Title: Highly Efficient Test-Time Scaling for T2I Diffusion Models with Text Embedding Perturbation
ArXiv ID: 2512.03996
Date: 2025-12-03
Authors: ** Hang Xu¹, Linjiang Huang², Feng Zhao¹* ¹ MoE Key Lab of BIPC, University of Science and Technology of China (USTC) ² Beihang University **
📝 Abstract
Test-time scaling (TTS) aims to achieve better results by increasing random sampling and evaluating samples based on rules and metrics. However, in text-to-image(T2I) diffusion models, most related works focus on search strategies and reward models, yet the impact of the stochastic characteristic of noise in T2I diffusion models on the method's performance remains unexplored. In this work, we analyze the effects of randomness in T2I diffusion models and explore a new format of randomness for TTS: text embedding perturbation, which couples with existing randomness like SDE-injected noise to enhance generative diversity and quality. We start with a frequency-domain analysis of these formats of randomness and their impact on generation, and find that these two randomness exhibit complementary behavior in the frequency domain: spatial noise favors low-frequency components (early steps), while text embedding perturbation enhances high-frequency details (later steps), thereby compensating for the potential limitations of spatial noise randomness in high-frequency manipulation. Concurrently, text embedding demonstrates varying levels of tolerance to perturbation across different dimensions of the generation process. Specifically, our method consists of two key designs: (1) Introducing step-based text embedding perturbation, combining frequency-guided noise schedules with spatial noise perturbation. (2) Adapting the perturbation intensity selectively based on their frequency-specific contributions to generation and tolerance to perturbation. Our approach can be seamlessly integrated into existing TTS methods and demonstrates significant improvements on multiple benchmarks with almost no additional computation. Code is available at \href{https://github.com/xuhang07/TEP-Diffusion}{https://github.com/xuhang07/TEP-Diffusion}.
💡 Deep Analysis
📄 Full Content
Highly Efficient Test-Time Scaling for T2I Diffusion Models with Text
Embedding Perturbation
Hang Xu1
Linjiang Huang2
Feng Zhao1*
1MoE Key Lab of BIPC, USTC 2Beihang University
Abstract
Test-time scaling (TTS) aims to achieve better results by in-
creasing random sampling and evaluating samples based
on rules and metrics. However, in text-to-image(T2I) diffu-
sion models, most related works focus on search strategies
and reward models, yet the impact of the stochastic charac-
teristic of noise in T2I diffusion models on the method’s per-
formance remains unexplored. In this work, we analyze the
effects of randomness in T2I diffusion models and explore a
new format of randomness for TTS: text embedding pertur-
bation, which couples with existing randomness like SDE-
injected noise to enhance generative diversity and quality.
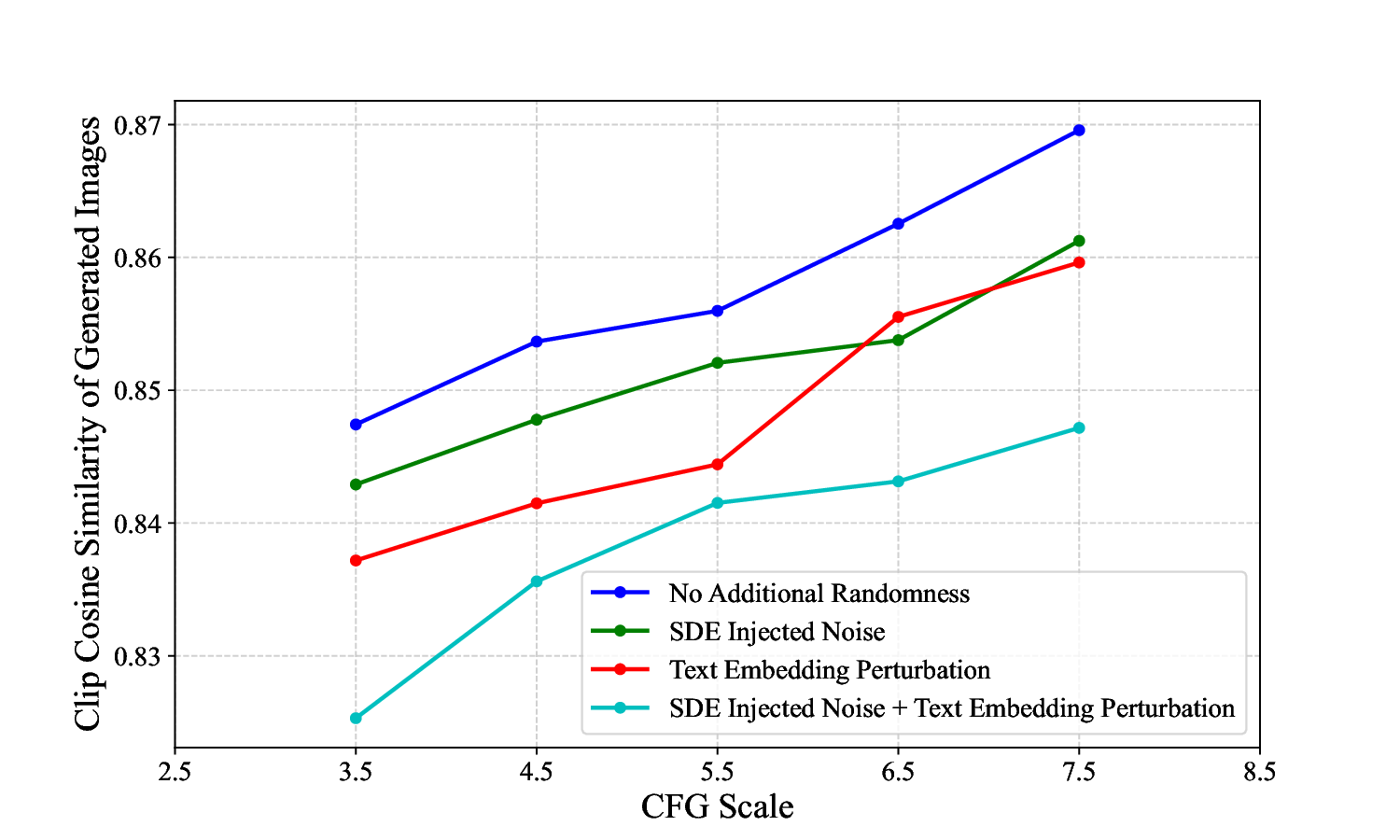
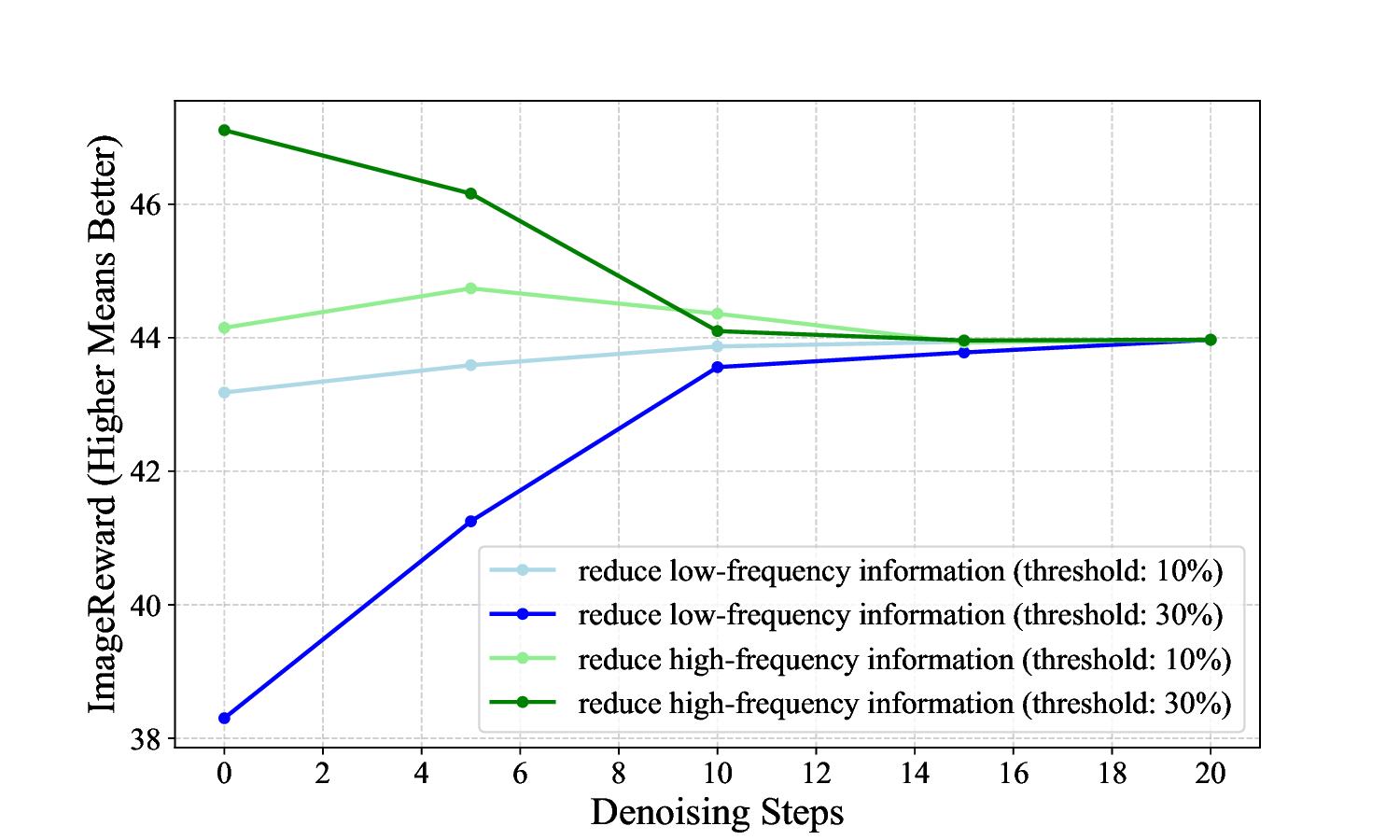
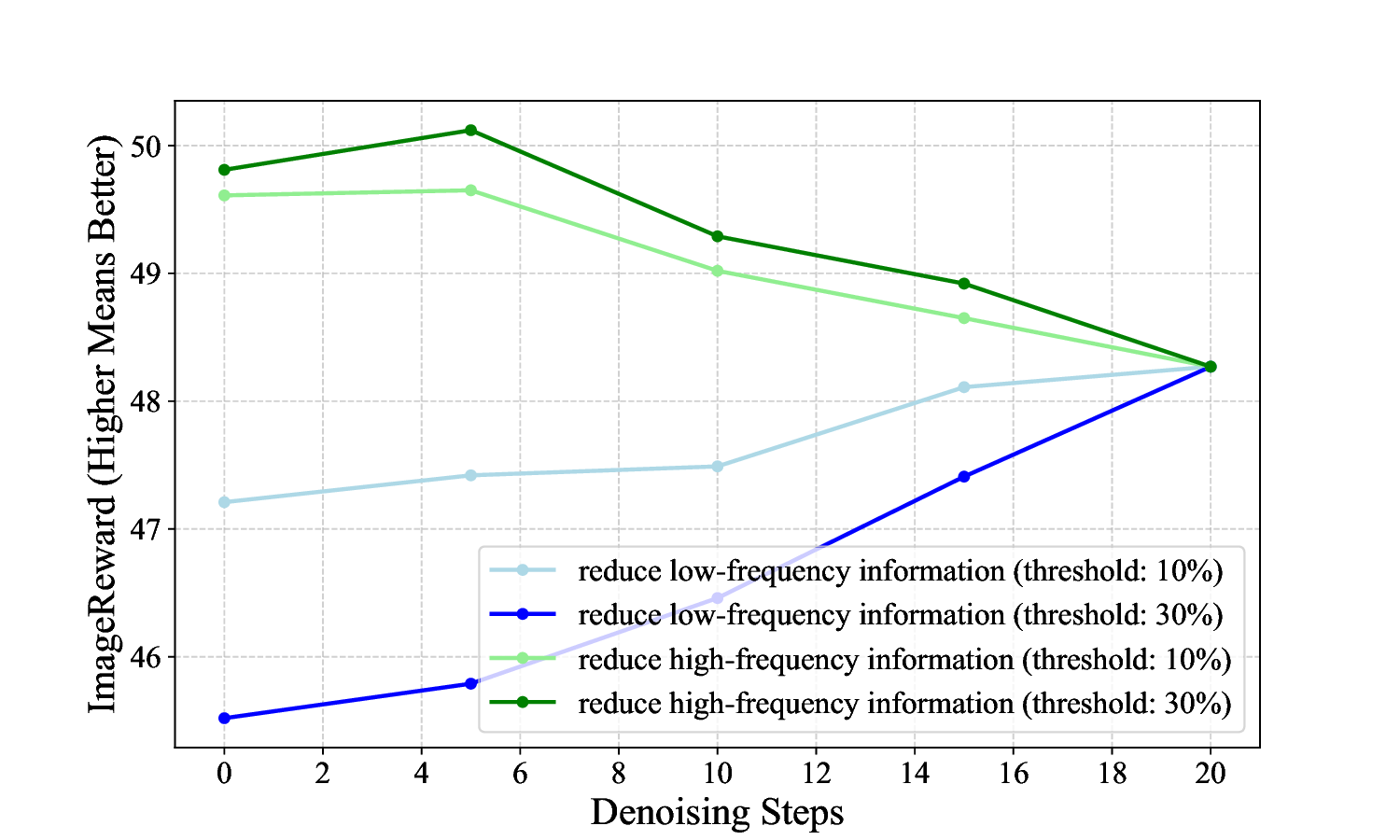
We start with a frequency-domain analysis of these formats
of randomness and their impact on generation, and find that
these two randomness exhibit complementary behavior in
the frequency domain: spatial noise favors low-frequency
components (early steps), while text embedding perturba-
tion enhances high-frequency details (later steps), thereby
compensating for the potential limitations of spatial noise
randomness in high-frequency manipulation. Concurrently,
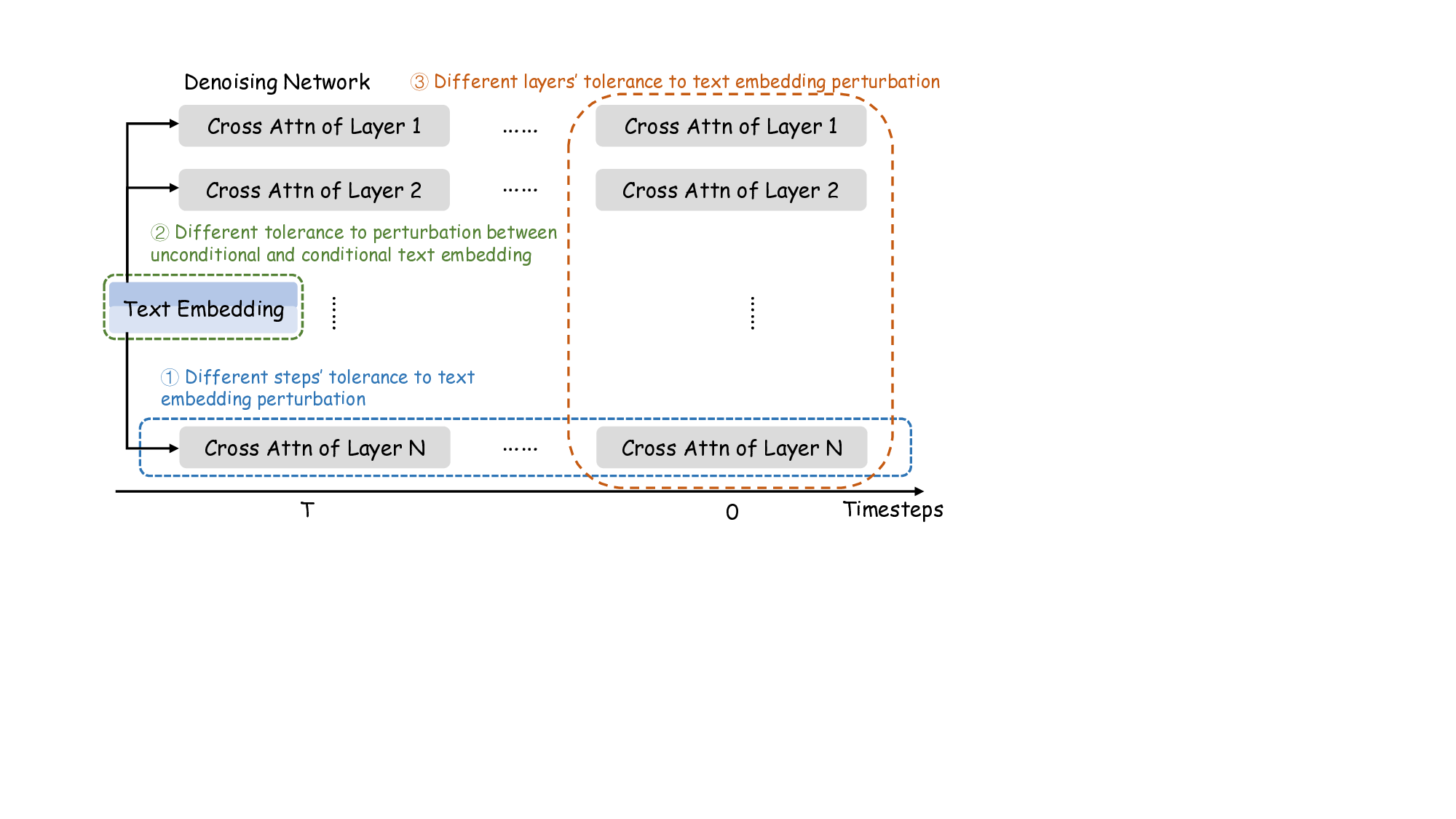
text embedding demonstrates varying levels of tolerance to
perturbation across different dimensions of the generation
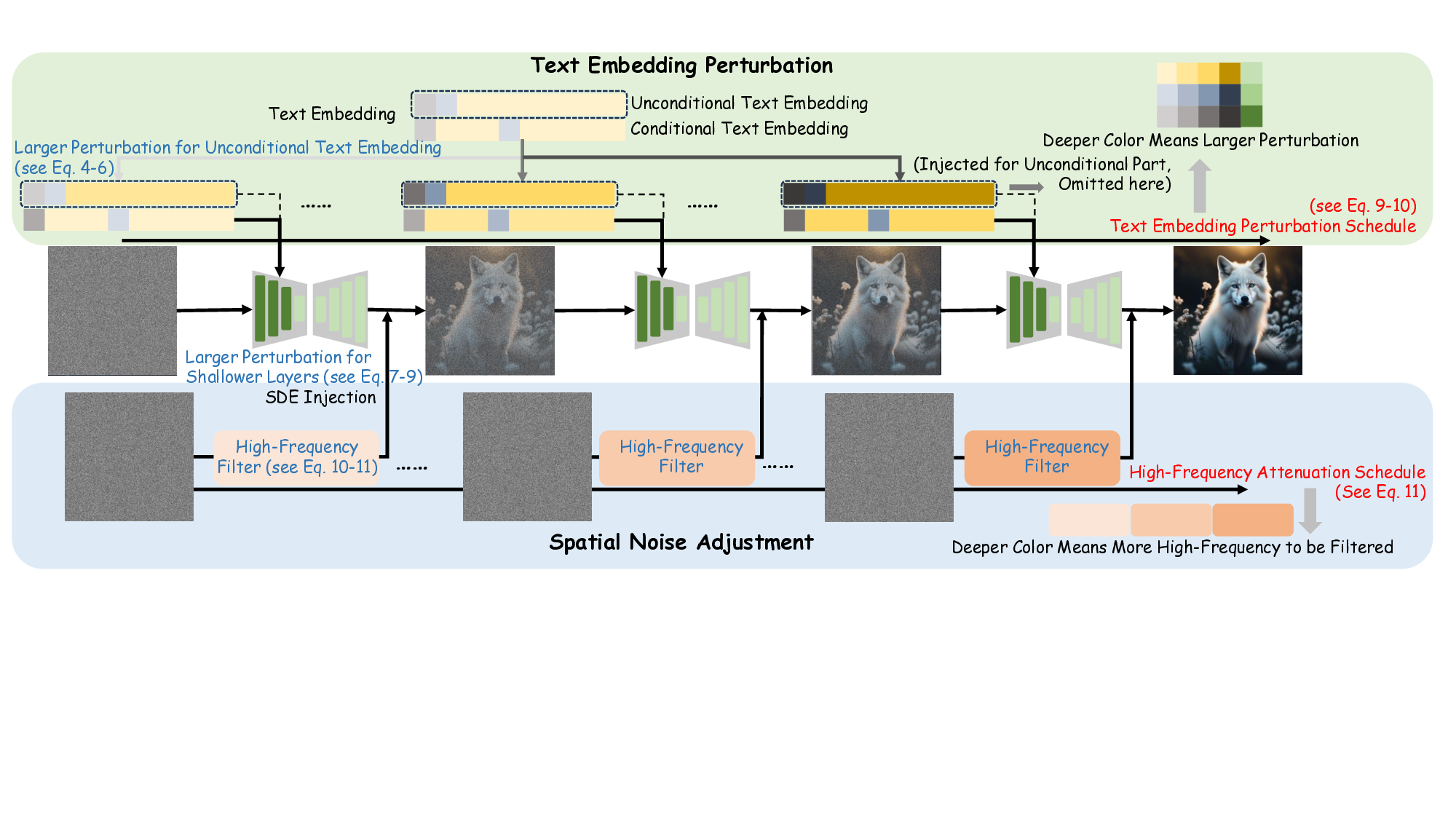
process. Specifically, our method consists of two key de-
signs: (1) Introducing step-based text embedding perturba-
tion, combining frequency-guided noise schedules with spa-
tial noise perturbation. (2) Adapting the perturbation inten-
sity selectively based on their frequency-specific contribu-
tions to generation and tolerance to perturbation. Our ap-
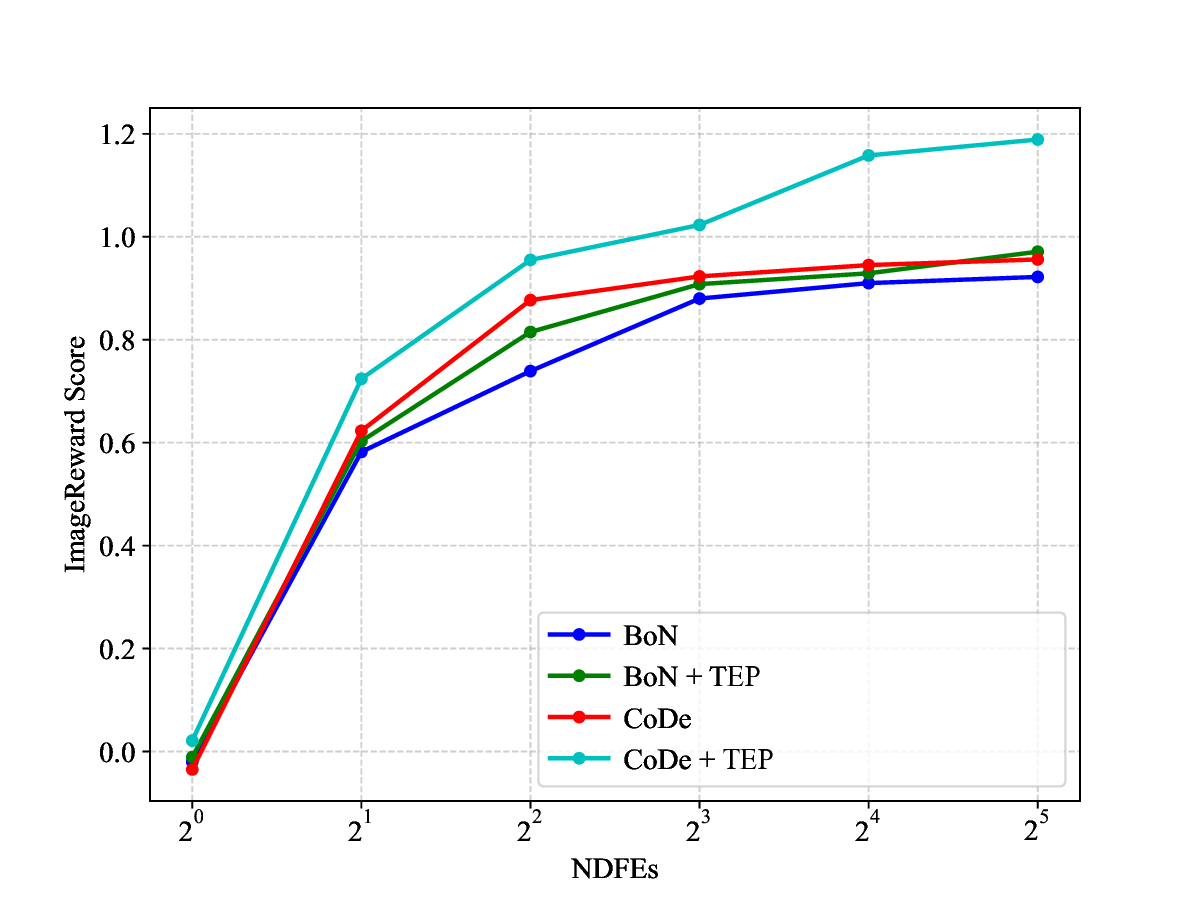
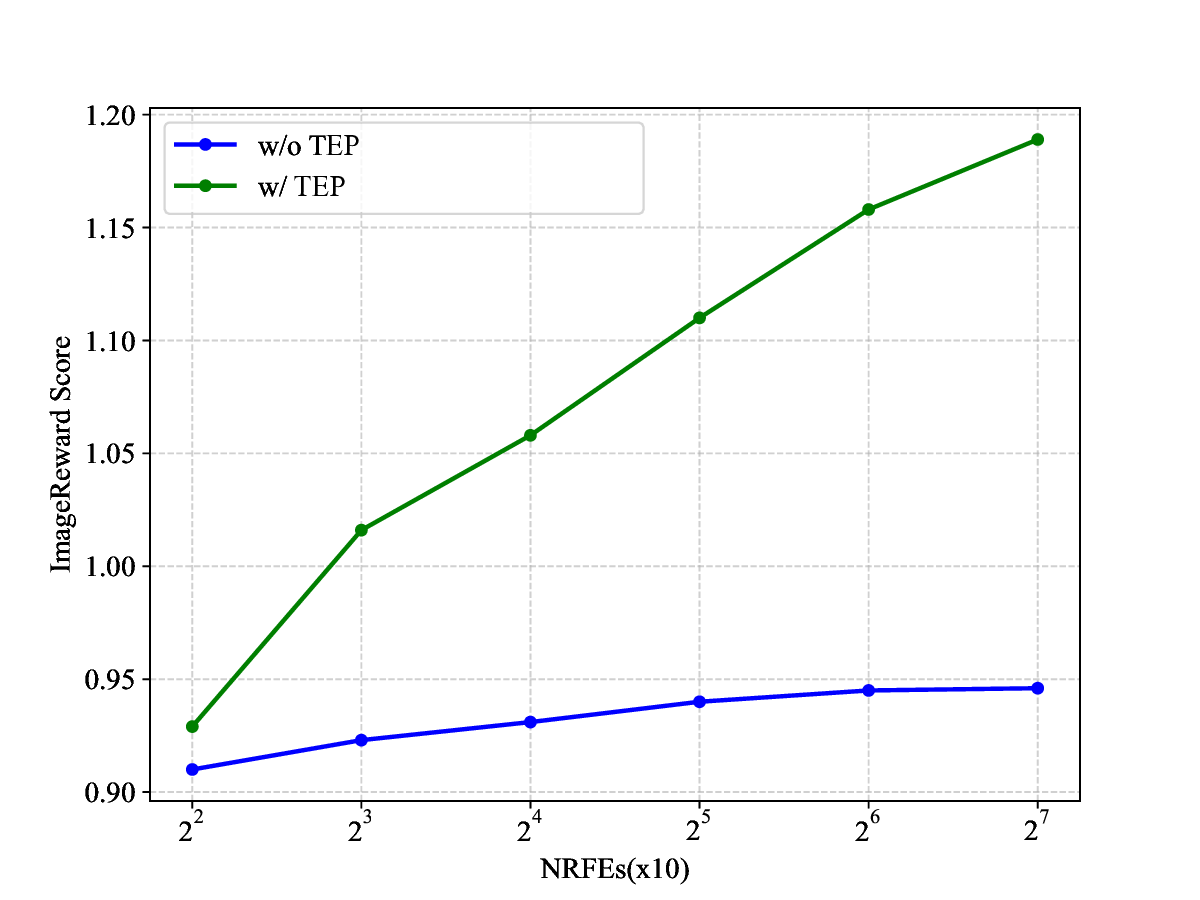
proach can be seamlessly integrated into existing TTS meth-
ods and demonstrates significant improvements on multiple
benchmarks with almost no additional computation. Code
is available at https://github.com/xuhang07/TEP-Diffusion.
1. Introduction
Diffusion models start from random noise and have
demonstrated impressive generative capabilities in text-to-
image(T2I) generation. However, due to the inconsistency
*Corresponding author
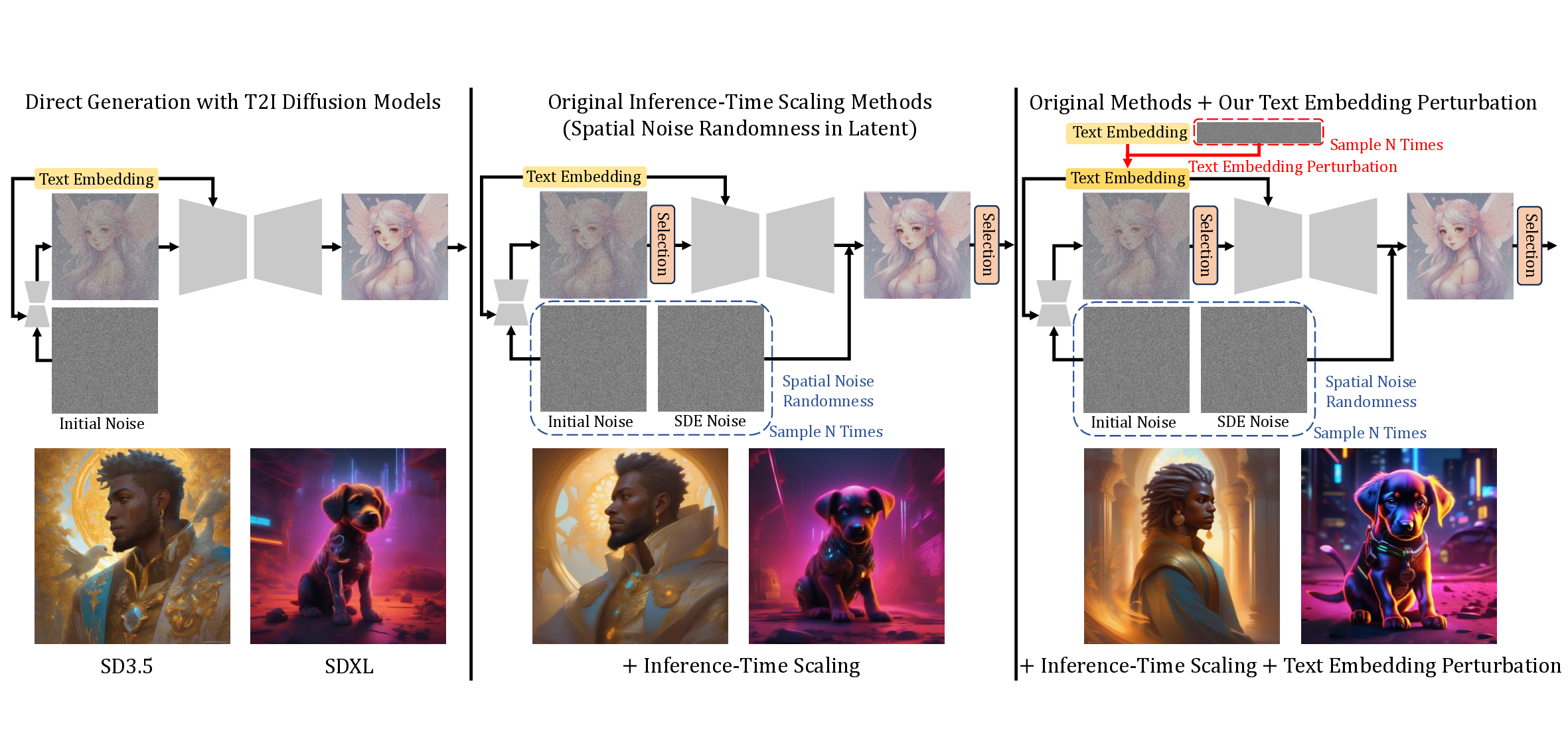
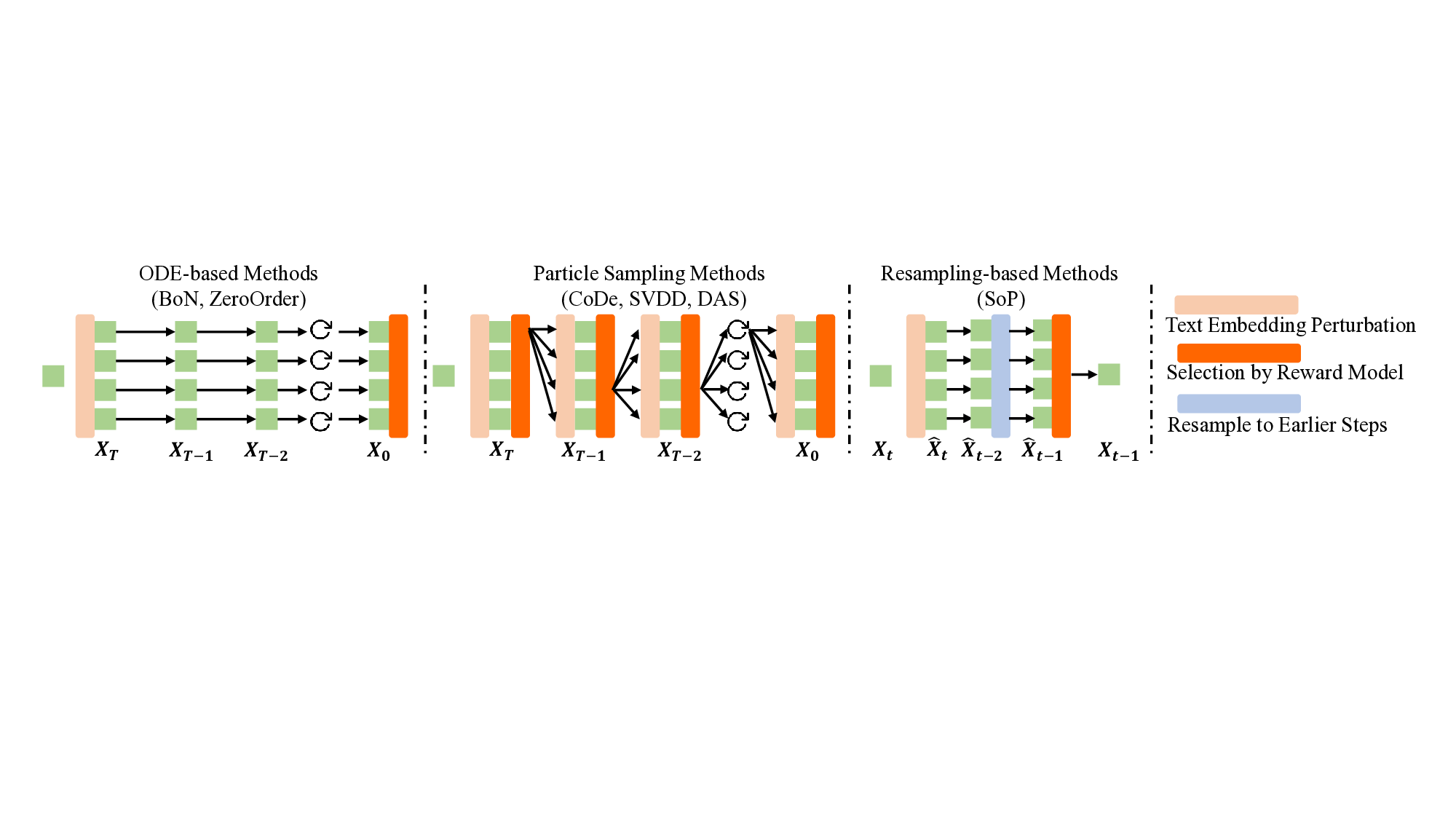
Original Inference-Time Scaling Methods
(Spatial Noise Randomness in Latent)
Original Methods + Our Text Embedding Perturbation
Text Embedding
Initial Noise
SDE Noise
Spatial Noise
Randomness
Selection
Selection
Sample N Times
Text Embedding
Initial Noise
SDE Noise
Spatial Noise
Randomness
Selection
Selection
Sample N Times
Text Embedding
Text Embedding Perturbation
Text Embedding
Initial Noise
Direct Generation with T2I Diffusion Models
SD3.5
SDXL
+ Inference-Time Scaling
+ Inference-Time Scaling + Text Embedding Perturbation
Sample N Times
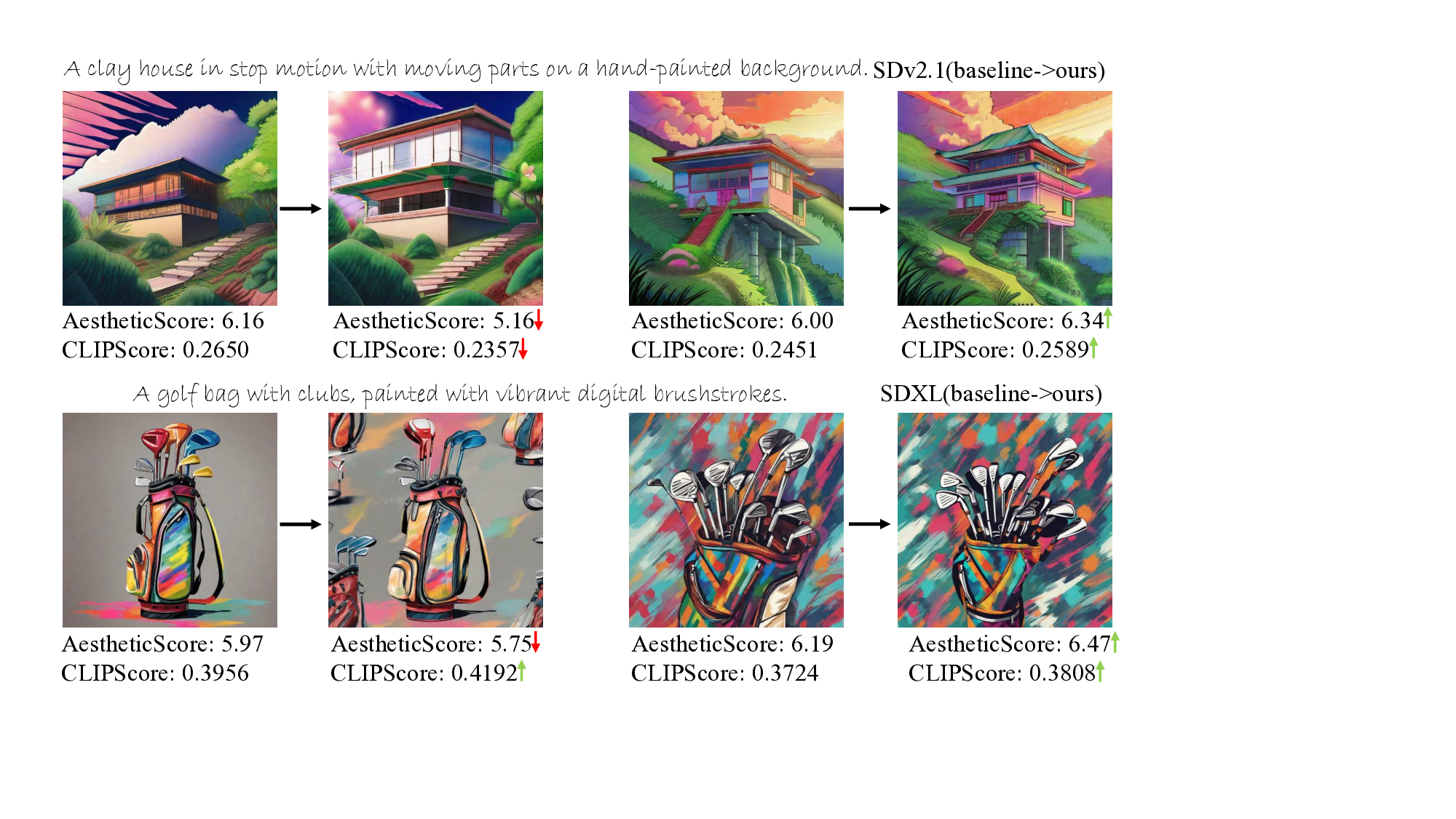
Figure 1. Top: Comparison of text embedding perturbation with
previous randomness. Bottom: The corresponding generated im-
ages of the Top. Our method is plug-and-play.
in their training-inference paradigm, where multiple noise-
to-data mappings are learned during training but only a
single noise is used during inference, the full potential of
diffusion models in generation remains untapped. There-
fore, inspired by the test-time scaling (TTS) techniques in
LLMs [11, 15], many researchers aim to enhance the gener-
ation quality of diffusion models by scaling inference com-
putations during inference [13, 23]. Specifically, these TTS
methods rely on the sampling randomness of diffusion mod-
els (like initial noise) to generate multiple candidate sam-
ples, evaluate them using reward models, and then employ
search strategies to select and further refine the candidates.
Therefore, the core components of TTS methods consist of
randomness, search strategies, and reward models.
Research on search strategies and reward models has
dominated TTS methods for T2I diffusion models, while
randomness and its impact on these methods remain unex-
plored. Notably, randomness directly affects the size of the
search space in TTS methods [32]. However, most existing
works rely solely on spatial random noise introduced in la-
tent space (i.e., SDE), which may not provide a sufficiently
large search space. A constrained search space means re-
peated sampling tends to converge on similar and redun-
dant candidates, leading to ineffective use of computational
resources [18]. Therefore, it is meaningful to explore a new
format of randomness that can both enhance generative di-
versity and complement existing spatial noise randomness.
In this paper, we explore a new format of randomness,
1
arXiv:2512.03996v1 [cs.CV] 3 Dec 2025
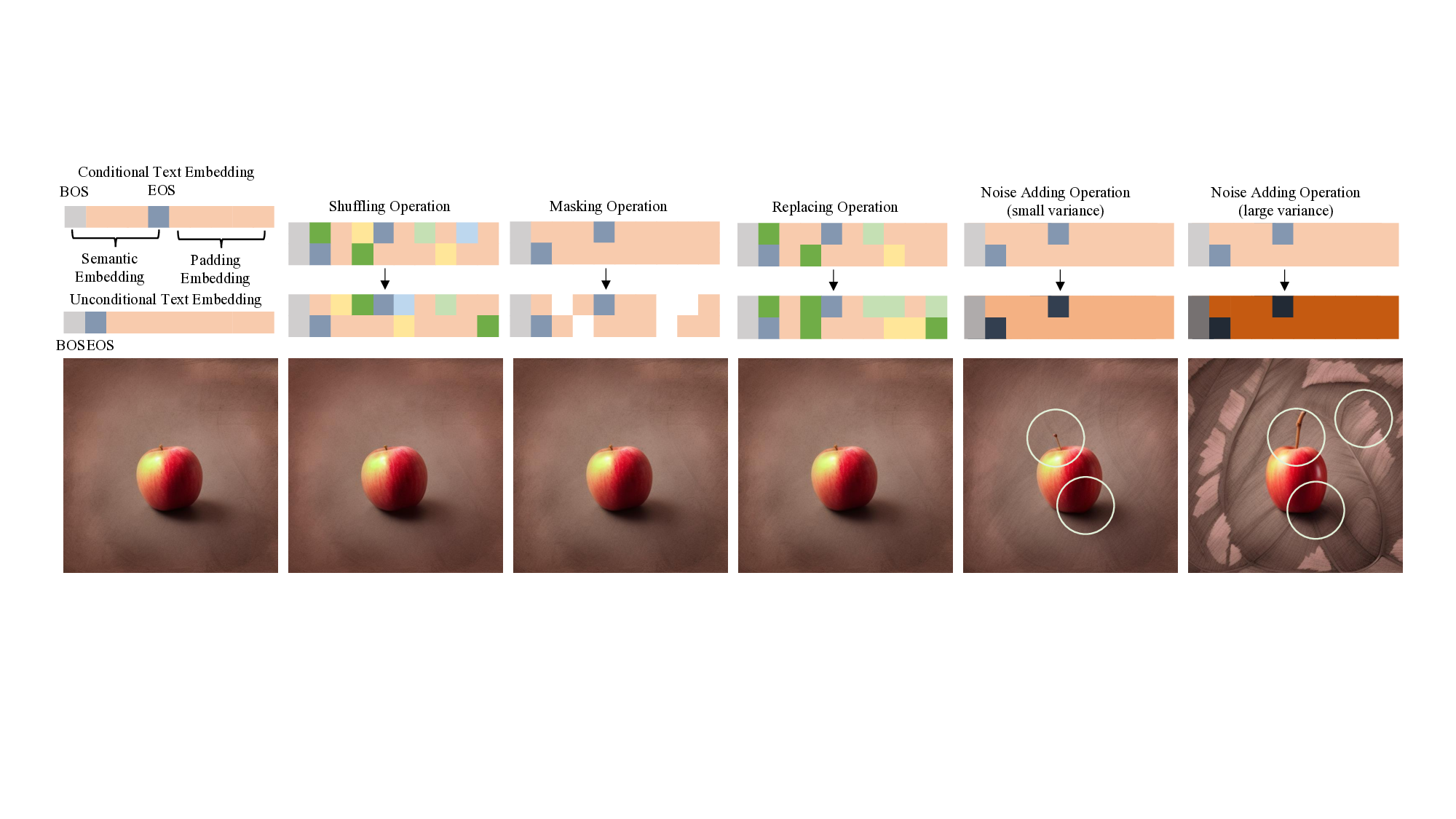
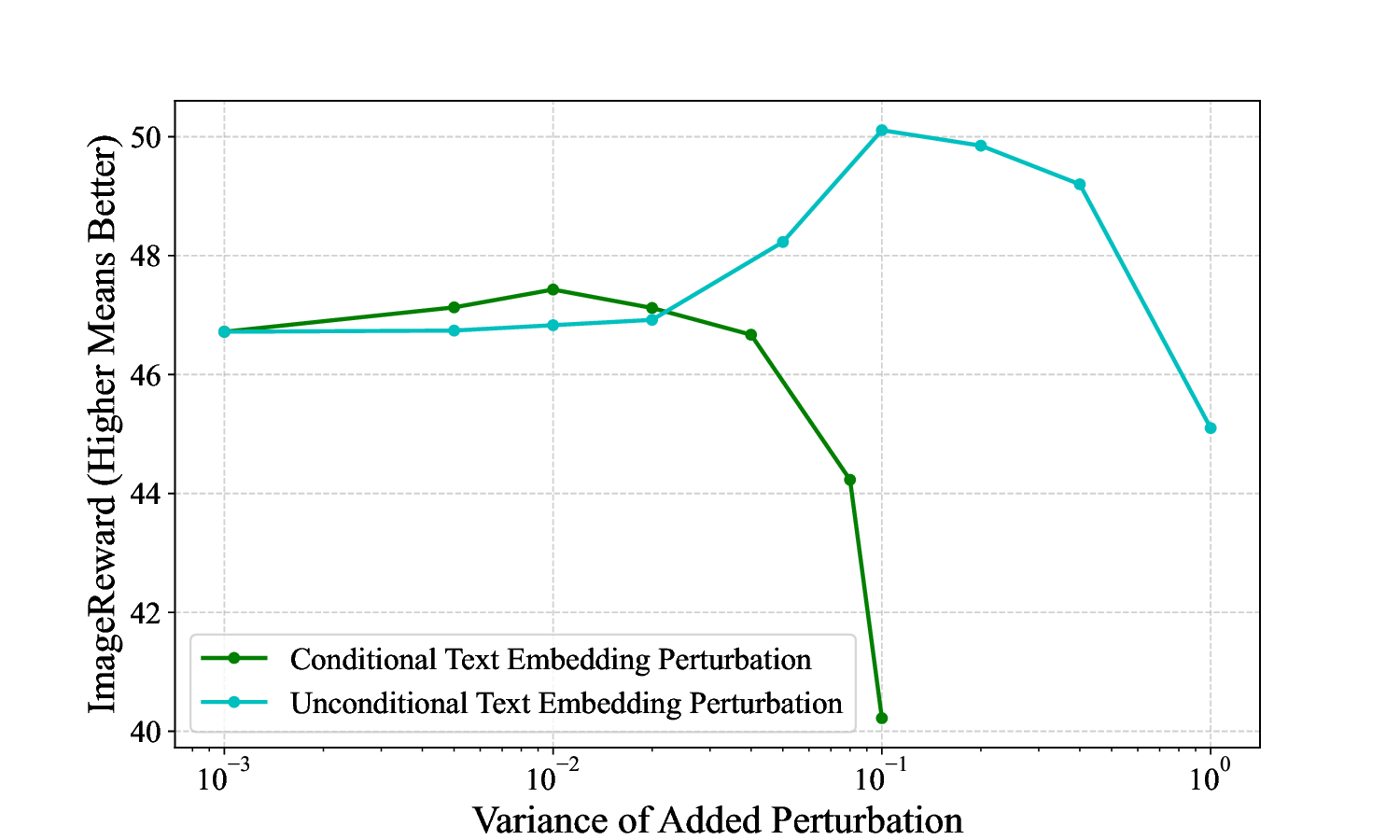
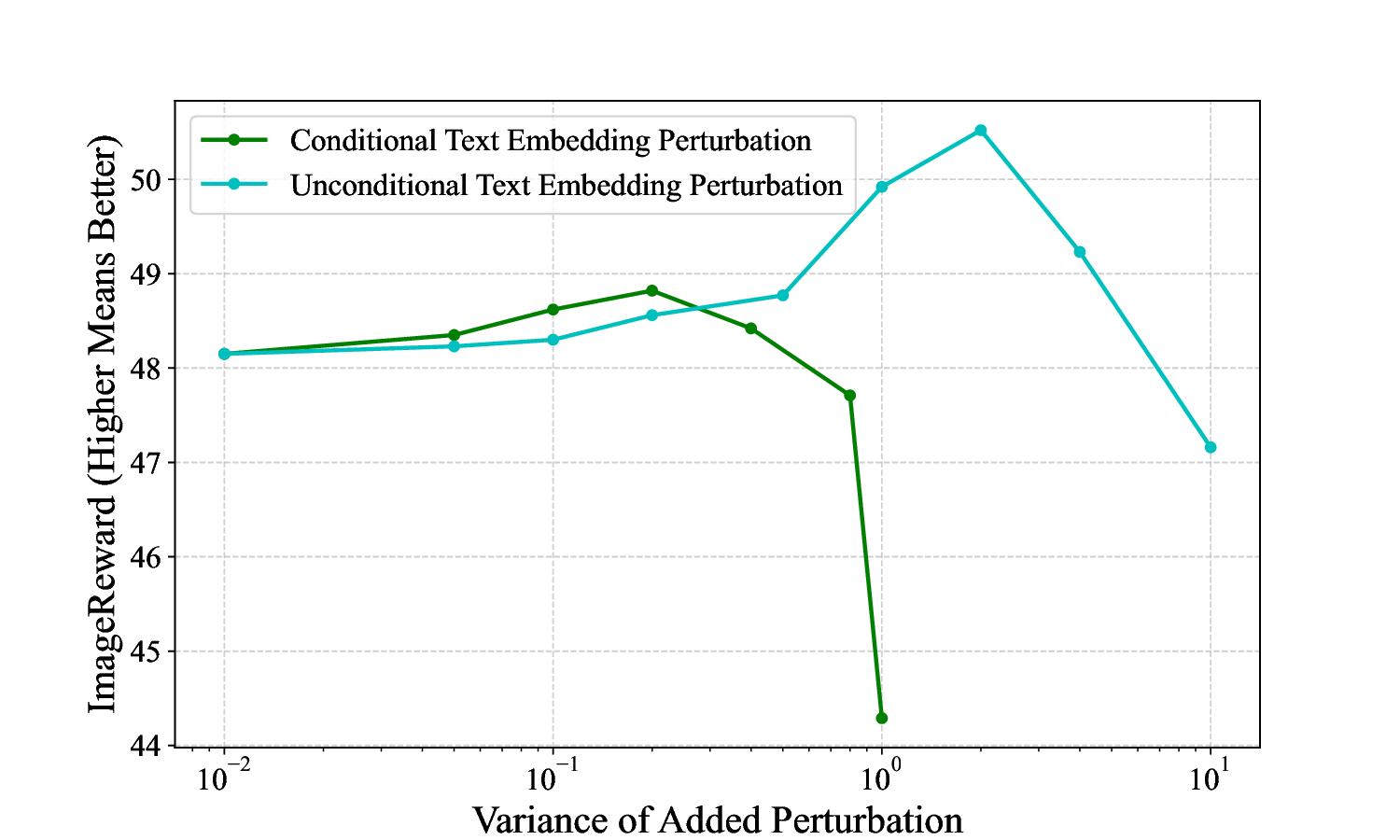
text embedding perturbation, for TTS methods in T2I dif-
fusion models. While recent studies have utilized text em-
bedding perturbation to generate more diverse images [20],
they struggle to maintain visual quality and text faithful-
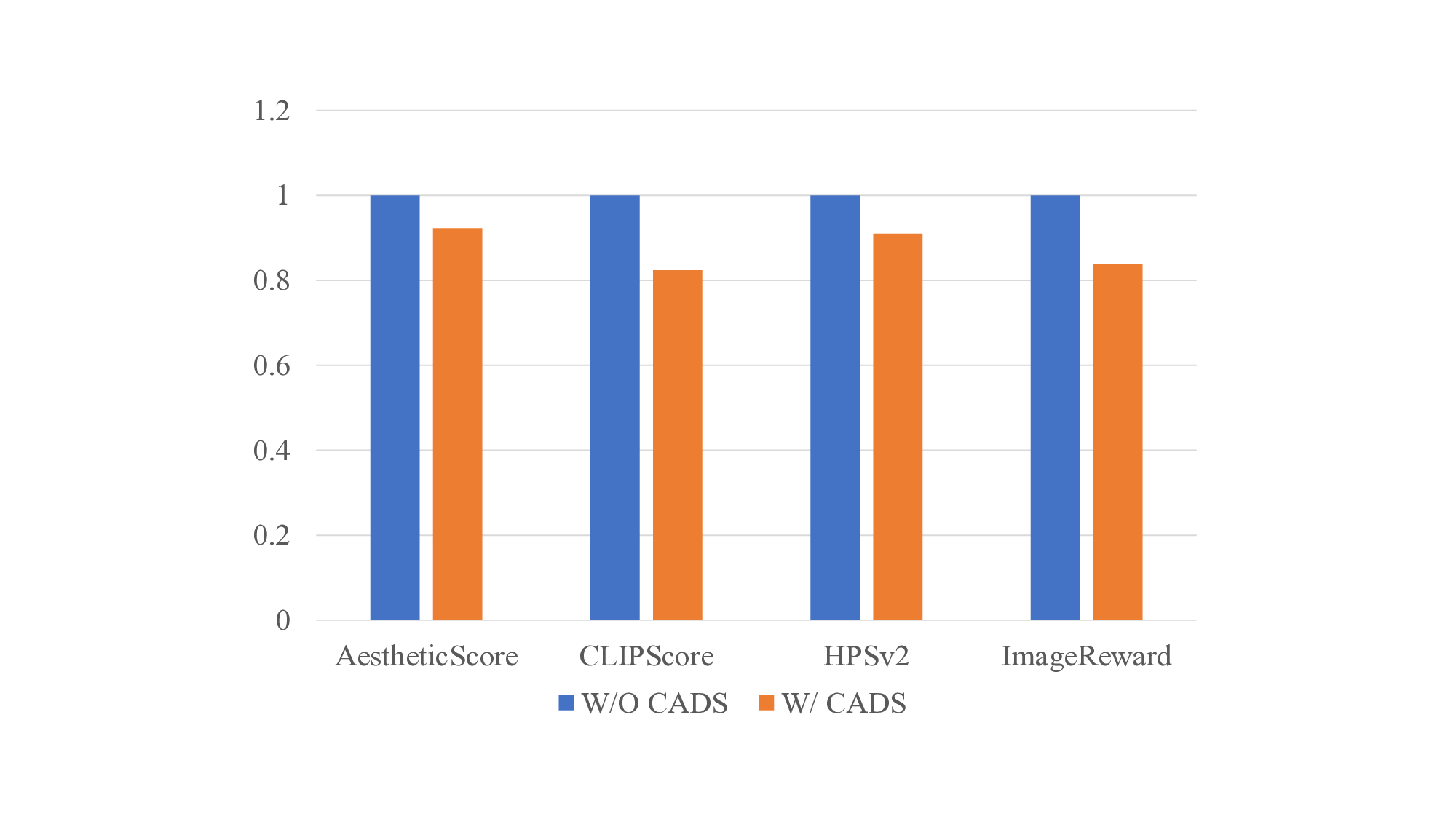
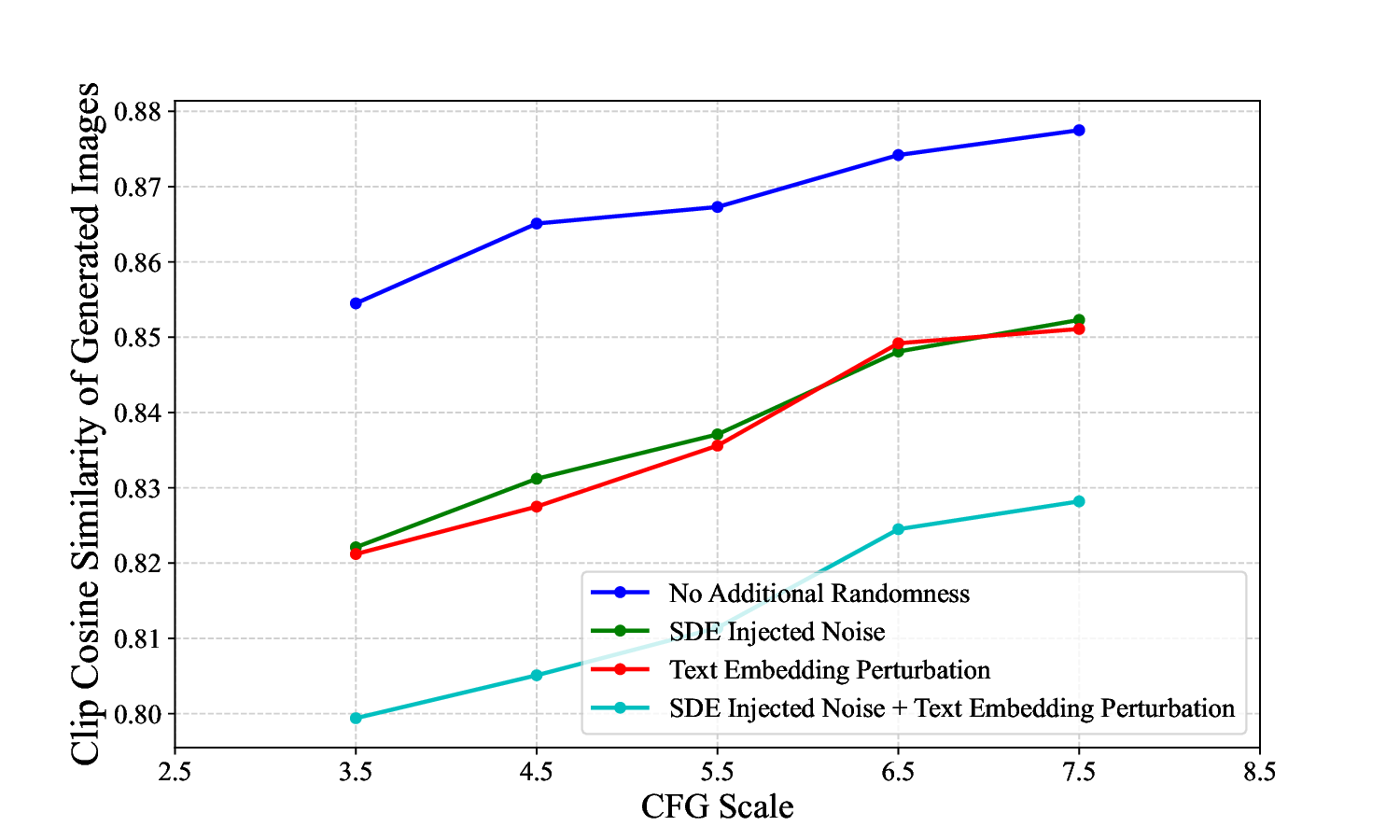
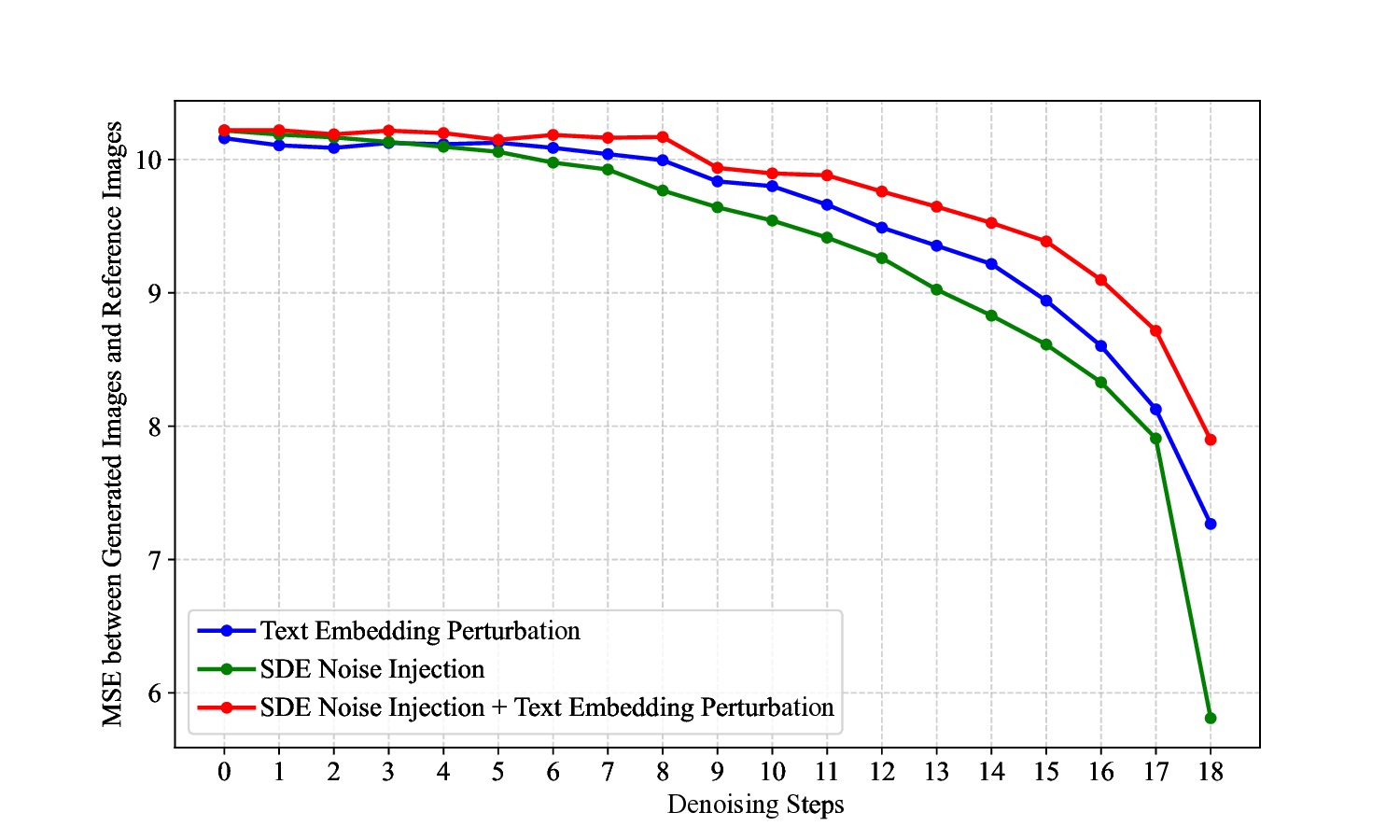
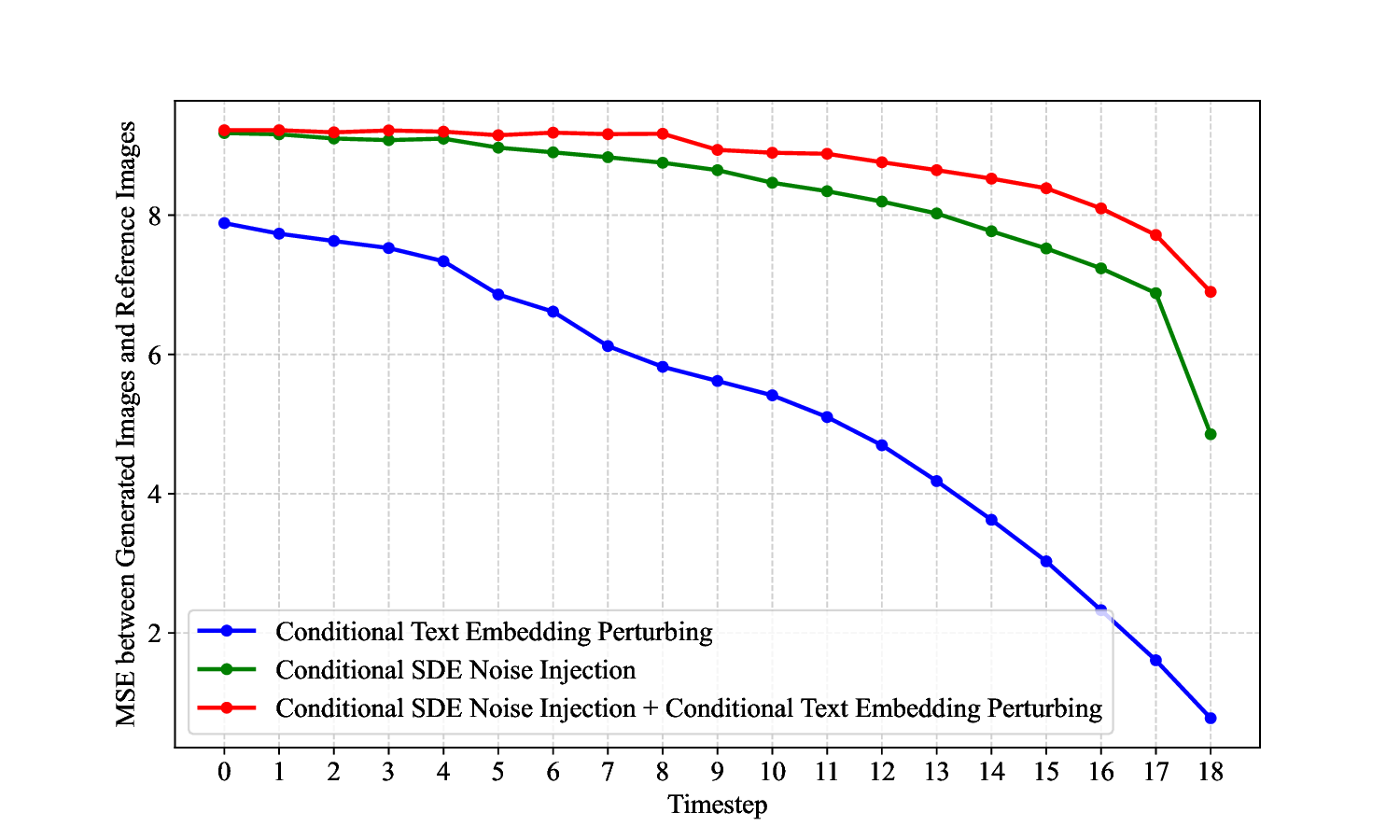
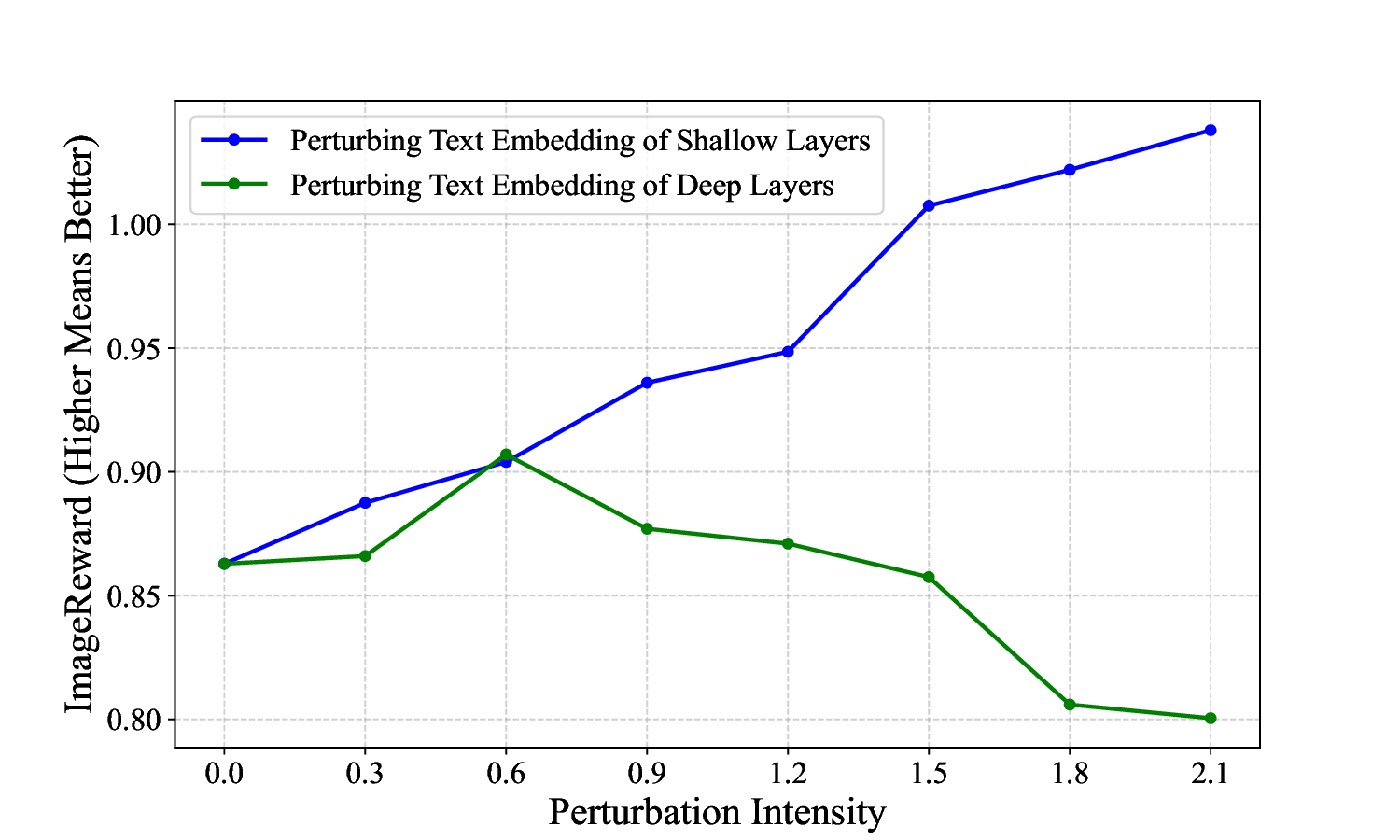
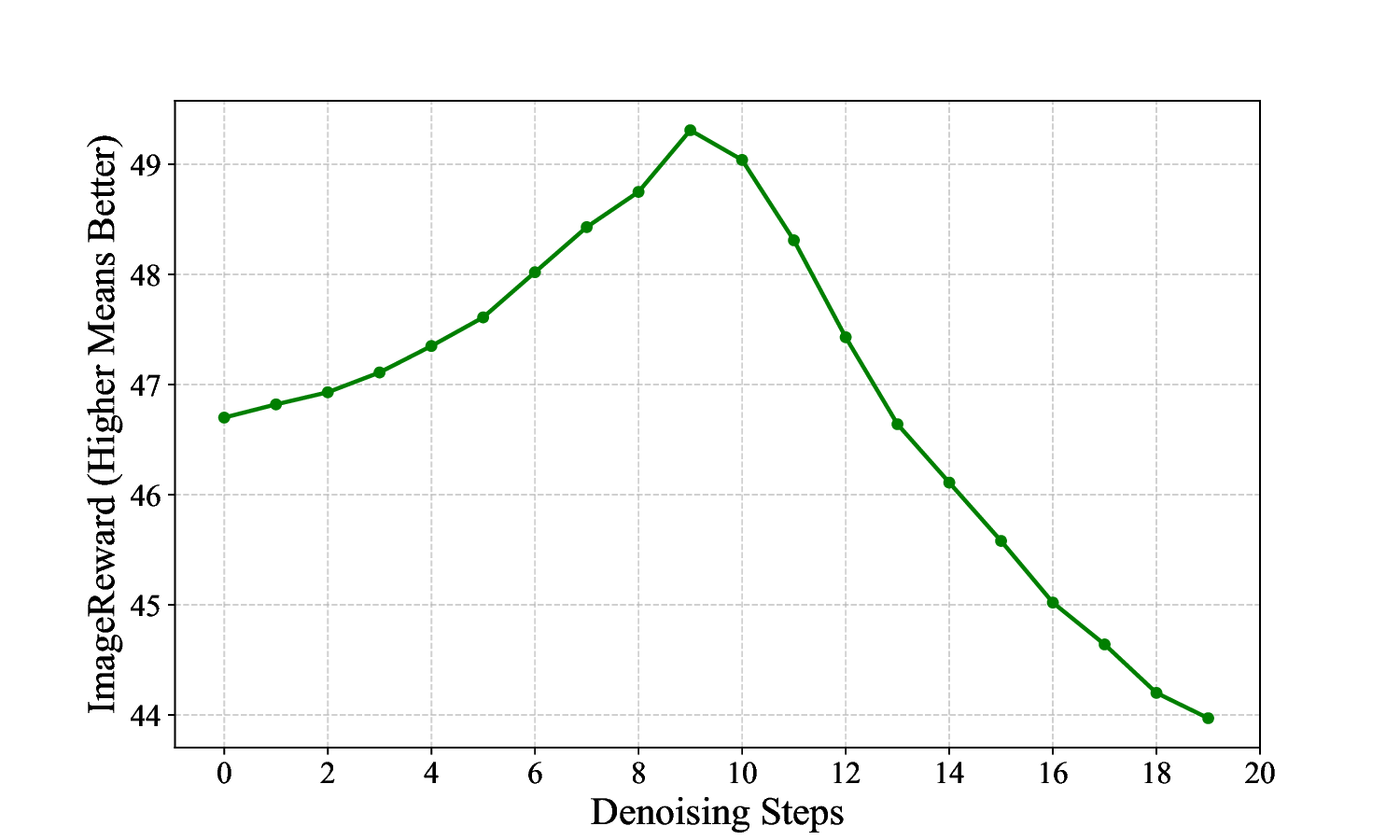
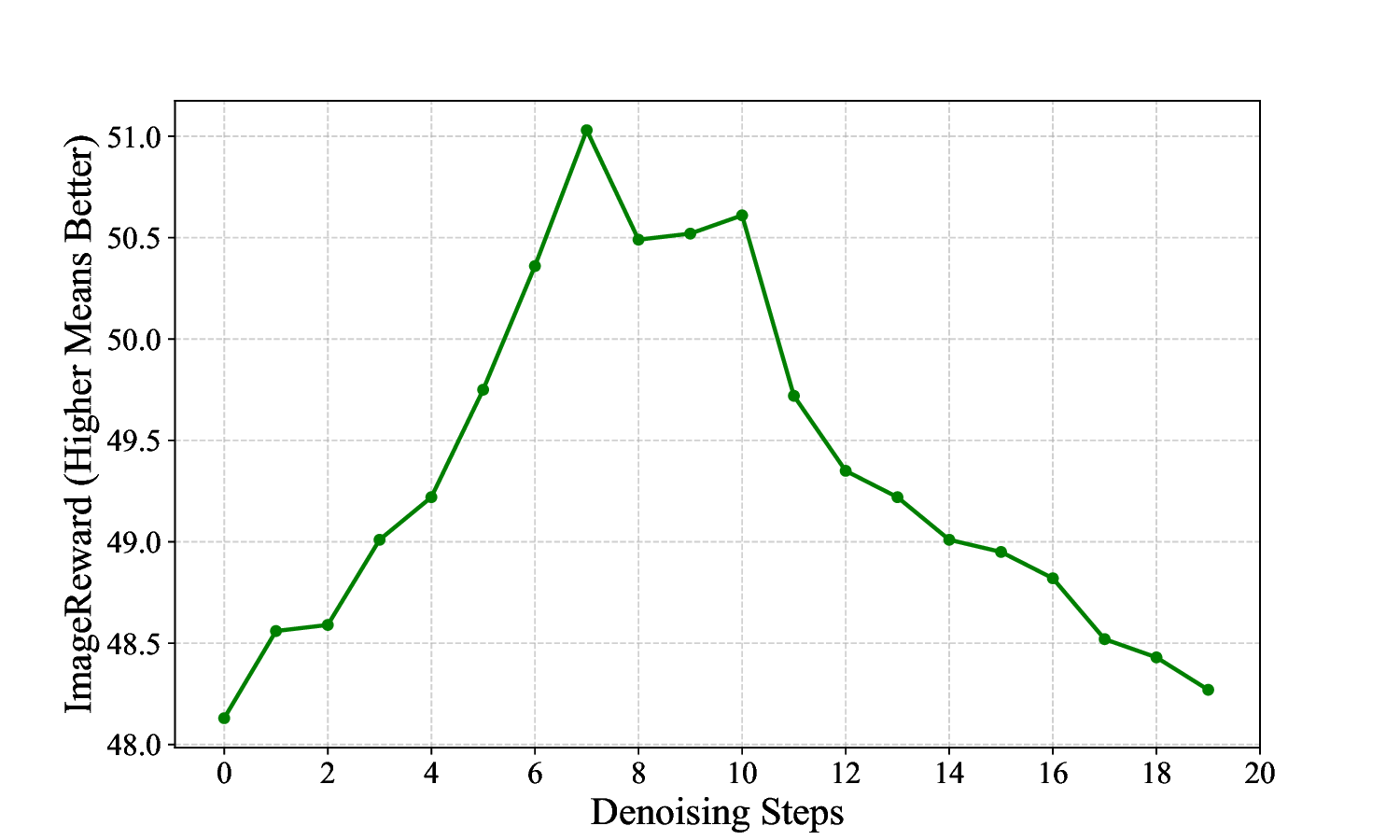
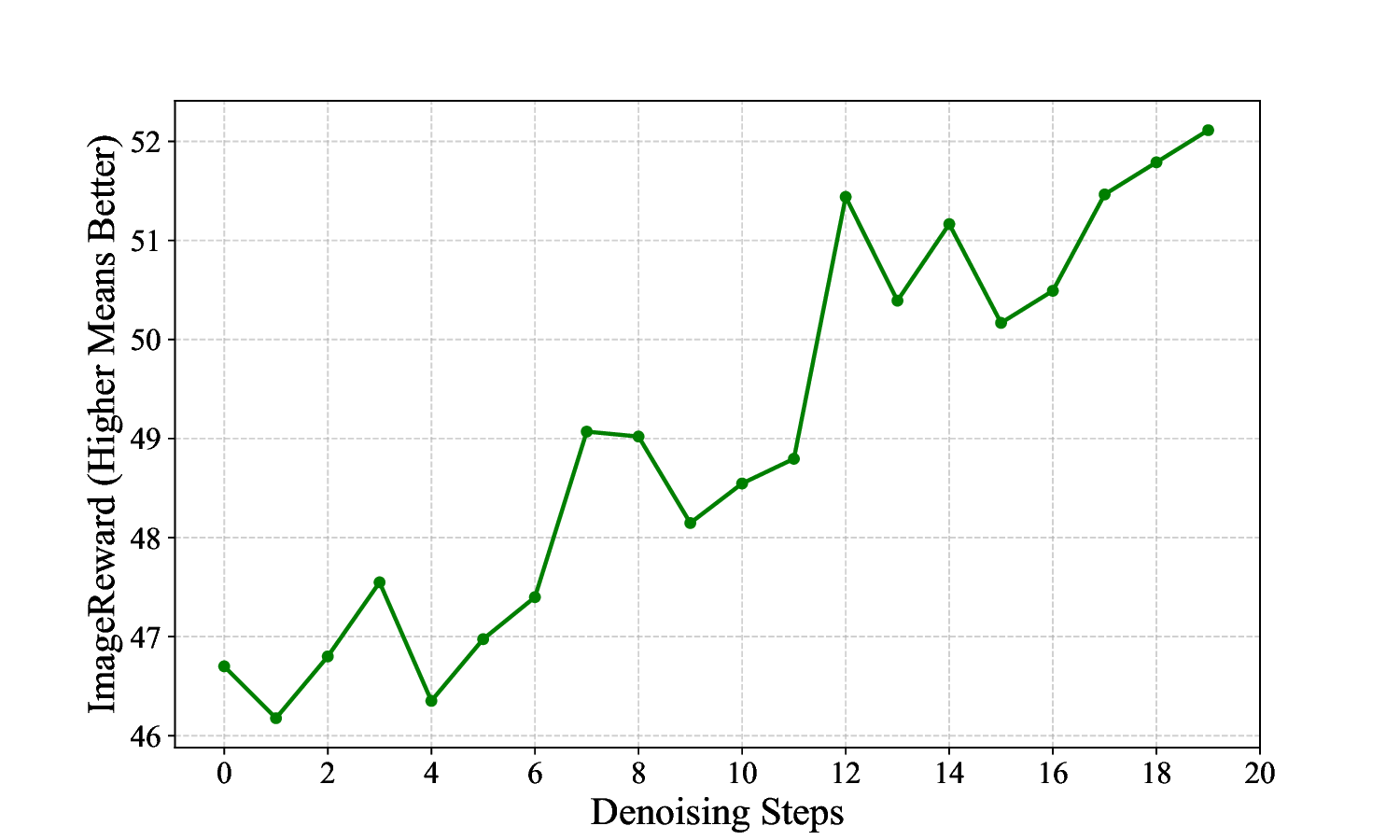
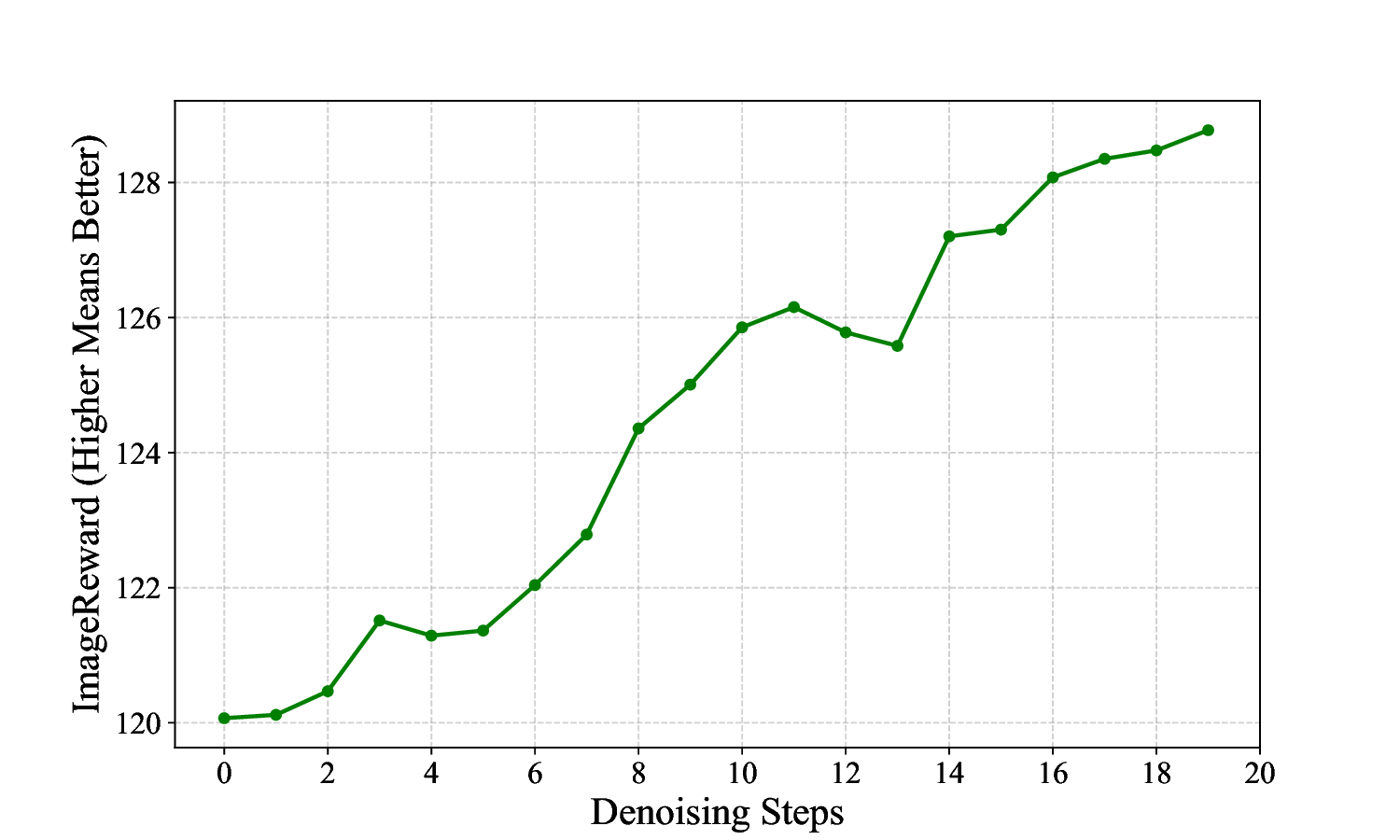
ness, making them unsuitable for TTS methods (see Fig.
2). Our experimental analysis attributes this limitation to
two key factors: (1) poor complementarity between t