📝 Original Info Title: World Models for Autonomous Navigation of Terrestrial Robots from LIDAR ObservationsArXiv ID: 2512.03429Date: 2025-12-03Authors: Raul Steinmetz, Fabio Demo Rosa, Victor Augusto Kich, Jair Augusto Bottega, Ricardo Bedin Grando, Daniel Fernando Tello Gamarra📝 Abstract Autonomous navigation of terrestrial robots using Reinforcement Learning (RL) from LIDAR observations remains challenging due to the high dimensionality of sensor data and the sample inefficiency of model-free approaches. Conventional policy networks struggle to process full-resolution LIDAR inputs, forcing prior works to rely on simplified observations that reduce spatial awareness and navigation robustness. This paper presents a novel model-based RL framework built on top of the DreamerV3 algorithm, integrating a Multi-Layer Perceptron Variational Autoencoder (MLP-VAE) within a world model to encode high-dimensional LIDAR readings into compact latent representations. These latent features, combined with a learned dynamics predictor, enable efficient imagination-based policy optimization. Experiments on simulated TurtleBot3 navigation tasks demonstrate that the proposed architecture achieves faster convergence and higher success rate compared to model-free baselines such as SAC, DDPG, and TD3. It is worth emphasizing that the DreamerV3-based agent attains a 100% success rate across all evaluated environments when using the full dataset of the Turtlebot3 LIDAR (360 readings), while model-free methods plateaued below 85%. These findings demonstrate that integrating predictive world models with learned latent representations enables more efficient and robust navigation from high-dimensional sensory data.
💡 Deep Analysis
📄 Full Content World Models for Autonomous
Navigation of Terrestrial Robots from
LIDAR observations
Journal of Intelligent & Fuzzy Systems
XX(X):1–10
©The Author(s) 2016
Reprints and permission:
sagepub.co.uk/journalsPermissions.nav
DOI: 10.1177/ToBeAssigned
www.sagepub.com/
SAGE
Raul Steinmetz1, 2, Fabio Demo Rosa1, Victor Augusto Kich2, Jair Augusto Bottega2,
Ricardo Bedin Grando3, 4 and Daniel Fernando Tello Gamarra1
Abstract
Autonomous navigation of terrestrial robots using Reinforcement Learning (RL) from LIDAR observations remains
challenging due to the high dimensionality of sensor data and the sample inefficiency of model-free approaches.
Conventional policy networks struggle to process full-resolution LIDAR inputs, forcing prior works to rely on simplified
observations that reduce spatial awareness and navigation robustness. This paper presents a novel model-based RL
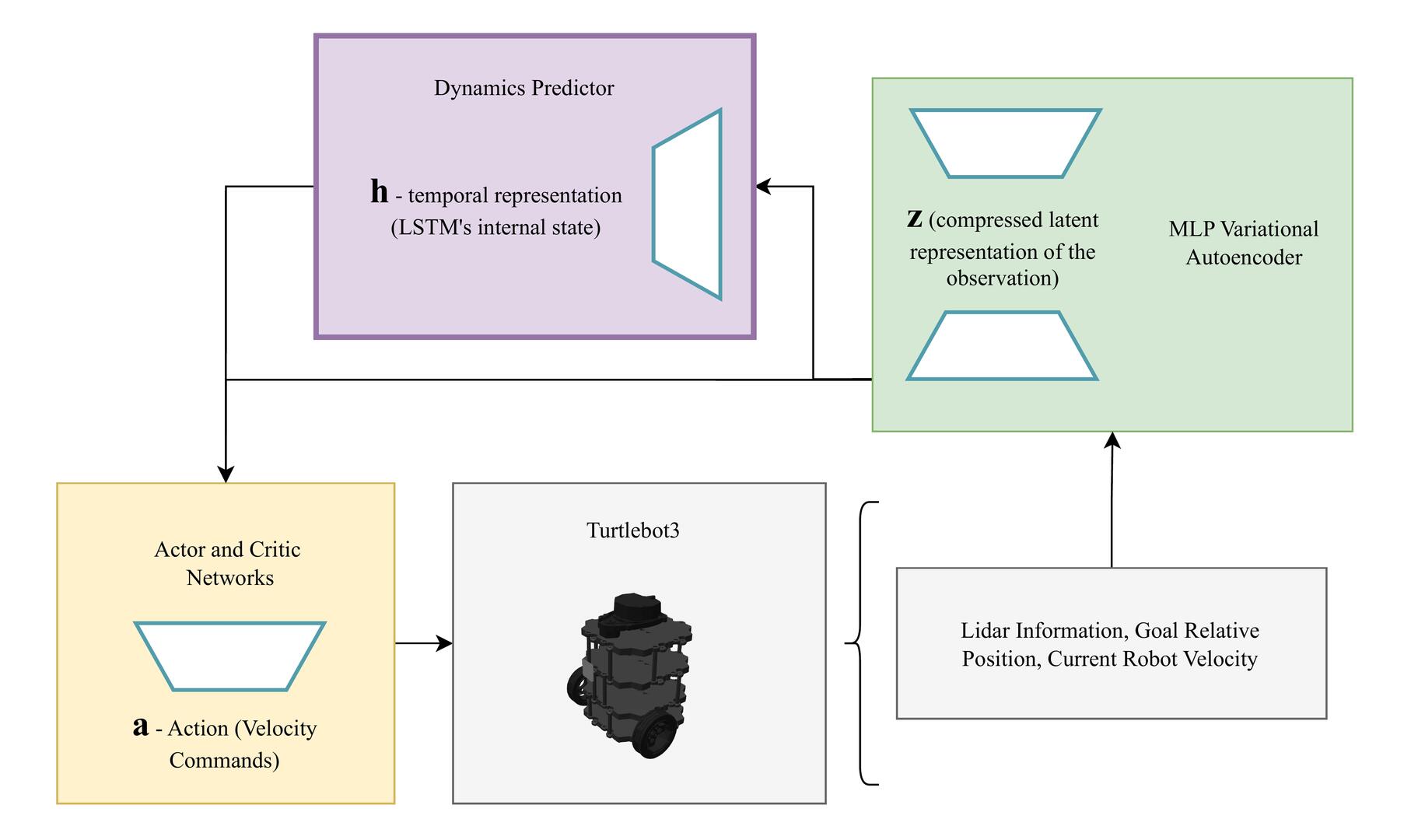
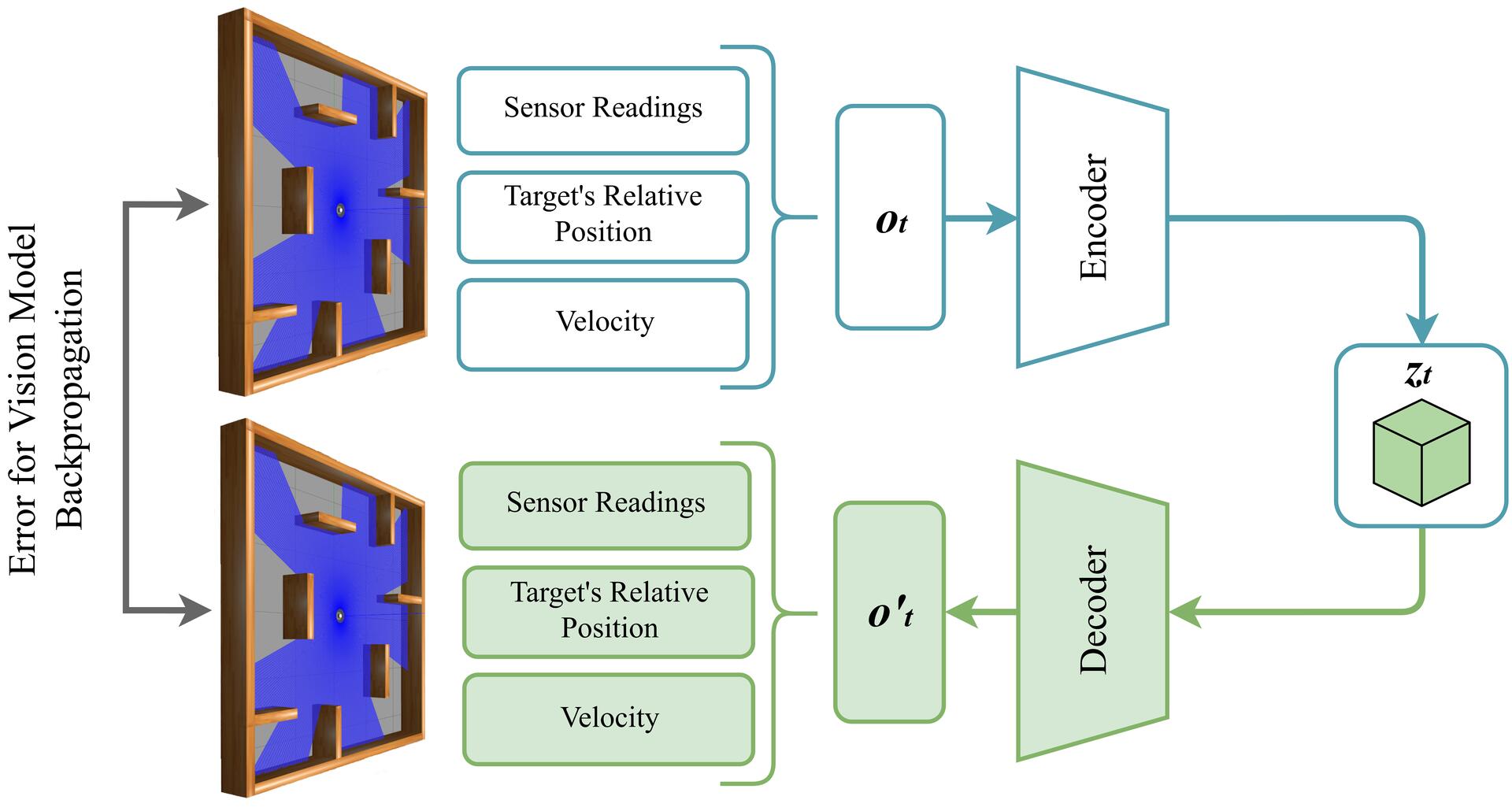
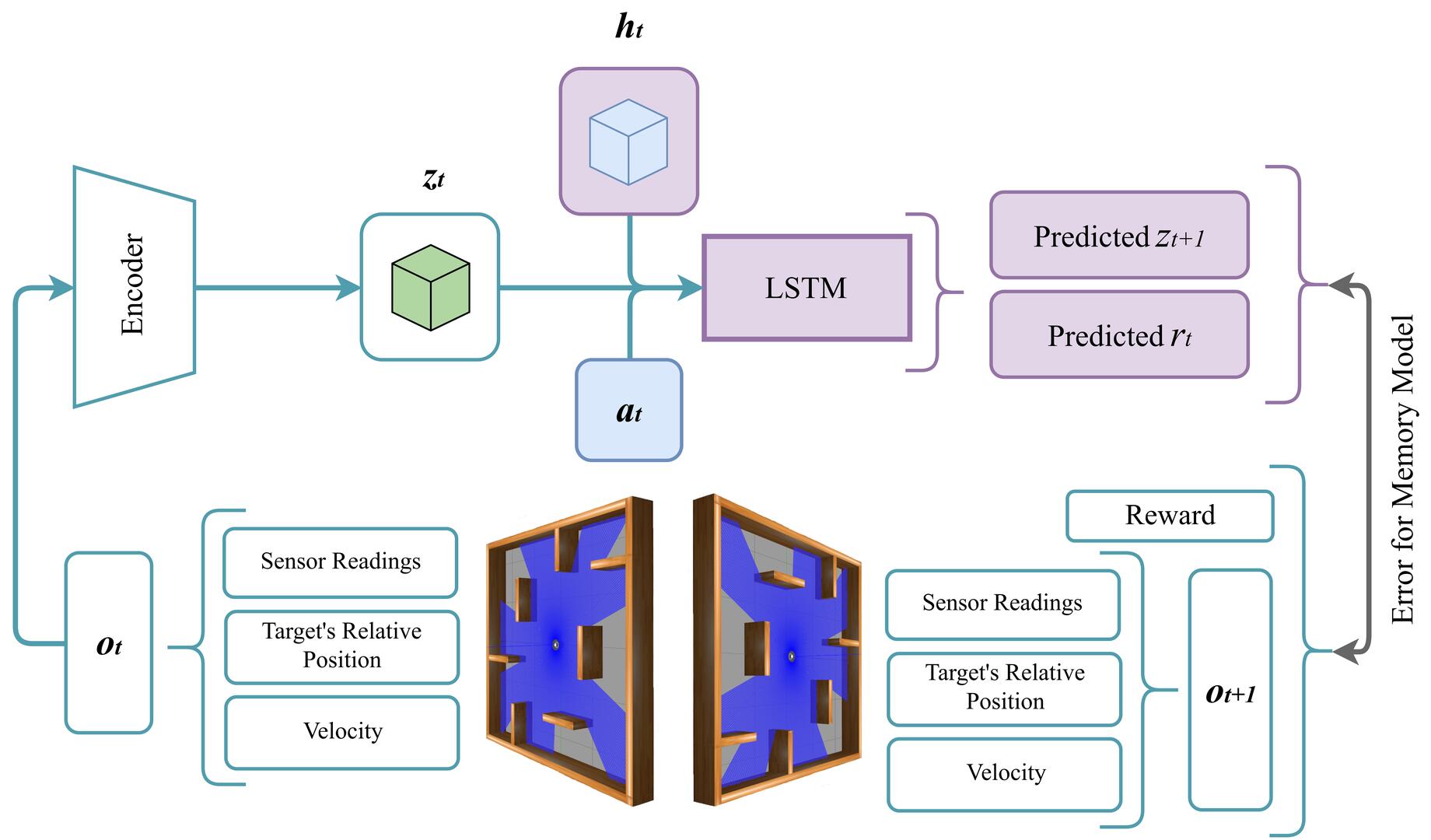
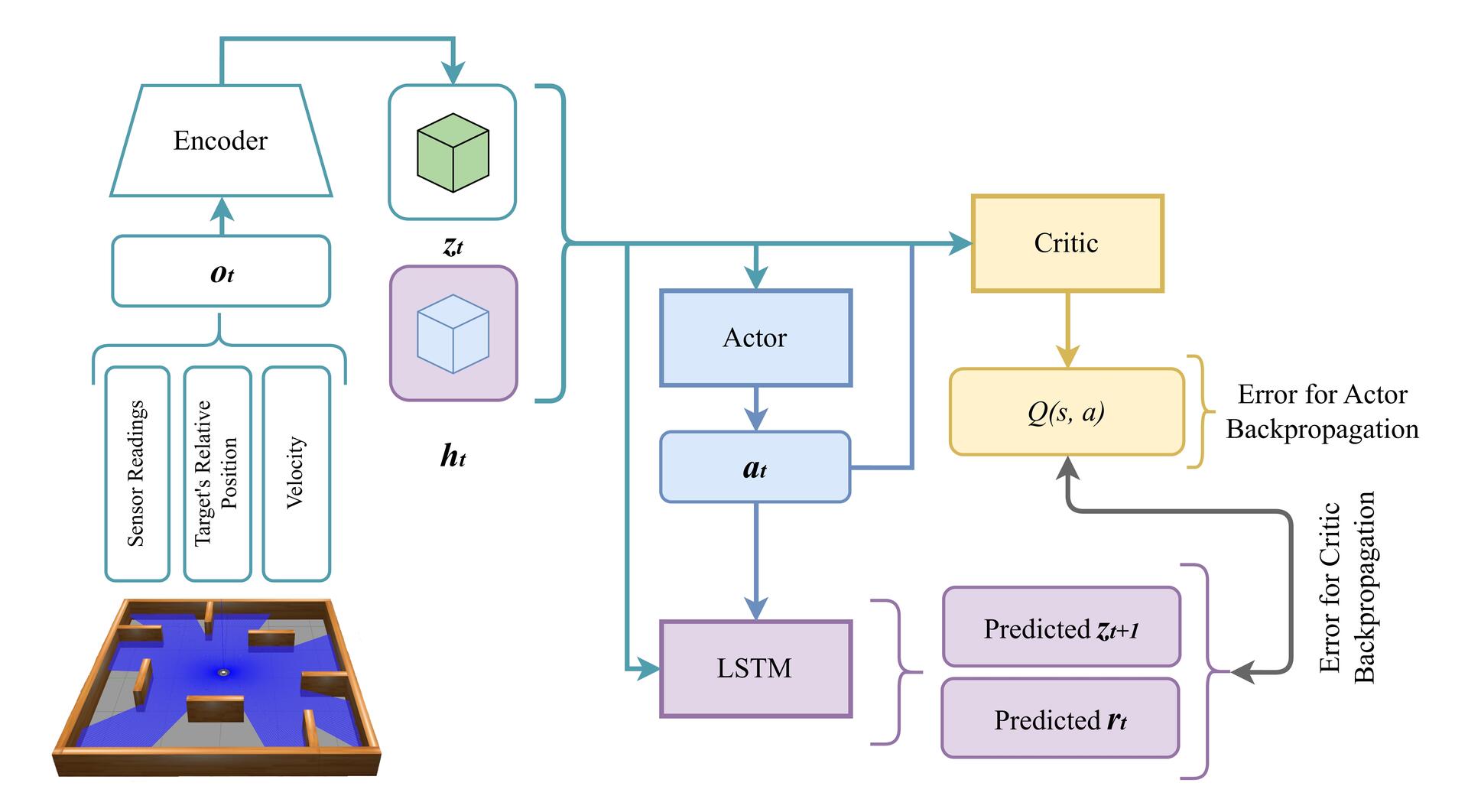
framework built on top of the DreamerV3 algorithm, integrating a Multi-Layer Perceptron Variational Autoencoder (MLP-
VAE) within a world model to encode high-dimensional LIDAR readings into compact latent representations. These
latent features, combined with a learned dynamics predictor, enable efficient imagination-based policy optimization.
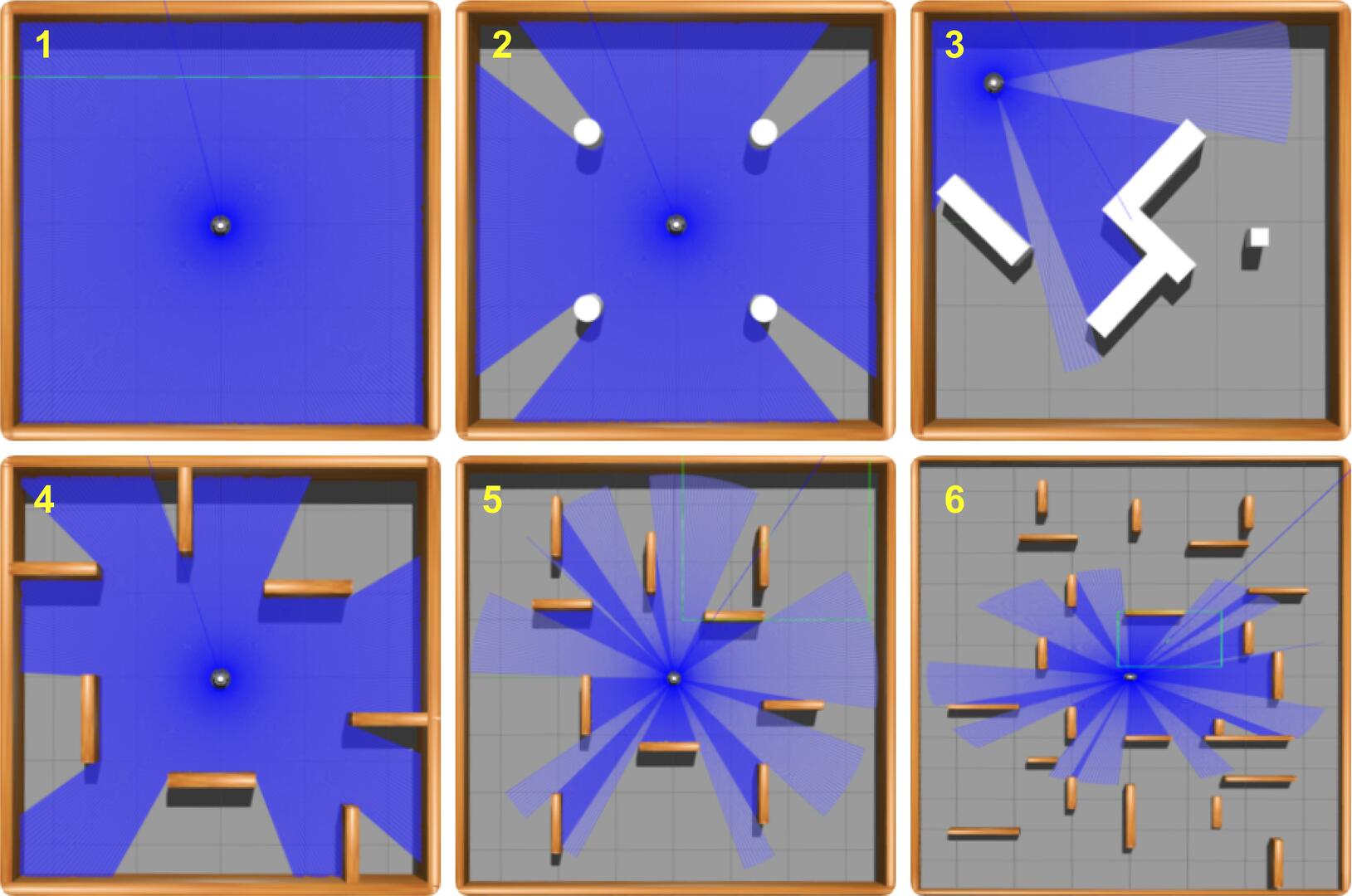
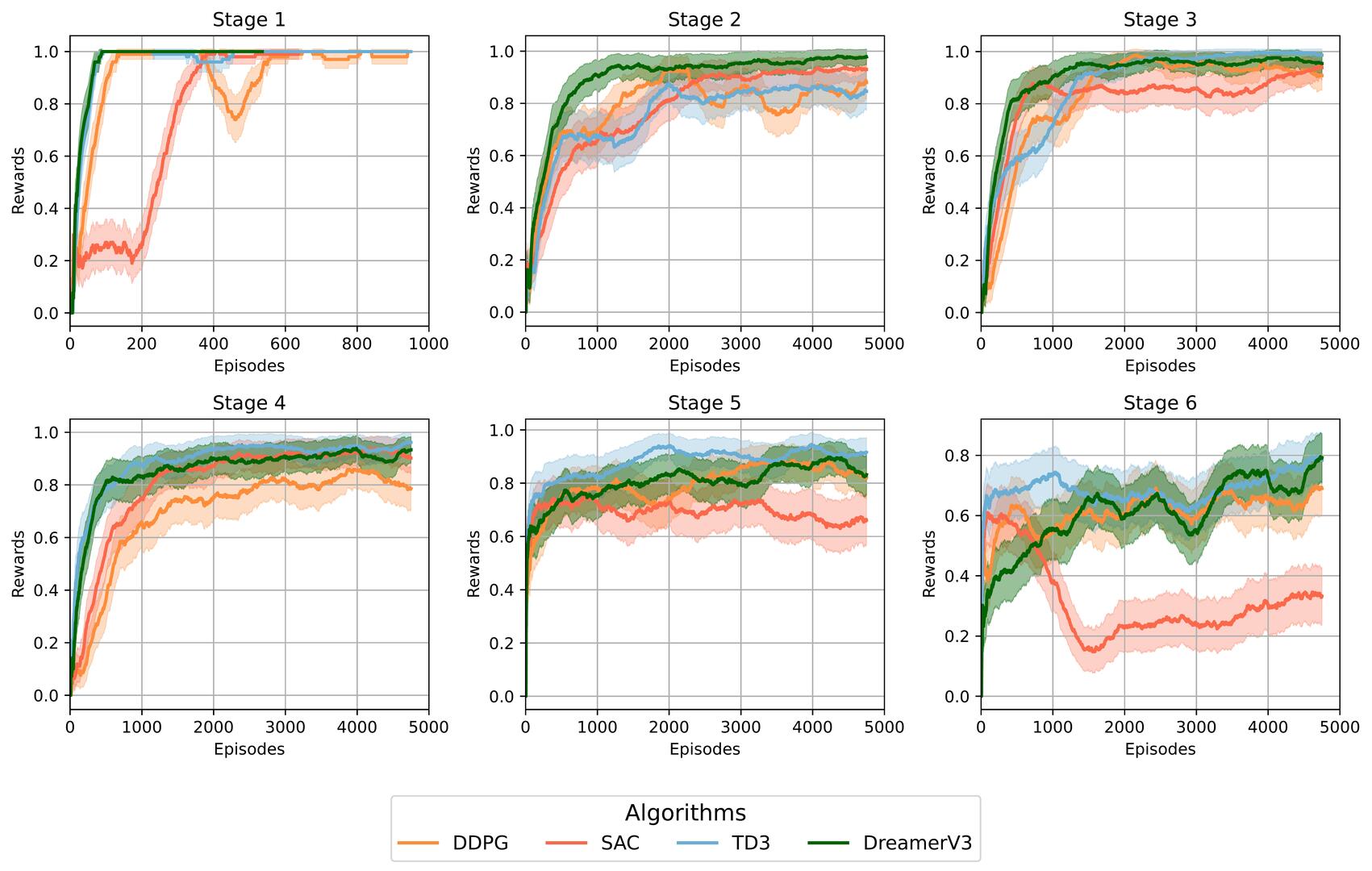
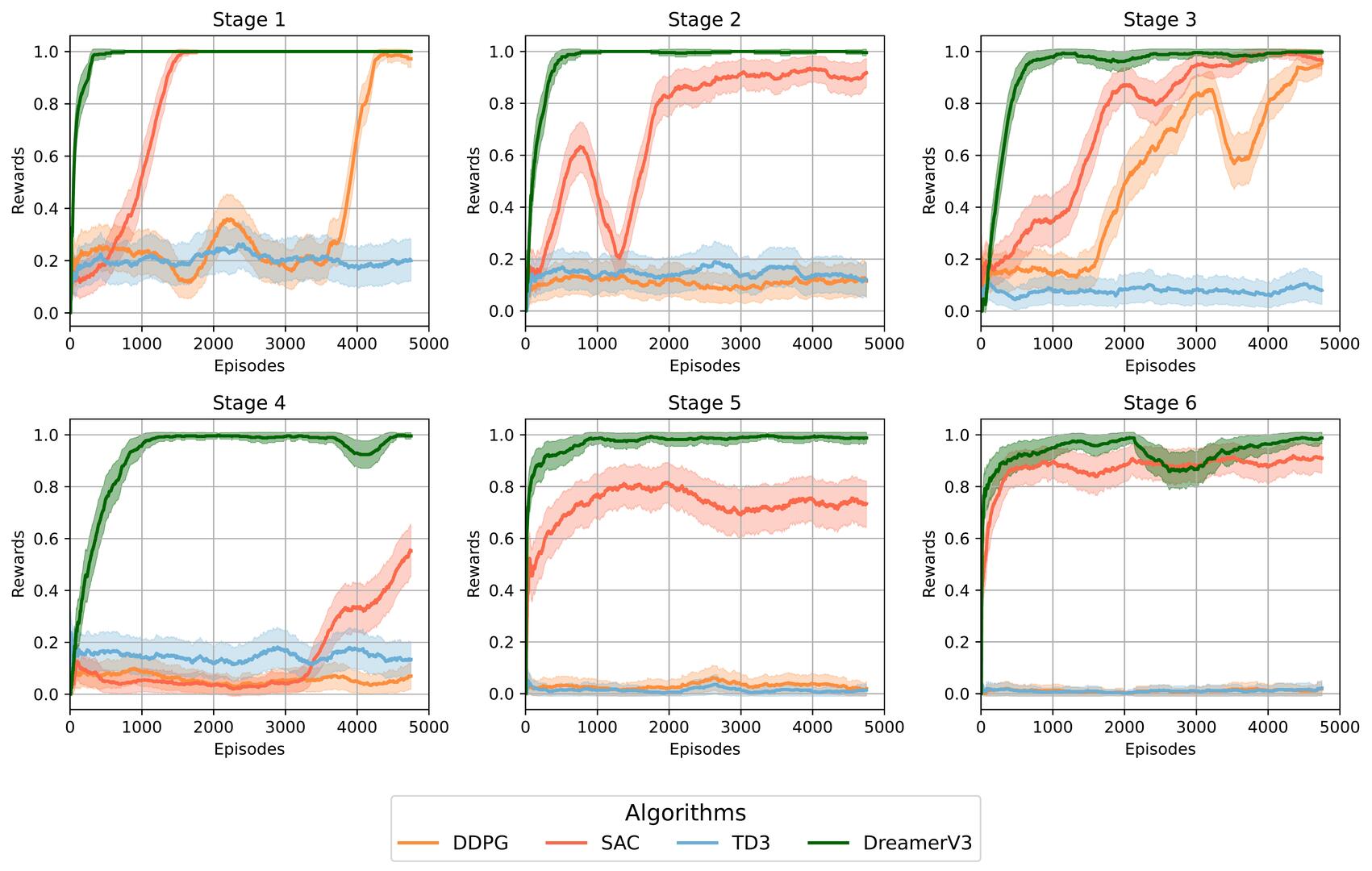
Experiments on simulated TurtleBot3 navigation tasks demonstrate that the proposed architecture achieves faster
convergence and higher success rate compared to model-free baselines such as SAC, DDPG, and TD3. It is worth
emphasizing that the DreamerV3-based agent attains a 100% success rate across all evaluated environments when
using the full dataset of the Turtlebot3 LIDAR (360 readings), while model-free methods plateaued below 85%. These
findings demonstrate that integrating predictive world models with learned latent representations enables more efficient
and robust navigation from high-dimensional sensory data.
Keywords
Deep Reinforcement Learning, Autonomous Navigation, Terrestrial Mobile Robot, TurtleBot3, World Models
Supplementary Material
The code and data used in this study are publicly available
at: https://github.com/raulsteinmetz/turtlebot-dreamerv3.
Introduction
Autonomous navigation of terrestrial robots has numerous
practical applications, including space exploration1, mining
operations2, agriculture3, household tasks4, and industrial
environments5. Deep Reinforcement Learning (DRL)6 has
emerged as a powerful approach to enabling robots
to autonomously learn complex behaviors, dynamically
adapting to diverse environments through interactions and
feedback7. DRL algorithms have demonstrated significant
potential, offering adaptive solutions to robot navigation
problems.
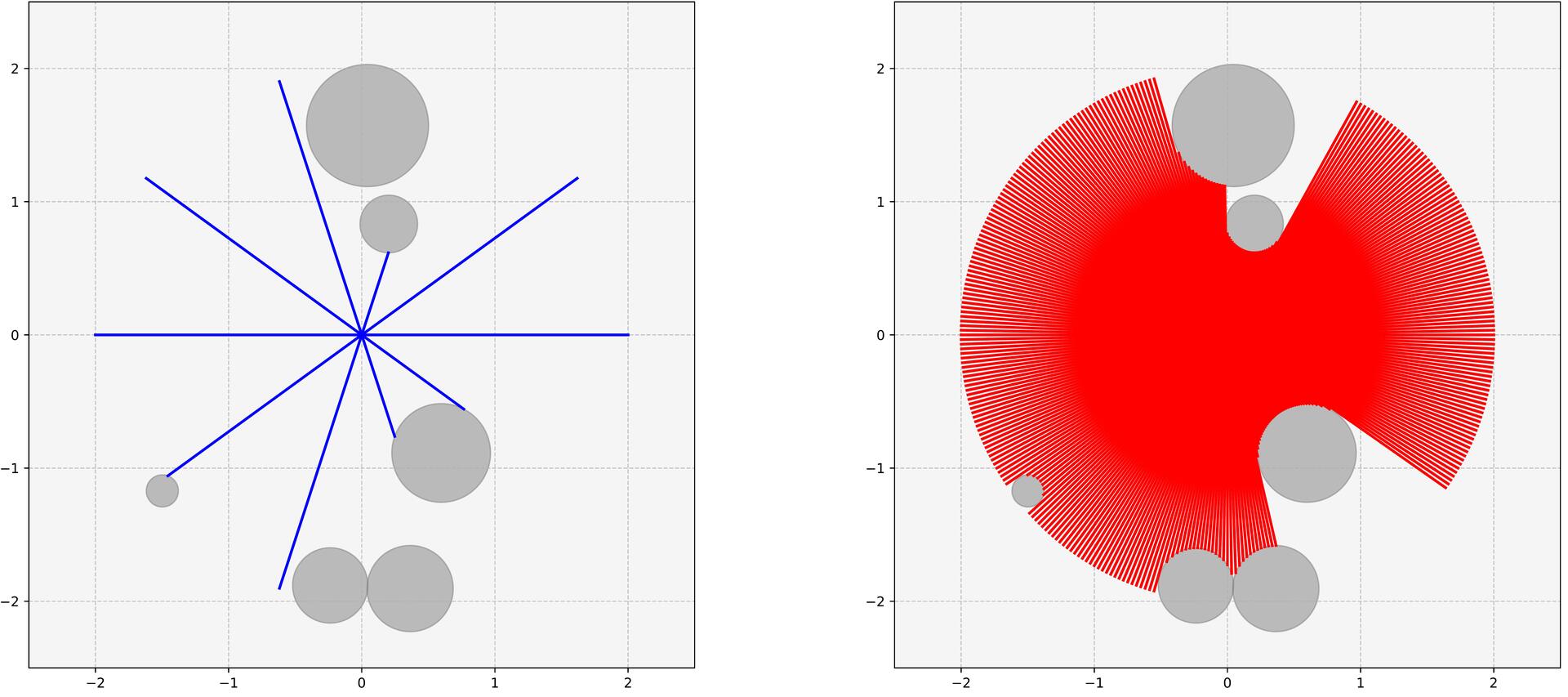
Distance sensors, especially Light Detection and Ranging
(LIDAR), are widely employed in mapless DRL-based
navigation tasks due to their reliability, computational
simplicity, and consistency across simulation and real-world
deployment. The TurtleBot38 robot is widely used as a
benchmark platform for evaluating DRL methods in mobile
navigation from LIDAR sensor observations. Prior work
has applied discrete-action algorithms, such as Deep Q-
Network (DQN)9, Double Deep Q-Network (DDQN)10, and
State-Action-Reward-State-Action (SARSA)11, as well as
continuous-action algorithms like Soft Actor Critic (SAC)12,
Deep Deterministic Policy Gradient (DDPG)13, and Twin
Delayed DDPG (TD3)14.
Model-free continuous-control algorithms such as SAC15,
DDPG16, and TD317 have achieved satisfactory performance
in relatively simple environments. However, their depen-
dence on direct interaction with the environment leads to
prolonged training periods and inefficient sample utilization.
Furthermore, these methods generally process LIDAR sen-
sor readings directly within policy networks using linear
layers, which works adequately for a limited number of
sensor inputs (usually fewer than 20 readings12–14). When
handling extensive sensor arrays, such as the complete set
of 360 readings from the LIDAR sensor of the TurtleBot3,
this direct processing approach struggles due to increased
representation complexity and sparse reward signals. These
challenges complicate the extraction of meaningful features,
hinder gradient informativeness, and degrade policy training,
leading to higher failure rates even in basic scenarios.
In contrast, model-based DRL approaches explicitly build
an internal predictive model of the environment, anticipating
future states and rewards18. This predictive capability signif-
icantly enhances decision-making efficiency, requiring fewer
1 Universidade Federal de Santa Maria, Brazil
2 University of Tsukuba, Japan
3 Universidade Federal de Rio Grande
4 Universidad Tecnológica del Uruguay, Uruguay
Corresponding author:
Daniel Fernando Tello Gamarra
Email: daniel.gamarra@ufsm.br
Prepared using sagej.cls [Version: 2017/01/17 v1.20]
arXiv:2512.03429v1 [cs.RO] 3 Dec 2025
2
Journal of Intelligent & Fuzzy Systems XX(X)
interactions with the actual environment and substantially
improving sample efficiency and reducing training time19.
Additi
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.