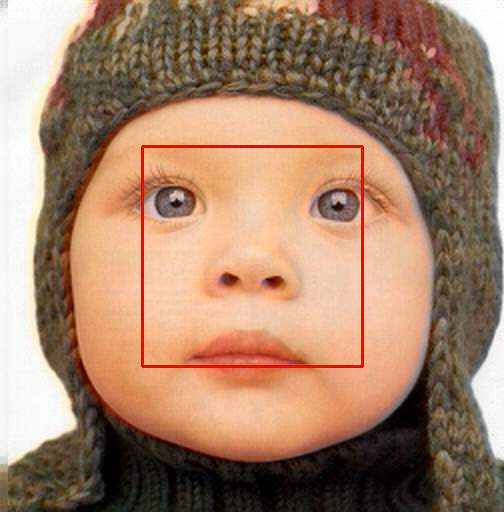
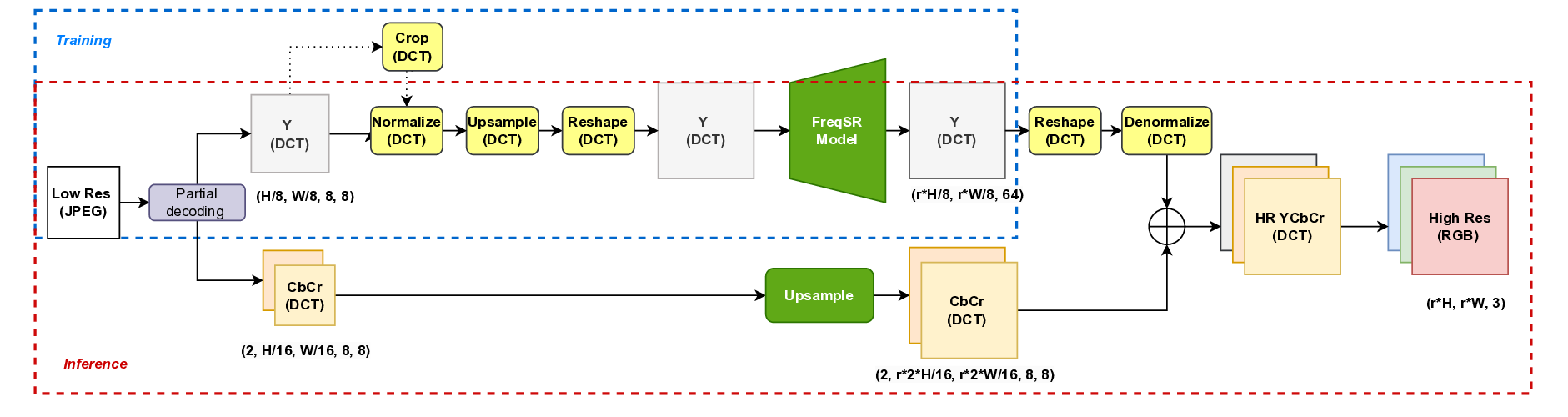
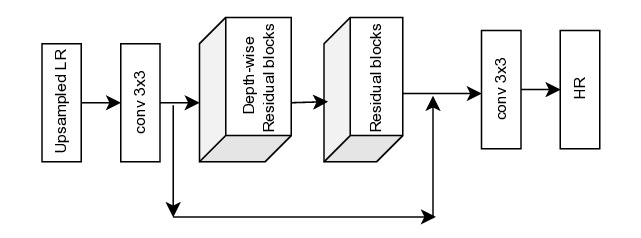
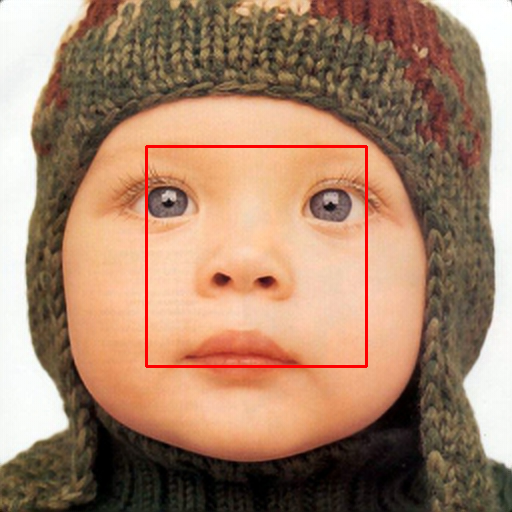
Title: Learning Single-Image Super-Resolution in the JPEG Compressed Domain
ArXiv ID: 2512.04284
Date: 2025-12-03
Authors: Sruthi Srinivasan, Elham Shakibapour, Rajy Rawther, Mehdi Saeedi
📝 Abstract
Deep learning models have grown increasingly complex, with input data sizes scaling accordingly. Despite substantial advances in specialized deep learning hardware, data loading continues to be a major bottleneck that limits training and inference speed. To address this challenge, we propose training models directly on encoded JPEG features, reducing the computational overhead associated with full JPEG decoding and significantly improving data loading efficiency. While prior works have focused on recognition tasks, we investigate the effectiveness of this approach for the restoration task of single-image super-resolution (SISR). We present a lightweight super-resolution pipeline that operates on JPEG discrete cosine transform (DCT) coefficients in the frequency domain. Our pipeline achieves a 2.6x speedup in data loading and a 2.5x speedup in training, while preserving visual quality comparable to standard SISR approaches.
💡 Deep Analysis
📄 Full Content
LEARNING SINGLE-IMAGE SUPER-RESOLUTION IN THE JPEG COMPRESSED
DOMAIN
Sruthi Srinivasan, Elham Shakibapour, Rajy Rawther, Mehdi Saeedi
Advanced Micro Devices, Inc.
ABSTRACT
Deep learning models have grown increasingly complex, with input data sizes scaling accordingly. Despite substantial
advances in specialized deep learning hardware, data loading continues to be a major bottleneck that limits training
and inference speed. To address this challenge, we propose training models directly on encoded JPEG features,
reducing the computational overhead associated with full JPEG decoding and significantly improving data loading
efficiency. While prior works have focused on recognition tasks, we investigate the effectiveness of this approach for
the restoration task of single-image super-resolution (SISR). We present a lightweight super-resolution pipeline that
operates on JPEG discrete cosine transform (DCT) coefficients in the frequency domain. Our pipeline achieves a 2.6x
speedup in data loading and a 2.5x speedup in training, while preserving visual quality comparable to standard SISR
approaches.
Index Terms— Data Loading Acceleration, Frequency Domain, Image Super-Resolution, JPEG Compression
1. INTRODUCTION
The efficiency of deep learning pipelines hinges on how quickly input data is processed. In image-based tasks, neural
networks rely on RGB pixels, matching common display formats. However, images are often stored in compressed
formats such as JPEG, requiring reading and preprocessing, also known as data loading [1]. Due to the increased
complexity and size of image datasets, inefficiencies in the data-loading phase are particularly important [2]. In the
regular data-loading pipeline, CPU reads input images from disk, decodes them from formats like JPEG, and applies
preprocessing before transferring data to the GPU to be used for training or inference. This process can lead to under-
utilization of GPU resources, as the CPU struggles to keep pace with the training speed, contributing to data loading
inefficiencies that can account for up to 40% of the epoch time [1].
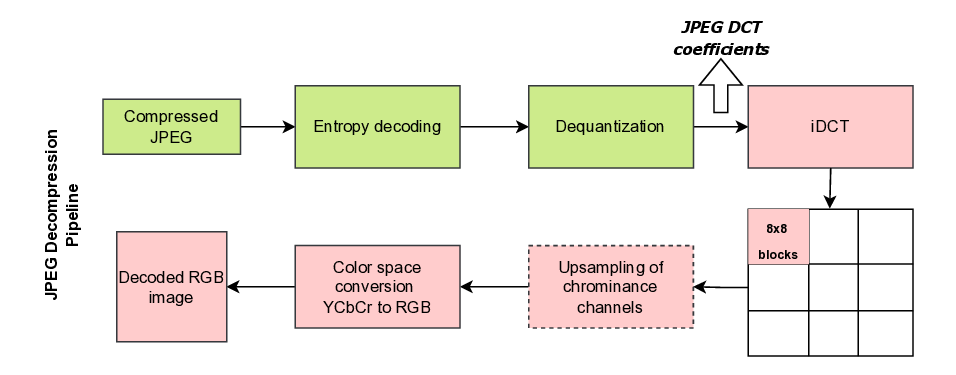
Restoring RGB images from JPEG-compressed data involves reversing the JPEG compression process. A core com-
ponent of this is frequency-domain transformation using DCT as specified in the JPEG standard (ISO/IEC 10918-
1:1993). This lossy compression format is widely adopted in digital imaging. By leveraging the frequency-domain
DCT coefficients directly, we can bypass the computationally expensive decoding step required to convert JPEG data
into RGB format (Fig. 1). This approach accelerates the data loading process and optimizes the entire end-to-end
training pipeline. Directly using the frequency-domain coefficients also allows deep learning models to operate on a
compressed representation that is 1/8th the size of the original RGB image in both height and width, further reducing
memory and computational requirements.
Although frequency-domain deep learning has proven effective for recognition tasks [3, 4], its application to pixel-level
restoration tasks like super-resolution remains underexplored. Extending frequency-domain learning to single-image
super-resolution (SISR) requires reconstructing high-resolution (HR) images from low-resolution (LR) inputs, which
demands finer precision for texture and detail reconstruction compared to recognition tasks. Deep learning-based SISR
approaches include CNN-based [5, 6], transformer-based [7, 8], and GAN-based methods [9]. Among them, CNN-
based methods offer a balance in speed and quality [10], making them suitable for resource-constrained environments
– a use case targeted in our study.
In this paper, we propose a lightweight CNN-based SISR pipeline that operates directly on JPEG discrete cosine trans-
form (DCT) coefficients, eliminating the need for full decoding to RGB. This design significantly reduces data loading
overhead and accelerates end-to-end training while maintaining competitive super-resolution quality. In summary, our
contributions are two-fold (1) A lightweight SISR pipeline designed for JPEG-DCT frequency-domain inputs, en-
abling fast data loading, accelerated end-to-end training, and efficient inference. (2) An evaluation of quality and
speed trade-offs in frequency-domain SISR using JPEG-DCT coefficients.
arXiv:2512.04284v1 [cs.CV] 3 Dec 2025
Compressed
JPEG
Entropy decoding
Dequantization
iDCT
8x8
blocks
Upsampling of
chrominance
channels
Color space
conversion
YCbCr to RGB
Decoded RGB
image
JPEG Decompression
Pipeline
JPEG DCT
coefficients
Fig. 1. JPEG decompression pipeline showing the use of DCT coefficients without full decoding to RGB image.
2. RELATED WORK
The increasing size of datasets and complexity of deep learning models have motivated research into training accelera-
tion. Model-level optimizations such as depthwise separable convolutions [11], factorized convolutions [12], quantiza-
tion [13], and low-rank approximations [14] have demonstrated substantial red