Authors: Alan T. L. Bacellar, Mustafa Munir, Felipe M. G. França, Priscila M. V. Lima, Radu Marculescu, Lizy K. John
📝 Abstract
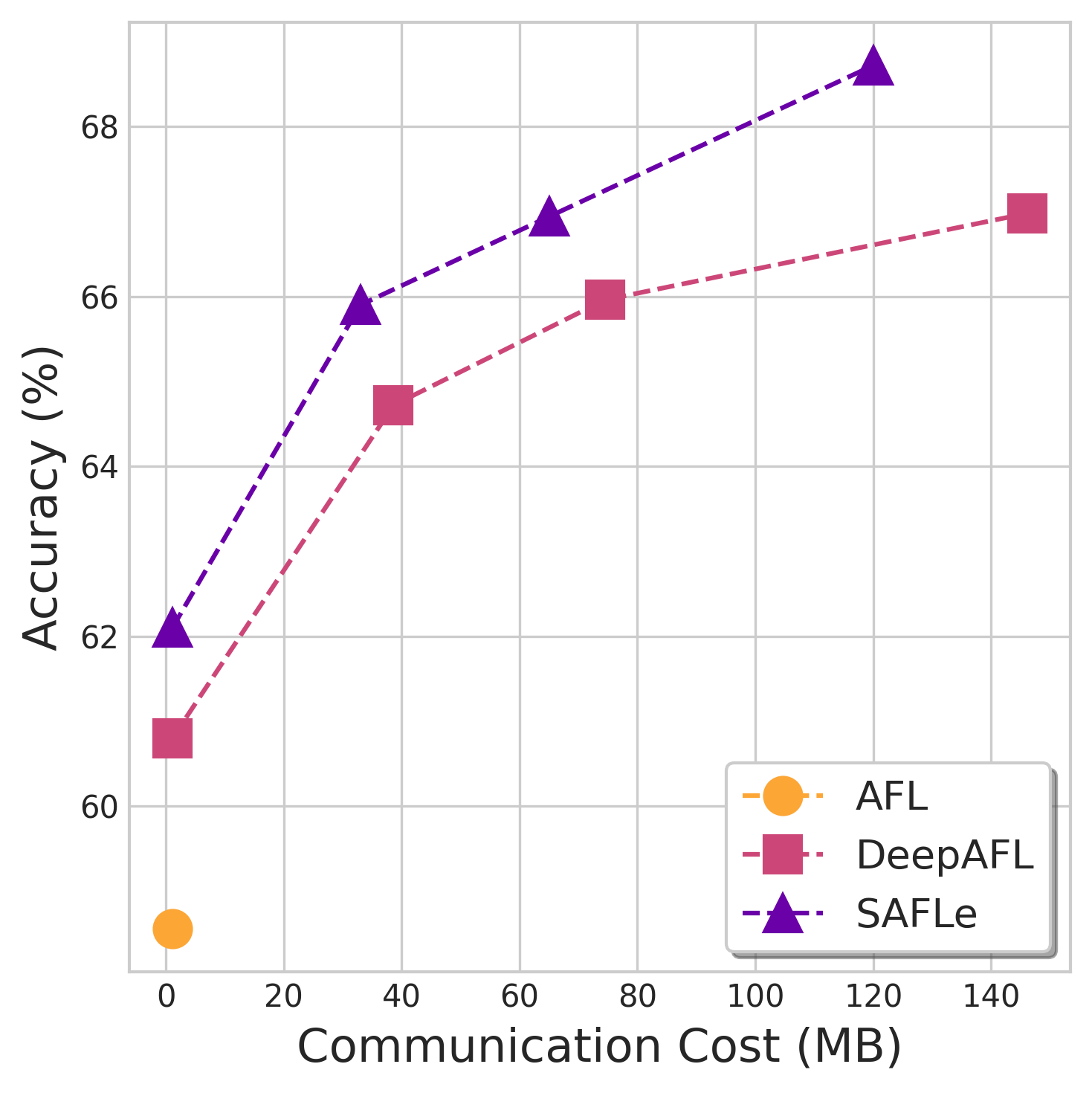
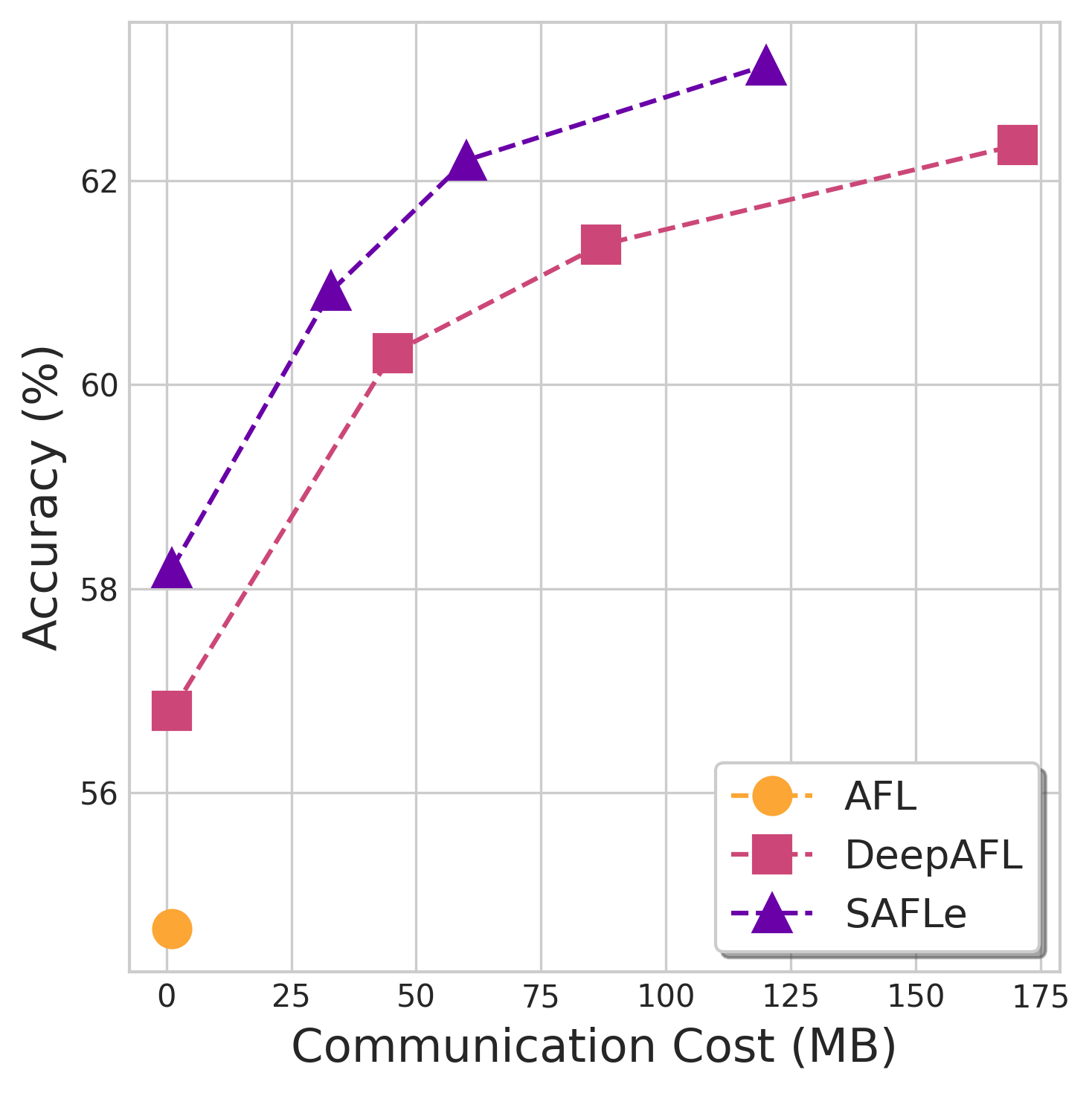
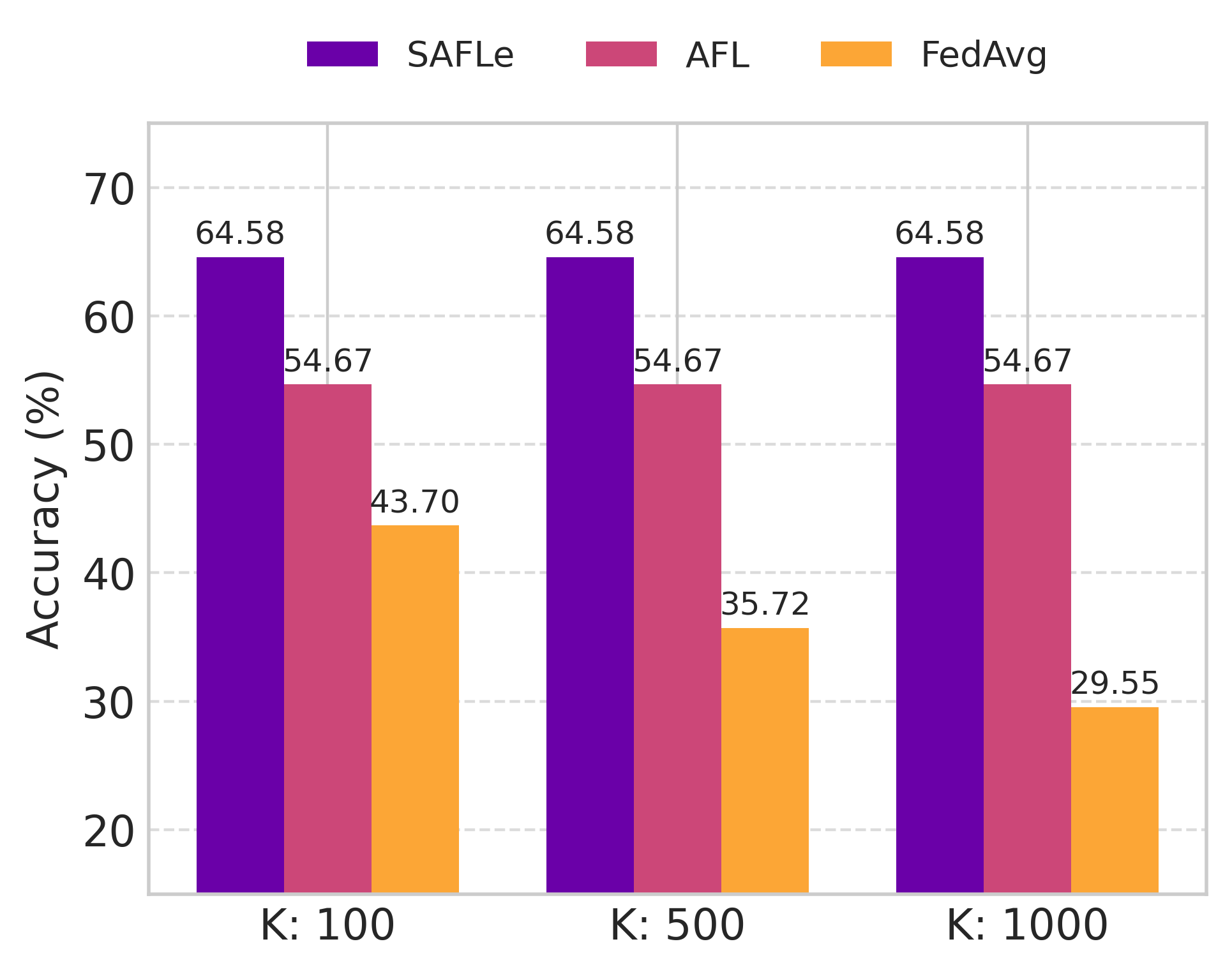
Federated Learning (FL) is plagued by two key challenges: high communication overhead and performance collapse on heterogeneous (non-IID) data. Analytic FL (AFL) provides a single-round, data distribution invariant solution, but is limited to linear models. Subsequent non-linear approaches, like DeepAFL, regain accuracy but sacrifice the single-round benefit. In this work, we break this trade-off. We propose SAFLe, a framework that achieves scalable non-linear expressivity by introducing a structured head of bucketed features and sparse, grouped embeddings. We prove this non-linear architecture is mathematically equivalent to a high-dimensional linear regression. This key equivalence allows SAFLe to be solved with AFL's single-shot, invariant aggregation law. Empirically, SAFLe establishes a new state-of-the-art for analytic FL, significantly outperforming both linear AFL and multi-round DeepAFL in accuracy across all benchmarks, demonstrating a highly efficient and scalable solution for federated vision.
💡 Deep Analysis
📄 Full Content
Single-Round Scalable Analytic Federated Learning
Alan T. L. Bacellar1, Mustafa Munir1, Felipe M. G. Franc¸a2,
Priscila M. V. Lima3, Radu Marculescu1, Lizy K. John1
1University of Texas at Austin 2Google
3Federal University of Rio de Janeiro
alanbacellar@utexas.edu
Abstract
Federated Learning (FL) is plagued by two key challenges:
high communication overhead and performance collapse
on heterogeneous (non-IID) data. Analytic FL (AFL) pro-
vides a single-round, data distribution invariant solution,
but is limited to linear models. Subsequent non-linear ap-
proaches, like DeepAFL, regain accuracy but sacrifice the
single-round benefit.
In this work, we break this trade-
off. We propose SAFLe, a framework that achieves scalable
non-linear expressivity by introducing a structured head of
bucketed features and sparse, grouped embeddings.
We
prove this non-linear architecture is mathematically equiva-
lent to a high-dimensional linear regression. This key equiv-
alence allows SAFLe to be solved with AFL’s single-shot,
invariant aggregation law. Empirically, SAFLe establishes
a new state-of-the-art for analytic FL, significantly outper-
forming both linear AFL and multi-round DeepAFL in ac-
curacy across all benchmarks, demonstrating a highly effi-
cient and scalable solution for federated vision.
1. Introduction
Federated Learning (FL) enables multiple clients or devices
to collaboratively train a shared model without exposing
their private data. Instead of centralizing data, clients per-
form local updates and periodically communicate model pa-
rameters to a server, which aggregates them into a global
model [16]. While conceptually appealing, conventional FL
frameworks require many communication rounds—often
hundreds or thousands—for a model to converge. In practi-
cal deployments, clients can operate at different speeds, dis-
connect intermittently, or fail mid-training, creating strag-
glers and asynchronous updates.
Such instability causes
training to progress unevenly, and the global model may
take days or weeks to reach convergence, severely limiting
FL’s real-world scalability.
Beyond communication inefficiency, a deeper issue lies
in statistical heterogeneity across clients.
In real FL
systems, local data distributions often differ sharply—for
instance, users capture different visual styles, hospitals
record different patient populations, or sensors observe non-
overlapping environments. This non-IID nature of the data
means that each client’s gradient direction diverges from the
global optimum, degrading performance and convergence
stability. Existing methods attempt to address this through
various regularizers, dynamic aggregation schemes, and us-
ing pre-trained models for initialization and distilation [1,
13, 14, 18], but these stuggles with non-IID settings.
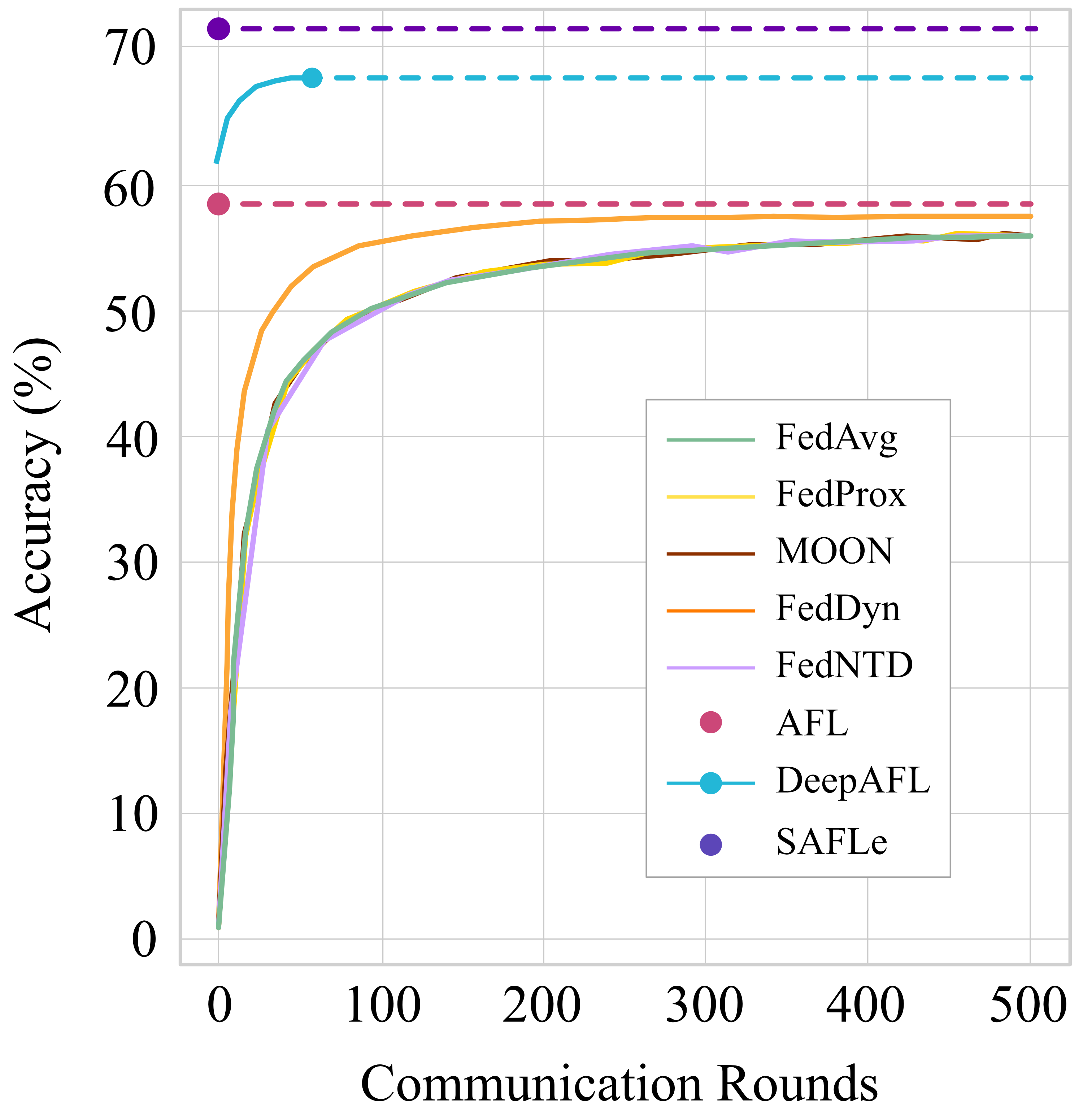
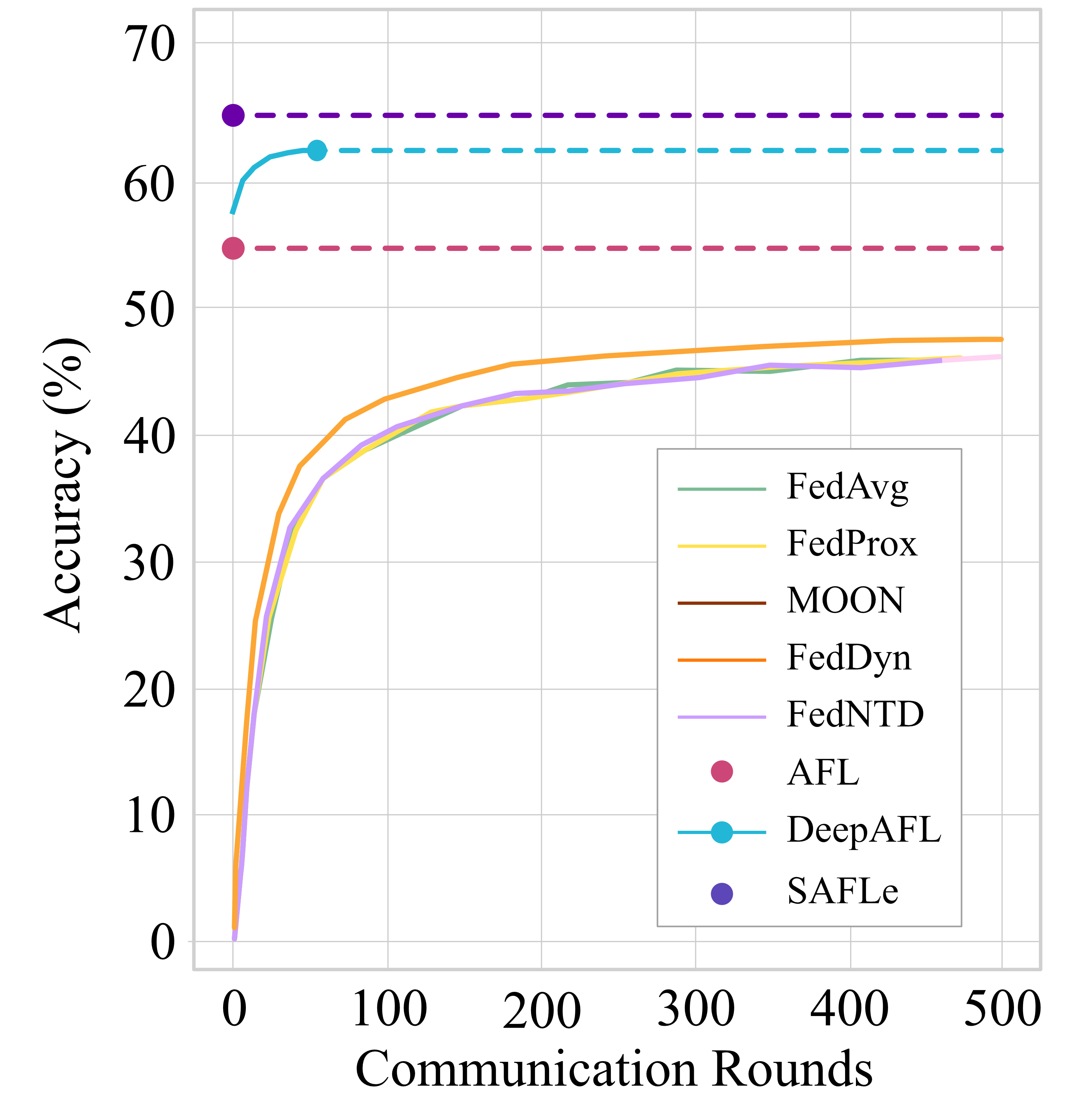
To overcome these limitations, recent work proposed An-
alytic Federated Learning (AFL) [7], which formulates the
FL problem in closed form. AFL leverages a pre-trained
backbone to extract embeddings on each client, and trains
a linear regression head analytically in only one commu-
nication round. Its analytic aggregation law guarantees in-
variance to both data partitioning and client count, enabling
the global solution to remain identical to centralized train-
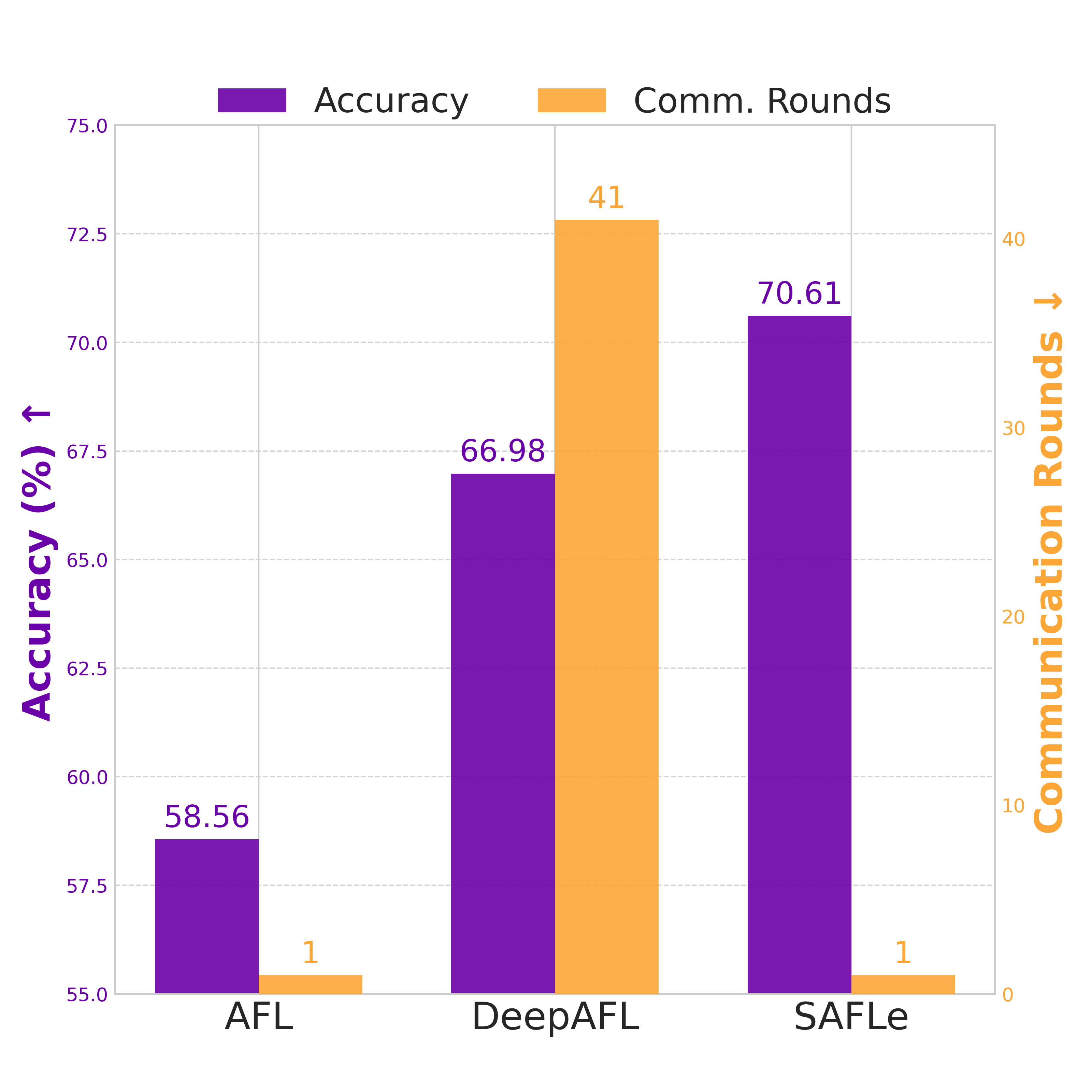
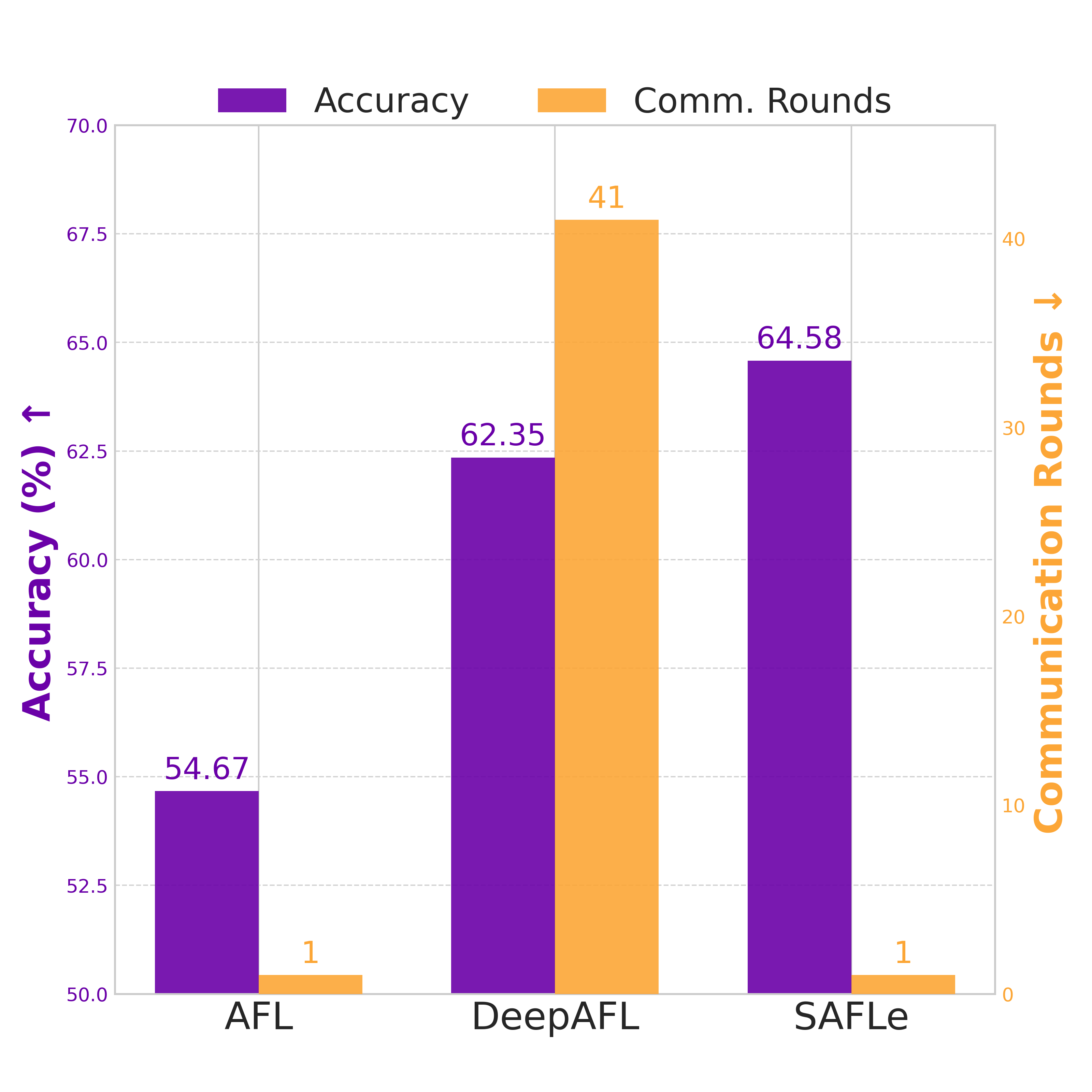
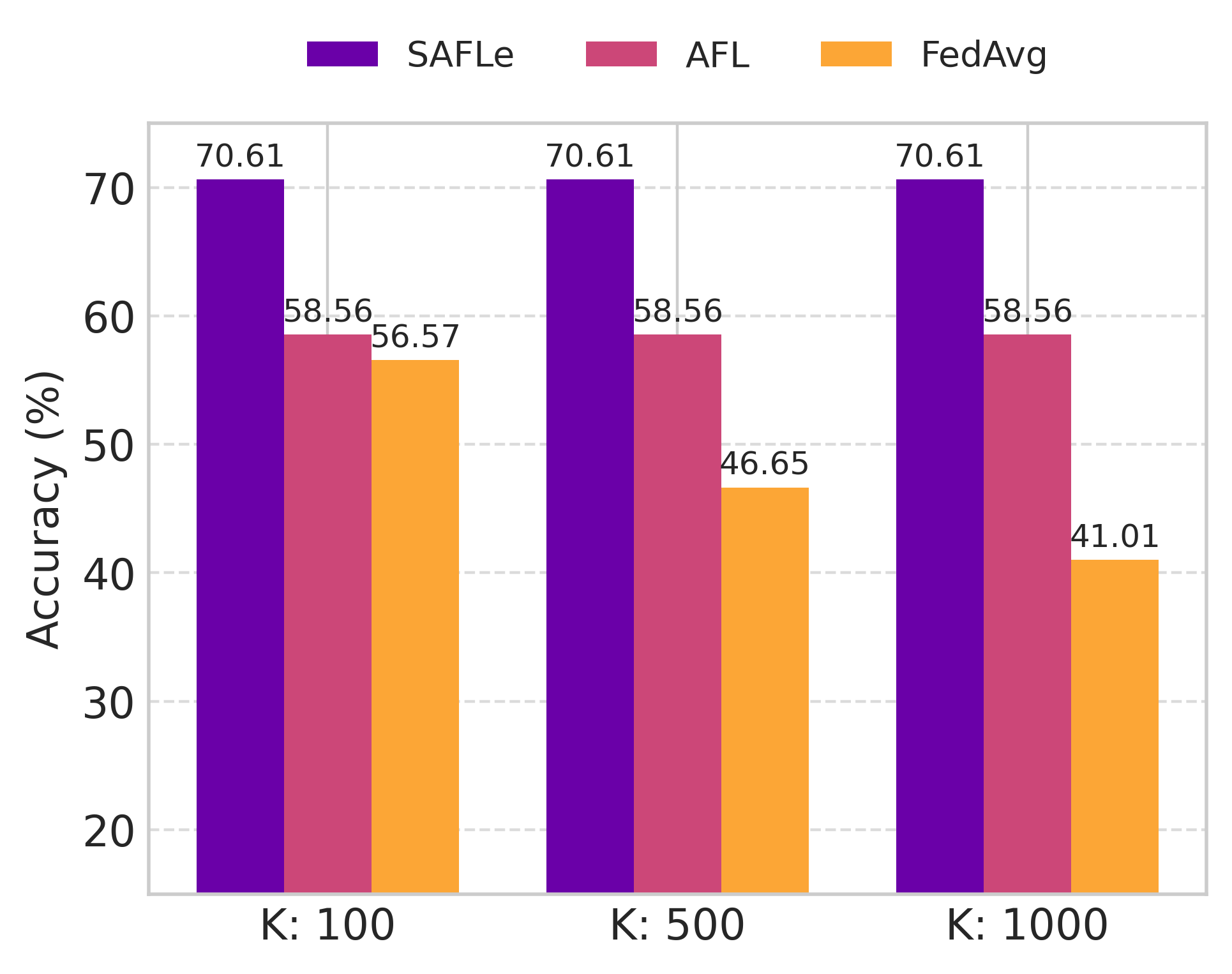
ing regardless of heterogeneity. As a result, AFL achieves
higher accuracy than conventional iterative FL methods un-
der highly non-IID conditions, while requiring only a single
communication round instead of hundreds. Despite these
appealing properties, AFL remains constrained by its linear
model structure, which limits representational capacity and
the ability to capture nonlinear feature interactions.
More recently, DeepAFL [3] proposed a layer-wise an-
alytic training scheme that extends AFL into deeper ar-
chitectures. DeepAFL retains AFL’s invariance property,
but trades communication efficiency for greater accuracy.
Each analytic layer requires a separate aggregation round,
increasing synchronization overhead and deviating from
AFL’s single-pass analytic design. Consequently, DeepAFL
achieves higher accuracy than AFL on non-IID data but at
the cost of multiple communication rounds.
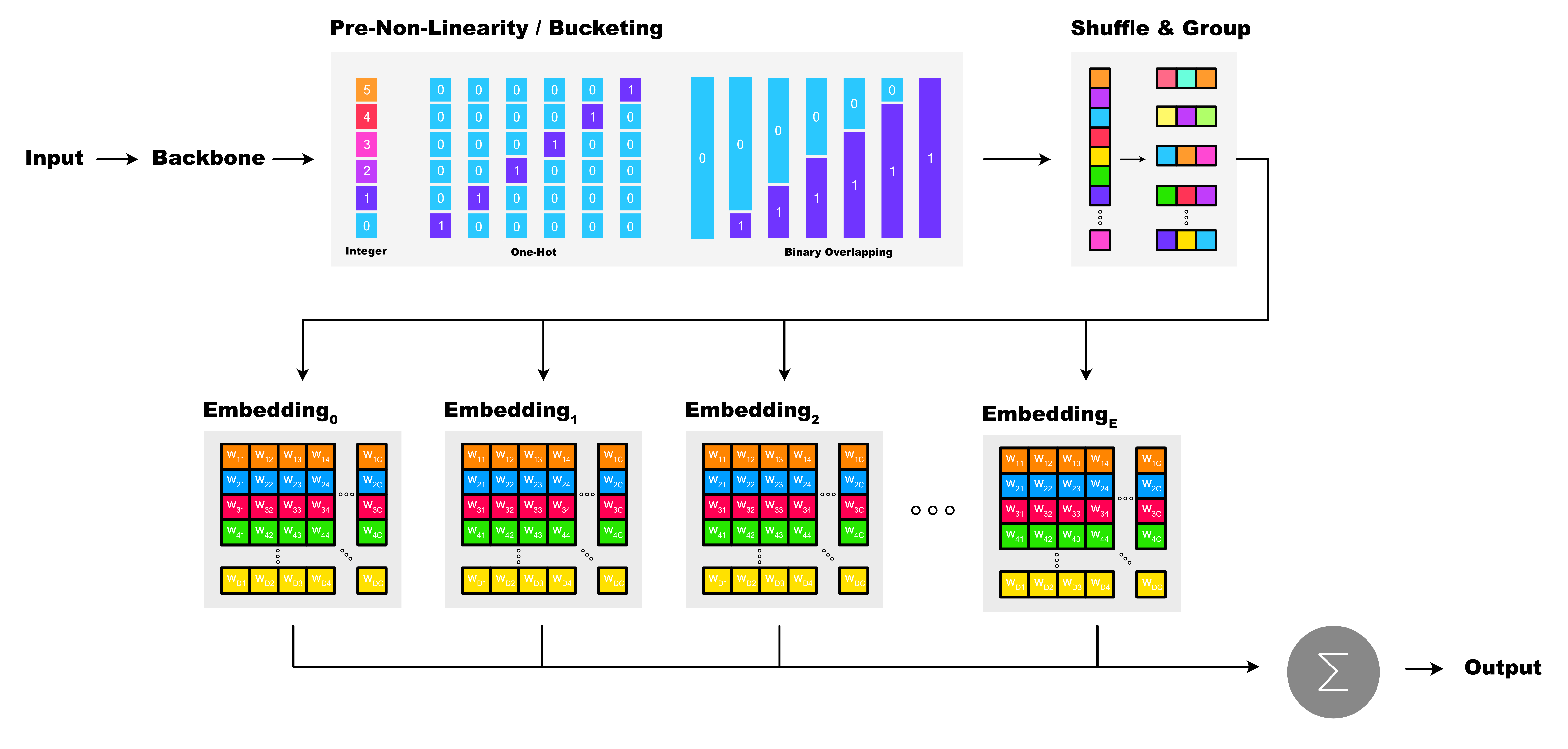
In this work, we propose SAFLe — Sparse Analytic Fed-
erated Learning with nonlinear embeddings — a frame-
work that retains AFL’s single-round analytic formulation
1
arXiv:2512.03336v1 [cs.LG] 3 Dec 2025
while significantly enhancing model expressivity. SAFLe
introduces a deterministic nonlinear transformation pipeline
composed of three stages: feature bucketing, shuffling and
grouping and sparse embeddings. We prove that this nonlin-
ear transformation pipeline can be reformulated as an equiv-
alent analytic regression problem, preserving AFL’s closed-
form training and invariance properties.
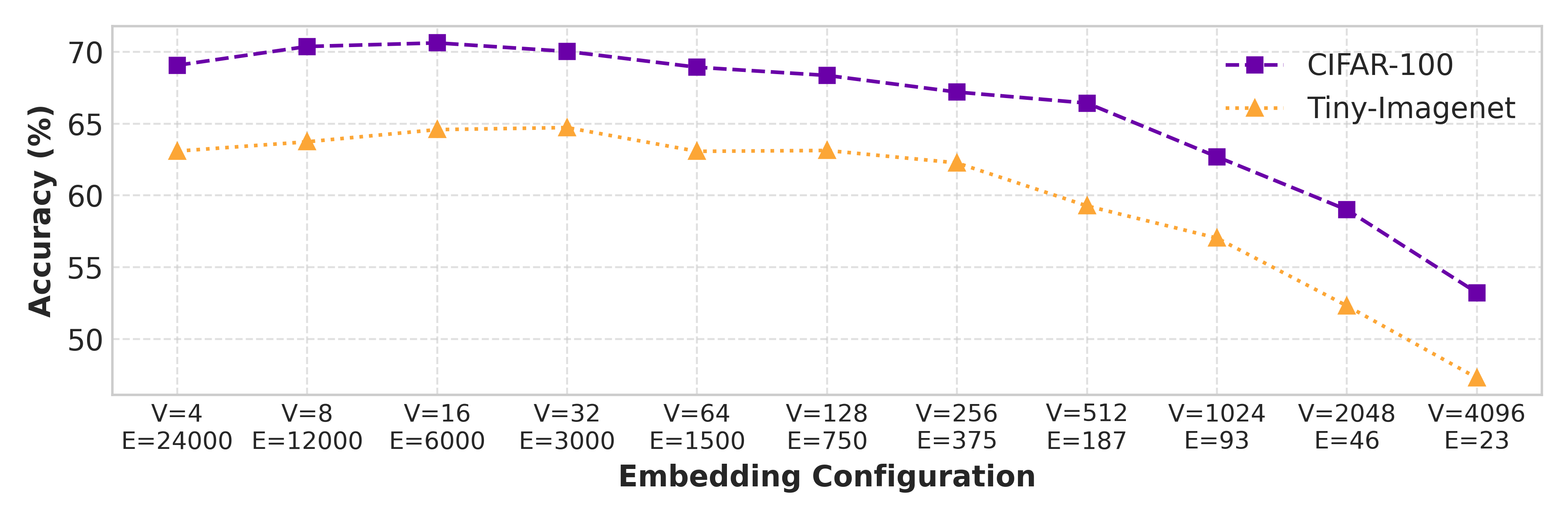
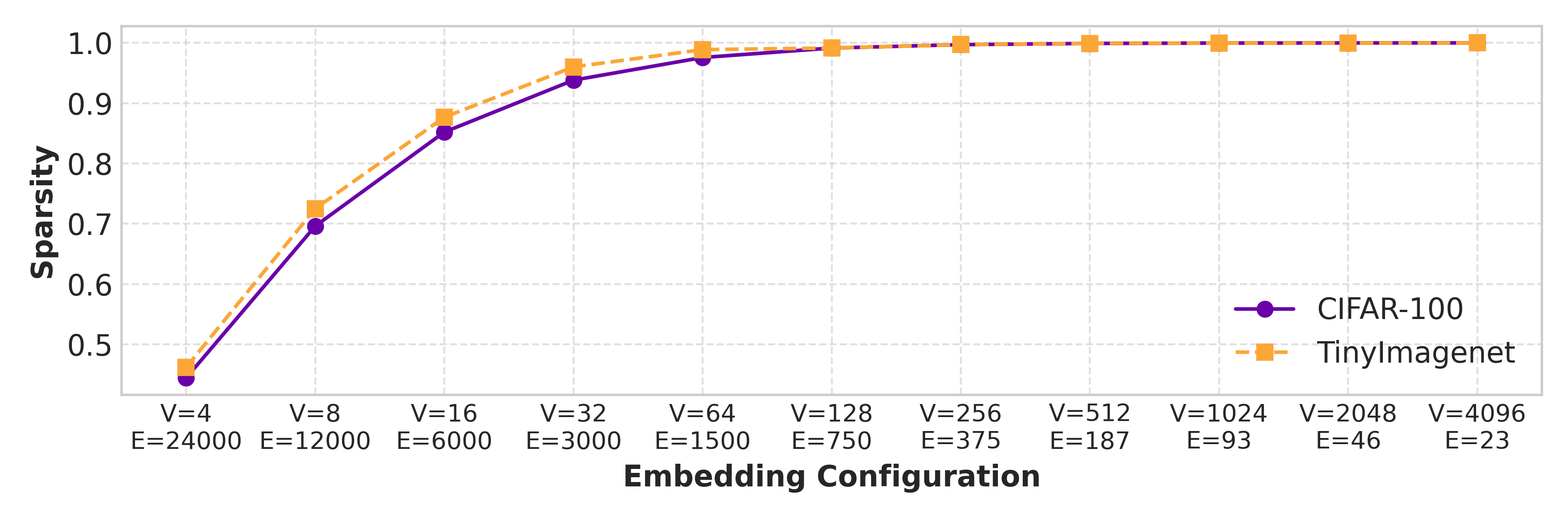
This design allows SAFLe to scale model capacity by
simply increasing the number of sparse embeddings, with-
out altering the analytic formulation or introducing ex-
tra communication rounds. Empirically, SAFL