Vision-Language Models (VLMs) deployed in safety-critical applications such as autonomous driving must handle continuous visual streams under imperfect conditions. However, existing benchmarks focus on static, high-quality images and ignore temporal degradation and error propagation, which are critical failure modes where transient visual corruption induces hallucinations that persist across subsequent frames. We introduce DIQ-H, the first benchmark for evaluating VLM robustness under dynamic visual degradation in temporal sequences. DIQ-H applies physics-based corruptions including motion blur, sensor noise, and compression artifacts, and measures hallucination persistence, error recovery, and temporal consistency through multi-turn question-answering tasks. To enable scalable annotation, we propose Uncertainty-Guided Iterative Refinement (UIR), which generates reliable pseudo-ground-truth using lightweight VLMs with uncertainty filtering, achieving a 15.3 percent accuracy improvement. Experiments on 16 state-of-the-art VLMs reveal substantial robustness gaps: even advanced models such as GPT-4o achieve only a 78.5 percent recovery rate, while open-source models struggle with temporal consistency at less than 60 percent. DIQ-H provides a comprehensive platform for evaluating VLM reliability in real-world deployments.
💡 Deep Analysis
📄 Full Content
1
DIQ-H: Evaluating Hallucination Persistence in
VLMs Under Temporal Visual Degradation
Zexin Lin1,3,∗, Hawen Wan1,3,∗, Yebin Zhong1,3, and Xiaoqiang Ji1,2,3,†
Abstract—Vision-Language Models (VLMs) deployed in safety-
critical applications like autonomous driving must handle con-
tinuous visual streams under imperfect conditions. However,
existing benchmarks focus on static, high-quality images, ignoring
temporal degradation and error propagation—critical failure
modes where transient visual corruption induces hallucinations
that persist across subsequent frames. We introduce DIQ-H,
the first benchmark evaluating VLM robustness under dynamic
visual degradation in temporal sequences. DIQ-H applies physics-
based corruptions (motion blur, sensor noise, compression arti-
facts) and measures hallucination persistence, error recovery, and
temporal consistency through multi-turn Q&A tasks. To enable
scalable annotation, we propose Uncertainty-Guided Iterative
Refinement (UIR), which generates reliable pseudo-ground-truth
via lightweight VLMs with uncertainty filtering, achieving 15.3%
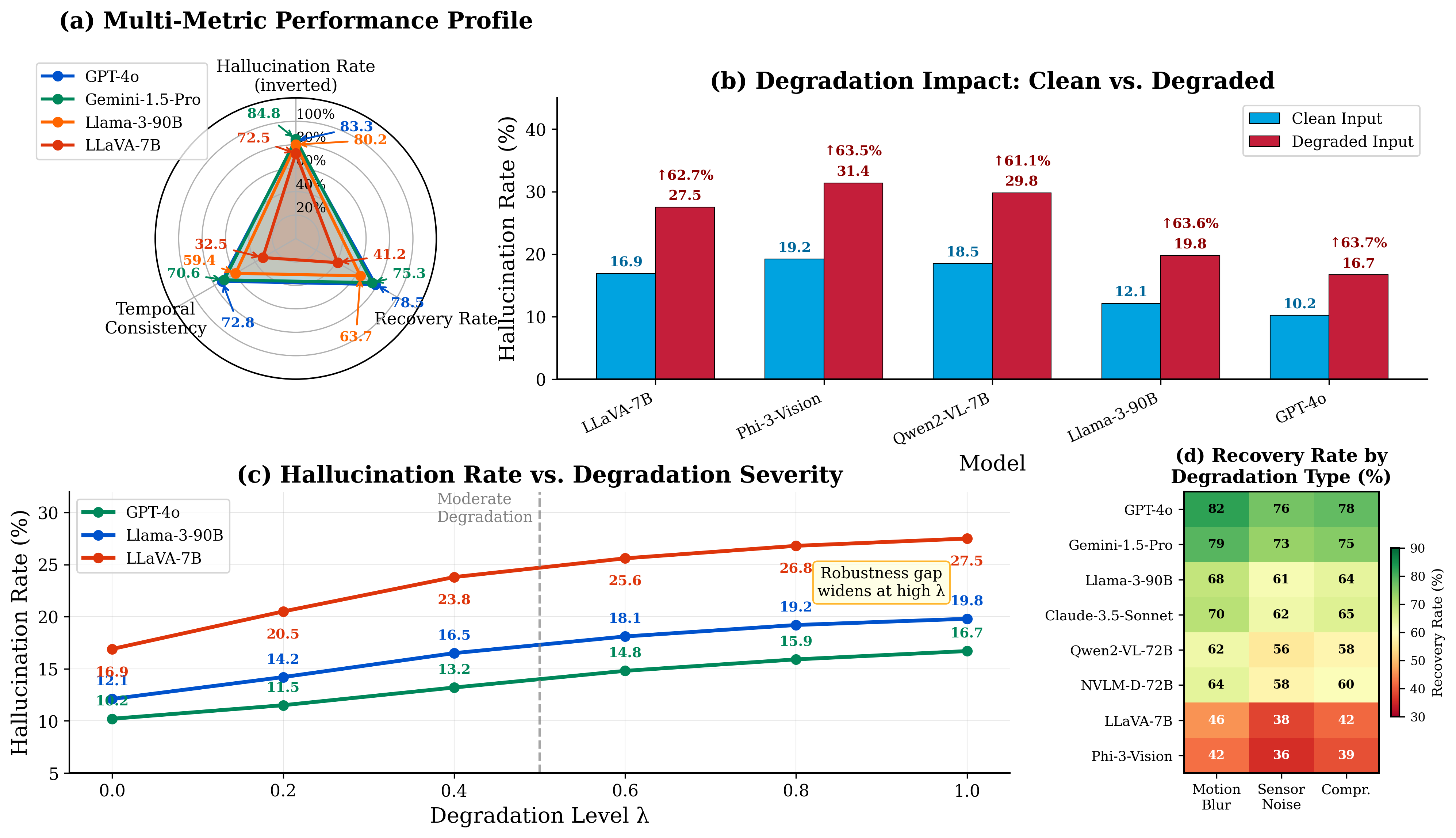
accuracy improvement. Experiments on 16 state-of-the-art VLMs
reveal significant robustness gaps: even top models like GPT-
4o show only 78.5% recovery rate, while open-source models
struggle with temporal consistency (<60%). DIQ-H provides a
comprehensive platform for evaluating VLM reliability in real-
world deployments.
Index Terms—Large Vision-Language Models, Error Propa-
gation, Automated Annotation, Multimodal Benchmarking, Ro-
bustness Evaluation
I. INTRODUCTION
Vision-Language Models (VLMs) are increasingly deployed
in safety-critical applications such as autonomous driving and
robotic manipulation, where they must interpret continuous
visual streams under imperfect conditions. A fundamental
challenge is hallucination—the tendency to fabricate non-
existent objects or attributes—which becomes particularly
dangerous when errors compound over time in sequential
reasoning tasks.
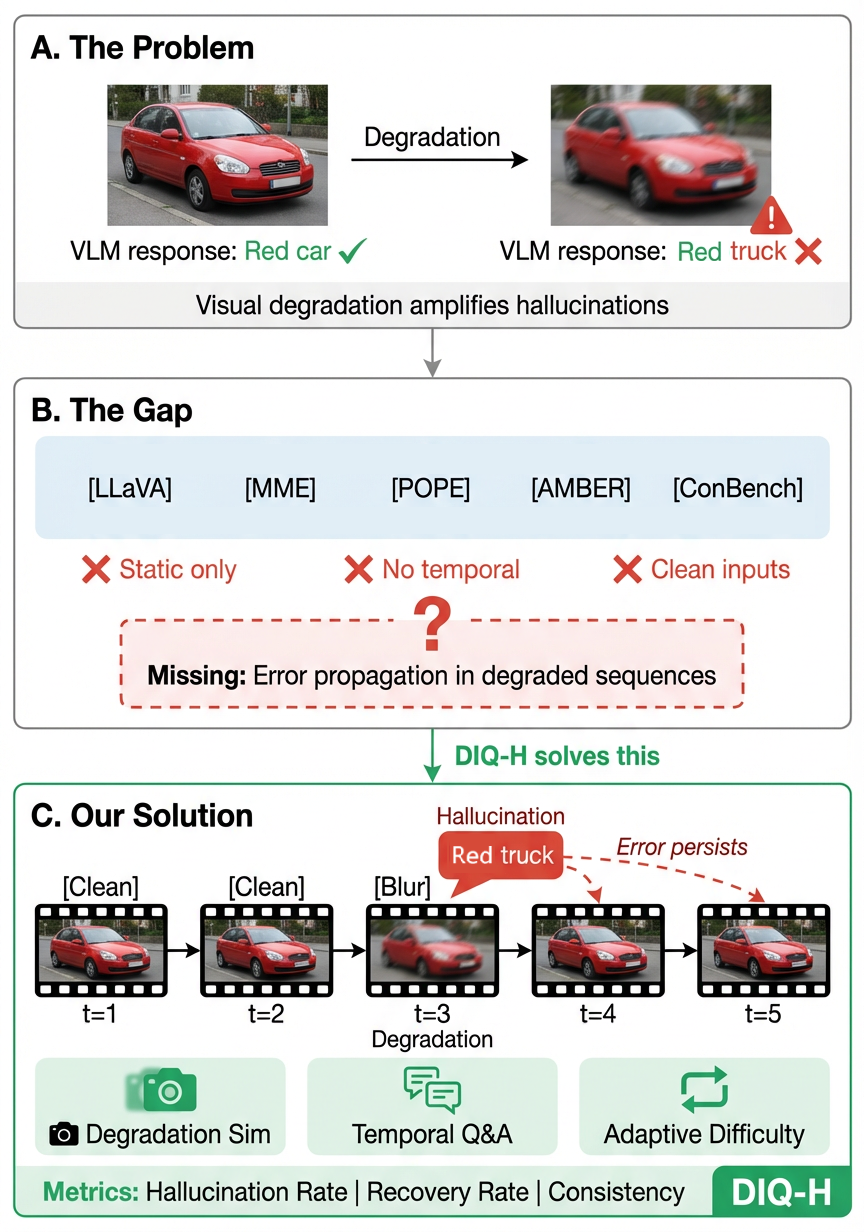
Limitations of Existing Benchmarks. Current evaluation
paradigms suffer from three critical gaps: (1) Static focus:
Benchmarks like LLaVA-Bench [1] and MME [2] assess only
single-frame understanding; (2) Temporal blindness: Halluci-
nation benchmarks (POPE [3], AMBER [4]) evaluate isolated
responses without modeling error propagation; (3) Idealized
inputs: Video benchmarks (ConBench [5]) assume pristine
quality, ignoring real-world degradation from motion blur, sen-
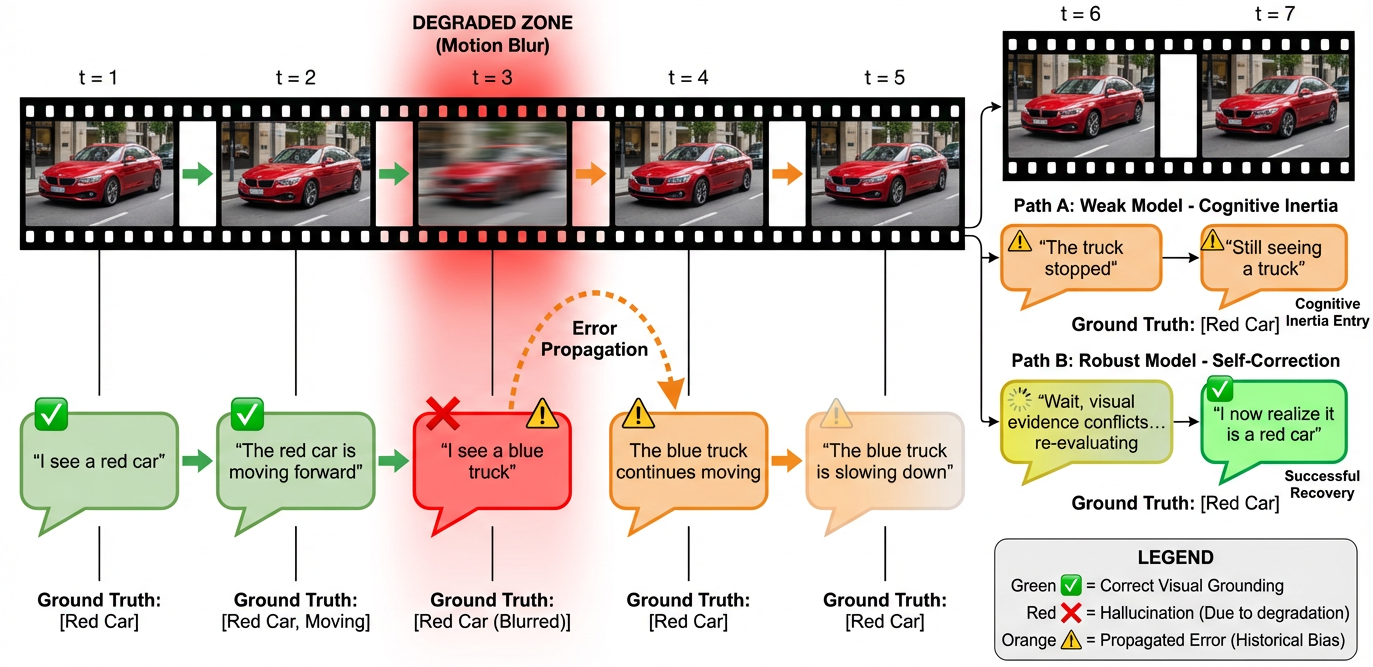
sor noise, and compression artifacts. These limitations obscure
a critical failure mode: cognitive inertia, where hallucinations
1The School of Science and Engineering, The Chinese University of Hong
Kong, Shenzhen, China.
2The School of Artificial Intelligence, The Chinese University of Hong
Kong, Shenzhen, China.
3The Shenzhen Institute of Artificial Intelligence and Robotics for Society
Shenzhen, China.
†Corresponding
author
is
Xiaoqiang
Ji
whose
e-mail
is
jixiaoqiang@cuhk.edu.cn.
Fig. 1.
Overview of motivation and approach. (a) VLMs hallucinate under
degradation. (b) Existing benchmarks ignore temporal error propagation.
(c) DIQ-H evaluates hallucination persistence and recovery under dynamic
degradation.
induced by transient degradation persist even after visual
quality recovers.
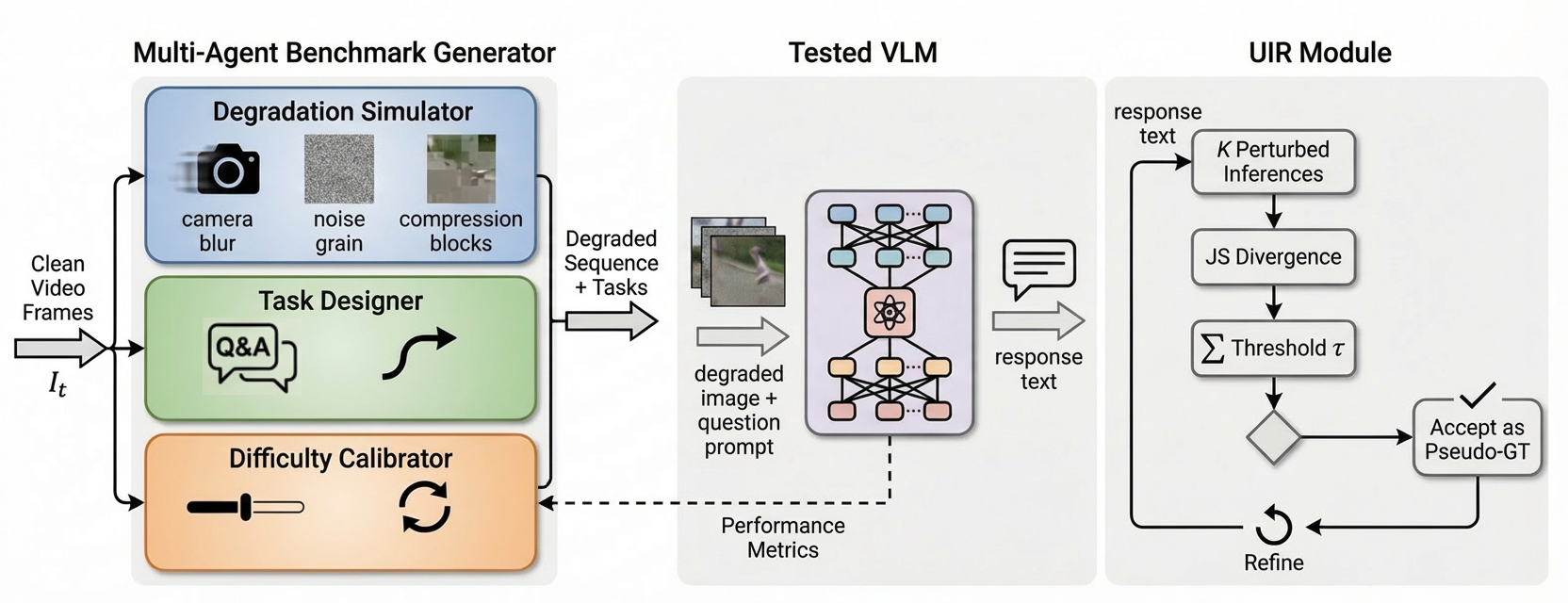
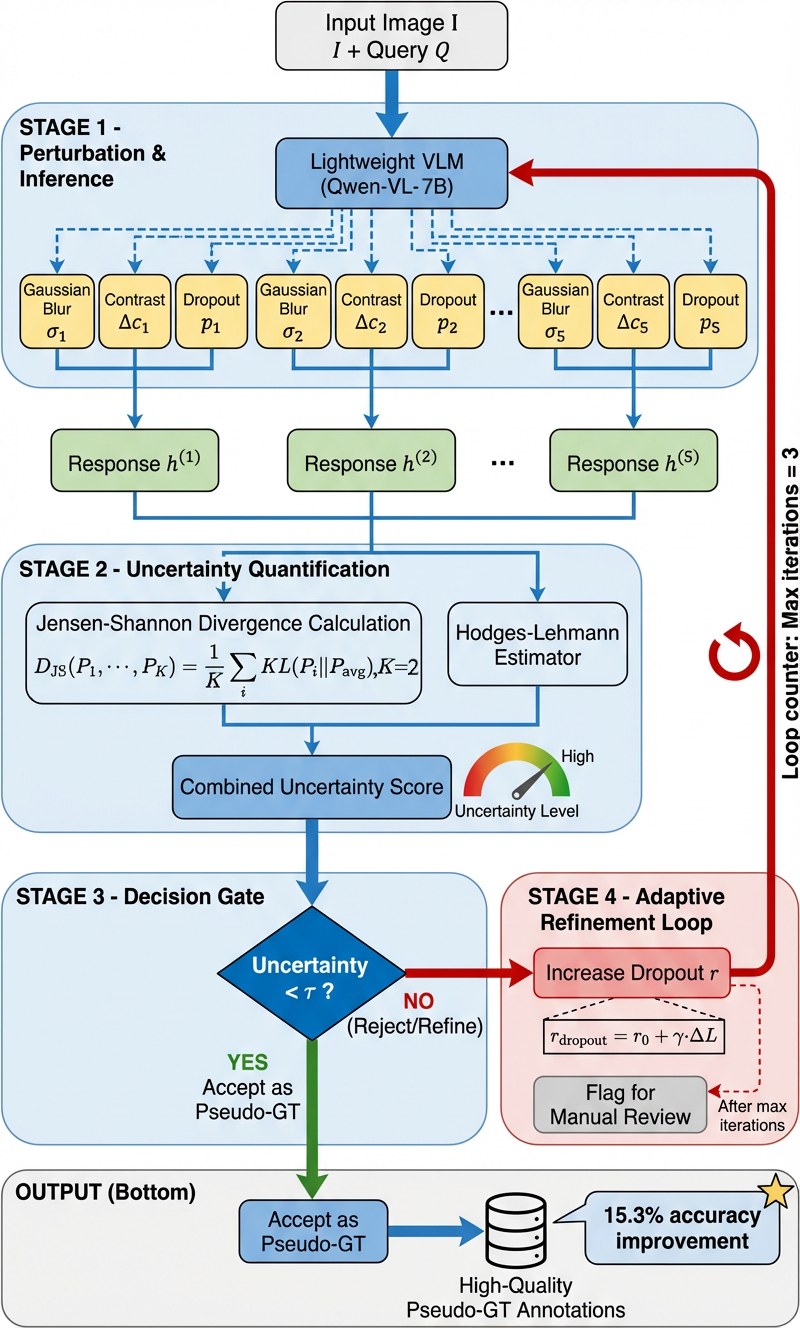
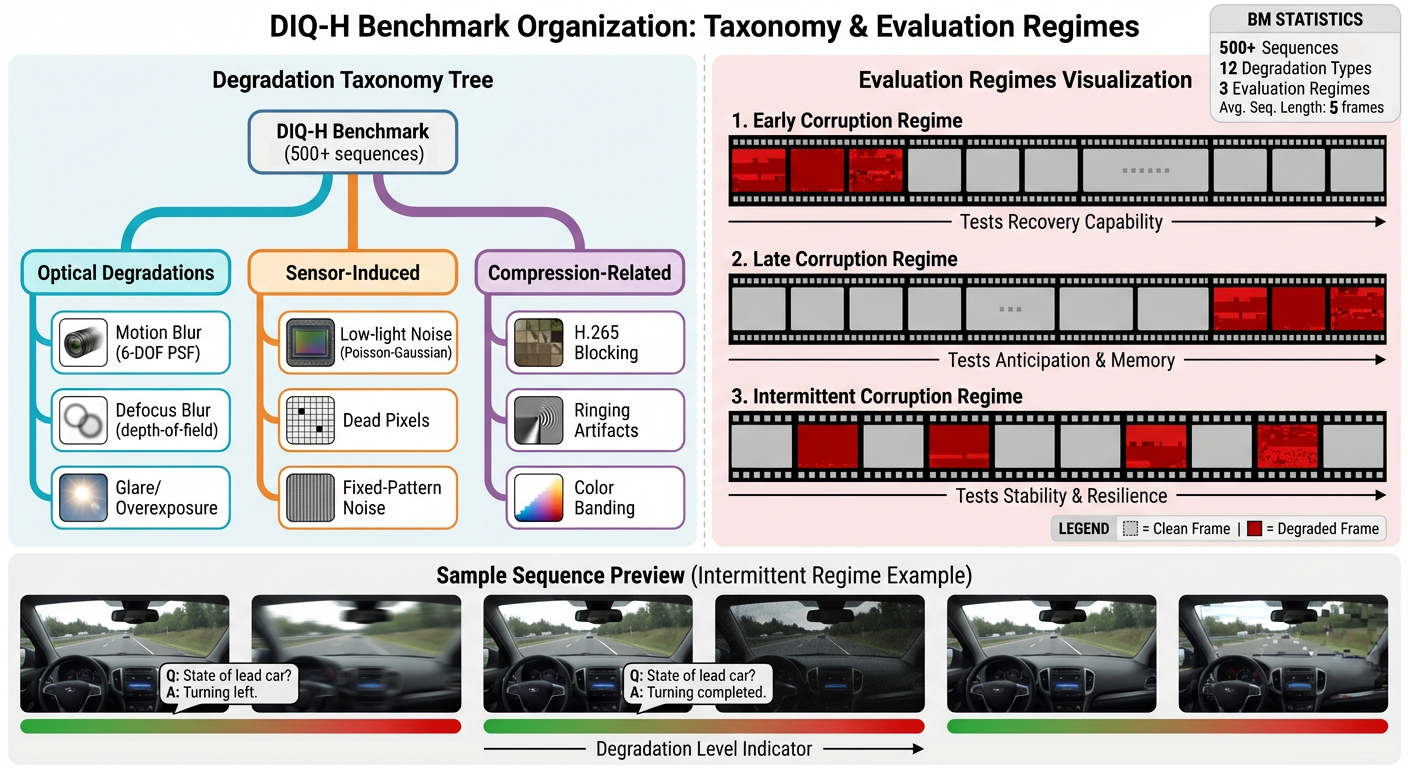
Our Approach. We introduce DIQ-H (Degraded Image
Quality leading to Hallucinations), the first benchmark to
evaluate VLMs under dynamic visual degradation in tem-
poral sequences. DIQ-H addresses the above gaps through:
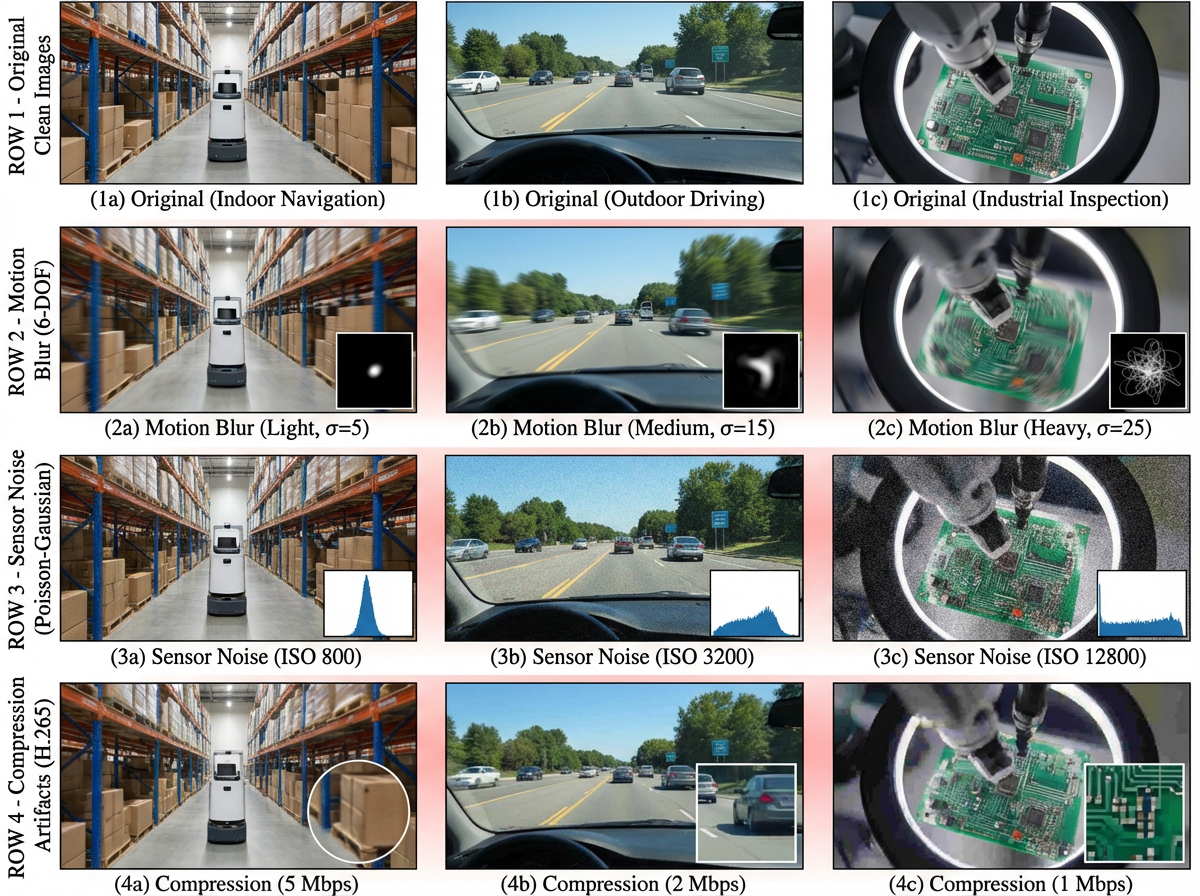
(1) Physics-based degradation simulation applying realistic
motion blur, Poisson-Gaussian noise, and H.265 compres-
sion; (2) Temporal task design with multi-turn Q&A prob-
ing error propagation and recovery; (3) Adaptive difficulty
calibration that stress-tests model limits. To enable scalable
annotation, we propose Uncertainty-Guided Iterative Refine-
arXiv:2512.03992v1 [cs.CV] 3 Dec 2025
2
ment (UIR), which generates reliable pseudo-ground-truth
using lightweight VLMs with uncertainty filtering, achieving
15.3% accuracy improvement over direct annotation. Our main
contributions are:
• DIQ-H Benchmark: First systematic evaluation of VLM
robustness to sequential degradation and hallucination
propagation in dynamic video environments.
• Multi-Agent Generation Framework: Scalable pipeline
combining degradation simulation, temporal task design,
and adaptive difficulty control.
• UIR Annotation Framework: Cost-effective method
for high-quality GT synthesis via uncertainty-guided re-
finement, reducing reliance on expensive human/GPT-4o
annotation.
II. RELATED WORK
With the increasing use of VLM, challenges regarding
their stability, accuracy, and controllability have become more
prominent. Benchmarking VLM has therefore become a focal
point of multimodal intelligence research.
Early benchmarks primarily assessed semantic comprehen-
sion over static images. Datasets such as VQA v2 [6] and the
RefCOCO series [7, 8] focused on tasks like visual question
answering and referring expression grounding