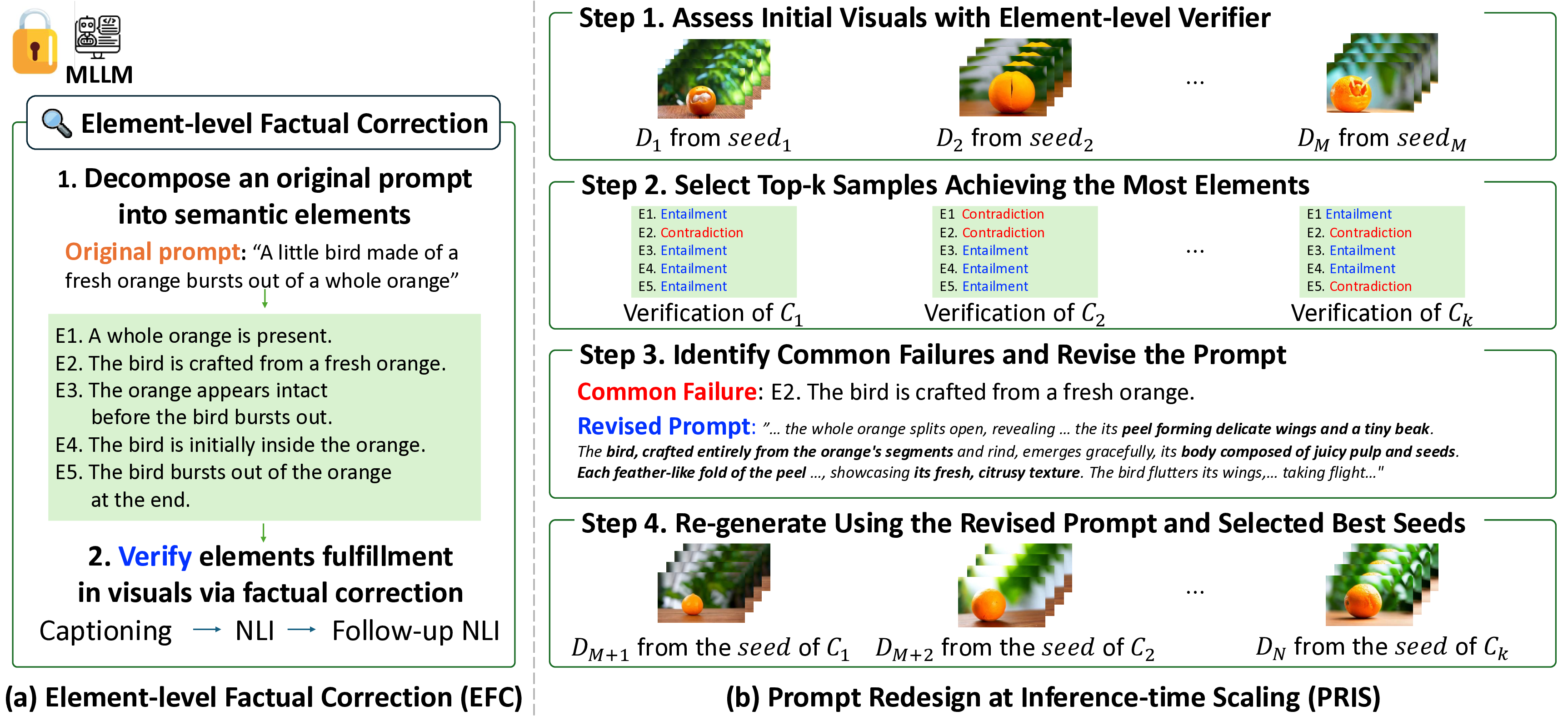
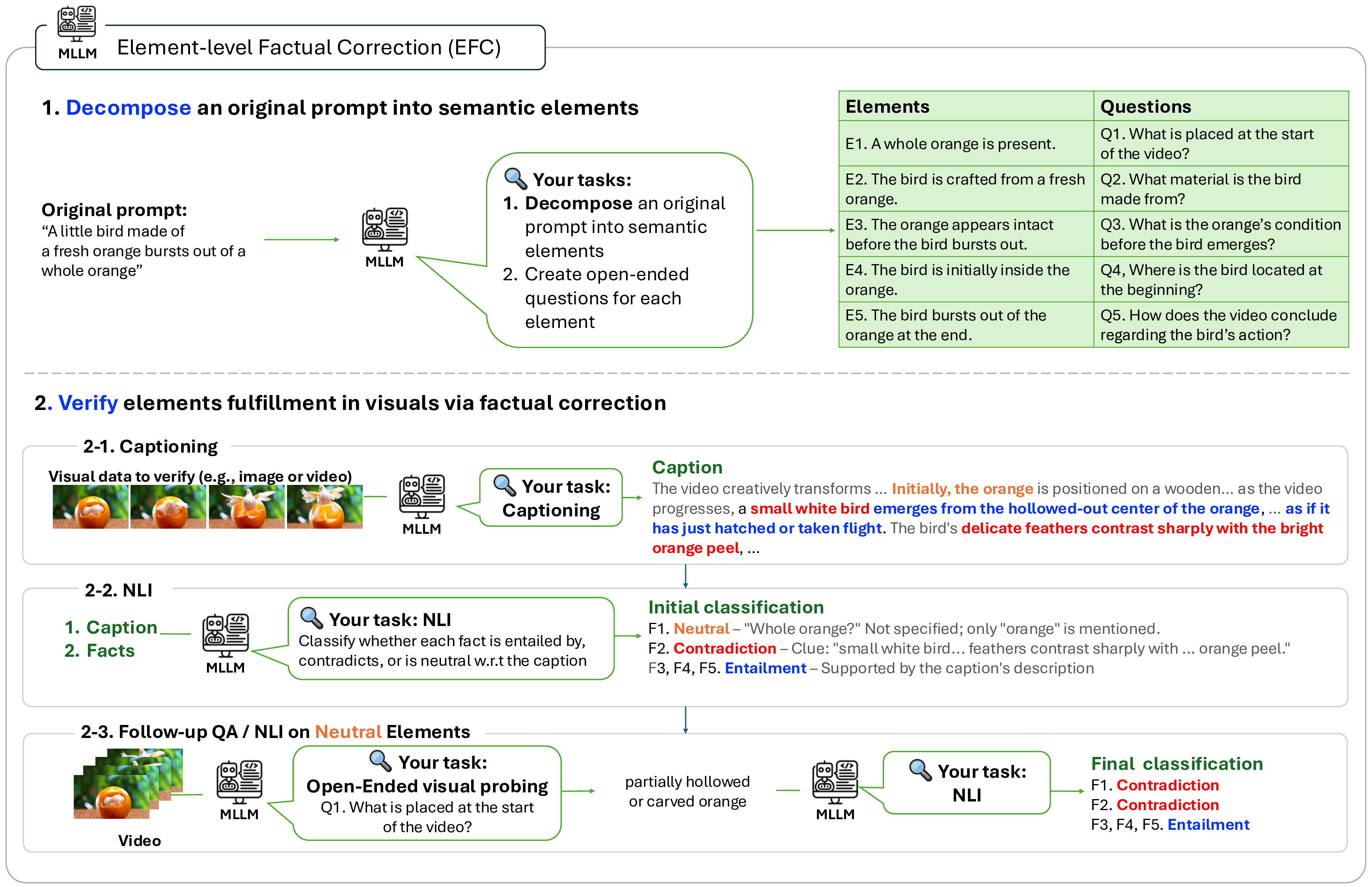
Achieving precise alignment between user intent and generated visuals remains a central challenge in text-to-visual generation, as a single attempt often fails to produce the desired output. To handle this, prior approaches mainly scale the visual generation process (e.g., increasing sampling steps or seeds), but this quickly leads to a quality plateau. This limitation arises because the prompt, crucial for guiding generation, is kept fixed. To address this, we propose Prompt Redesign for Inference-time Scaling, coined PRIS, a framework that adaptively revises the prompt during inference in response to the scaled visual generations. The core idea of PRIS is to review the generated visuals, identify recurring failure patterns across visuals, and redesign the prompt accordingly before regenerating the visuals with the revised prompt. To provide precise alignment feedback for prompt revision, we introduce a new verifier, element-level factual correction, which evaluates the alignment between prompt attributes and generated visuals at a fine-grained level, achieving more accurate and interpretable assessments than holistic measures. Extensive experiments on both text-to-image and text-to-video benchmarks demonstrate the effectiveness of our approach, including a 15% gain on VBench 2.0. These results highlight that jointly scaling prompts and visuals is key to fully leveraging scaling laws at inference-time. Visualizations are available at the website: https://subin-kim-cv.github.io/PRIS.
💡 Deep Analysis
📄 Full Content
Rethinking Prompt Design for Inference-time Scaling in Text-to-Visual Generation
Subin Kim1
Sangwoo Mo2
Mamshad Nayeem Rizve3
Yiran Xu3
Difan Liu3
Jinwoo Shin1
Tobias Hinz4
1KAIST
2POSTECH
3Adobe
4Meta
subin-kim@kaist.ac.kr
Abstract
Achieving precise alignment between user intent and gen-
erated visuals remains a central challenge in text-to-visual
generation, as a single attempt often fails to produce the
desired output. To handle this, prior approaches mainly
scale the visual generation process (e.g., increasing sam-
pling steps or seeds), but this quickly leads to a quality
plateau. This limitation arises because the prompt, crucial
for guiding generation, is kept fixed. To address this, we
propose Prompt Redesign for Inference-time Scaling, coined
PRIS, a framework that adaptively revises the prompt during
inference in response to the scaled visual generations. The
core idea of PRIS is to review the generated visuals, iden-
tify recurring failure patterns across visuals, and redesign
the prompt accordingly before regenerating the visuals with
the revised prompt. To provide precise alignment feedback
for prompt revision, we introduce a new verifier, element-
level factual correction, which evaluates the alignment be-
tween prompt attributes and generated visuals at a fine-
grained level, achieving more accurate and interpretable
assessments than holistic measures. Extensive experiments
on both text-to-image and text-to-video benchmarks demon-
strate the effectiveness of our approach, including a 15%
gain on VBench 2.0. These results highlight that jointly scal-
ing prompts and visuals is key to fully leveraging scaling
laws at inference-time. Visualizations are available at the
website: https://subin-kim-cv.github.io/PRIS.
1. Introduction
Generative models [5, 21, 35] have achieved remarkable
progress across various domains, including language, image,
and video, demonstrating strong capabilities in modeling
complex data distributions. In the visual domain, denoising
models [16, 27] conditioned on textual prompts now allow
users to generate high-quality images and videos directly
from natural language. However, as prompts become more
intricate, e.g., requiring compositional structures in images
or complex motion, camera movements, and causal orders in
videos, it becomes increasingly challenging to obtain outputs
that fully align with the prompt in a single attempt.
Recent work addresses this shortfall in text-visual align-
ment by allocating additional compute at inference time (i.e.,
inference-time scaling). These approaches typically scale the
visual generation either by increasing the compute budget
for decoding a single candidate from a prompt [30], or by
generating multiple candidates for the same prompt to pro-
duce a diverse pool of visual outputs [12, 18, 19]. However,
they primarily focus on scaling visual parts while keeping
the input prompt fixed. This creates a key bottleneck because
many generation errors arise from ambiguous or incomplete
prompts, and scaling visuals conditioned on a suboptimal
prompt offers limited benefit since the prompt provides es-
sential guidance for conditional generation.
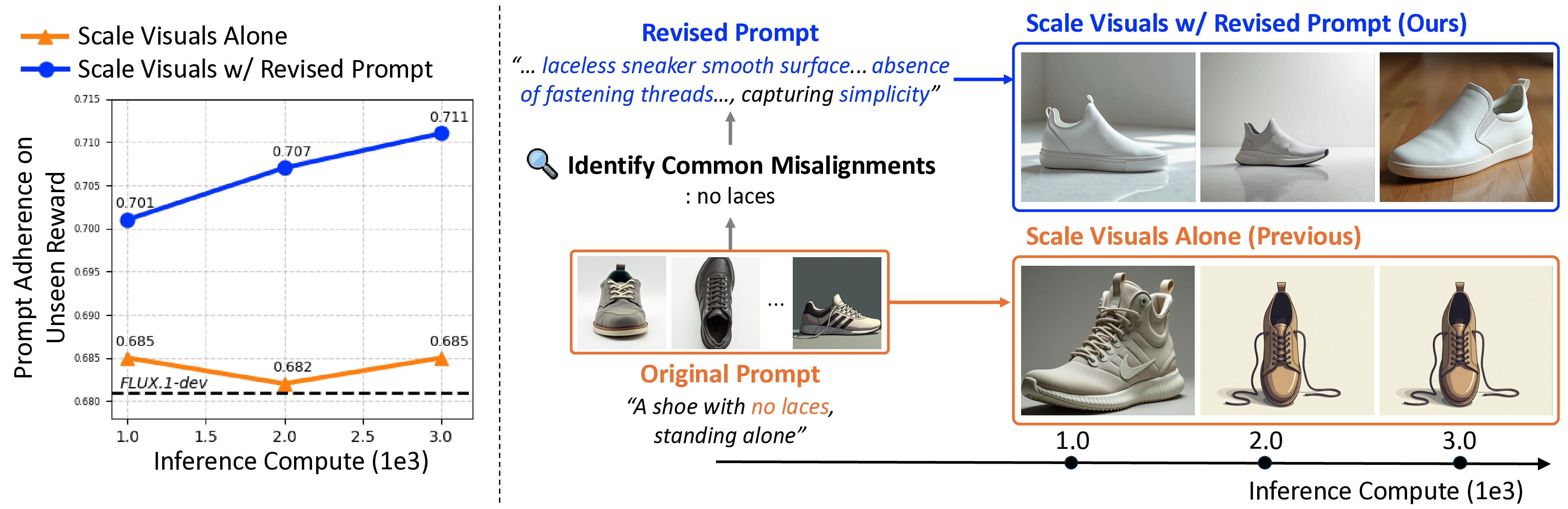
More importantly, visual scaling consistently reveals re-
curring generative failures. For example, in Figure 1, when
scaling with the intent “a shoe with no laces, standing alone,”
the element “a shoe” is consistently achieved, yet laces still
appear in every output. These failure patterns become even
more pronounced as prompts grow more complex, such as
in text-to-video generation, where producing a high-fidelity
sample becomes substantially harder. However, prior prompt-
refinement approaches [4, 6, 11, 40] are confined to individ-
ual samples, focusing on sample-specific deviations. As a
result, they fail to correct the recurring failure modes that
consistently appear across samples when scaling, missing
the opportunity to jointly improve both the conditioning text
and the generated outputs.
To address these limitations, we extend inference-time
scaling beyond the visual domain to the text prompts, propos-
ing Prompt Redesign for Inference-time Scaling (PRIS). In-
stead of passively waiting for a high-scoring sample when
scaling visuals, PRIS identifies recurring failure modes
across scaled visuals and adaptively revises the prompt to
reinforce commonly under-addressed aspects while preserv-
ing the user’s original intent. Consequently, whereas fixed-
prompt inference-time scaling quickly plateaus in prompt
1
arXiv:2512.03534v1 [cs.CV] 3 Dec 2025
Identify Common Misalignments
: no laces
1.0
2.0
3.0
Inference Compute (1e3)
“A shoe with no laces,
standing alone”
Original Prompt
“… laceless sneaker smooth surface... absence
of fastening threads…, capturing simplicity”
Revised Prompt
Scale Visuals w/ Revised Prompt (Ours)
Scale Visuals Alone (Previous)
⋯
Inference Compute (1e3)
Prompt Adherence on
Unseen Reward
Scale Visuals Alone
Scale Visuals w/ Revised Prompt
Figure 1. Our prompt redesign