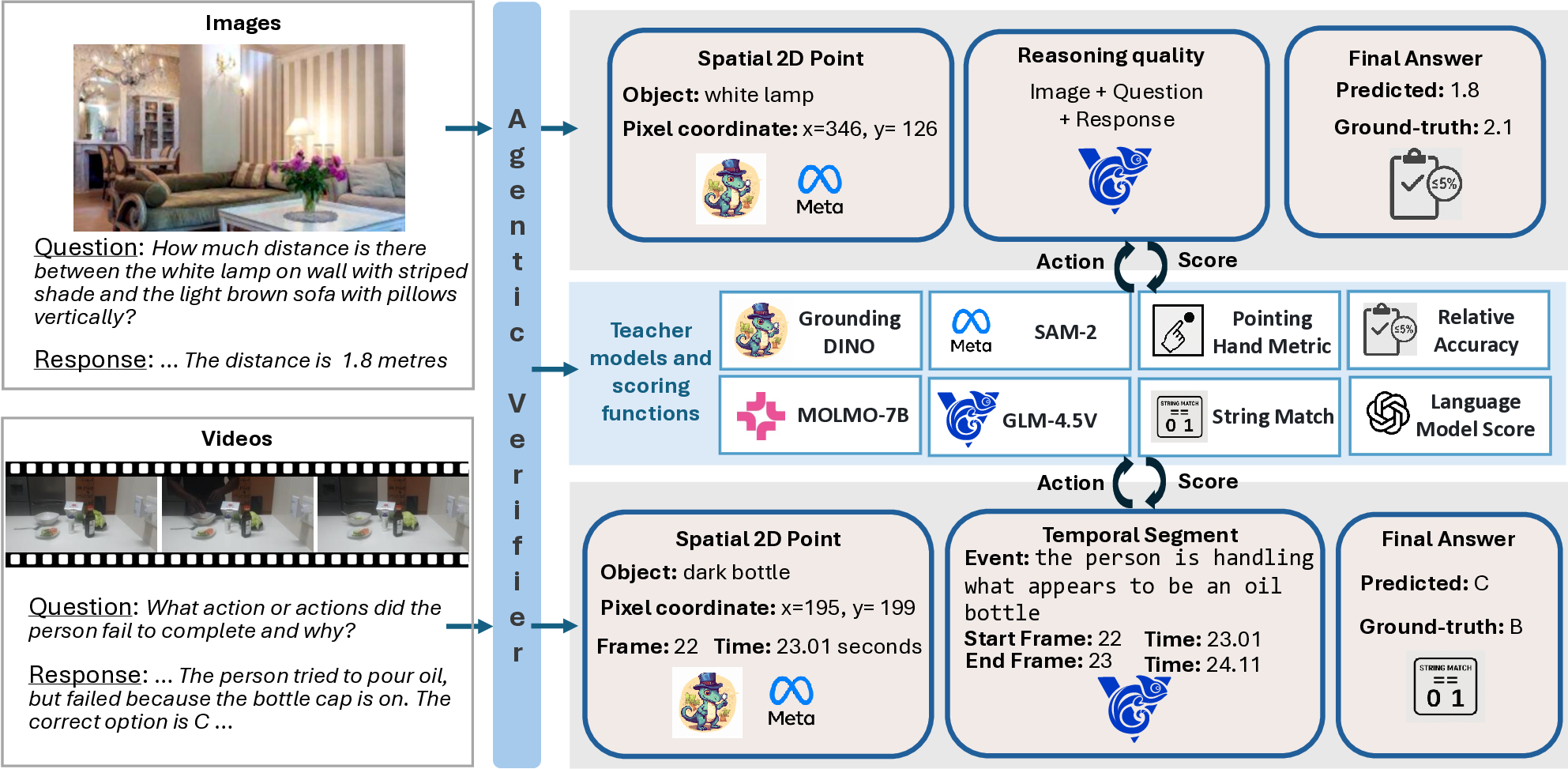
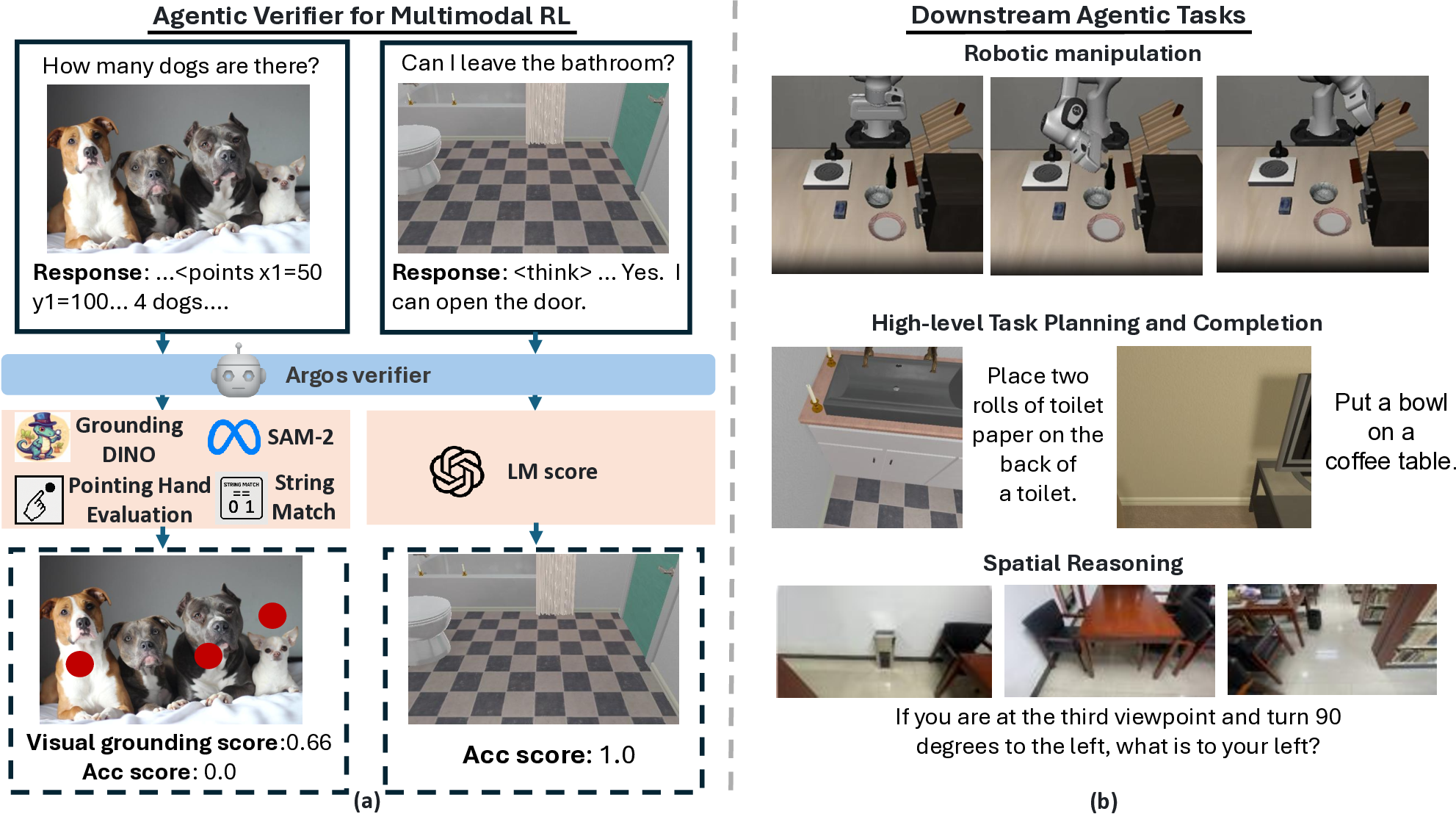
To address the above-mentioned challenges, we introduce Agentic Reward for Grounded and Objective Scoring (Argos) verifier (Figure 1a), which adaptively selects from a set of teacher models and rule-based scoring functions like string matching to evaluate the response of each sample across spatial grounding, reasoning quality and accuracy. Our proposed verifier jointly evaluates final answer accuracy, spatiotemporal grounding and reasoning quality. Finally, we compute an aggregated final reward that is gated by correct outcomes but enriched with intermediate reward terms. Additionally, we propose an approach based on overlaying explicit 2D point coordinates on images and video frames, that leverages the OCR capability of a teacher model to generate reasoning data that are visually grounded in pixels across space and time. In addition to MMRL, we also use Argos during our data curation process to filter out low-quality rollouts from the teacher model for the SFT stage.
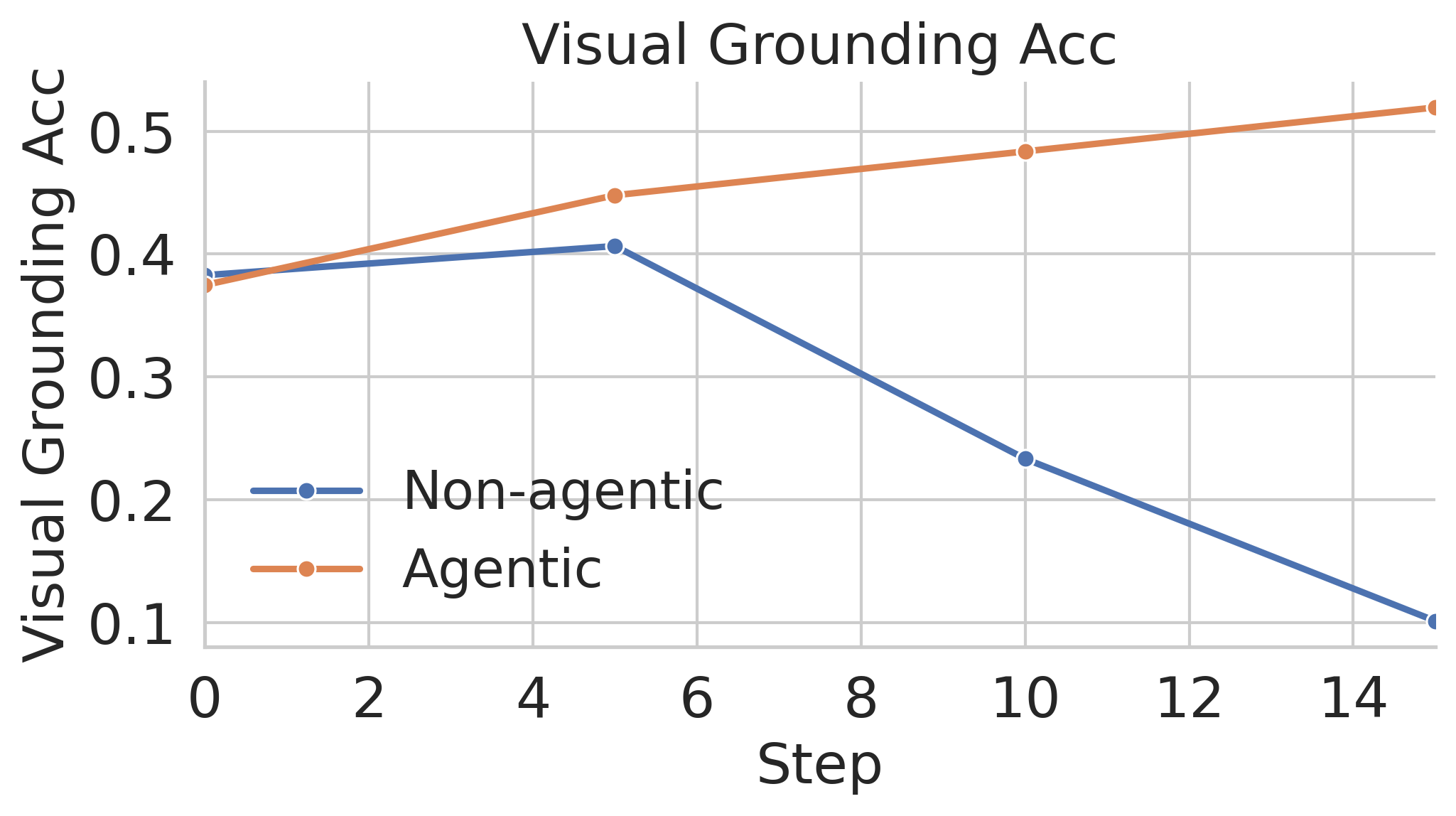
While some concurrent approaches have also proposed the concept of visually grounded reasoning, they place the main focus on the curation of SFT annotations. Crucially, we observe empirically that curating grounded SFT data is not sufficient. These agentic reasoning models invariably collapse to ungrounded responses without verifying the generated 2D points during MMRL. In addition, our agentic verifier helps curb reward hacking in MMRL. Argos is also related to research on tool-augmented agents [50] but those methods generally employ tools for inference-time problem solving, leaving the intermediate reasoning and visual evidence under-verified during training. In contrast, Argos helps to convert multiple noisy reward signals into a final verifiable reward.
From a learning perspective, our verifier reframes MMRL as multi-objective optimization with multiple noisy teacher rewards. We provide a brief theoretical justification to provide an intuition on why adaptive and multi-objective reward verification can help the policy model to learn better. The modular architecture of Argos enables it to extend naturally to new modalities and objectives. As task-specific teacher models improve, our Argos has the potential to compute more informative reward signals, enabling the
This content is AI-processed based on open access ArXiv data.