Many self-attention sublayers in large language models (LLMs) can be removed with little to no loss. We attribute this to the Attention Suppression Hypothesis: during pre-training, some deep attention layers learn to mute their own contribution, leaving the residual stream and the MLP to carry the representation. We propose Gate-Norm, a one-shot, weight-only criterion that ranks attention sublayers by query--key coupling and removes the least coupled ones, requiring no calibration data, no forward passes, no fine-tuning, and no specialized kernels. On 40-layer, 13B-parameter LLaMA models, Gate-Norm prunes the model in under a second. Pruning $8$--$16$ attention sublayers yields up to $1.30\times$ higher inference throughput while keeping average zero-shot accuracy within $2\%$ of the unpruned baseline across BoolQ, RTE, HellaSwag, WinoGrande, ARC-Easy/Challenge, and OpenBookQA. Across these settings, Gate-Norm matches data-driven pruning methods in accuracy while being $\sim 1000\times$ faster to score layers, enabling practical, data-free compression of LLMs.
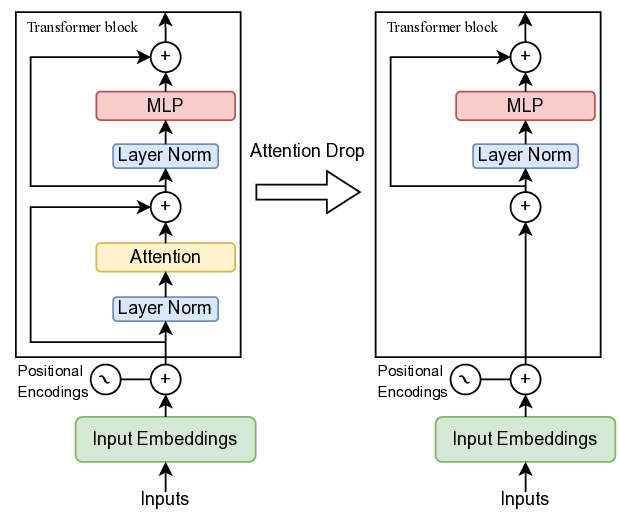
Large language models (LLMs) have grown from millions to hundreds of billions of parameters, providing success in translation, code generation, and reasoning (Brown et al., 2020;Meta-AI, 2023a;OpenAI, 2023). However, this growth increases inference latency, energy consumption, and carbon emissions, driving up deployment costs and environmental impact (Luccioni et al., 2023). To alleviate these burdens, prior work has compressed models along two axes: precision, via quantizing weights to 8, 4, or 2 bits (Frantar et al., 2022;Lin et al., 2024), and width, via weight pruning to remove redundant parameters (Frantar & Alistarh, 2023;Sun et al., 2024;Yin et al., 2023). These approaches, however, deliver significant speed-ups only on hardware with specialized low-precision or sparse-matrix kernels and often require fine-tuning to restore accuracy (Eccles et al., 2025). Meanwhile, the third axis-depth, i.e. the number of layers remains largely under-explored for LLMs. An LLM first maps input tokens to embeddings, then processes them through N Transformer blocks (Vaswani et al., 2017). Each block consists of (i) a multi-head self-attention sublayer that performs token mixing -each token attends to every other token, and (ii) an MLP (a two-layer feed-forward network) that performs channel mixing independently at each token. In LLAMA-7B (Meta-AI, 2023b), for example, an attention layer contains about 67 million parameters, while its MLP layer holds roughly 135 million. Despite having half the parameter count of an MLP layer, attention still dominates runtime -taking nearly twice as long as the MLP at n ≈ 3000 and about three times longer by n ≈ 7000, due to its O(n 2 ) dependence on sequence length n (Figure 1). Attention is clearly the runtime bottleneck. Consequently, pruning even a few attention layers, or dropping entire Transformer blocks, translates directly into substantial inference speed-ups on any hardware.
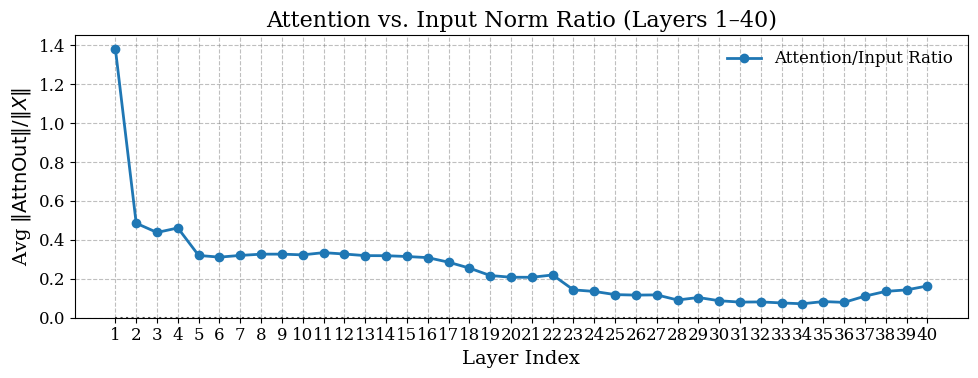
Recent work has targeted structural redundancy (Gromov et al., 2024) instead of weight pruning. SHORTGPT (Men et al., 2024) computes cosine similarity between each block’s input and output on a calibration dataset: high similarity implies the block changes its input minimally and can be removed. However, accuracy drops significantly after pruning more than four blocks. The same similarity test is applied at sublayer granularity (attention vs. MLP), showing that many attention layers are more redundant than MLP layers (He et al., 2024). Crucially, both works mentioned above depend not only on thousands of calibration tokens and multiple forward-passes, but also on grid-searching across diverse datasets (e.g. C4 (Raffel et al., 2020), CodeAlpaca1 , MathInstruct (Yue et al., 2023), and LIMA (Zhou et al., 2023)) to select the corpus that best preserves downstream performance, increasing the compute overhead. In contrast, an ideal data-free criterion -one that inspects only the model’s learned weights -enables instantaneous, on-device pruning without any external data, hyperparameter tuning, or dataset leakage. We ask a deeper question: why do many attention layers contribute so little? We propose the Attention Suppression Hypothesis: during pre-training, deep attention sublayers learn to mute their outputs, producing near-zero updates so the residual connection carries the representation unchanged into the MLP. Crucially, a suppressed attention layer leaves a distinct pattern in its own weights, allowing us to detect redundancy without any data.
Exploiting this insight, we introduce a data-free importance score, Gate-Norm, computed directly from attention weights, which achieves over 1,000× speedup compared to data-driven scoring methods. This millisecond-scale overhead enables practical, on-the-fly pruning in large-scale deployments, whereas calibrationbased methods would be prohibitively slow for ondemand compression. It is to be noted that even in accelerator-free environments, Gate-Norm runs entirely within the limits of system RAM and no GPUs or forward passes are needed. A 13 B-parameter model can be pruned in 30 s on a standard CPU. In contrast, data-driven pipelines require thousands of tokens and repeated forward-passes, rendering them prohibitively slow or infeasible without specialized hardware.
Removing one-third of attention sublayers preserves perplexity within 1% of baseline, improves zero-shot accuracy on BoolQ, RTE, HellaSwag, WinoGrande, ARC-Easy/Challenge, and OpenBookQA, and increases end-to-end throughput by up to 1.4×.
In summary, our key contributions are as follows:
• We formulate the Attention Suppression Hypothesis, explaining why deep self-attention sublayers become functionally inert.
• We propose the first fully data-free, millisecond-scale importance score for attention layers and a one-shot pruning algorithm.
• We validate our approach on large LLAMA checkpoints, achieving substantial latency reductions while preserving baseline perplexity and zero-shot performance.
We
This content is AI-processed based on open access ArXiv data.