Title: Vision Foundry: A System for Training Foundational Vision AI Models
ArXiv ID: 2512.11837
Date: 2025-12-03
Authors: Mahmut S. Gokmen, MS1, Mitchell A. Klusty, BS1, Evan W. Damron, BS1, W. Vaiden Logan, BS1, Aaron D. Mullen, MS1, Caroline N. Leach, BS1, Emily B. Collier, MS1, Samuel E. Armstrong, MS1, V. K. Cody Bumgardner, PhD1
📝 Abstract
Self-supervised learning (SSL) leverages vast unannotated medical datasets, yet steep technical barriers limit adoption by clinical researchers. We introduce Vision Foundry, a code-free, HIPAA-compliant platform that democratizes pre-training, adaptation, and deployment of foundational vision models. The system integrates the DINO-MX framework, abstracting distributed infrastructure complexities while implementing specialized strategies like Magnification-Aware Distillation (MAD) and Parameter-Efficient Fine-Tuning (PEFT). We validate the platform across domains, including neuropathology segmentation, lung cellularity estimation, and coronary calcium scoring. Our experiments demonstrate that models trained via Vision Foundry significantly outperform generic baselines in segmentation fidelity and regression accuracy, while exhibiting robust zero-shot generalization across imaging protocols. By bridging the gap between advanced representation learning and practical application, Vision Foundry enables domain experts to develop state-of-the-art clinical AI tools with minimal annotation overhead, shifting focus from engineering optimization to clinical discovery.
💡 Deep Analysis
📄 Full Content
Vision Foundry: A System for Training Foundational Vision AI Models
Mahmut S. Gokmen, MS1, Mitchell A. Klusty, BS1, Evan W. Damron, BS1, W. Vaiden
Logan, BS1, Aaron D. Mullen, MS1, Caroline N. Leach, BS1, Emily B. Collier, MS1, Samuel
E. Armstrong, MS1, V. K. Cody Bumgardner, PhD1
1 Center for Applied AI, University of Kentucky, Lexington, KY
Abstract
Self-supervised learning (SSL) leverages vast unannotated medical datasets, yet steep technical barriers limit adoption
by clinical researchers. We introduce Vision Foundry, a code-free, HIPAA-compliant platform that democratizes pre-
training, adaptation, and deployment of foundational vision models. The system integrates the DINO-MX framework,
abstracting distributed infrastructure complexities while implementing specialized strategies like Magnification-Aware
Distillation (MAD) and Parameter-Efficient Fine-Tuning (PEFT). We validate the platform across domains, including
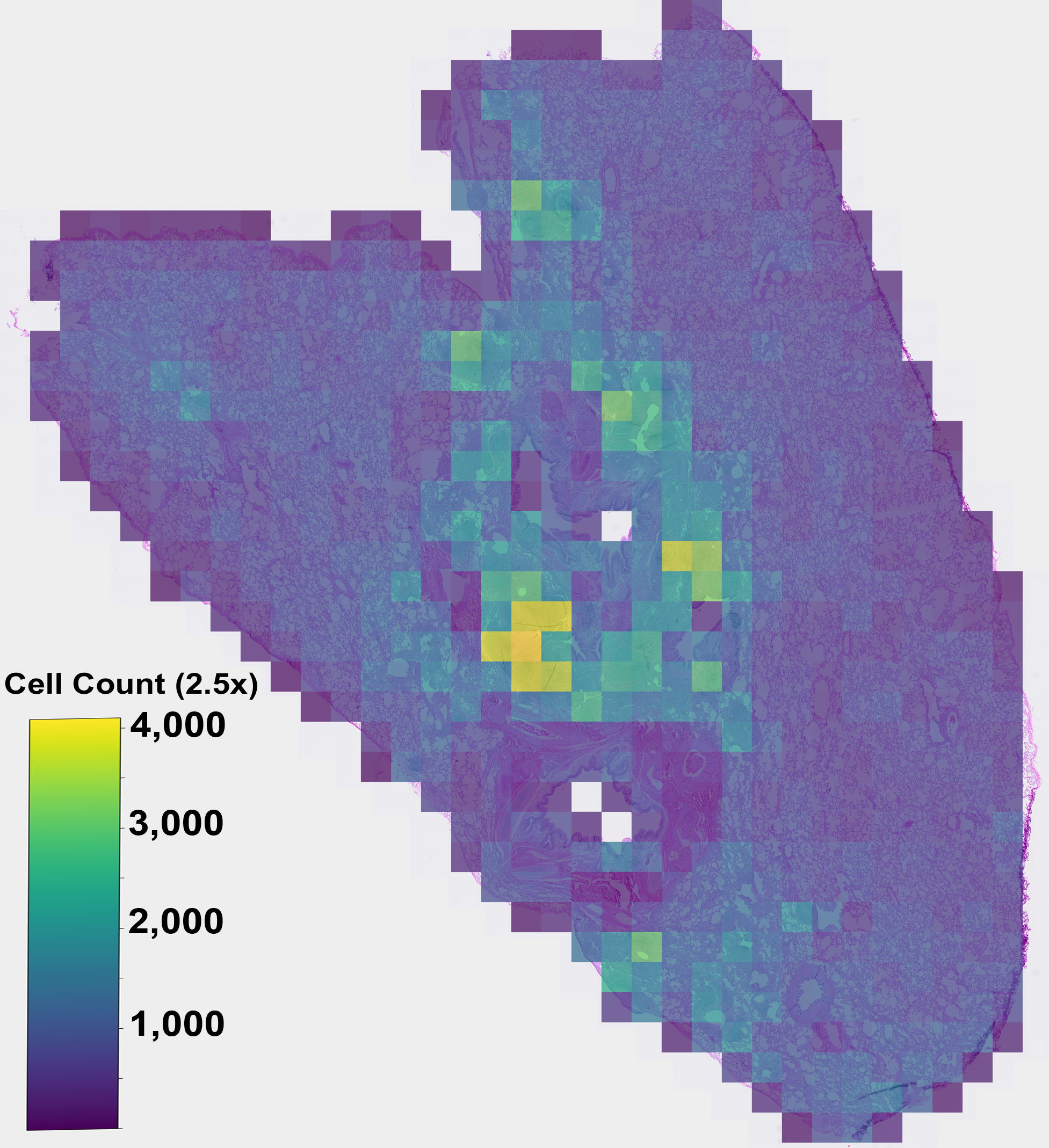
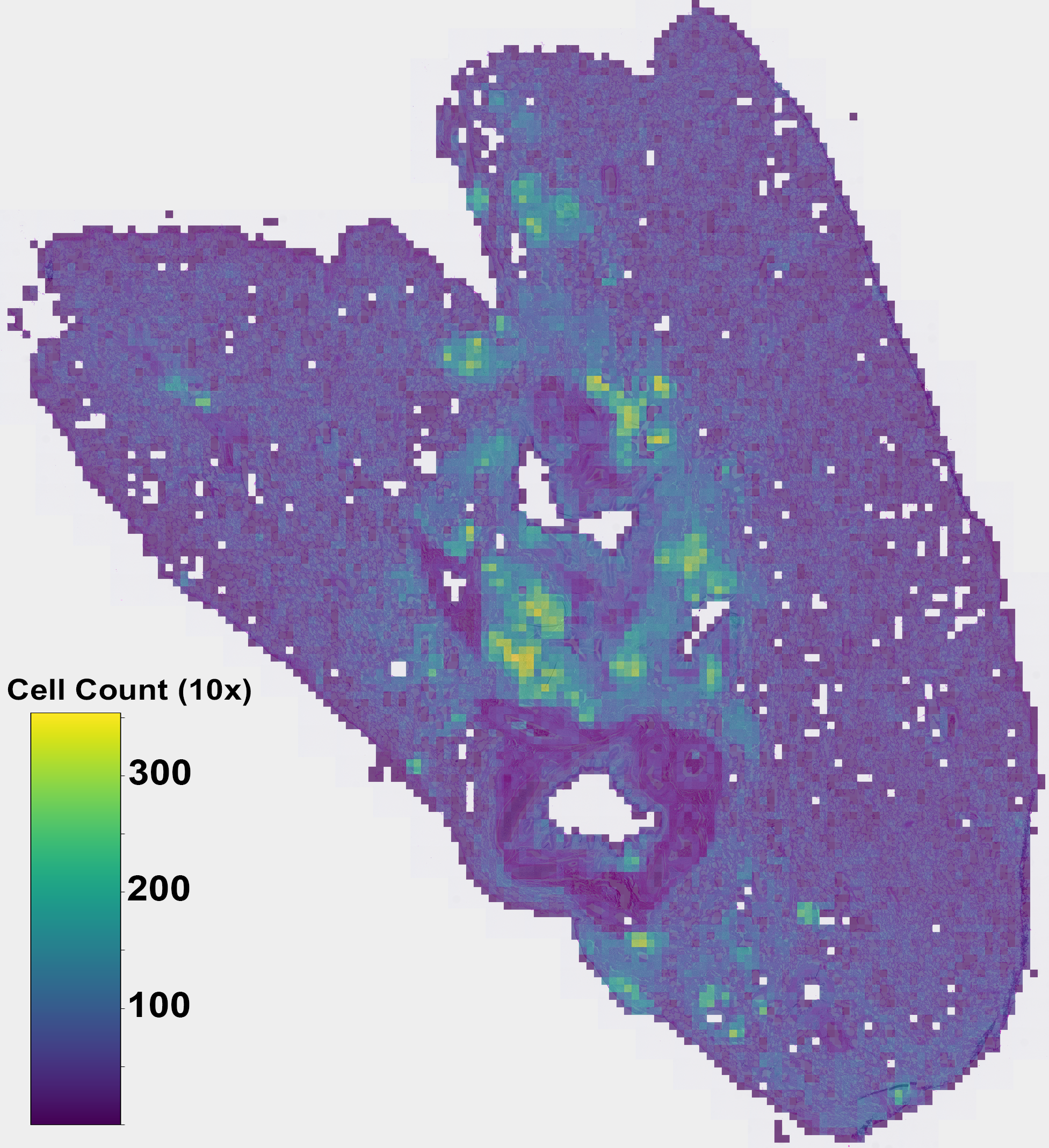
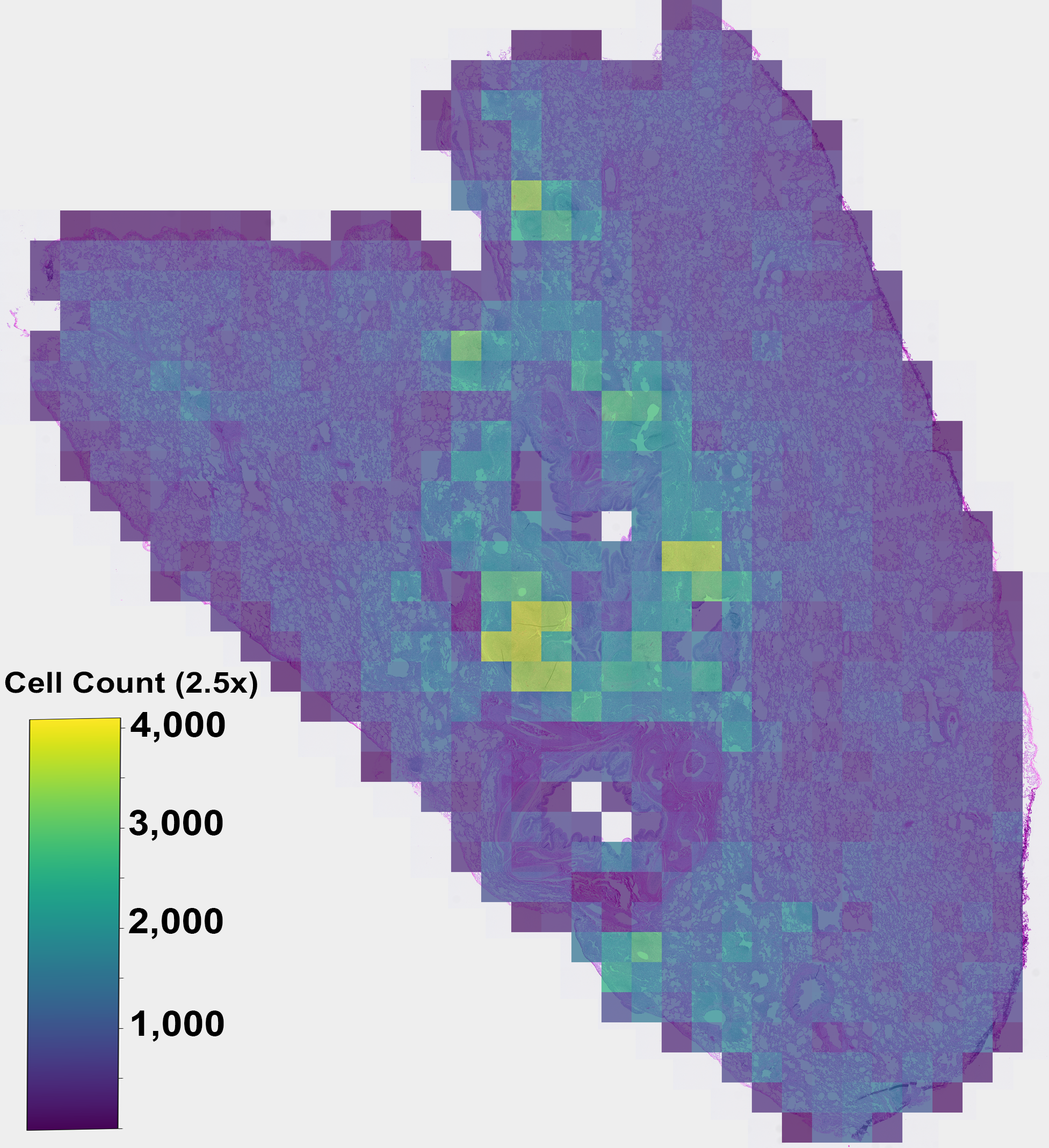
neuropathology segmentation, lung cellularity estimation, and coronary calcium scoring. Our experiments demon-
strate that models trained via Vision Foundry significantly outperform generic baselines in segmentation fidelity and
regression accuracy, while exhibiting robust zero-shot generalization across imaging protocols. By bridging the gap
between advanced representation learning and practical application, Vision Foundry enables domain experts to de-
velop state-of-the-art clinical AI tools with minimal annotation overhead, shifting focus from engineering optimization
to clinical discovery.
1
Introduction
Recent advances in self-supervised learning and foundational vision models have reshaped how computer vision
systems are developed for domain-specific applications.1 Unlike supervised methods that depend on large labeled
datasets, SSL approaches such as DINO,2,3 SimCLR,4 and MAE5 learn meaningful representations directly from un-
labeled data. Foundational models trained with these techniques produce rich and transferable embeddings that support
downstream tasks including classification, segmentation, and anomaly detection.6,7 A key strength of these models is
their ability to learn structured feature spaces that capture color distributions, textures, edges, and higher-level semantic
patterns, enabling broad generalization across datasets and tasks.8
These capabilities are especially relevant in medical imaging, where obtaining expert-labeled data is both expensive
and time-consuming.9,10 Meanwhile, hospitals and research centers already store large quantities of unlabeled WSIs
and CT/MRI scans that remain underutilized.11 SSL allows these datasets to be transformed into rich, domain-adapted
representations, enabling downstream models to be trained with substantially fewer labeled samples and reducing
reliance on extensive annotation efforts.12
Tasks such as segmentation, classification, regression, or clustering rely on transforming model-derived representa-
tions into meaningful outputs. While supervised models attempt to learn these outputs directly from labeled data,
foundational models instead prioritize learning the underlying structure of the dataset, resulting in richer and more
transferable embeddings.13 Lightweight downstream heads can be trained to produce task-specific predictions using
these embeddings, and both contrastive and non-contrastive SSL objectives further strengthen feature quality.14 This
shared-compute paradigm reduces labeling requirements, accelerates model development, and improves generalization
in settings where conventional supervised models struggle to transfer across datasets or populations.11
Despite these advantages, the practical use of SSL frameworks remains challenging. Existing repositories often re-
quire substantial technical expertise, complex configuration workflows, and an understanding of distributed training
procedures.15,11 Although several tools have been introduced to lower the barrier to SSL training, many still demand
considerable coding effort, lack the flexibility needed for medical imaging workflows, and provide only limited support
for modern SSL training strategies.15,16 Downstream development also presents challenges, as designing appropriate
head architectures and training pipelines frequently requires domain knowledge and iterative experimentation. This
highlights the need for an integrated, accessible system that enables domain experts to pretrain, fine-tune, and deploy
foundational models without extensive machine learning expertise.17
arXiv:2512.11837v1 [q-bio.QM] 3 Dec 2025
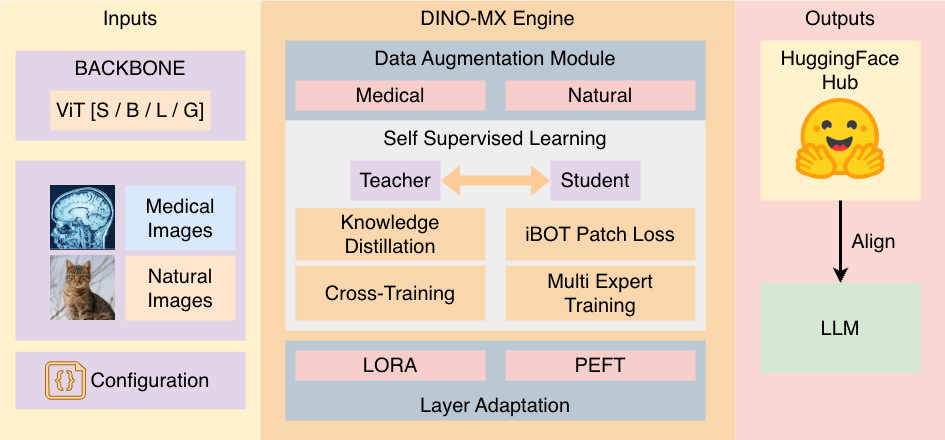
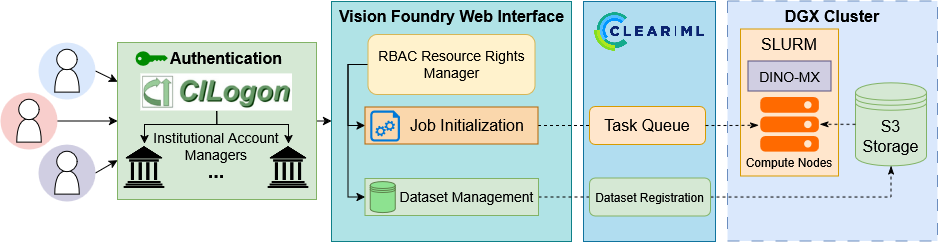
To address these challenges, we introduce Vision Foundry, a unified platform that simplifies the training, adapta-
tion, and deployment of foundational vision models for medical imaging applications. Vision Foundry integrates
DINO-MX18, a modular SSL framework supporting large-scale distributed training, parameter-efficient fine-tuning,
domain-specific augmentation, and multi-expert learning strategies. The platform provides a secure dataset manager,
a