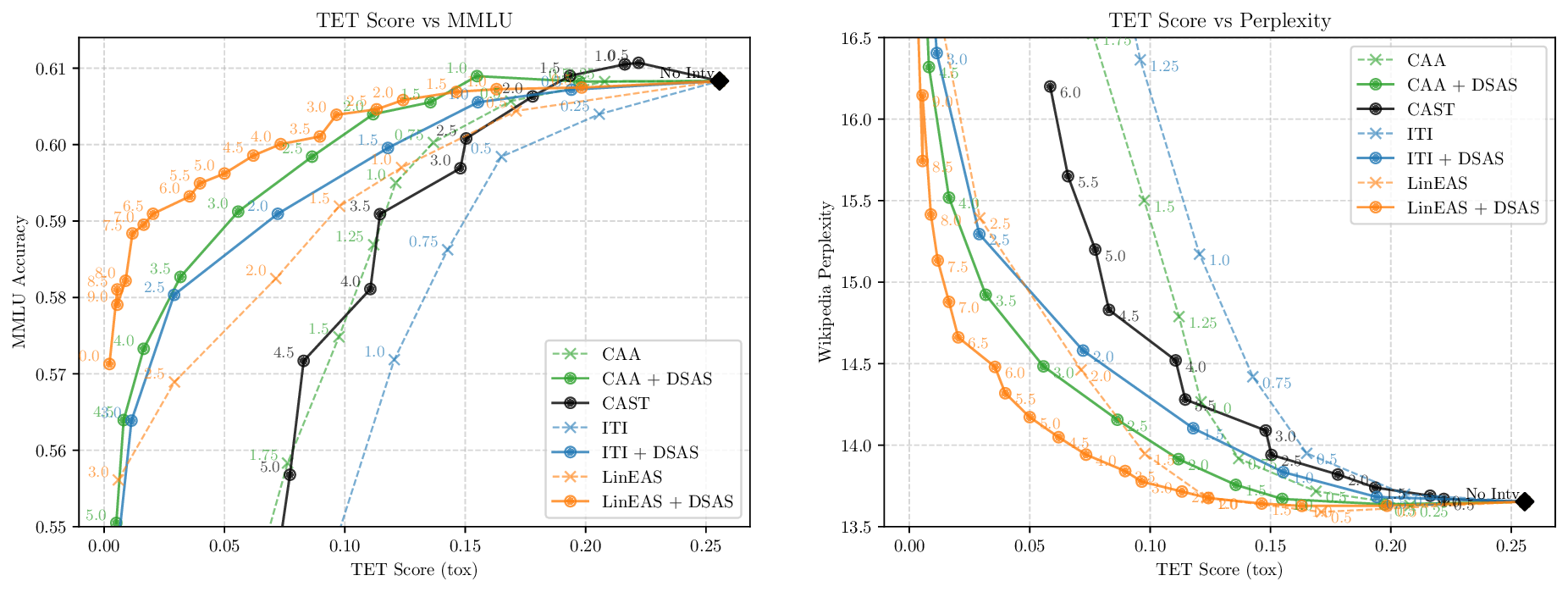
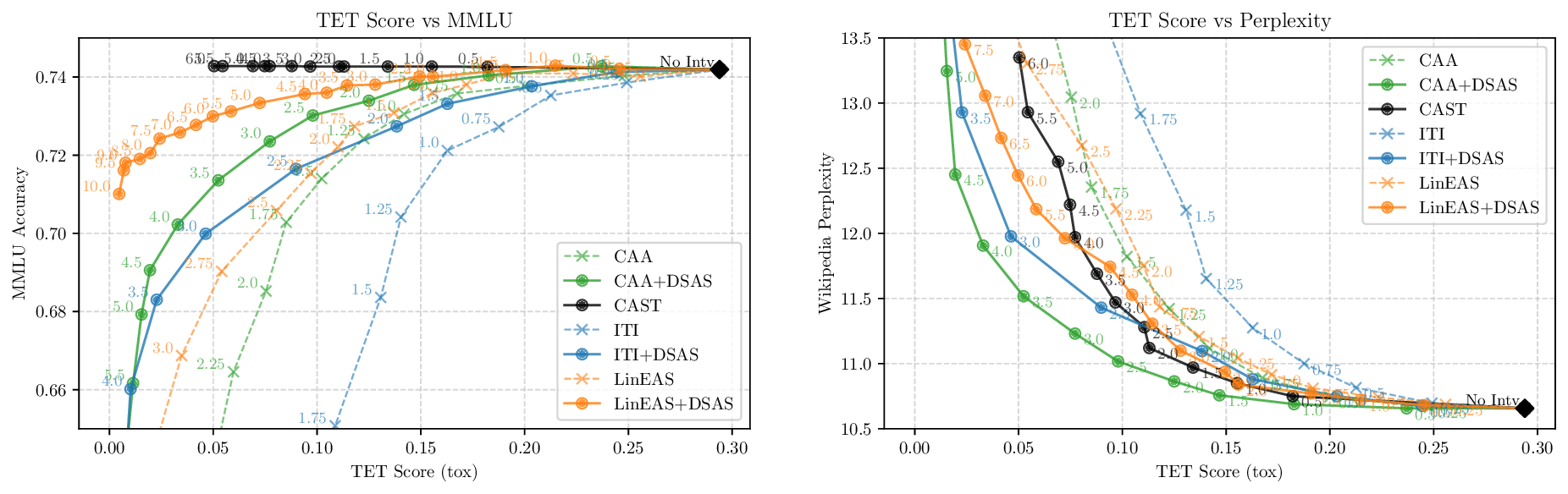
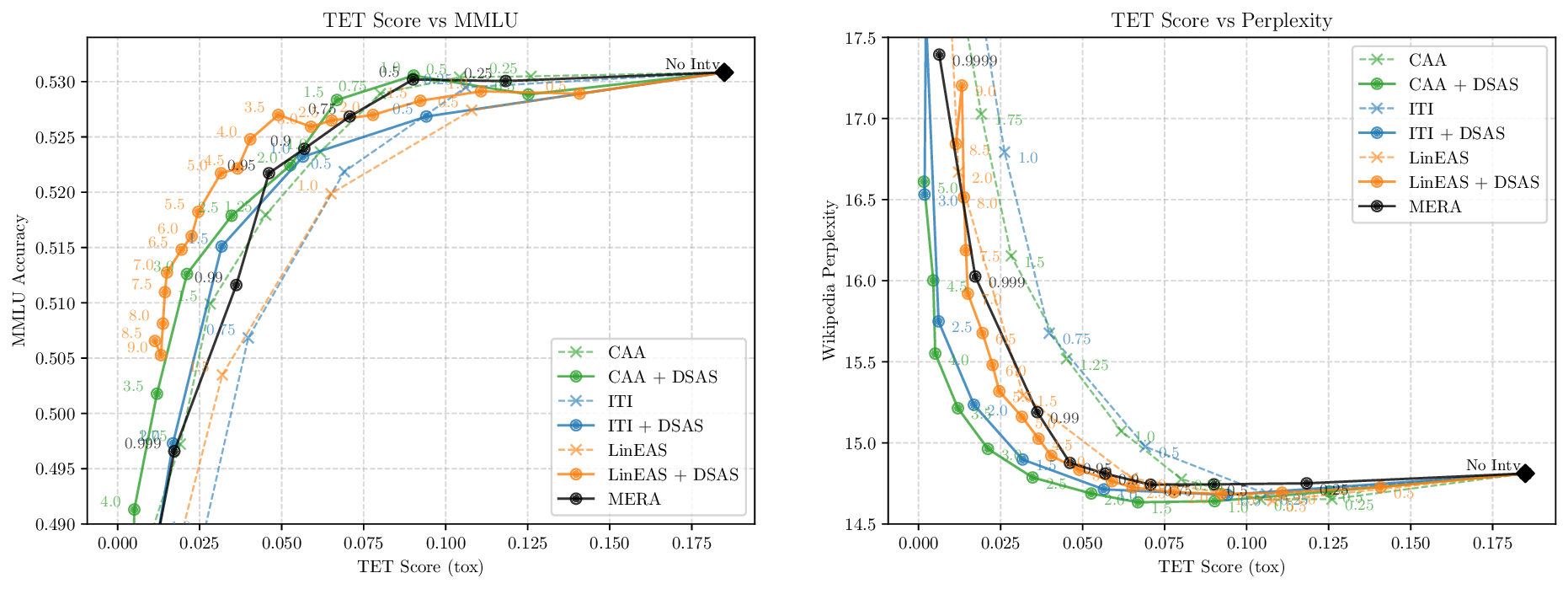
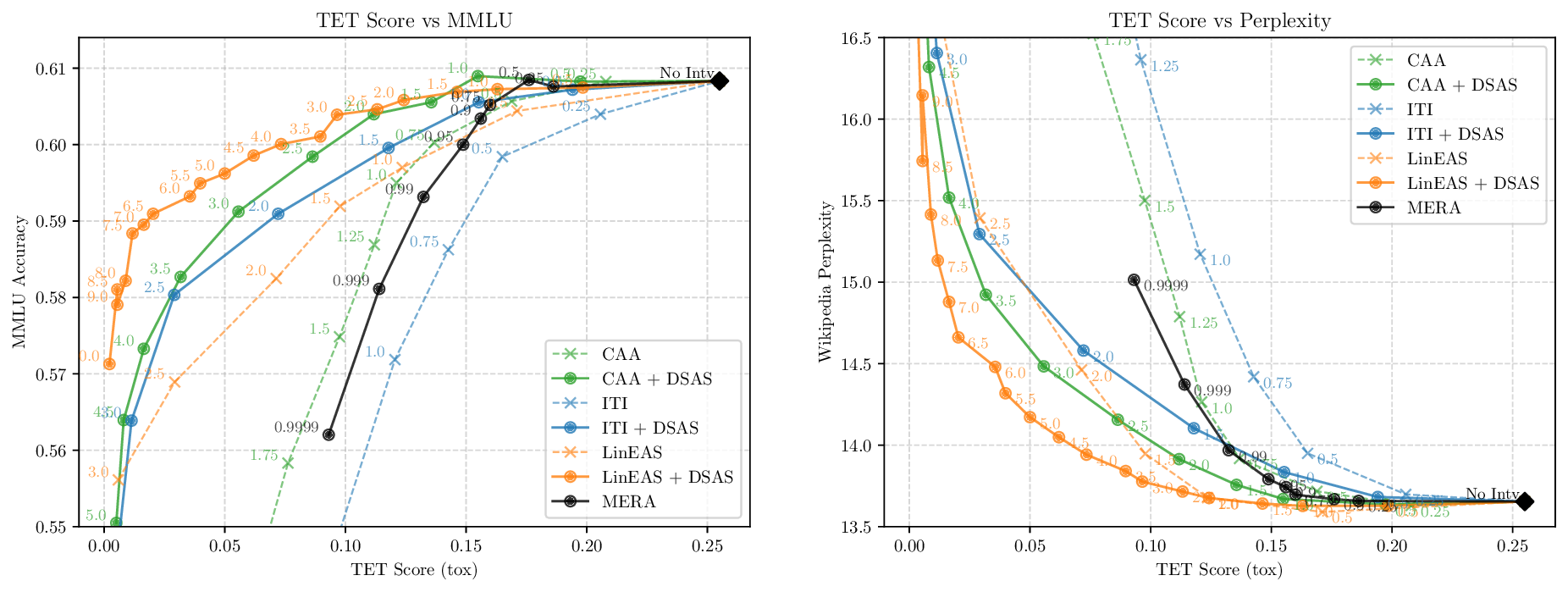
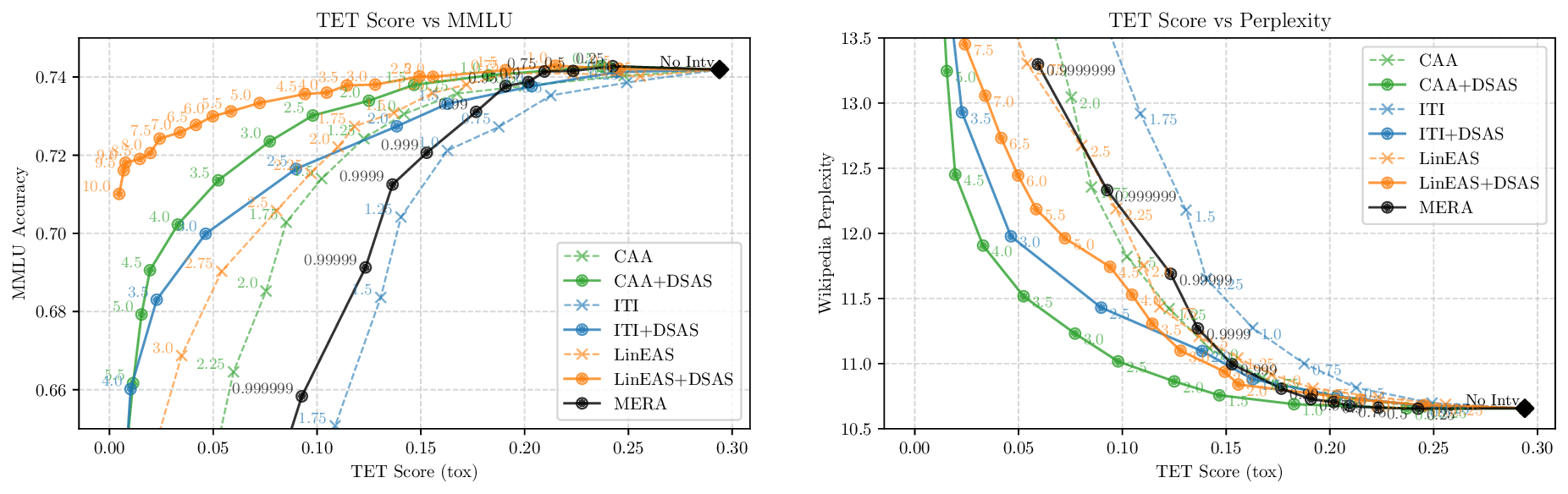
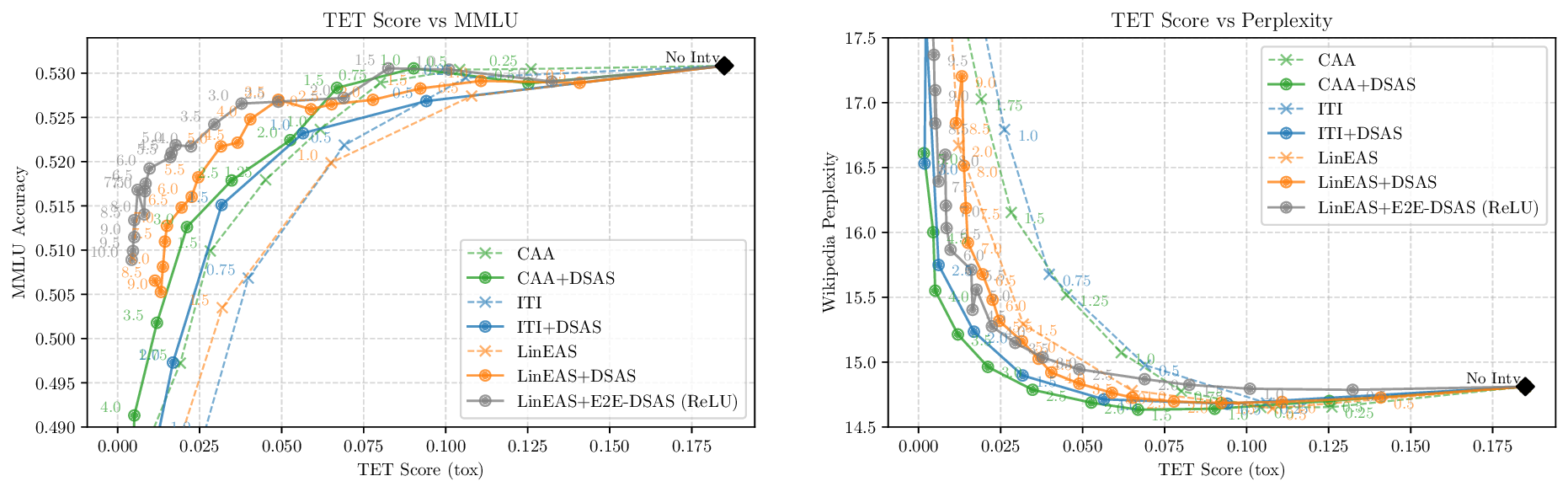
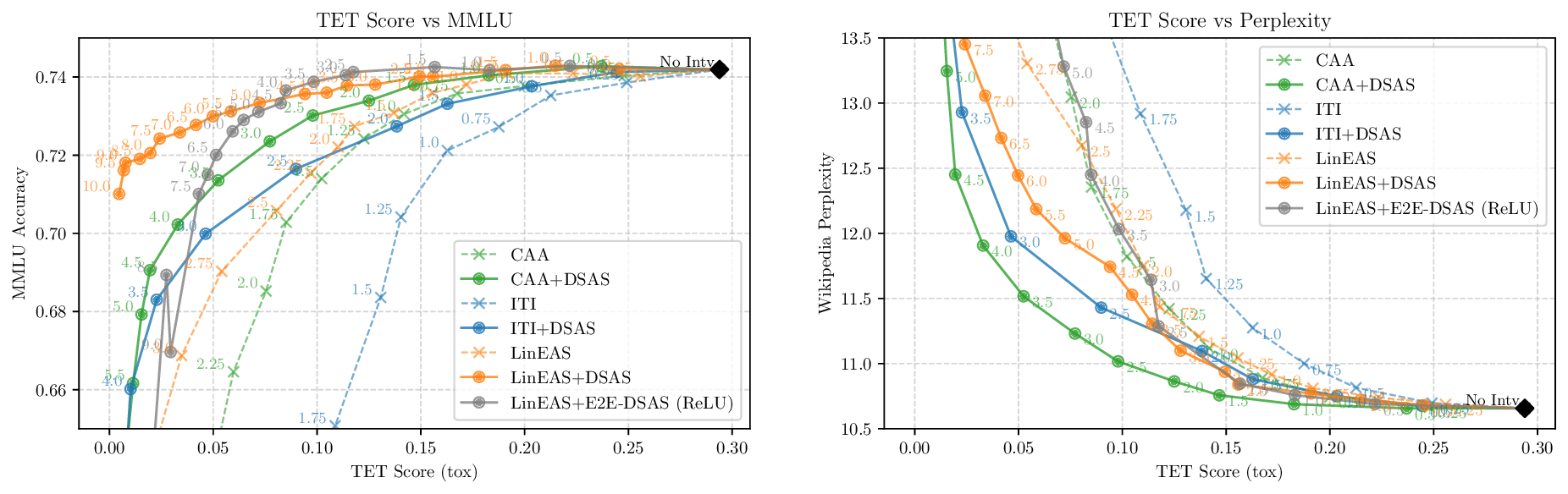
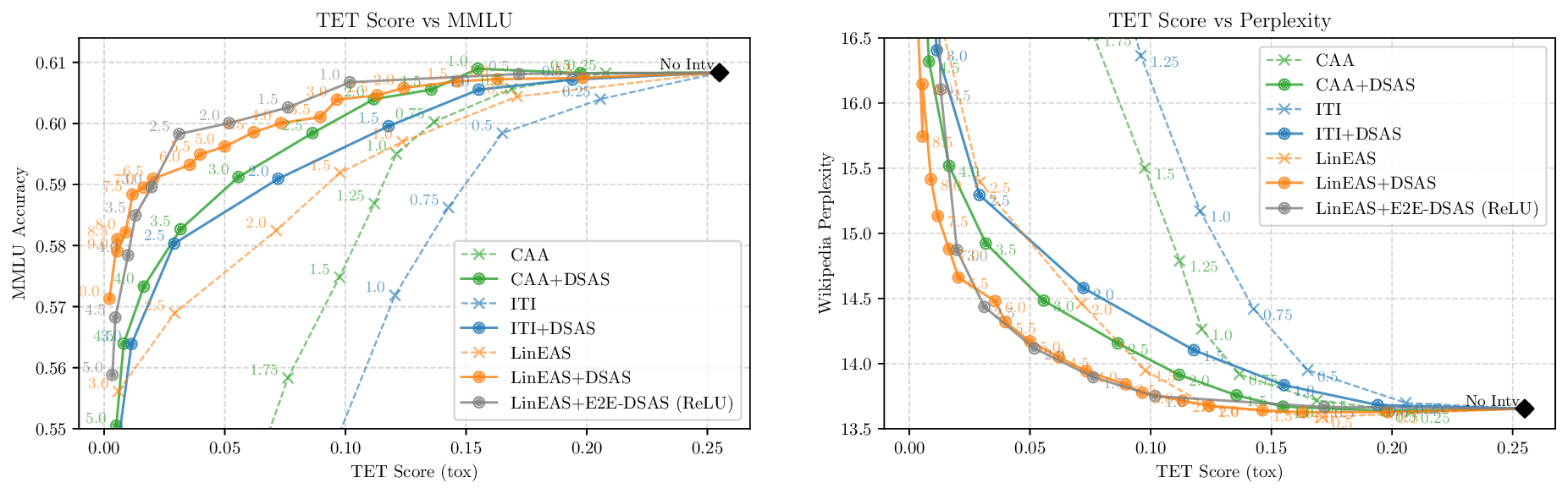
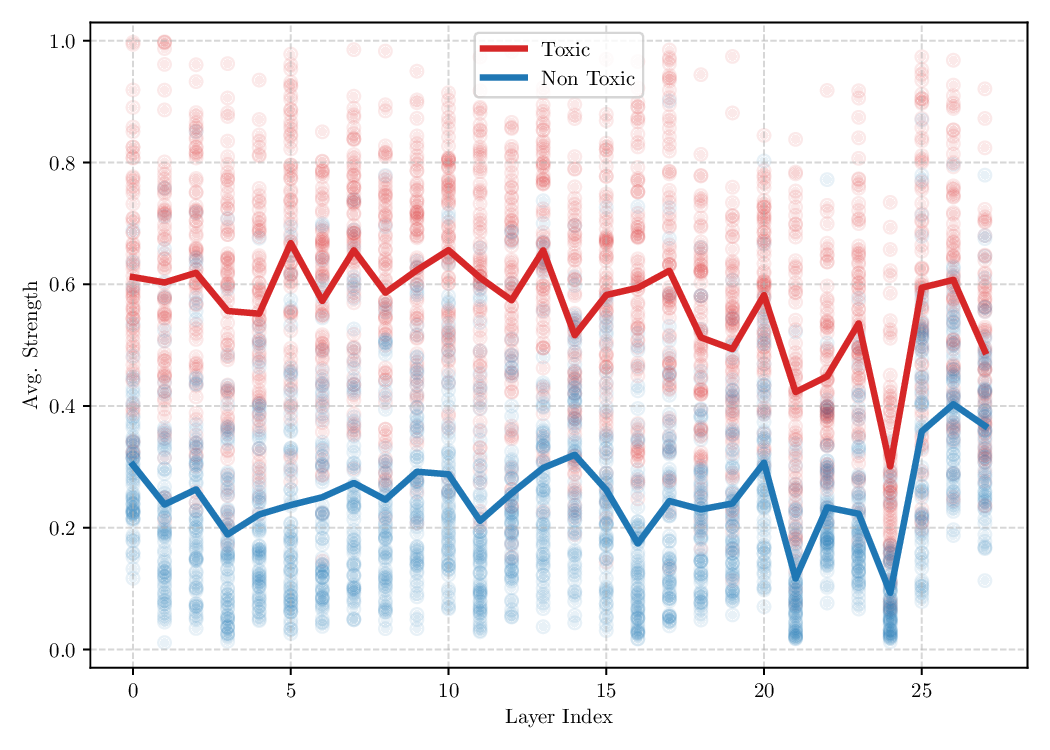
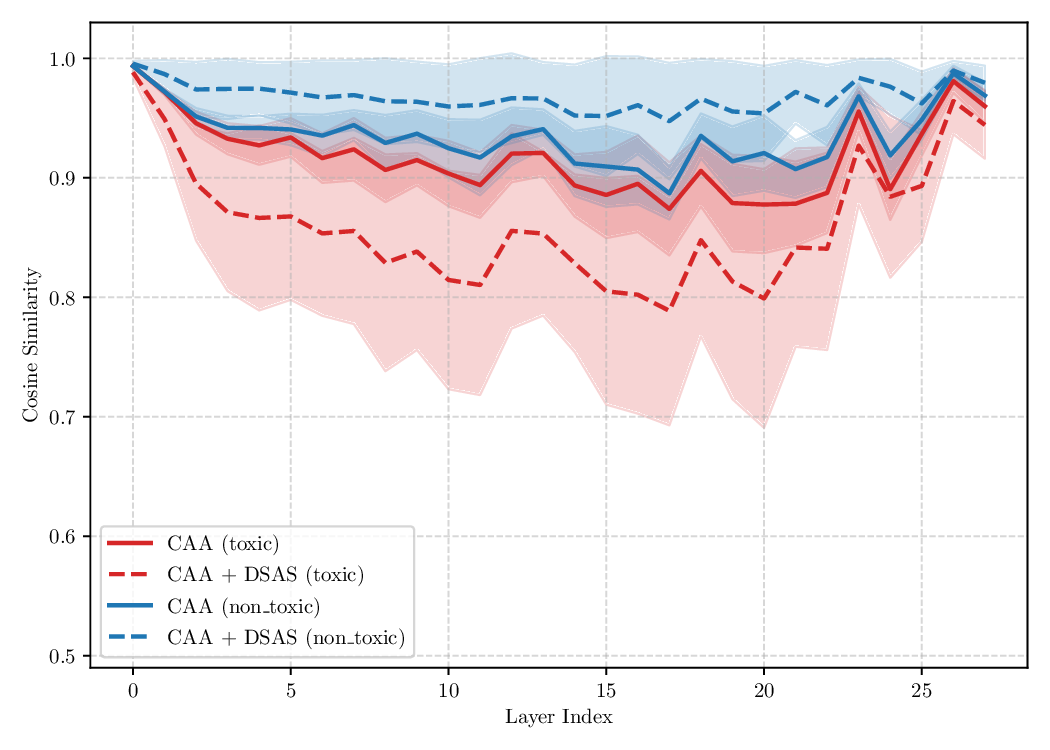
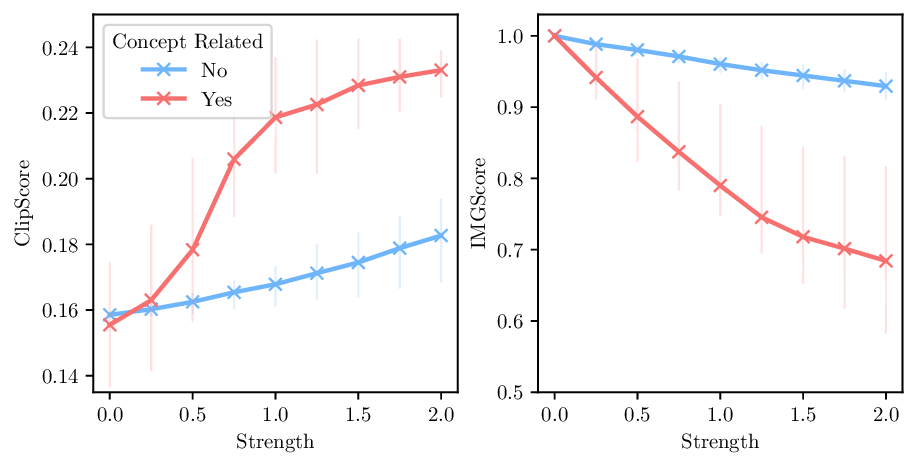
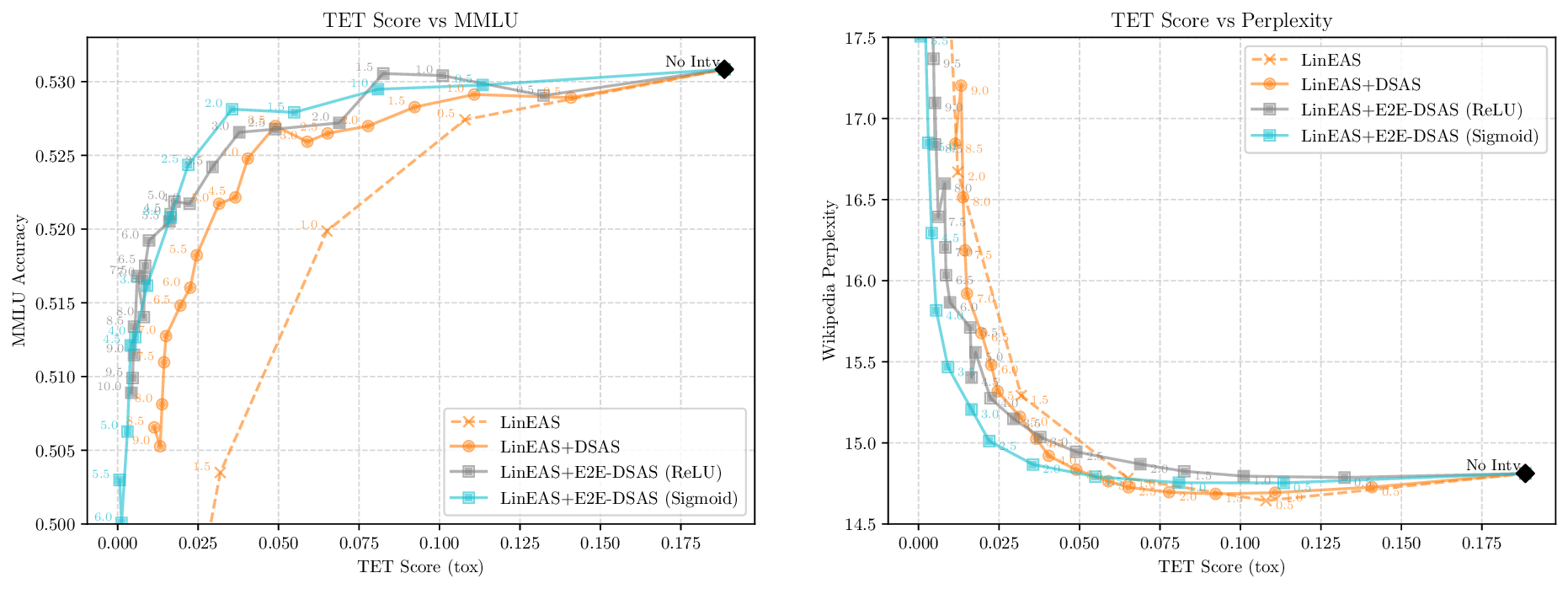
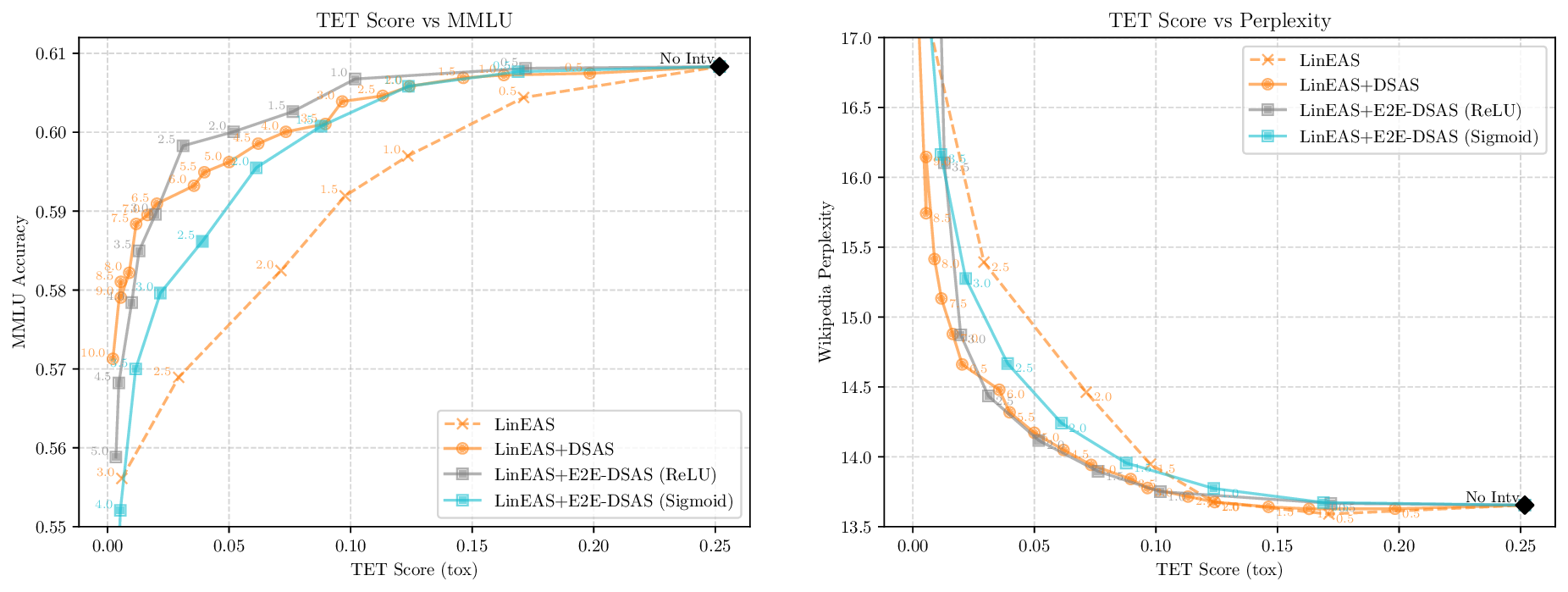
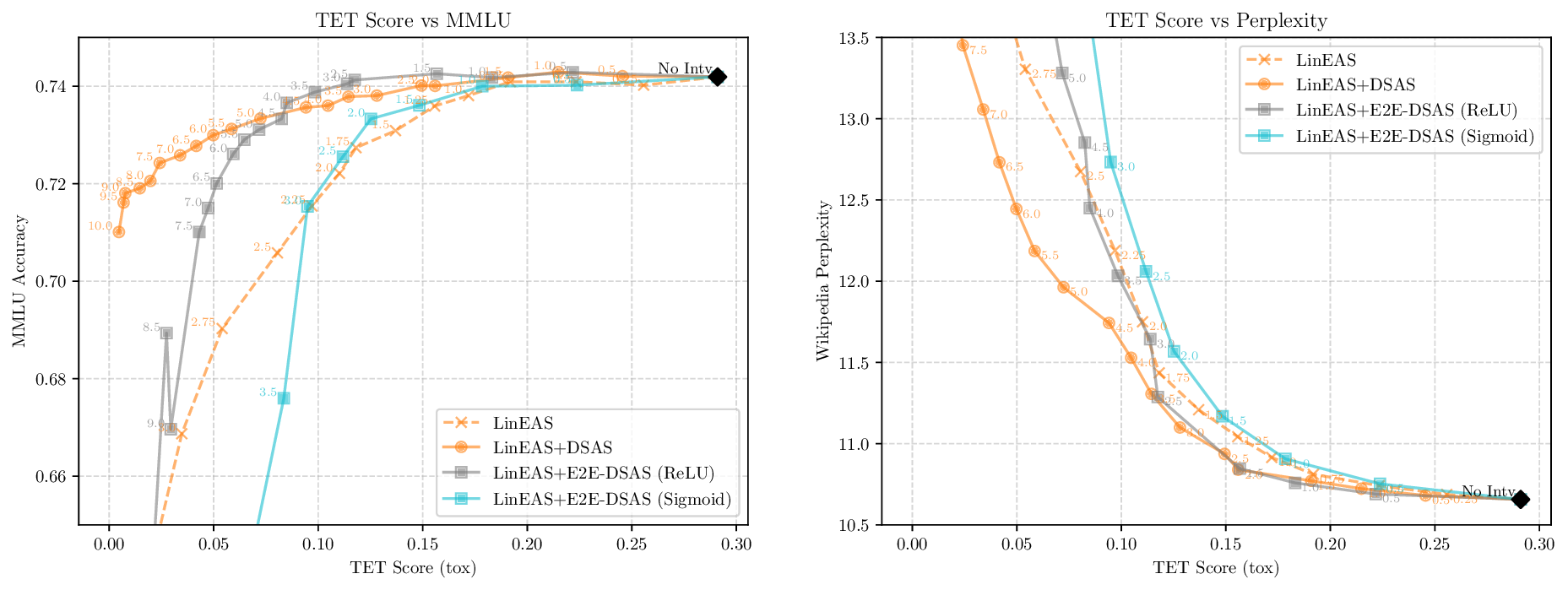
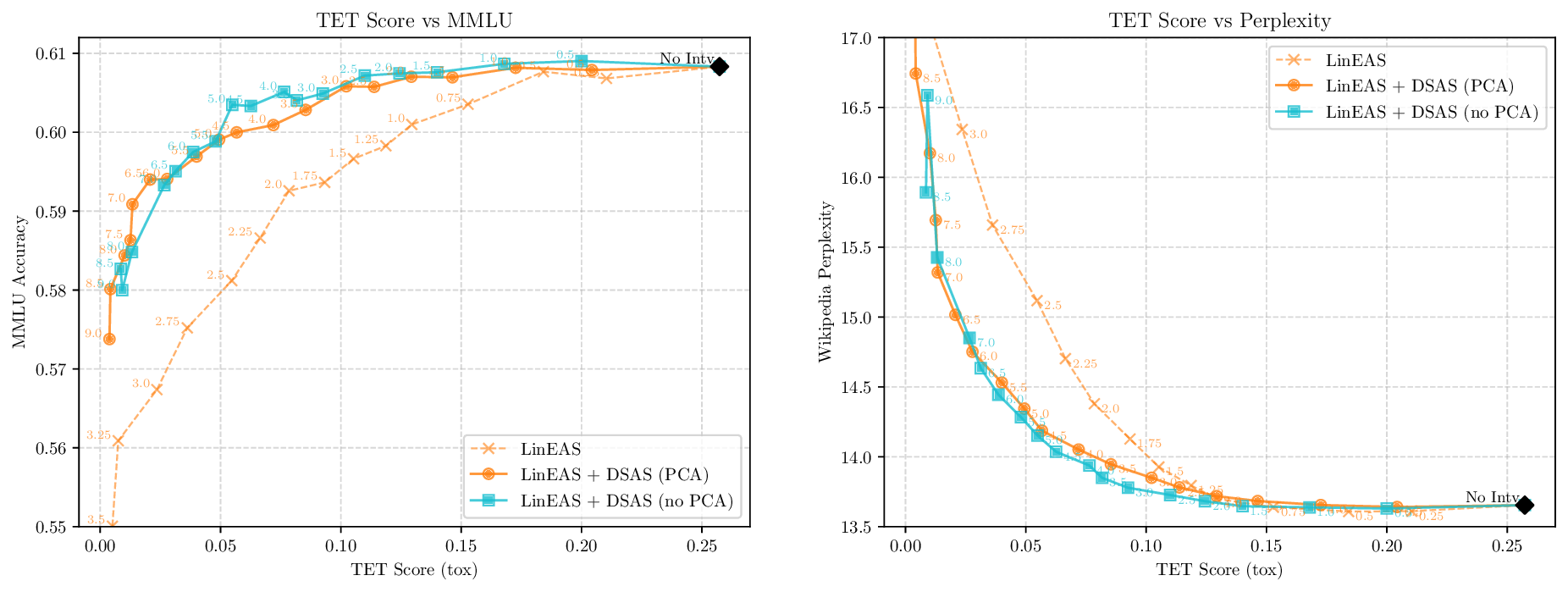
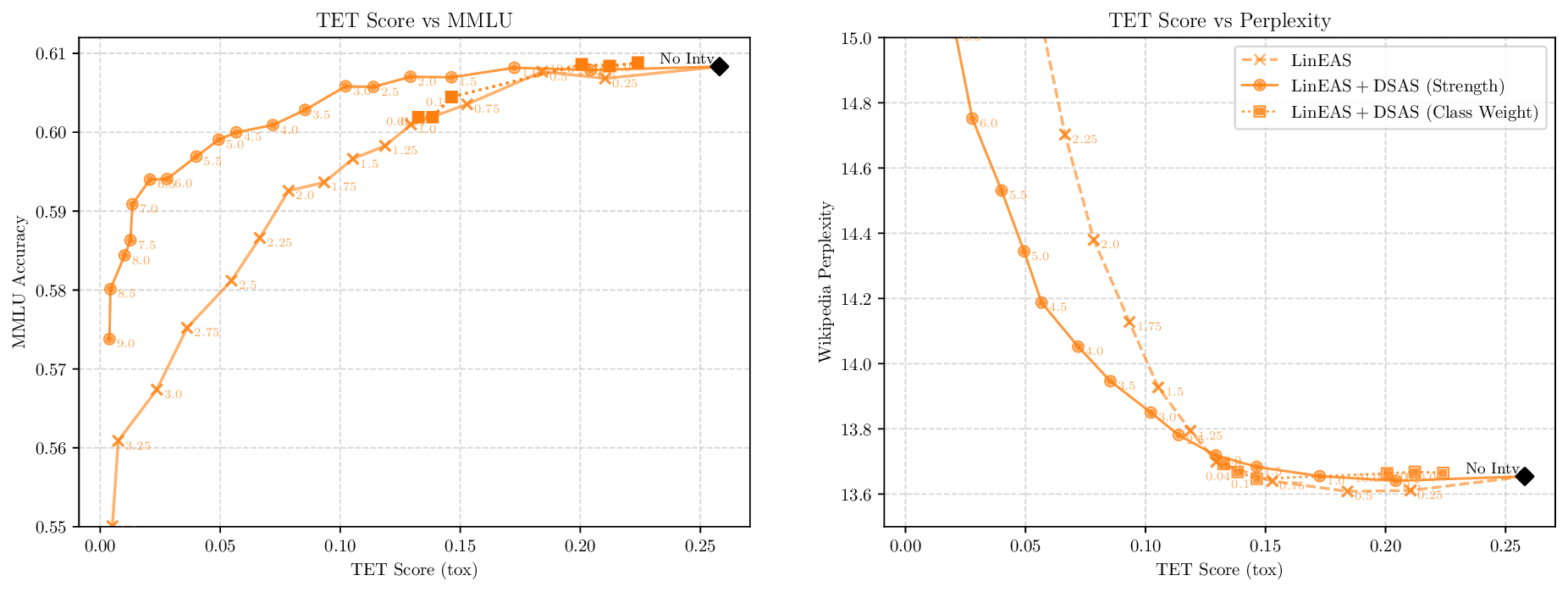
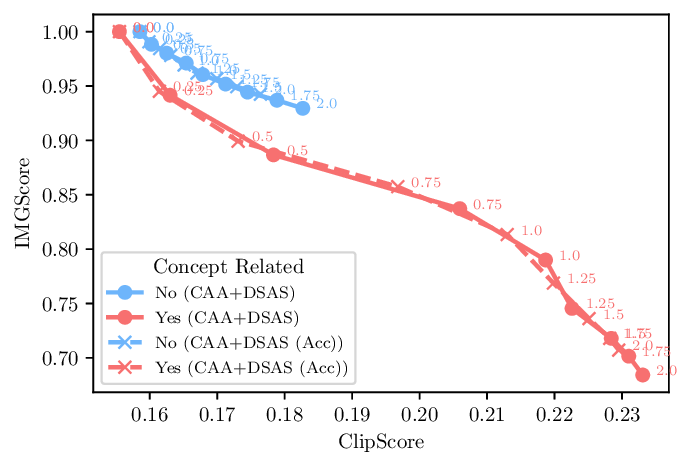
Activation steering has emerged as a powerful method for guiding the behavior of generative models towards desired outcomes such as toxicity mitigation. However, most existing methods apply interventions uniformly across all inputs, degrading model performance when steering is unnecessary. We introduce Dynamically Scaled Activation Steering (DSAS), a method-agnostic steering framework that decouples when to steer from how to steer. DSAS adaptively modulates the strength of existing steering transformations across layers and inputs, intervening strongly only when undesired behavior is detected. At generation time, DSAS computes context-dependent scaling factors that selectively adjust the strength of any steering method. We also show how DSAS can be jointly optimized end-to-end together with the steering function. When combined with existing steering methods, DSAS consistently improves the Pareto front with respect to steering alone, achieving a better trade-off between toxicity mitigation and utility preservation. We further demonstrate DSAS's generality by applying it to a text-to-image diffusion model, showing how adaptive steering allows the modulation of specific concepts. Finally, DSAS introduces minimal computational overhead while improving interpretability, pinpointing which tokens require steering and by how much.
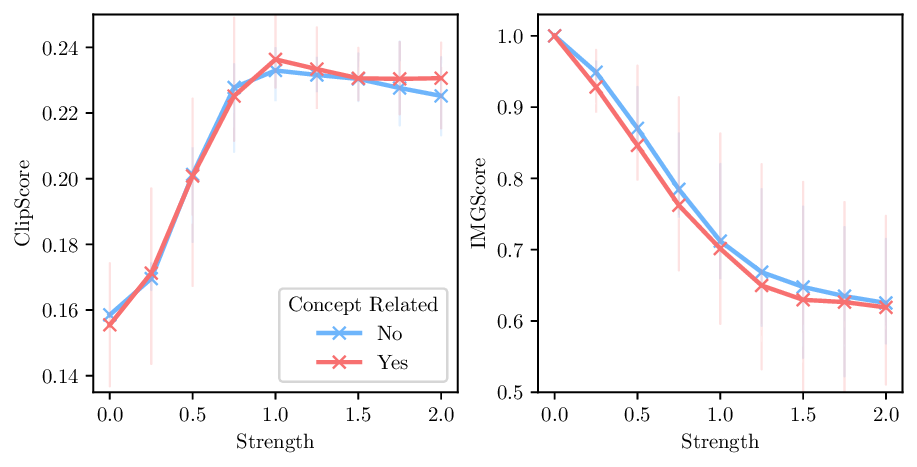
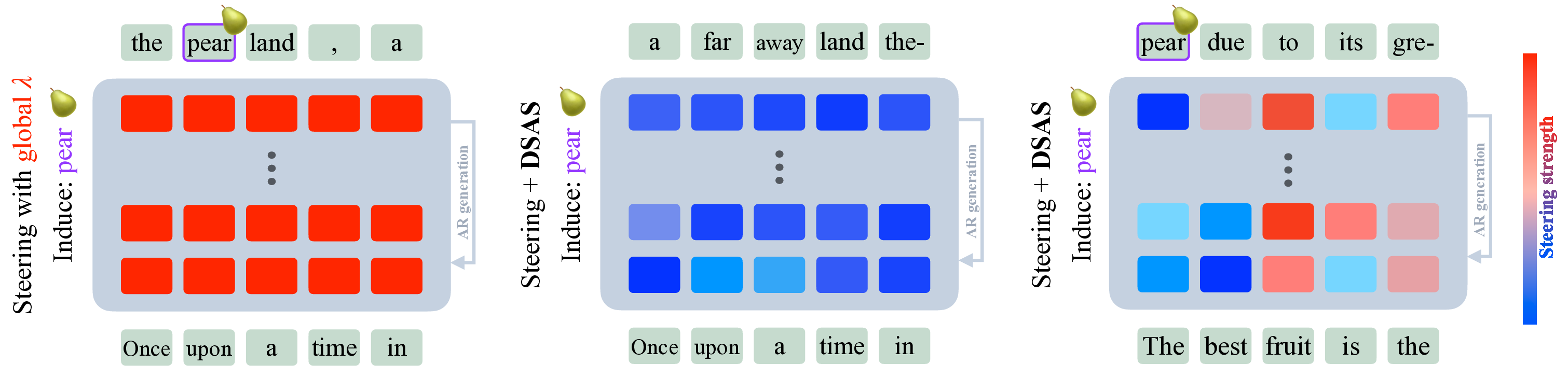
Induce: pear Figure 1 DSAS dynamically scales the intervention strengths applied to each token. Vanilla activation steering with the common strategy of applying a global strength λ, induces pear regardless of the input prompt (left). Our DSAS adapts the per-token strength of any steering technique to work only conditional to some aspect of the input, in this example, only when the concept fruit is present (right). Note how pear does not appear in (middle) since the prompt is not about fruits.
A central challenge in generative modeling is aligning model behavior with human expectations, suppressing harmful or biased outputs while preserving general capabilities. The need for such alignment has motivated research into different conditioning methods, such as prompt engineering (Marvin et al., 2023), fine-tuning (Hu et al., 2022), or activation steering (Li et al., 2023).
Activation steering has recently gained traction by effectively balancing computational cost and conditioning power. This family of techniques directly manipulate internal representations towards a desired behavior offering fine-grained control and interpretability without modifying the model weights. Previous work has
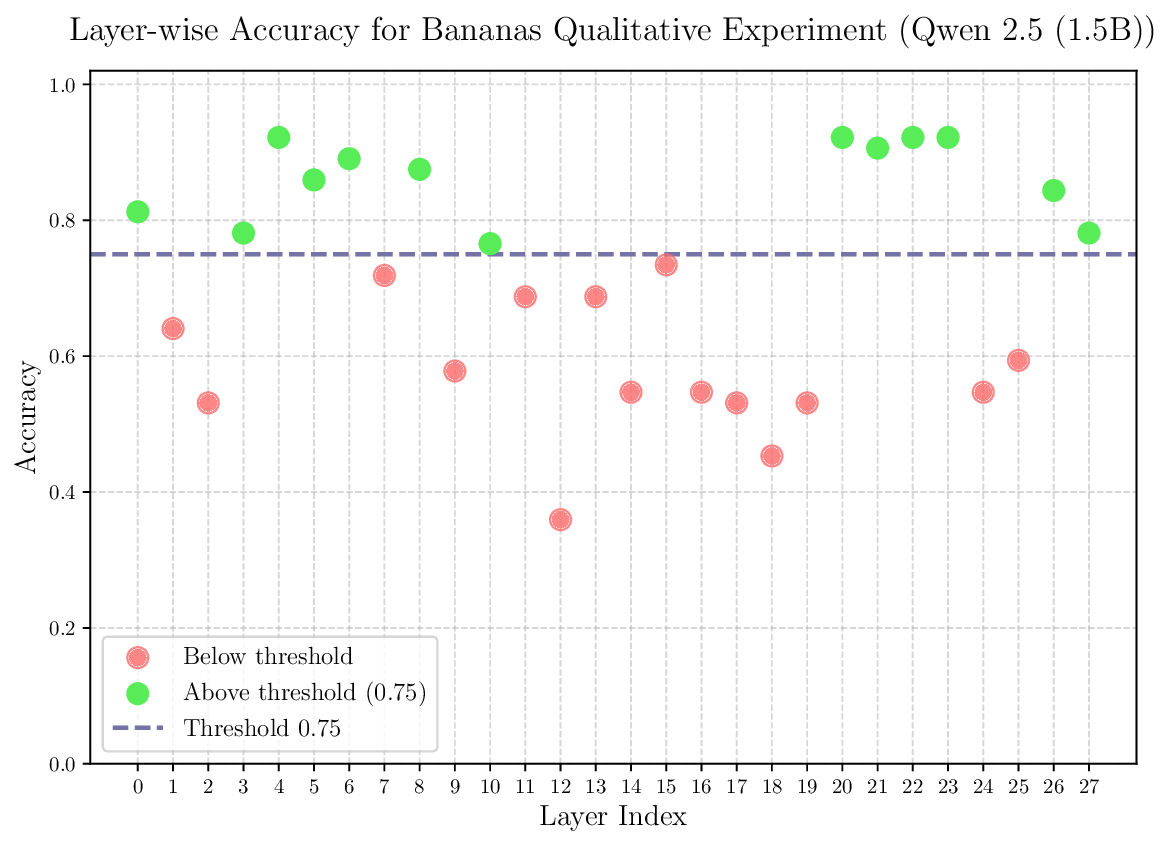
The goal of activation steering is to guide the neural network to exhibit a desired behavior, while preserving its performance in other domains. As discussed in section 1, existing literature has demonstrated promising results in eliciting target behaviors such as reducing toxicity or improving truthfulness. However, the ability to steer the model selectively, i.e., activating steering only when necessary, while maintaining its general capabilities remains underexplored and challenging. In this section, we introduce a novel method designed to enable controlled and context-dependent steering.
Following the notation from Rodríguez et al. (2025c), we define a neural network as a composition of L + 1 functions f ℓ , where each f ℓ represents a distinct component of the network (e.g., a transformer layer, a block of consecutive layers, an MLP, etc.). Thus, for a given input x ∼ X, the output of the network is
Each input is considered a sequence of K tokens t k so that x = [t 1 , . . . , t k , . . . , t K ], with t k ∈ R d .
The steering functions, namely T ℓ : R d ℓ → R d ℓ , are applied on the intermediate activations of the network, i.e., the outputs of f 1 , . . . , f L , where d ℓ denotes the dimensionality of the embedding space produced by f ℓ .
A given layer composed with an intervention, T ℓ • f ℓ , is considered an intervened layer. Note that one could choose to intervene only upon a subset of layers.
An internal activation of the original network is defined as
Similarly, an internal activation of the intervened network is defined as âℓ
It is important to note that âℓ (x) does not include the steering applied at layer ℓ itself, but only the steering up to layer ℓ -1.
For simplicity, we often refer to a ℓ and âℓ , dropping the (x) term.
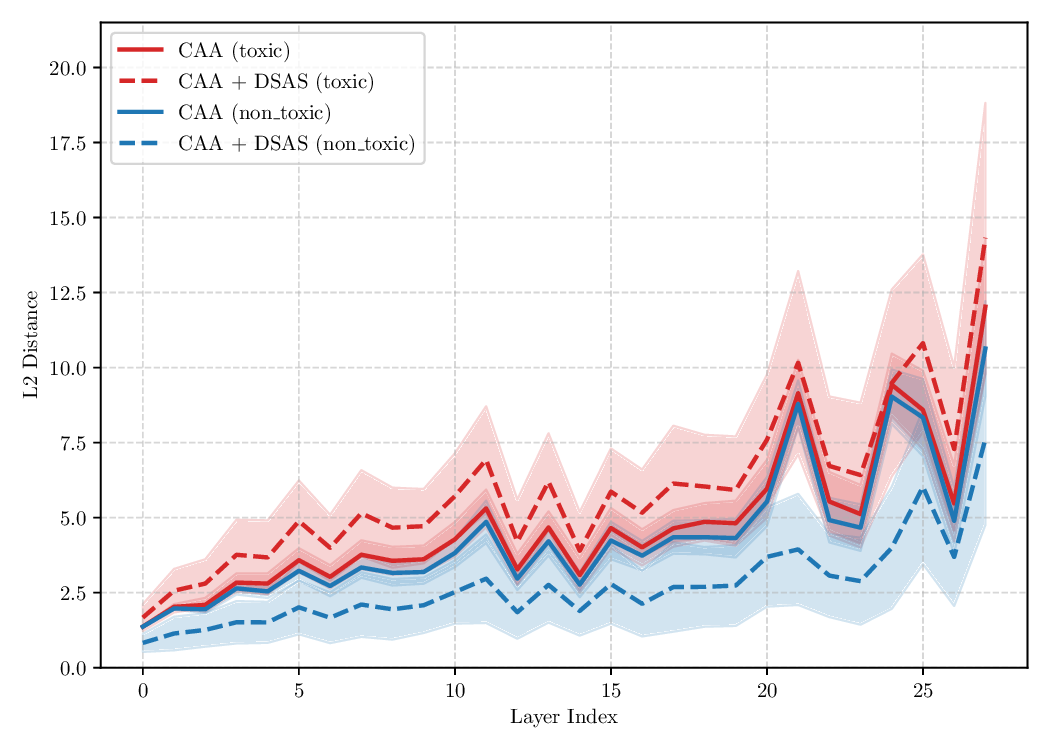
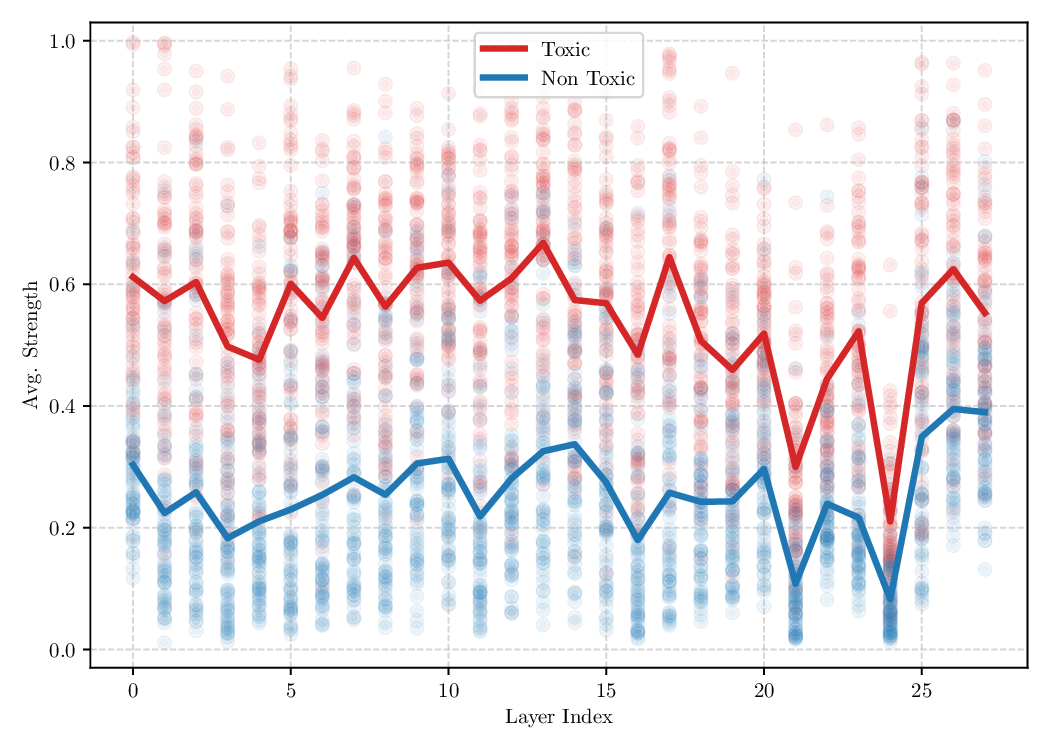
Existing activation steering methods (Li et al., 2024;Rimsky et al., 2023;Wu et al., 2024;Rodríguez et al., 2025b,c) rely on two sets of inputs to estimate the intervention functions T ℓ , namely source and target sets (see definitions 1 and 2). Typically, the source inputs are sentences that represent an unwanted behavior of the model (e.g., toxic language), while target sentences represent a wanted behavior (e.g., non-toxic language). Then, different approaches propose various ways of estimating T ℓ such that the overall model behavior is closer to the target domain.
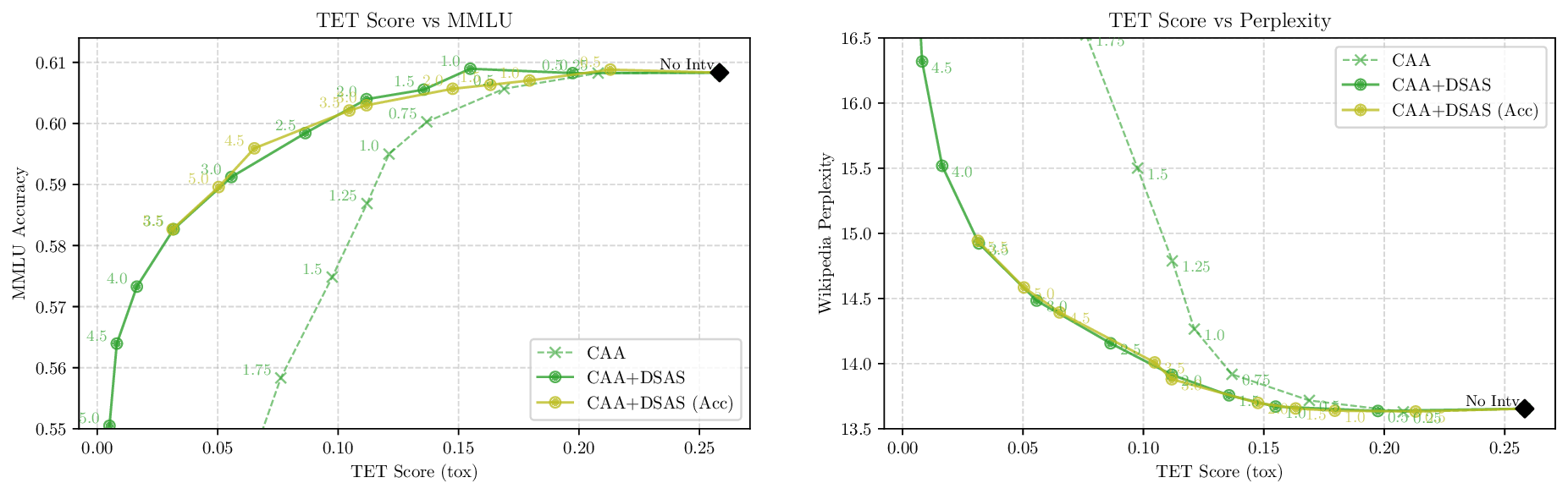
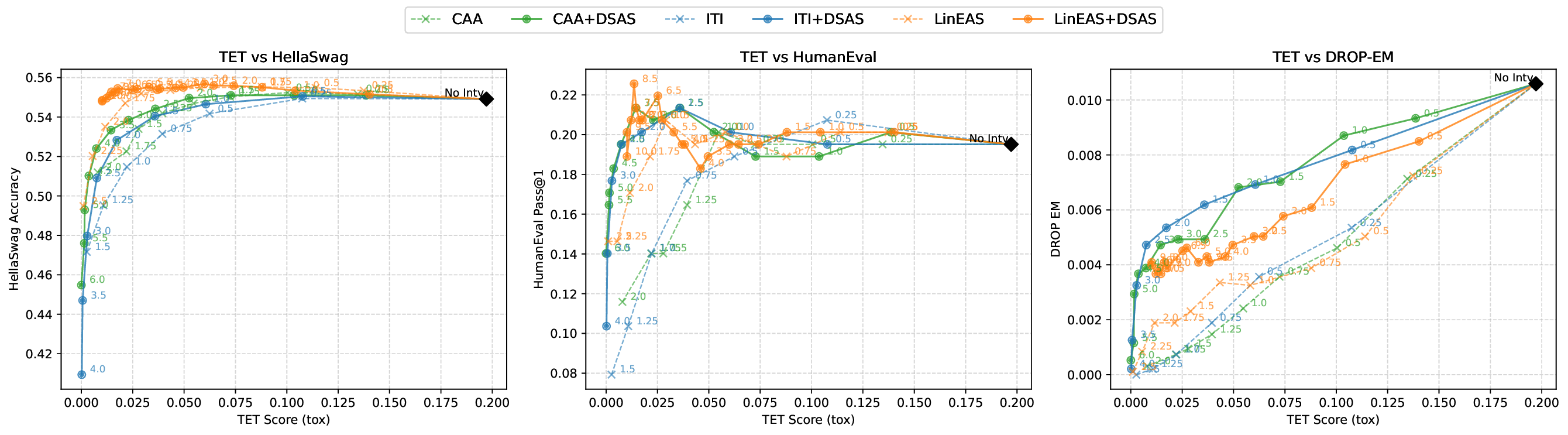
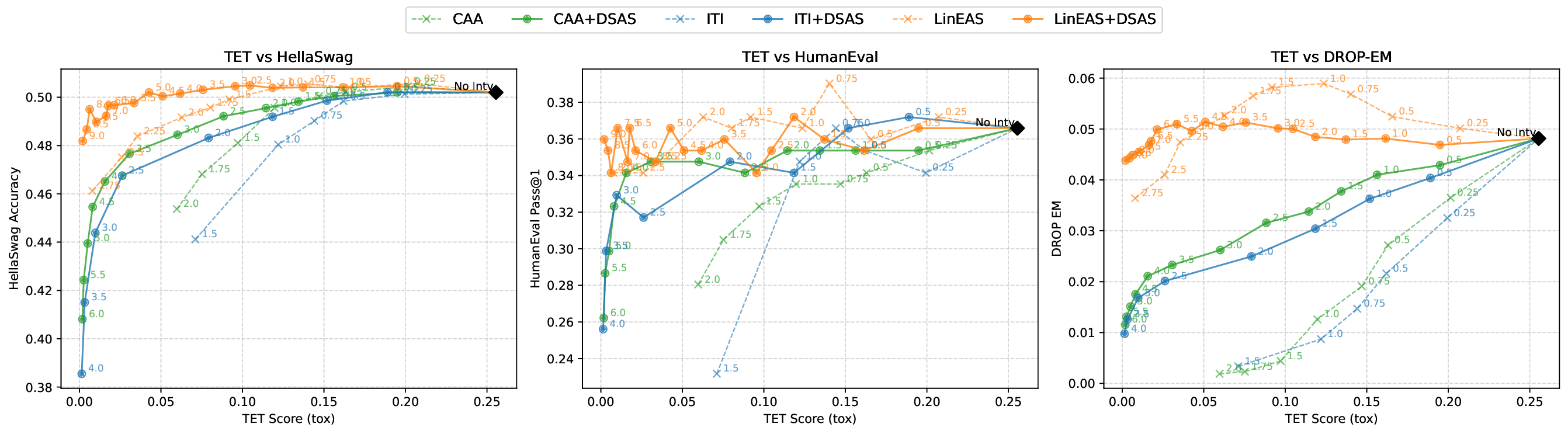
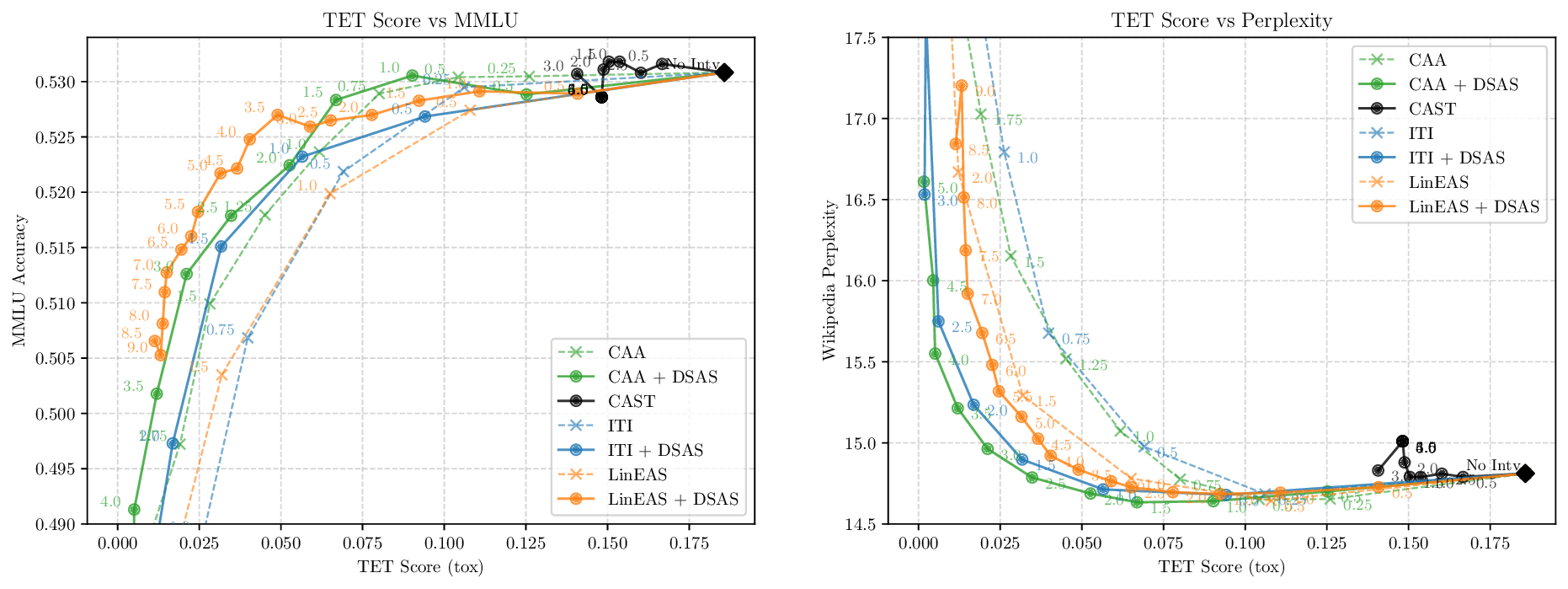
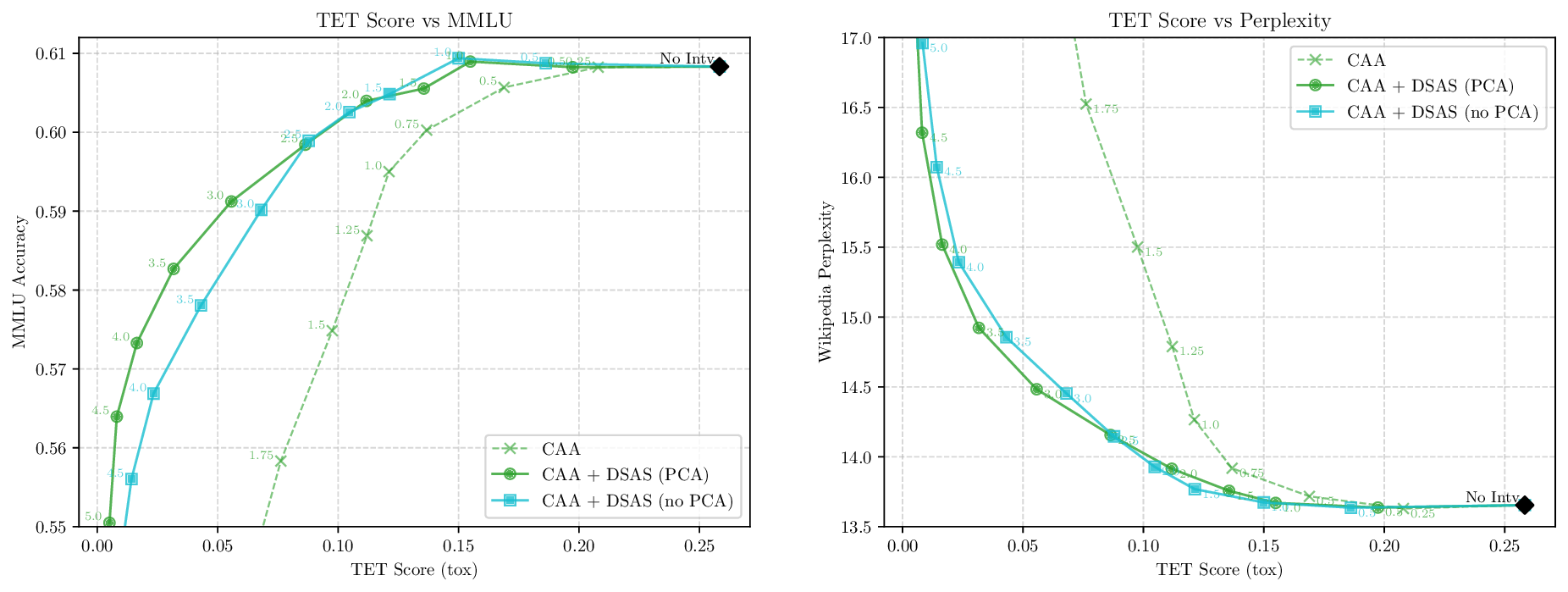
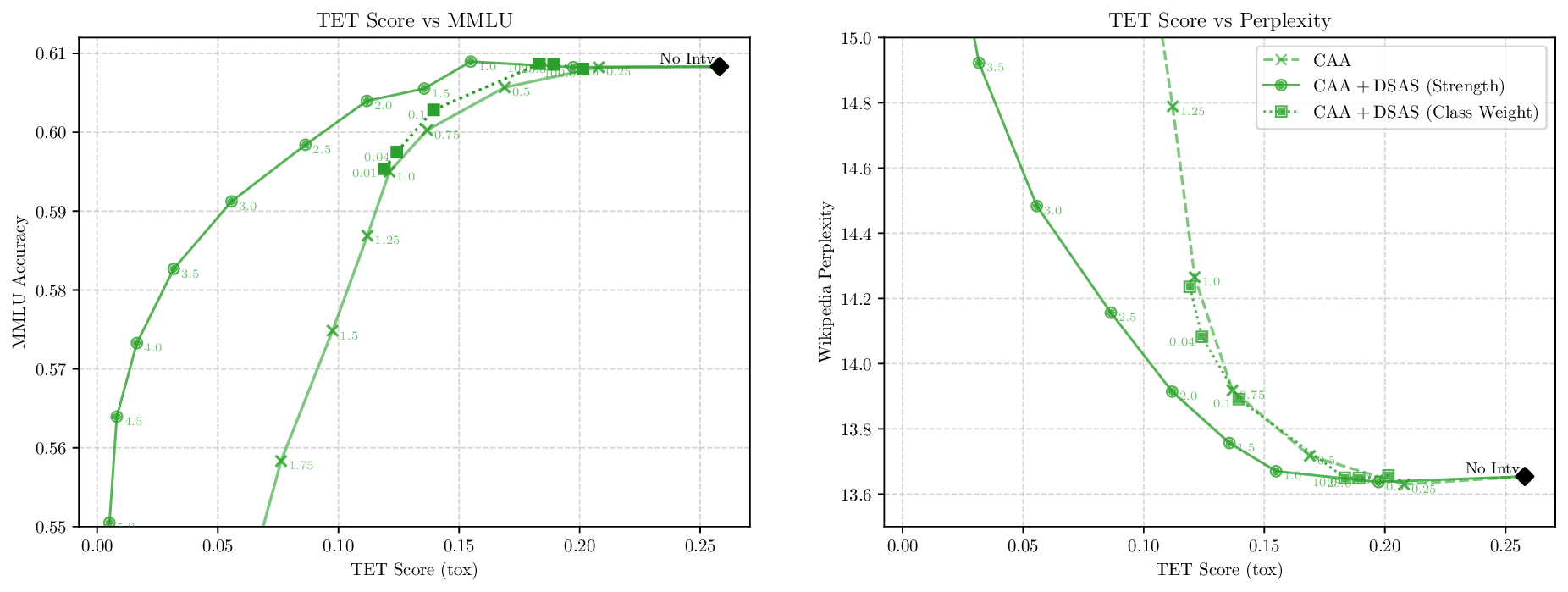
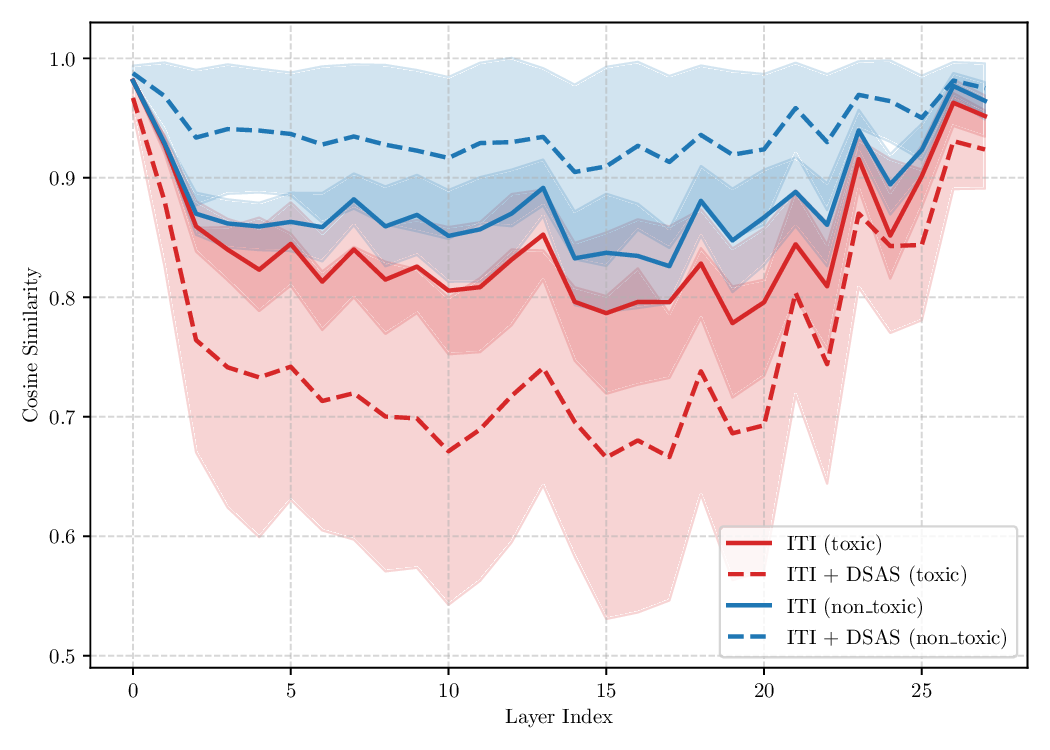
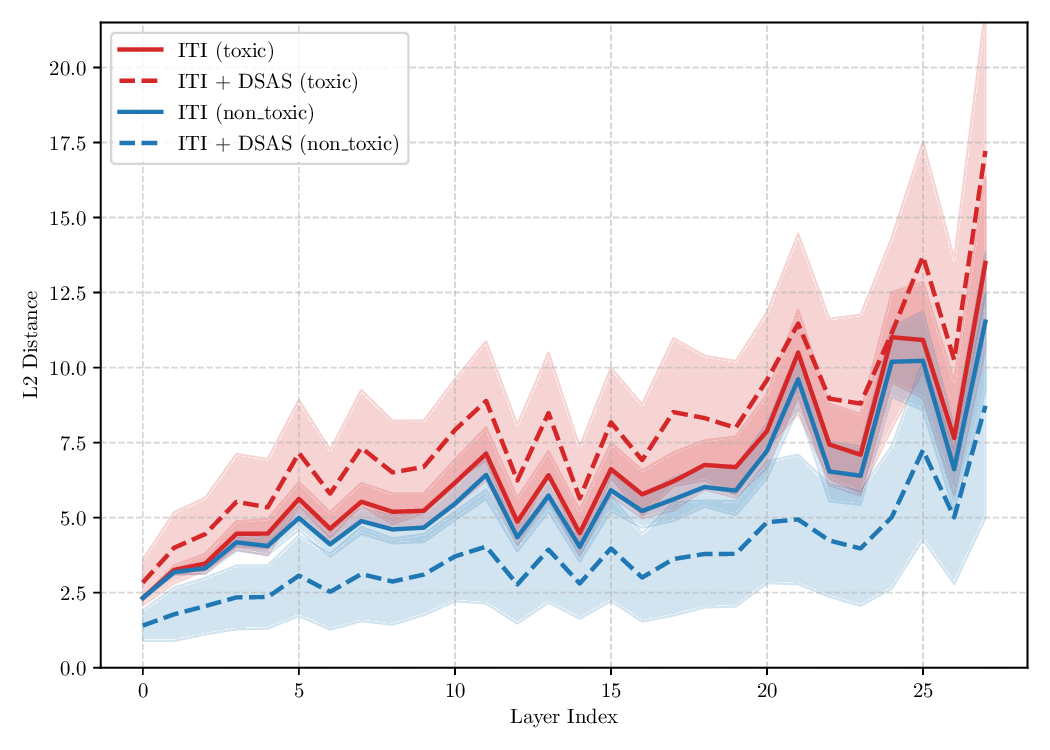
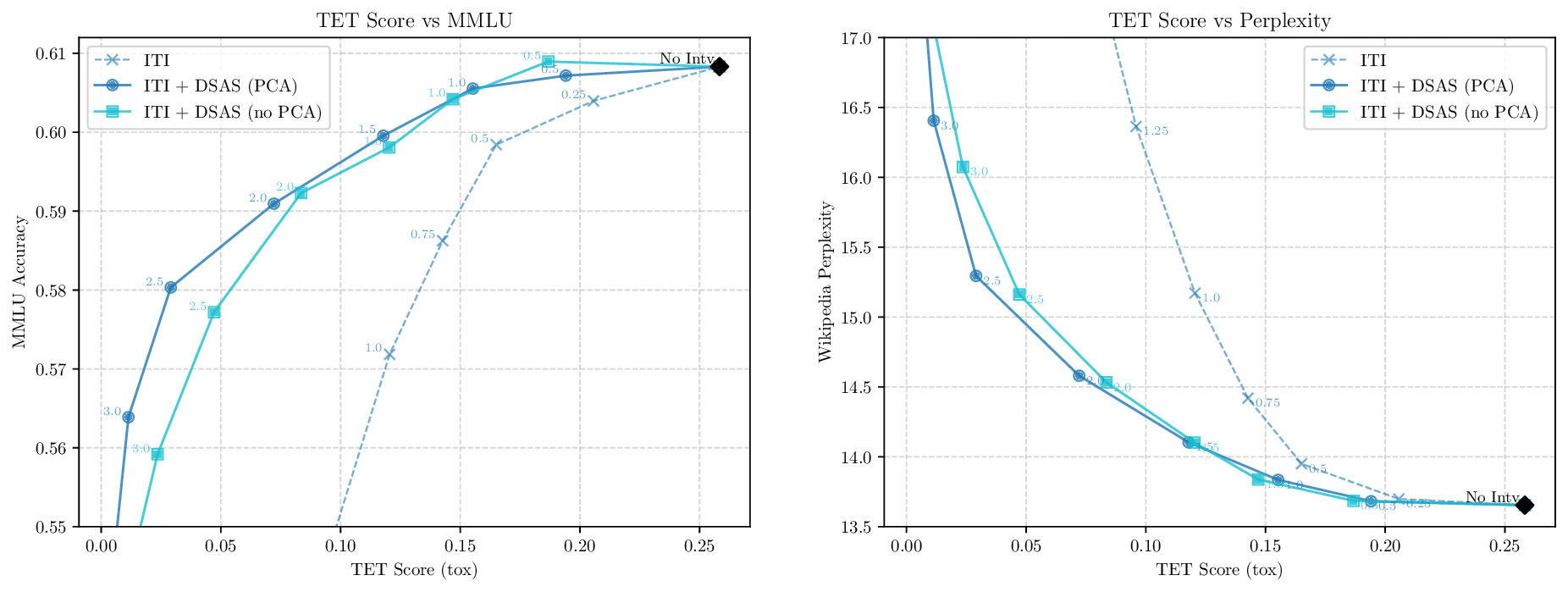
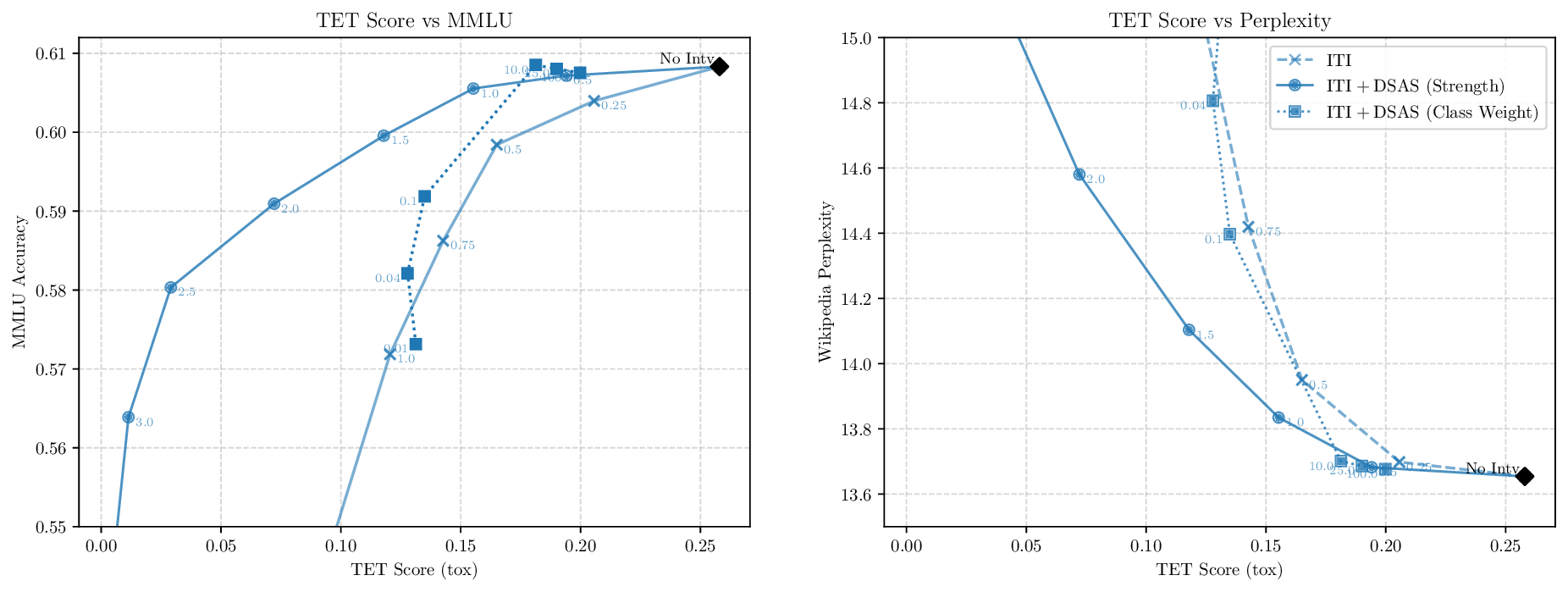
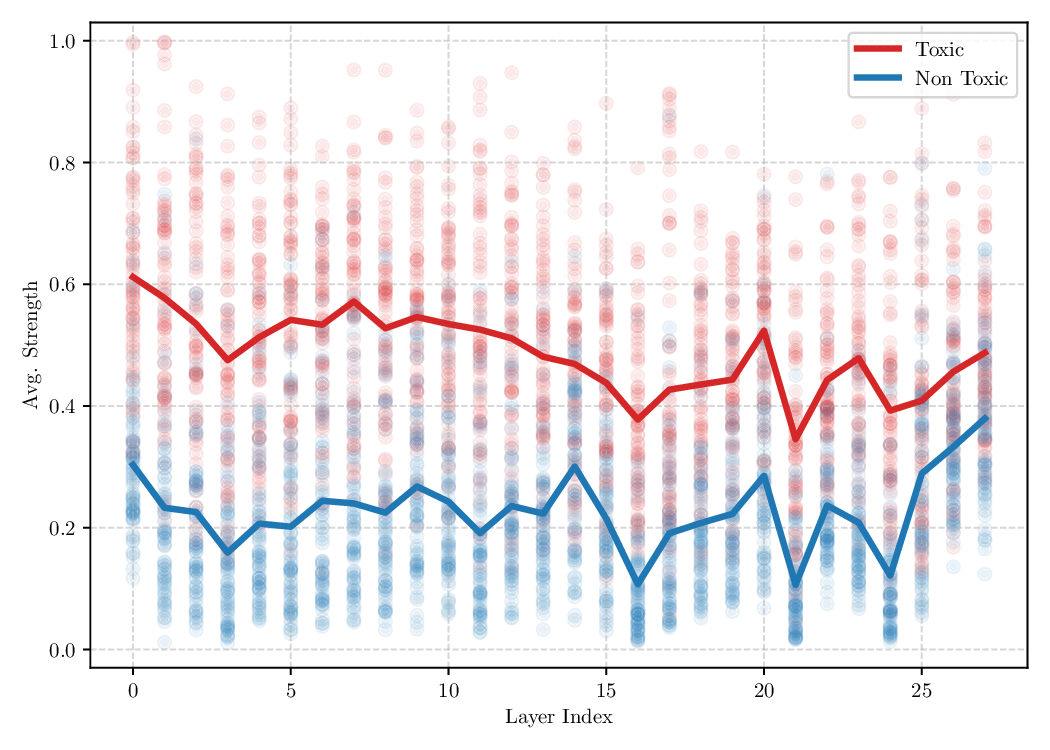
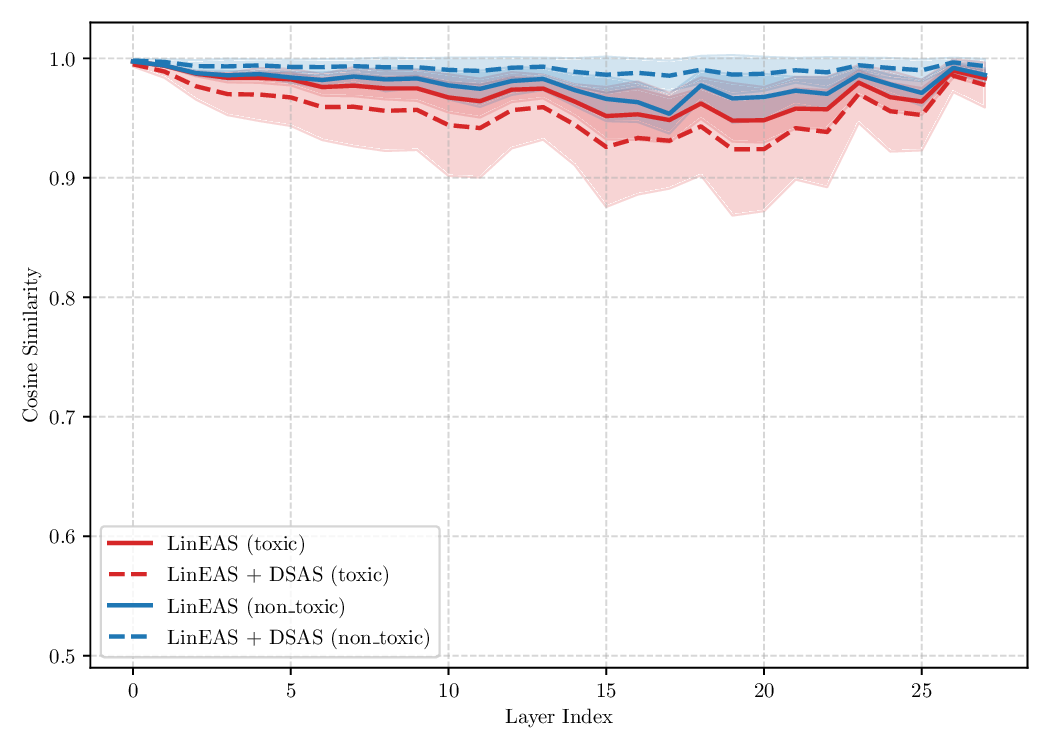
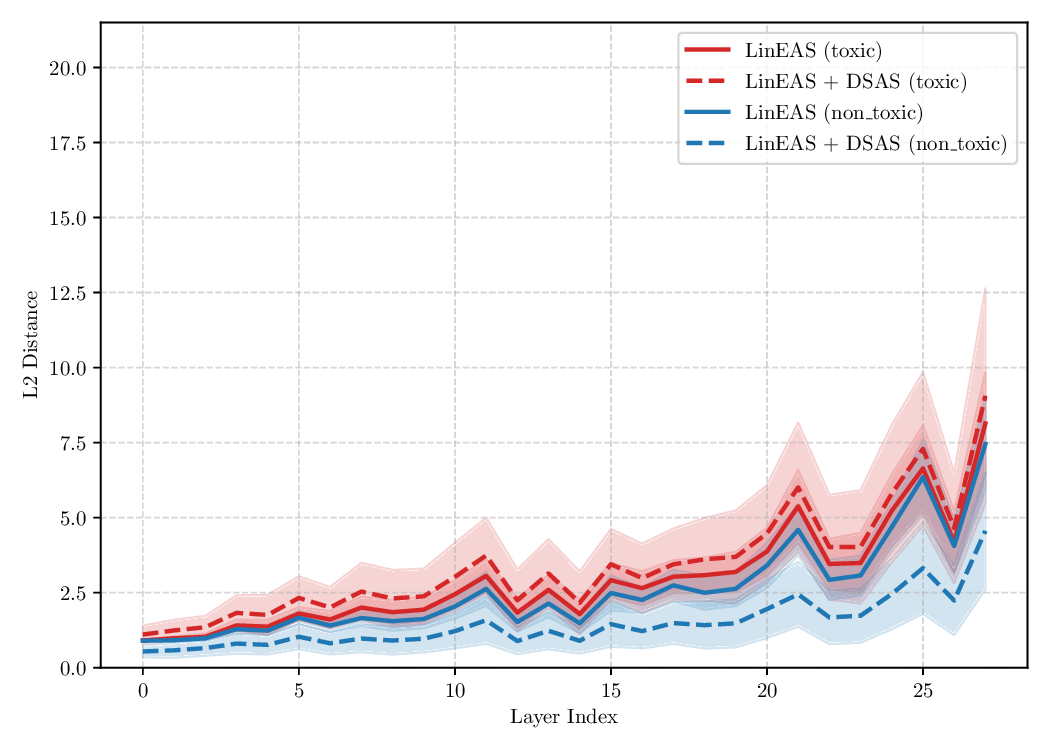
Although effective, blindly steering the model behavior towards the target domain has adverse side effects. For example, steering away from a sensitive domain like toxicity can unintentionally degrade the model’s performance on unrelated tasks, reducing its ability to generate accurate responses outside the target domain. Therefore, a core challenge in activation steering is to flexibly apply behavioral modifications only when necessary, e.g., steering inputs that exhibit undesired behaviors (represented by the source set) while preserving the model’s original performance on neutral or unrelated inputs. To this end, we use a control set (definition 3) with the goal of steering from source to target domains, while preserving the model’s original behavior on the control domain.
Definition 1 (Source set). A set of samples S = {x src,(i) } ∼ X src ⊂ X exhibiting undesired behavior ( e.g., toxicity, hallucinations). These are the examples the model should steer away from.
Definition 2 (Target set). A set of samples T = {x tgt,(i) } ∼ X tgt ⊂ X exhibiting desired behavior ( e.g., politeness, factuality). These represent the behavior the model should move towards.
Definition 3 (Control set). A set of samples C = {x ctl,(i) } ∼ X ctl ⊂ X neutral with respect to the behavior being modified. They serve as a baseline and should remain unaffected by steering.
The relationship between the control set C and the target set T d
This content is AI-processed based on open access ArXiv data.