Title: MVRoom: Controllable 3D Indoor Scene Generation with Multi-View Diffusion Models
ArXiv ID: 2512.04248
Date: 2025-12-03
Authors: Shaoheng Fang, Chaohui Yu, Fan Wang, Qixing Huang
📝 Abstract
We introduce MVRoom, a controllable novel view synthesis (NVS) pipeline for 3D indoor scenes that uses multi-view diffusion conditioned on a coarse 3D layout. MVRoom employs a two-stage design in which the 3D layout is used throughout to enforce multi-view consistency. The first stage employs novel representations to effectively bridge the 3D layout and consistent image-based condition signals for multi-view generation. The second stage performs image-conditioned multi-view generation, incorporating a layout-aware epipolar attention mechanism to enhance multi-view consistency during the diffusion process. Additionally, we introduce an iterative framework that generates 3D scenes with varying numbers of objects and scene complexities by recursively performing multi-view generation (MVRoom), supporting text-to-scene generation. Experimental results demonstrate that our approach achieves high-fidelity and controllable 3D scene generation for NVS, outperforming state-of-the-art baseline methods both quantitatively and qualitatively. Ablation studies further validate the effectiveness of key components within our generation pipeline.
💡 Deep Analysis
📄 Full Content
MVRoom: Controllable 3D Indoor Scene Generation with Multi-View Diffusion
Models
Shaoheng Fang1*
Chaohui Yu2,3
Fan Wang2
Qixing Huang1
1The University of Texas at Austin, 2DAMO Academy, Alibaba Group, 3Hupan Lab
Abstract
We introduce MVRoom, a controllable novel view syn-
thesis (NVS) pipeline for 3D indoor scenes that uses multi-
view diffusion conditioned on a coarse 3D layout.
MV-
Room employs a two-stage design in which the 3D layout is
used throughout to enforce multi-view consistency. The first
stage employs novel representations to effectively bridge the
3D layout and consistent image-based condition signals for
multi-view generation. The second stage performs image-
conditioned multi-view generation, incorporating a layout-
aware epipolar attention mechanism to enhance multi-view
consistency during the diffusion process. Additionally, we
introduce an iterative framework that generates 3D scenes
with varying numbers of objects and scene complexities by
recursively performing multi-view generation (MVRoom),
supporting text-to-scene generation. Experimental results
demonstrate that our approach achieves high-fidelity and
controllable 3D scene generation for NVS, outperforming
state-of-the-art baseline methods both quantitatively and
qualitatively. Ablation studies further validate the effective-
ness of key components within our generation pipeline.
1. Introduction
Creating high-quality 3D content is crucial for immersive
applications in augmented reality (AR), virtual reality (VR),
gaming, and filmmaking. Yet producing detailed 3D as-
sets remains challenging and labor-intensive, often requir-
ing professional skills and tools. Recent advances in gener-
ative modeling enable text-to-3D object synthesis, stream-
lining creation [20, 32]. However, generating 3D scenes is
more complex, as it involves creating numerous objects ar-
ranged within complex spatial layouts, and the generated
scenes must exhibit realism to ensure authenticity and user
engagement.
Several methods have recently been proposed to address
3D scene generation [7, 9, 14, 23, 31, 38, 56–58]. Compo-
sition approaches first generate objects via text-to-3D tech-
*Work done during internship at DAMO Academy, Alibaba Group
niques and then assemble a full scene [7, 57, 58]. While
these methods leverage the strengths of 3D object gener-
ation, they frequently fall short in overall scene realism.
Other methods adopt incremental generation frameworks.
They construct 3D indoor environments by sequentially
synthesizing different viewpoints frame by frame and re-
constructing room meshes from these images [14, 31, 56].
However, these methods always suffer from error accumu-
lation and weak layout control, making it difficult to ensure
a coherent spatial arrangement.
To address these limitations, we propose a novel ap-
proach MVRoom for multi-view-based 3D scene genera-
tion, conditioned on initial scene image(s) and a coarse 3D
layout (oriented object bounding boxes with class labels).
The 3D layout, which can be obtained from user input or
off-the-shelf 3D layout generative models, provides a flex-
ible and easily editable representation, serving as essential
guidance of our framework. Moreover, the initial images
can be generated using text-2-image models (see Figure 5
and the accompanying video).
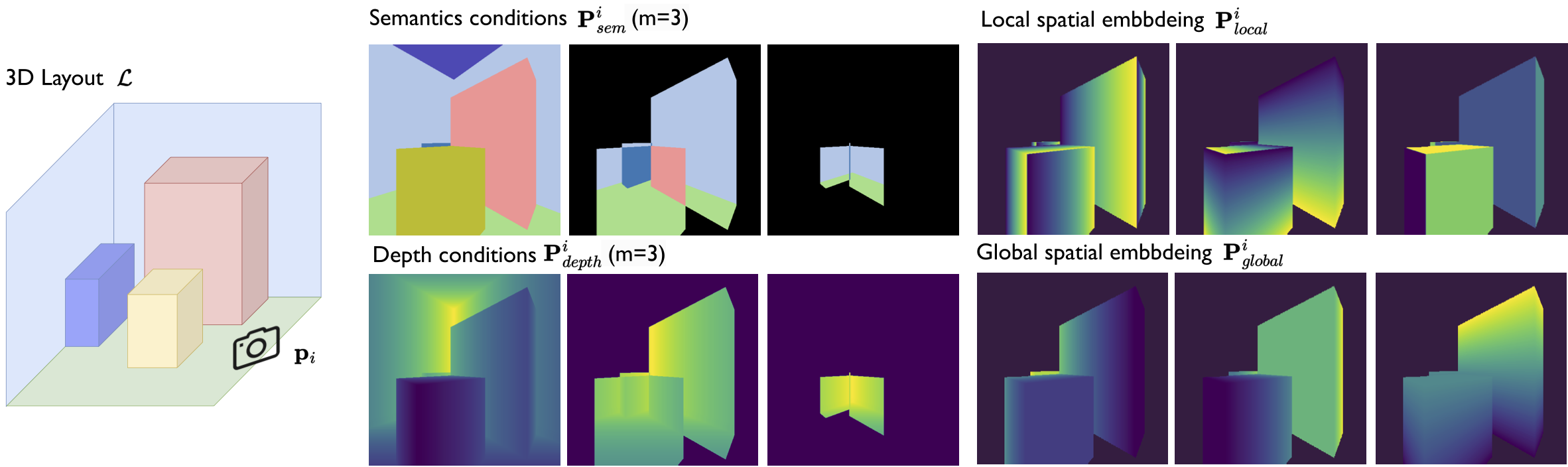
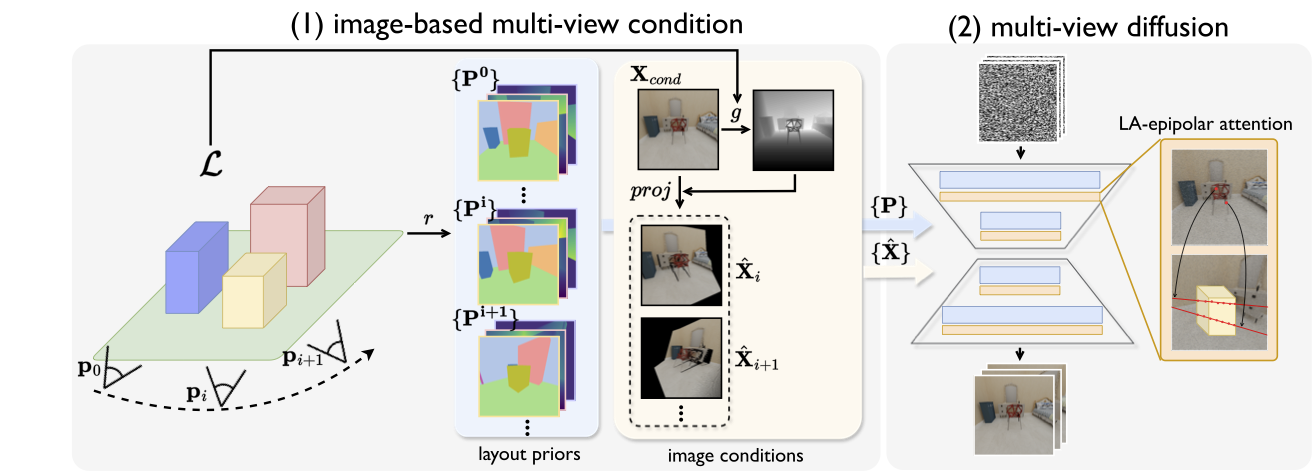
MVRoom has two stages. The first stage focuses on how
to bridge the 3D layout into image-based condition signals
for multi-view generation. To achieve this, we introduce
a novel image-based representation that preserves 3D lay-
out information and enables cross-view feature aggregation
during generation. This representation includes hybrid lay-
out priors, incorporating multi-layer semantics and depth
conditions, along with layout spatial embeddings. In the
second stage, we employ an image-conditioned multi-view
generative model that produces views that cover the under-
lying scene, supporting the whole scene generation. In ad-
dition to conditioning on rich signals derived from a 3D lay-
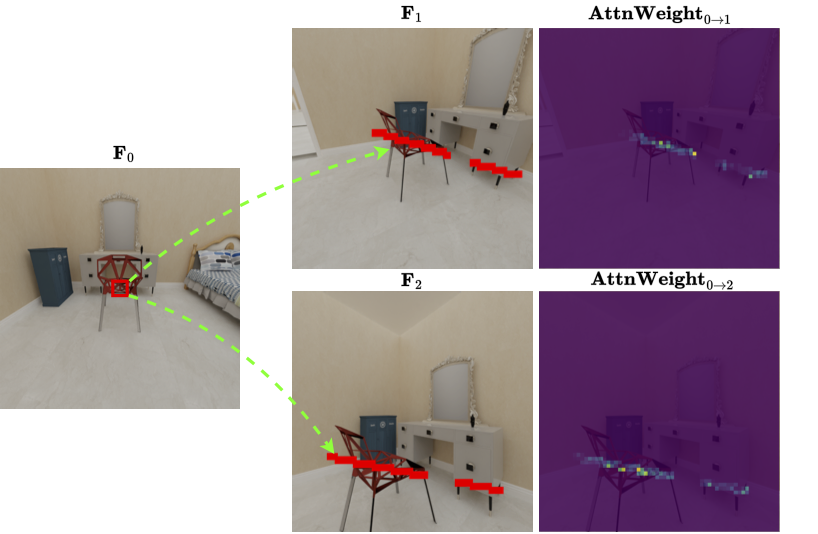
out, we introduce a layout-aware epipolar attention layer to
effectively fuse cross-view features. This approach ensures
accurate feature alignment across perspectives, greatly en-
hancing multi-view consistency in the generated images, a
critical issue in multi-view based 3D generation.
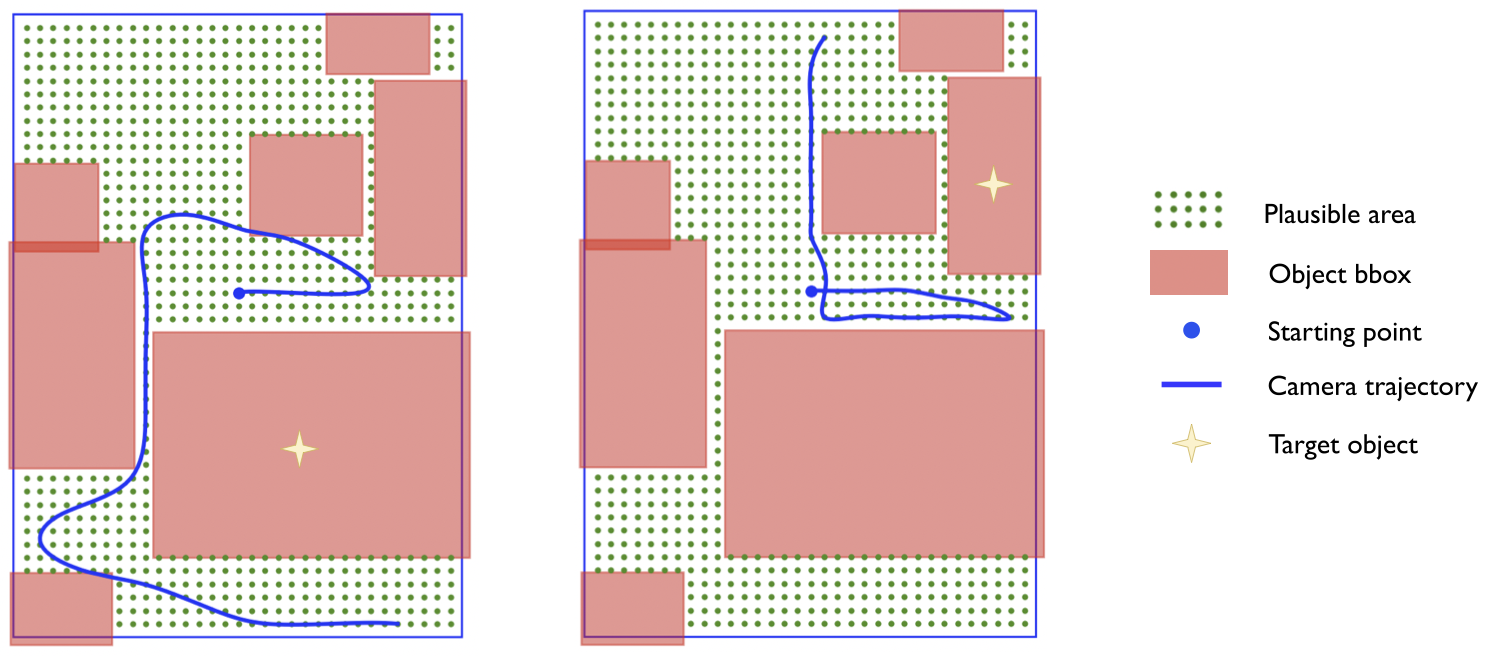
In addition, to generate a complete indoor scene, we
adopt an iterative framework that recursively produces
multi-view content according to the 3D scene layout. Our
framework takes as input the 3D layout and one or more
1
arXiv:2512.04248v1 [cs.CV] 3 Dec 2025
Figure 1. We introduce MVRoom, an indoor scene generation pipeline utilizing multi-view diffusion models. Given a 3D layout and
an initial image (generated from a text description). MVRoom uses conditional layout-aware multi-view diffusion models to generate
consistent novel views along continuous camera trajectories within the 3D scene. The consistent views are fed into a 3D-GS pipeline for
scene reconstruction and novel-view