Title: Scalable Decision Focused Learning via Online Trainable Surrogates
ArXiv ID: 2512.03861
Date: 2025-12-03
Authors: ** Gaetano Signorelli, Michele Lombardi – University of Bologna (이탈리아) **
📝 Abstract
Decision support systems often rely on solving complex optimization problems that may require to estimate uncertain parameters beforehand. Recent studies have shown how using traditionally trained estimators for this task can lead to suboptimal solutions. Using the actual decision cost as a loss function (called Decision Focused Learning) can address this issue, but with a severe loss of scalability at training time. To address this issue, we propose an acceleration method based on replacing costly loss function evaluations with an efficient surrogate. Unlike previously defined surrogates, our approach relies on unbiased estimators reducing the risk of spurious local optima and can provide information on its local confidence allowing one to switch to a fallback method when needed. Furthermore, the surrogate is designed for a black-box setting, which enables compensating for simplifications in the optimization model and accounting for recourse actions during cost computation. In our results, the method reduces costly inner solver calls, with a solution quality comparable to other state-of-the-art techniques.
💡 Deep Analysis
📄 Full Content
SCALABLE DECISION FOCUSED LEARNING VIA ON-
LINE TRAINABLE SURROGATES
Gaetano Signorelli and Michele Lombardi
University of Bologna
{gaetano.signorelli2, michele.lombardi2}@unibo.it
ABSTRACT
Decision support systems often rely on solving complex optimization problems that
may require to estimate uncertain parameters beforehand. Recent studies have shown
how using traditionally trained estimators for this task can lead to suboptimal solutions.
Using the actual decision cost as a loss function (called Decision Focused Learning)
can address this issue, but with a severe loss of scalability at training time. To address
this issue, we propose an acceleration method based on replacing costly loss function
evaluations with an efficient surrogate. Unlike previously defined surrogates, our ap-
proach relies on unbiased estimators – reducing the risk of spurious local optima – and
can provide information on its local confidence – allowing one to switch to a fallback
method when needed. Furthermore, the surrogate is designed for a black-box setting,
which enables compensating for simplifications in the optimization model and account-
ing for recourse actions during cost computation. In our results, the method reduces
costly inner solver calls, with a solution quality comparable to other state-of-the-art
techniques.
1
INTRODUCTION
Many real-world decision support systems, in domains such as logistics or production planning,
rely on the solution of constrained optimization problems with parameters that are estimated via
Machine Learning (ML) predictors. Literature from the last decade has showed how this approach,
sometimes referred to as Prediction Focused Learning (PFL), can lead to poor decision quality due
to a misalignment between the training objective (usually likelihood maximization) and the actual
decision cost. Decision Focused Learning (DFL) (Amos & Kolter, 2017; Elmachtoub & Grigas,
2022) was then introduced to correct for this issue by training predictors for minimal decision regret.
While remarkable progress in the field has been made (Mandi et al., 2024), we argue that, based
on our experience with industrial optimization use cases, three issues still prevent DFL from finding
widespread practical application. First, while DFL methods are very efficient at inference time, their
training scalability is often severely limited, since the problems encountered in decision support are
frequently difficult (NP-hard or worse) and most DFL approaches require frequent solver calls and
cost evaluations. Second, many DFL methods make restrictive assumptions on the decision problem
(e.g. linear cost function, no parameters in the constraints); in addition to limiting applicability, it
has been shown (Hu et al., 2022; Elmachtoub et al., 2023) that such assumptions also cause the DFL
advantage to vanish if the parameters expectations can be accurately estimated (section A). Third,
several DFL methods require explicit knowledge of the problem structure or the solver state, which
in a practical setting would require costly refactoring of the existing tools, or even a radical change
of the solution technology. Solving these issues would allow one to use DFL for improving the
effectiveness and robustness of any real-world decision support tool, while maintaining scalability.
We aim at making a significant step toward addressing these limitations, by relying on a carefully
designed, efficient, surrogate to replace most solver calls at training time. Our surrogate is suitable
1
arXiv:2512.03861v1 [cs.LG] 3 Dec 2025
for a black-box setting, where no restrictive assumption is made on regret computation and no access
to the solver state is needed. Compared to the relevant state of the art: 1) our surrogate is an
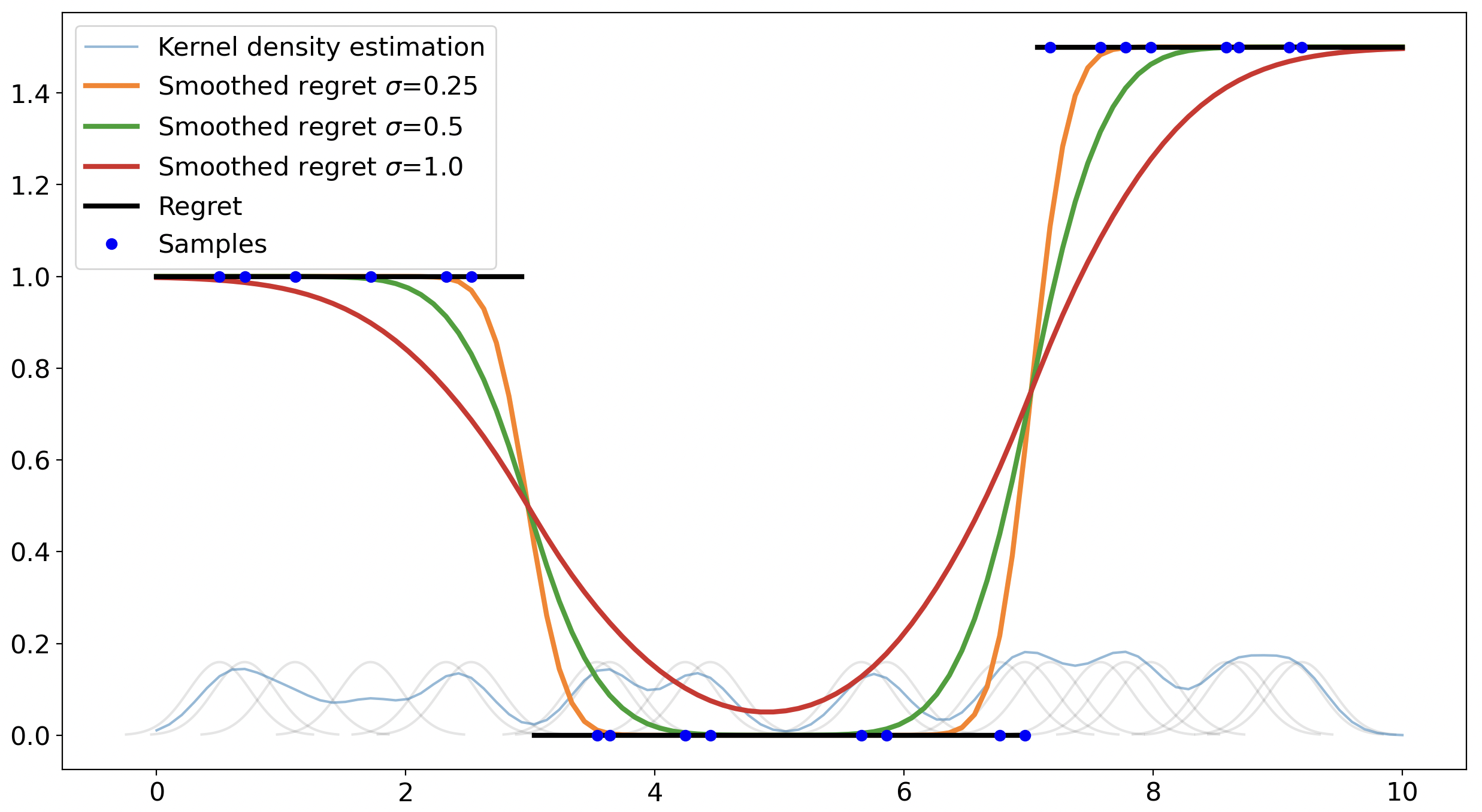
asymptotically unbiased regret estimator, i.e. with no irreducible approximation error; 2) we use a
principled mechanism (stochastic smoothing and importance sampling) to address 0-gradients often
occurring in DFL settings; 3) we include uncertainty quantification via a confidence level, used to
decide when to dynamically update the surrogate based on samples generated by a fallback method.
Only a few of the existing DFL methods can be applied to achieve similar goals, a representative
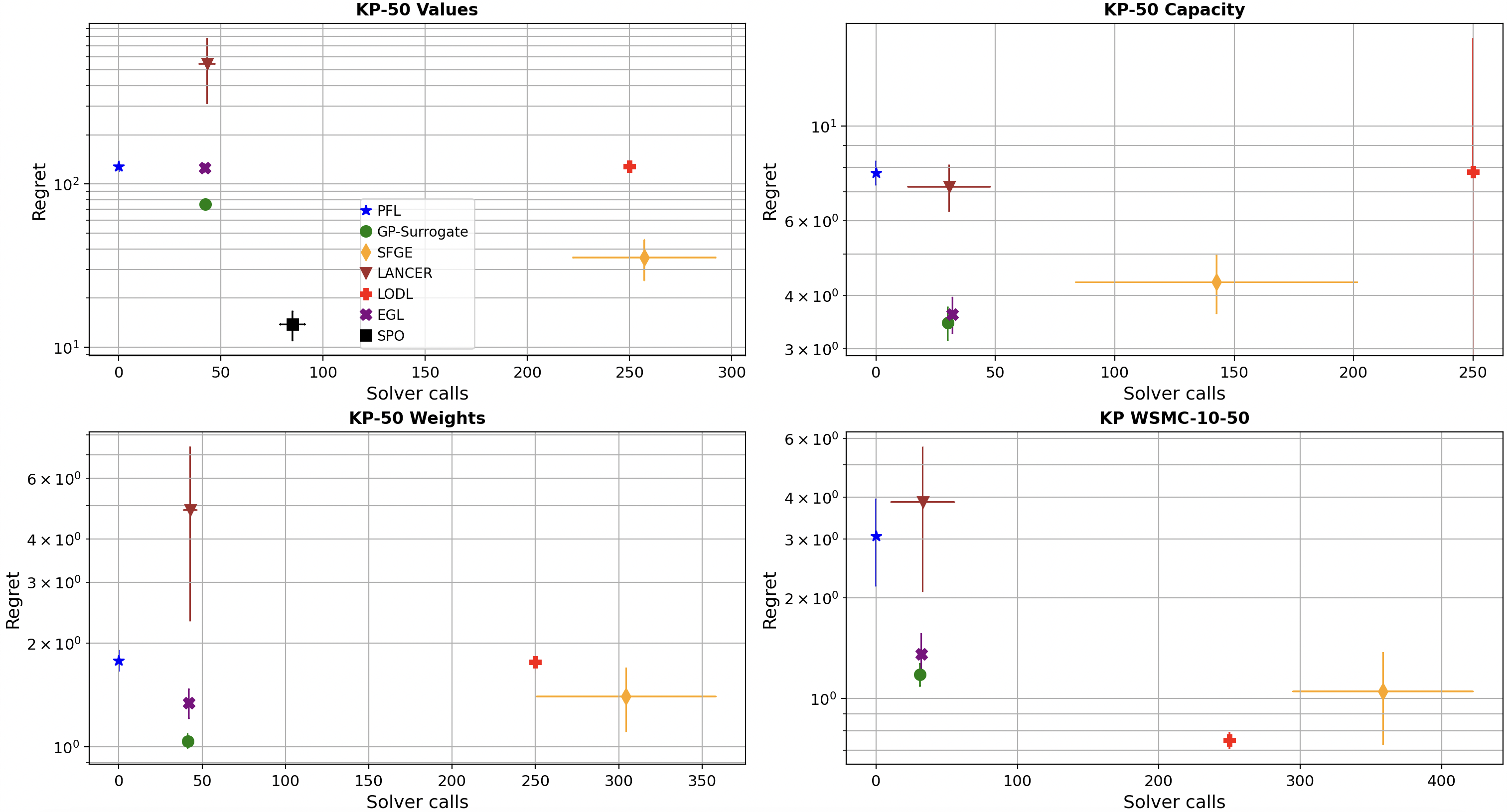
set of which is used as a baseline in our empirical evaluation. We design our experiments to assess
the scalability and effectiveness of our method in a controlled setting, by comparing DFL and PFL
on extended versions of standard benchmarks in the current literature. We emphasize problems
with recourse actions and/or non-linearities, since they represent the settings where the benefits of
DFL over PFL are robust even when accurate predictions can be obtained. We allow for scaling the
problem complexity, to assess how the evaluated approaches behave on problems of different size
(in terms of number of variables or parameters). In our results, our surrogate significantly reduces
both the training runtime and the number of solver calls and c