BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents
Reading time: 5 minute
...
📝 Original Info
Title: BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents
ArXiv ID: 2512.03413
Date: 2025-12-03
Authors: Shu Wang, Yingli Zhou, Yixiang Fang
📝 Abstract
As an effective method to boost the performance of Large Language Models (LLMs) on the question answering (QA) task, Retrieval-Augmented Generation (RAG), which queries highly relevant information from external complex documents, has attracted tremendous attention from both industry and academia. Existing RAG approaches often focus on general documents, and they overlook the fact that many real-world documents (such as books, booklets, handbooks, etc.) have a hierarchical structure, which organizes their content from different granularity levels, leading to poor performance for the QA task. To address these limitations, we introduce BookRAG, a novel RAG approach targeted for documents with a hierarchical structure, which exploits logical hierarchies and traces entity relations to query the highly relevant information. Specifically, we build a novel index structure, called BookIndex, by extracting a hierarchical tree from the document, which serves as the role of its table of contents, using a graph to capture the intricate relationships between entities, and mapping entities to tree nodes. Leveraging the BookIndex, we then propose an agent-based query method inspired by the Information Foraging Theory, which dynamically classifies queries and employs a tailored retrieval workflow. Extensive experiments on three widely adopted benchmarks demonstrate that BookRAG achieves state-of-the-art performance, significantly outperforming baselines in both retrieval recall and QA accuracy while maintaining competitive efficiency.
💡 Deep Analysis
📄 Full Content
BookRAG: A Hierarchical Structure-aware Index-based Approach
for Retrieval-Augmented Generation on Complex Documents
Shu Wang
The Chinese University of Hong
Kong, Shenzhen
shuwang3@link.cuhk.edu.cn
Yingli Zhou
The Chinese University of Hong
Kong, Shenzhen
yinglizhou@link.cuhk.edu.cn
Yixiang Fang
The Chinese University of Hong
Kong, Shenzhen
fangyixiang@cuhk.edu.cn
Abstract
As an effective method to boost the performance of Large Language
Models (LLMs) on the question answering (QA) task, Retrieval-
Augmented Generation (RAG), which queries highly relevant in-
formation from external complex documents, has attracted tremen-
dous attention from both industry and academia. Existing RAG
approaches often focus on general documents, and they overlook
the fact that many real-world documents (such as books, booklets,
handbooks, etc.) have a hierarchical structure, which organizes
their content from different granularity levels, leading to poor per-
formance for the QA task. To address these limitations, we intro-
duce BookRAG, a novel RAG approach targeted for documents
with a hierarchical structure, which exploits logical hierarchies and
traces entity relations to query the highly relevant information.
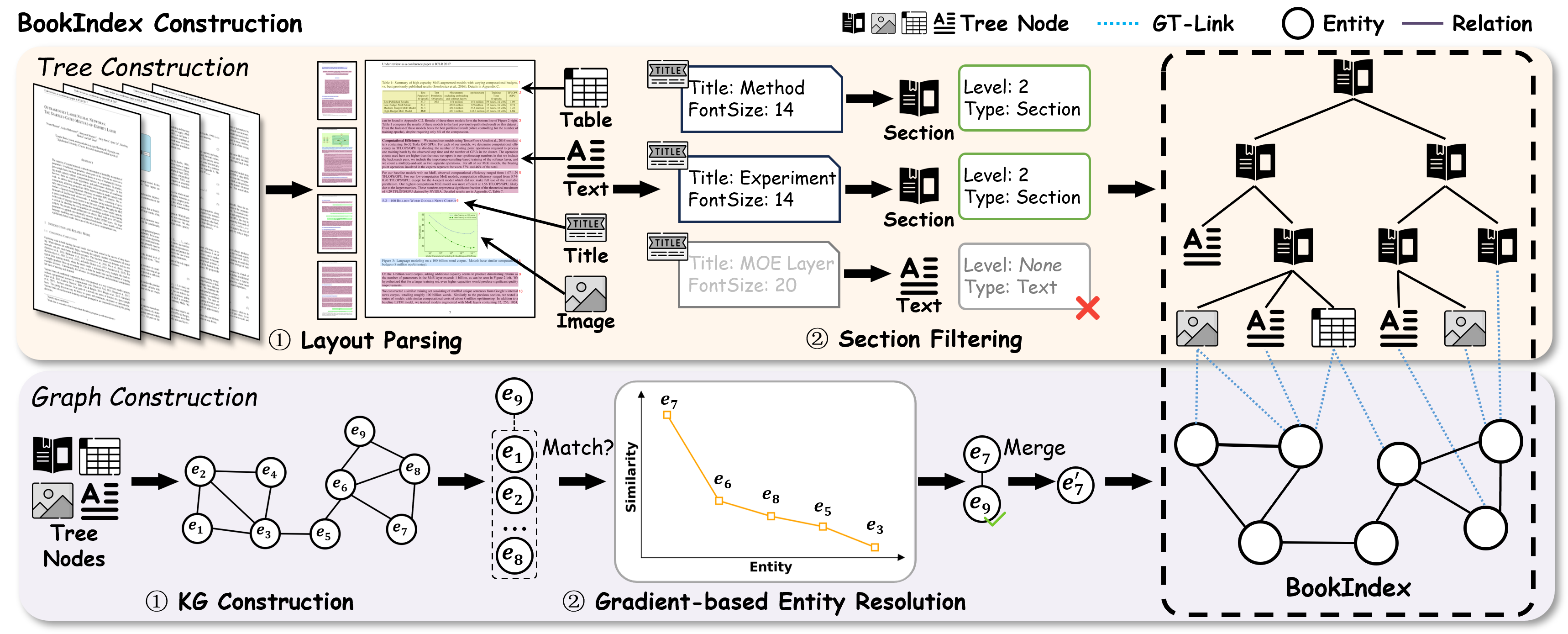
Specifically, we build a novel index structure, called BookIndex, by
extracting a hierarchical tree from the document, which serves as
the role of its table of contents, using a graph to capture the intri-
cate relationships between entities, and mapping entities to tree
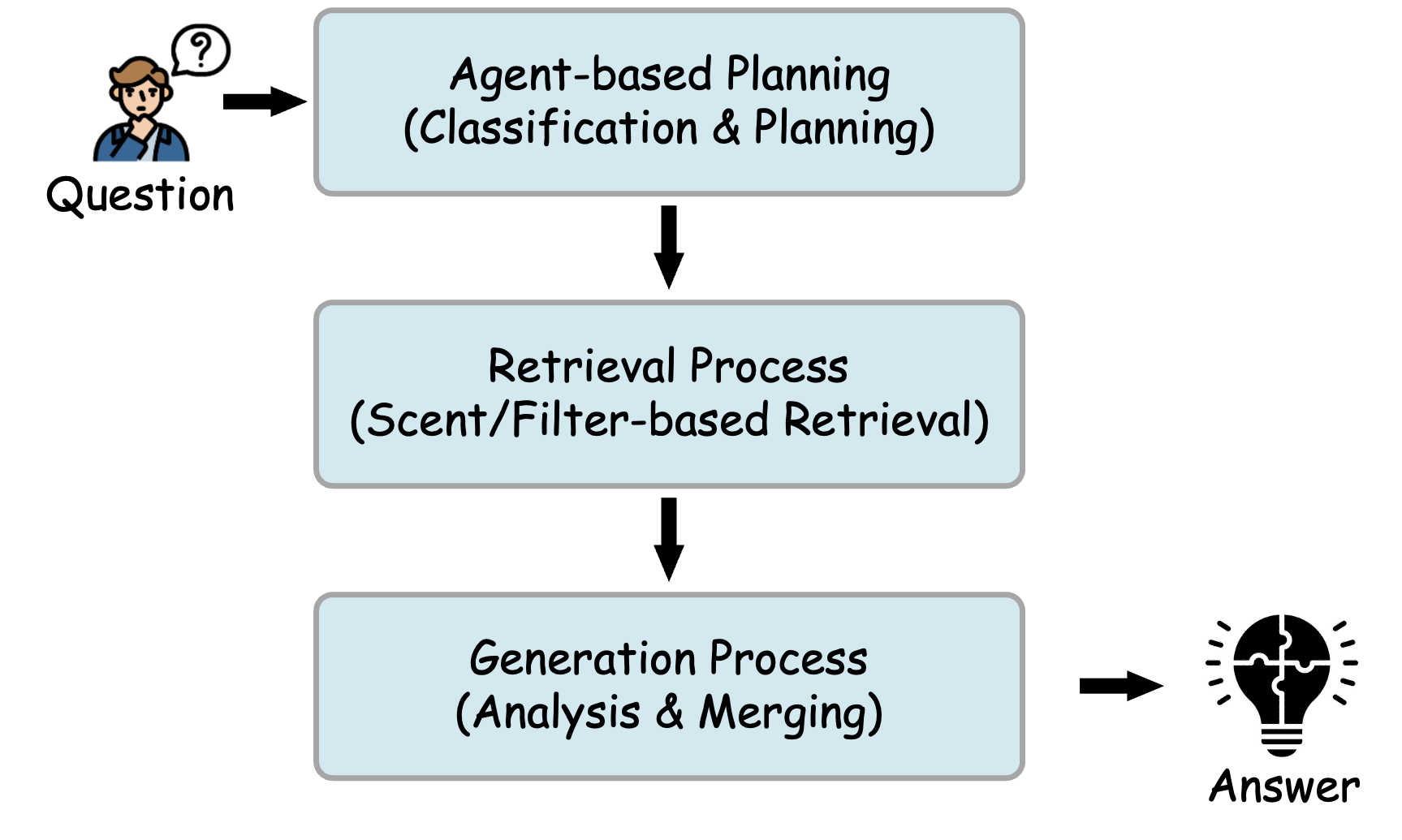
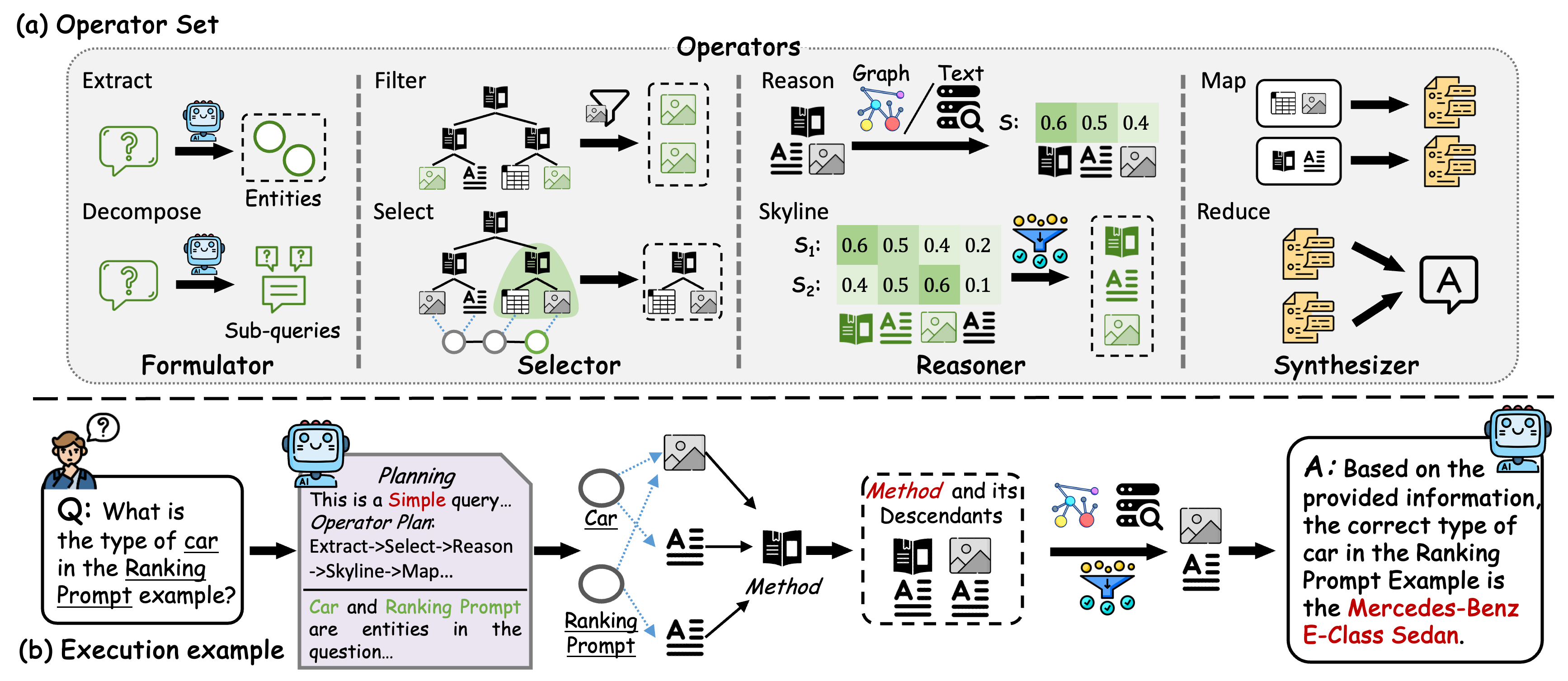
nodes. Leveraging the BookIndex, we then propose an agent-based
query method inspired by the Information Foraging Theory, which
dynamically classifies queries and employs a tailored retrieval work-
flow. Extensive experiments on three widely adopted benchmarks
demonstrate that BookRAG achieves state-of-the-art performance,
significantly outperforming baselines in both retrieval recall and
QA accuracy while maintaining competitive efficiency.
1
Introduction
Large Language Models (LLMs) such as Qwen 3 [60] and Gemini
2.5 [13] have revolutionized the Question Answering (QA) sys-
tem [15, 61, 65]. The industry has increasingly adopted LLMs to
build QA systems that assist users and reduce manual effort in
many applications [65, 67], such as financial auditing [29, 37], legal
compliance [8], and scientific discovery [56]. However, directly
relying on LLMs may lead to missing domain knowledge and gen-
erating outdated or unsupported information. To address these
issues, Retrieval-Augmented Generation (RAG) has been widely
adopted [17, 22] by retrieving relevant domain knowledge from
external sources and using it to guide the LLM during response
generation. On the other hand, in real-world enterprise scenarios,
domain knowledge is often stored in long-form documents, such
as technical handbooks, API reference manuals, and operational
guidebooks [49]. A notable feature of such documents is that they
follow the structure of books, characterized by intricate layouts and
rigorous logical hierarchies (e.g., explicit tables of contents, nested
chapters, and multi-level sections). In this paper, we aim to design
an effective RAG system for QA over long and highly structured
documents.
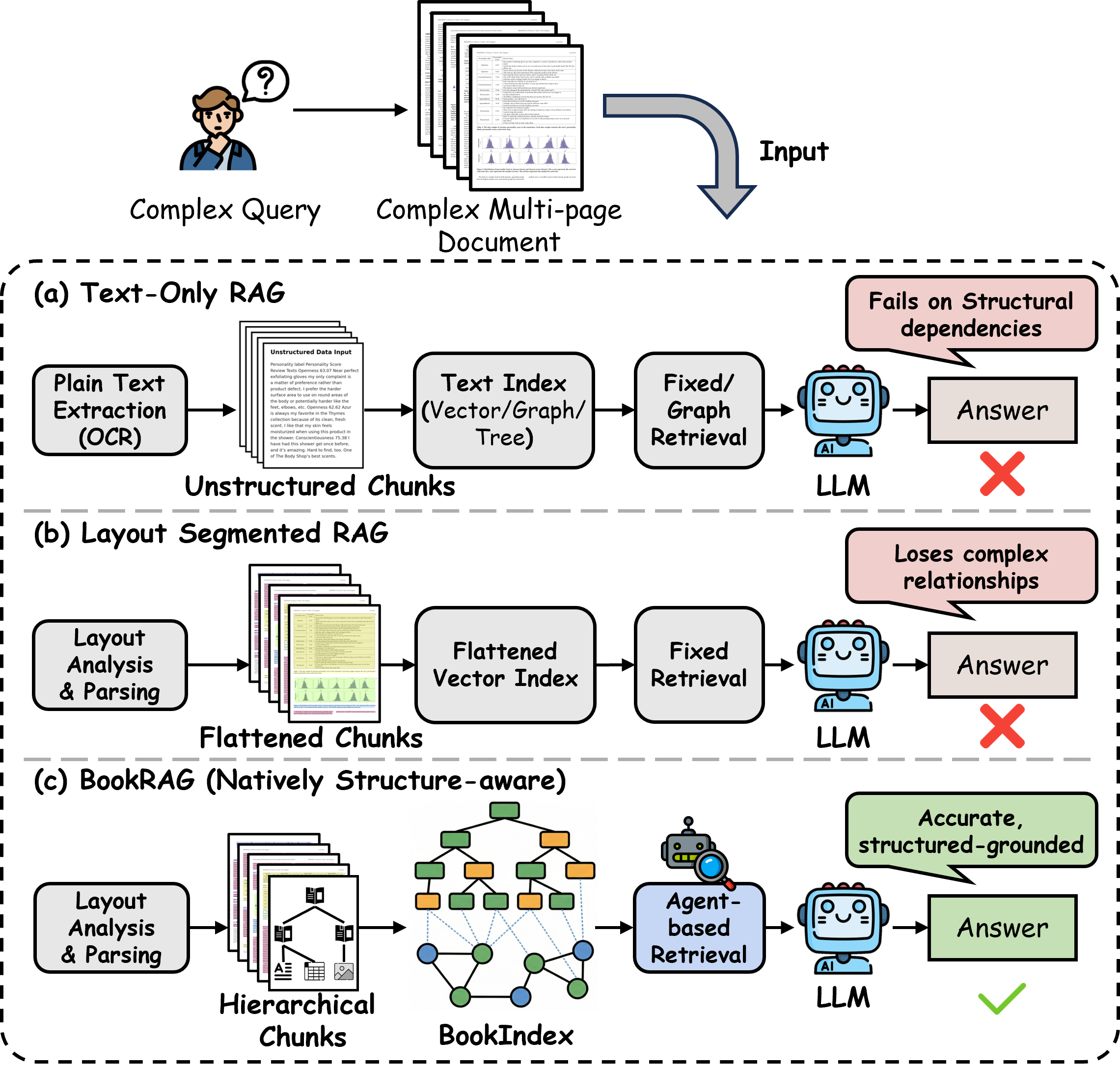
Figure 1: Comparison of existing methods and BookRAG for
complex document QA.
• Prior works. The existing RAG approaches for document-
level QA generally fall into two paradigms, as illustrated in Figure 1.
The first paradigm relies on OCR (Optical Character Recognition)
to convert the document into plain text, after which any text-based
RAG method can be directly applied. Among text-based RAG meth-
ods, state-of-the-art approaches increasingly adopt graph-based
RAG [6, 62, 66], where graph data serves as an external knowl-
edge source because it captures rich semantic information and the
relational structure between entities. As shown in Table 1, two rep-
resentative methods are GraphRAG [16] and RAPTOR [45]. Specif-
ically, GraphRAG first constructs a knowledge graph (KG) from
the textual corpus, and then applies the Leiden community detec-
tion algorithm [51] to obtain hierarchical clusters. Summaries are
generated for each community, providing a comprehensive, global
overview of the entire corpus. RAPTOR builds a recursive tree struc-
ture by iteratively clustering document chunks and summarizing
them at each level, enabling the model to capture both fine-grained
and high-level semantic information across the corpus.
In contrast, the second paradigm, layout-aware segmentation [5,
52], first parses the document into structured blocks that preserve
the original layout and information of the document, such as para-
graphs, tables, figures, or equations. By doing so, it not only avoids
the fixed chunk size used in the first paradigm, which often leads
arXiv:2512.03413v1 [cs.IR] 3 Dec 2025
Shu Wang, Yingli Zhou, and Yixiang Fang
Table 1: Comparison of representative methods and our BookRAG.
Type
Representative
Method
Core Feature
Multi-hop
Reasoning
Document
Parsing
Query
Workflow
G