Title: AdaptVision: Efficient Vision-Language Models via Adaptive Visual Acquisition
ArXiv ID: 2512.03794
Date: 2025-12-03
Authors: ** Zichuan Lin*, Yicheng Liu*, Yang Yang, Lvfang Tao, Deheng Ye (Tencent AI Lab) 동일 기여 — **
📝 Abstract
Vision-Language Models (VLMs) have achieved remarkable success in visual question answering tasks, but their reliance on large numbers of visual tokens introduces significant computational overhead. While existing efficient VLM approaches reduce visual tokens through fixed-ratio compression, they operate passively and lack the ability to adapt to varying task requirements. This motivates a fundamental question: Can VLMs autonomously determine the minimum number of visual tokens required for each sample? Inspired by human active vision mechanisms, we introduce AdaptVision, an efficient VLM paradigm that enables adaptive visual token acquisition through a coarse-to-fine approach. Our model initially processes compressed visual tokens from low-resolution images and selectively acquires additional visual information by invoking a bounding box tool to crop key regions when necessary. We train AdaptVision using a reinforcement learning framework that carefully balances accuracy and efficiency. Central to our approach is Decoupled Turn Policy Optimization (DTPO), which decouples the learning objective into two components: (1) tool learning, which optimizes correct tool utilization, and (2) accuracy improvement, which refines the generated responses to improve answer correctness. Based on this formulation, we further decouple advantage estimation by computing separate advantages for tokens associated with each objective. This formulation enables more effective optimization for AdaptVision compared to vanilla GRPO. Comprehensive experiments across multiple VQA benchmarks demonstrate that AdaptVision achieves superior performance while consuming substantially fewer visual tokens than state-of-the-art efficient VLM methods.
💡 Deep Analysis
📄 Full Content
AdaptVision: Efficient Vision-Language Models via Adaptive Visual Acquisition
Zichuan Lin*
Yicheng Liu*
Yang Yang
Lvfang Tao
Deheng Ye
Tencent AI Lab
Codes and models: github.com/adaptvision/adaptvision
Abstract
Vision-Language Models (VLMs) have achieved remark-
able success in visual question answering tasks, but their
reliance on large numbers of visual tokens introduces sig-
nificant computational overhead. While existing efficient
VLM approaches reduce visual tokens through fixed-ratio
compression, they operate passively and lack the ability to
adapt to varying task requirements. This motivates a funda-
mental question: Can VLMs autonomously determine the
minimum number of visual tokens required for each sam-
ple? Inspired by human active vision mechanisms, we in-
troduce AdaptVision, an efficient VLM paradigm that en-
ables adaptive visual token acquisition through a coarse-
to-fine approach. Our model initially processes compressed
visual tokens from low-resolution images and selectively ac-
quires additional visual information by invoking a bound-
ing box tool to crop key regions when necessary. We train
AdaptVision using a reinforcement learning framework that
carefully balances accuracy and efficiency. Central to our
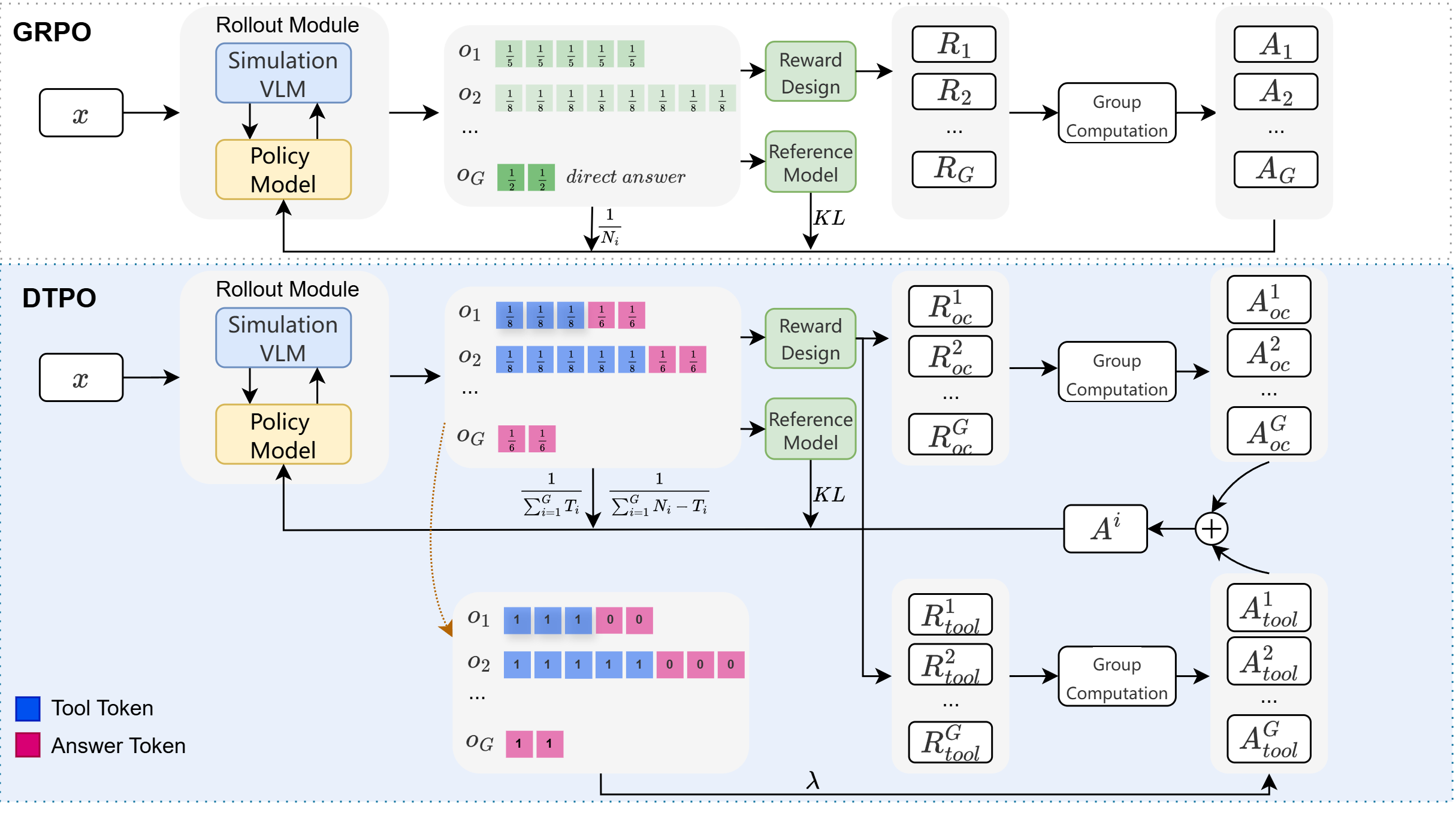
approach is Decoupled Turn Policy Optimization (DTPO),
which decouples the learning objective into two compo-
nents: (1) tool learning, which optimizes correct tool uti-
lization, and (2) accuracy improvement, which refines the
generated responses to improve answer correctness. Based
on this formulation, we further decouple advantage estima-
tion by computing separate advantages for tokens associ-
ated with each objective. This formulation enables more
effective optimization for AdaptVision compared to vanilla
GRPO. Comprehensive experiments across multiple VQA
benchmarks demonstrate that AdaptVision achieves supe-
rior performance while consuming substantially fewer vi-
sual tokens than state-of-the-art efficient VLM methods.
1. Introduction
Recently, Vision-Language Models (VLMs) [2, 4, 15] have
achieved significant breakthroughs in general visual ques-
tion answering (VQA) and diverse practical applications by
*Equal contribution
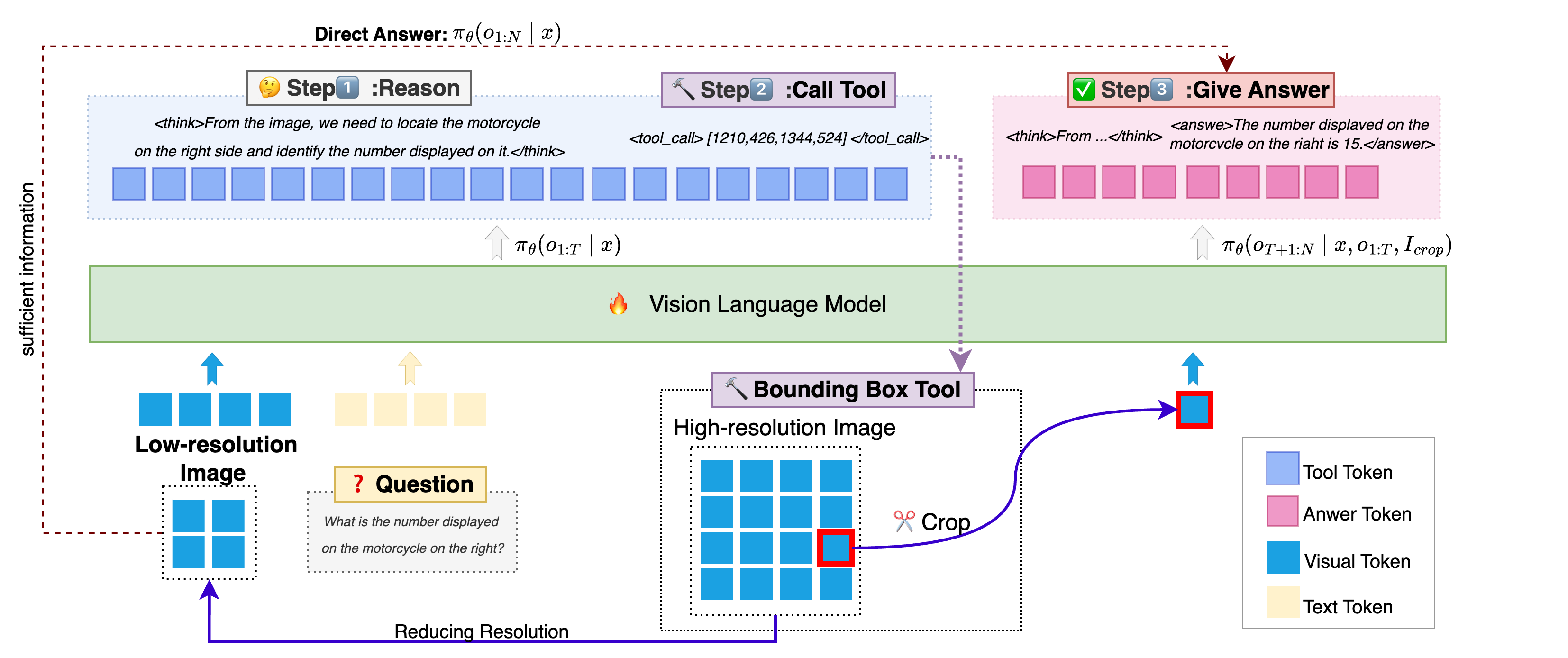
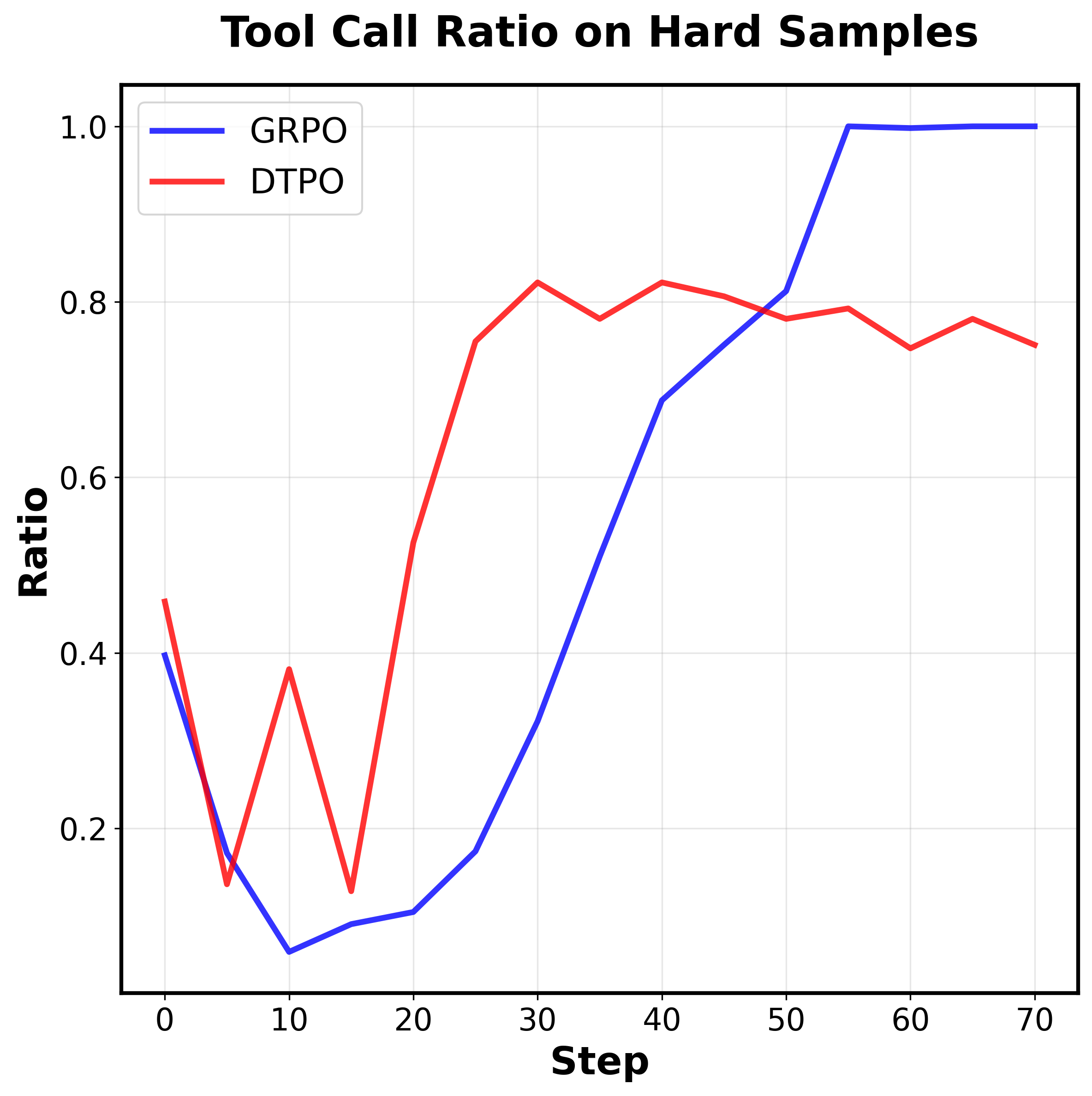
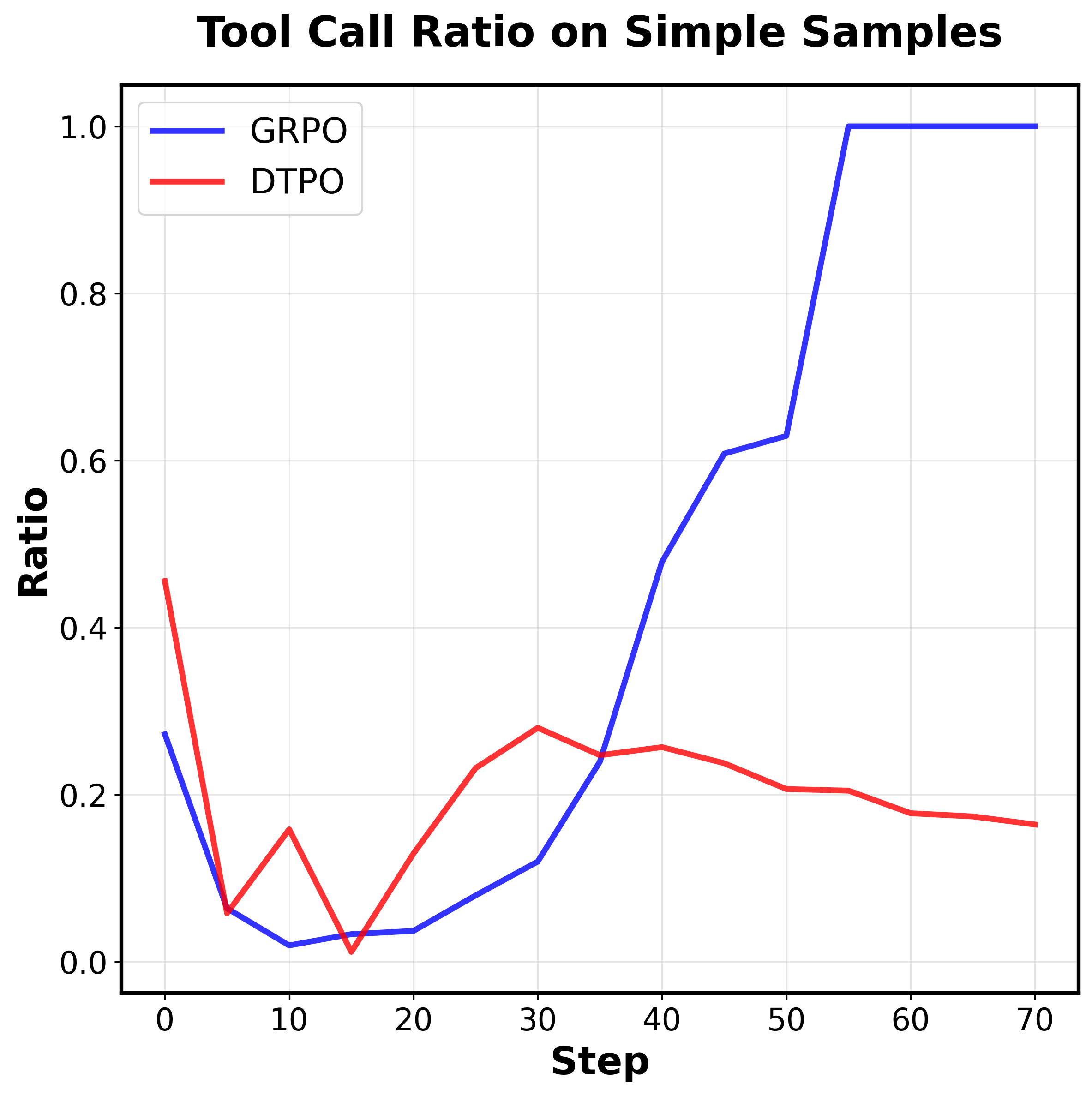
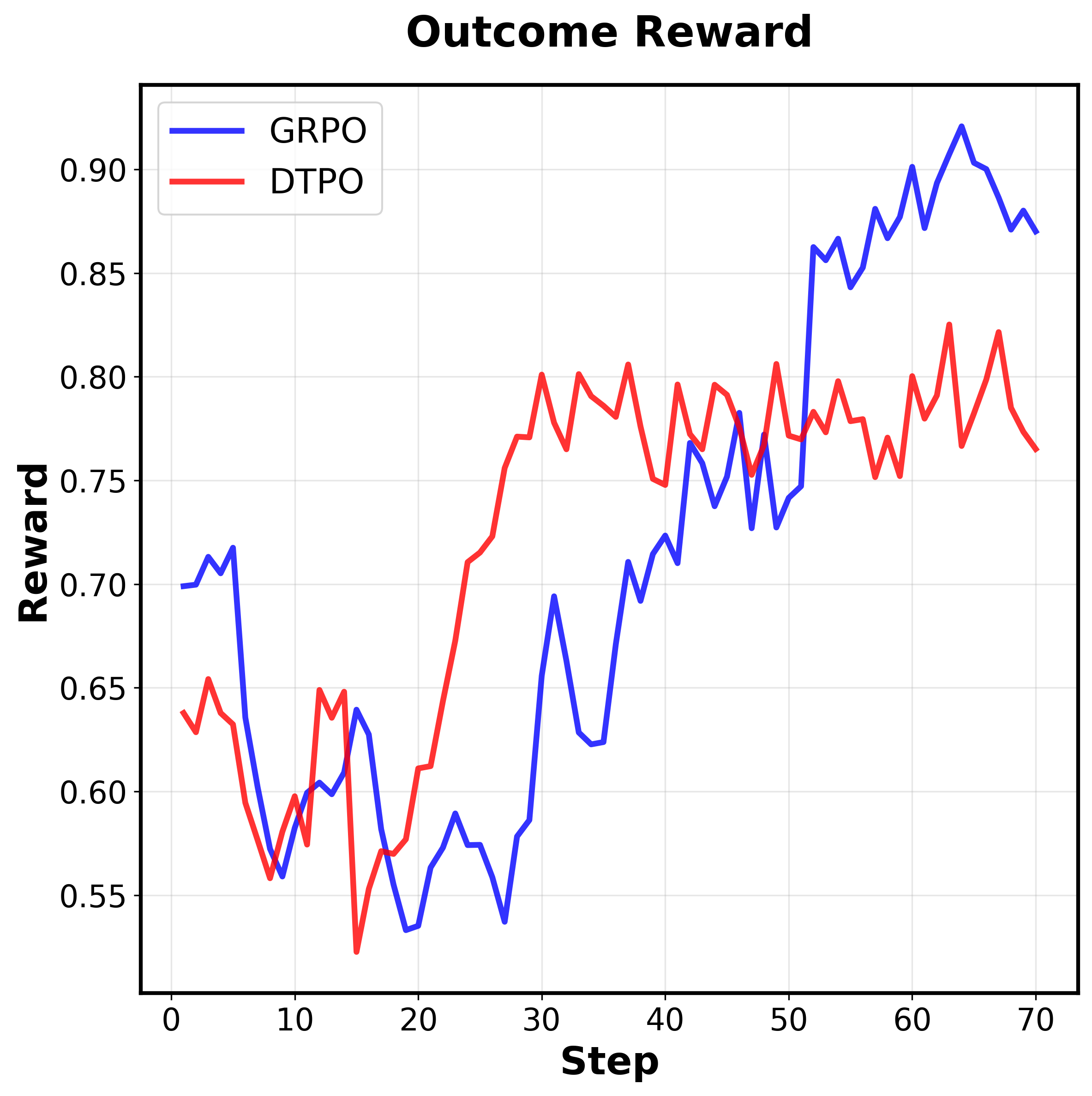
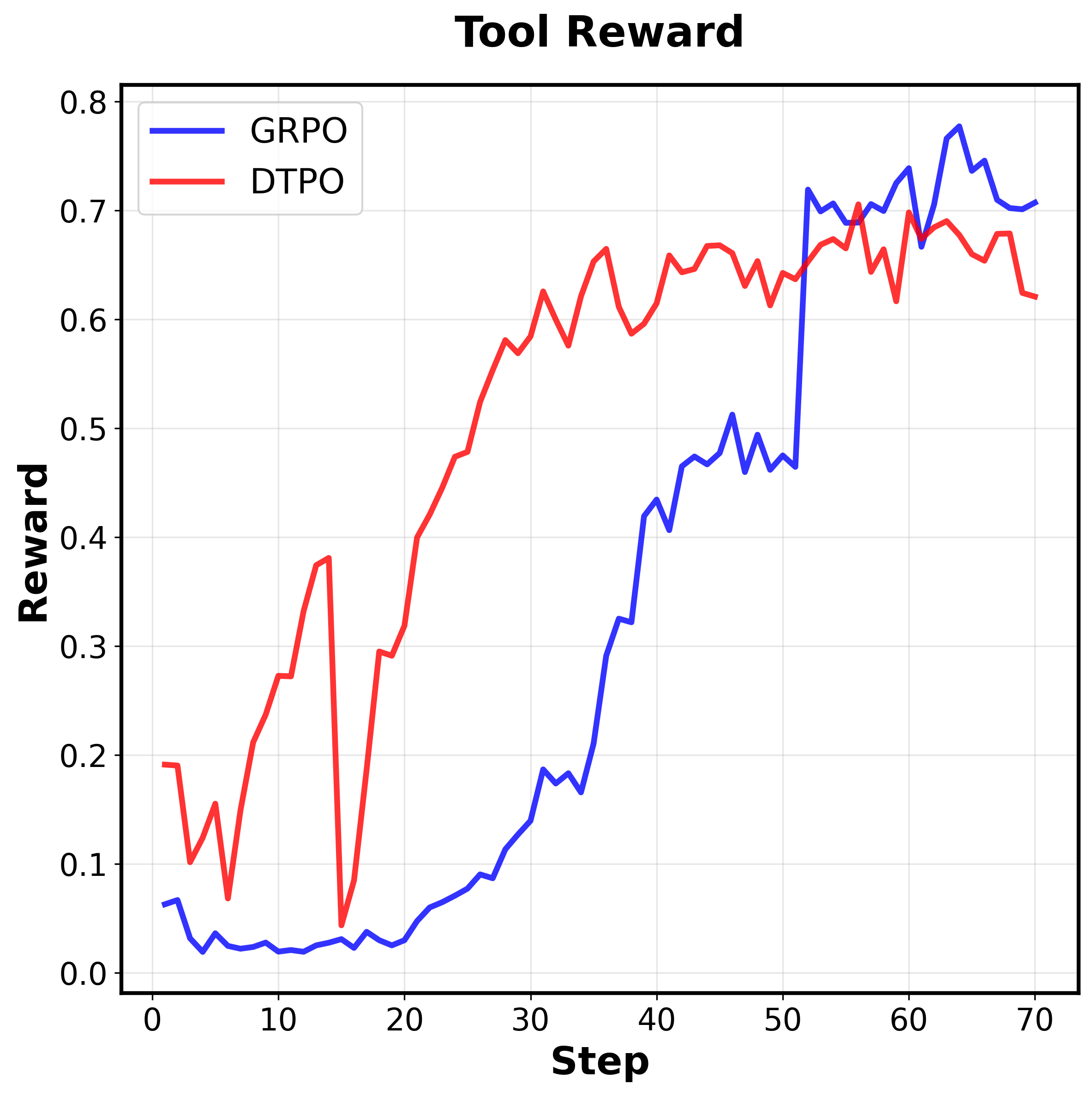
Question: What is the number displayed on
the motorcycle on the right?
Answer: The number
is 15
Higher Efficiency
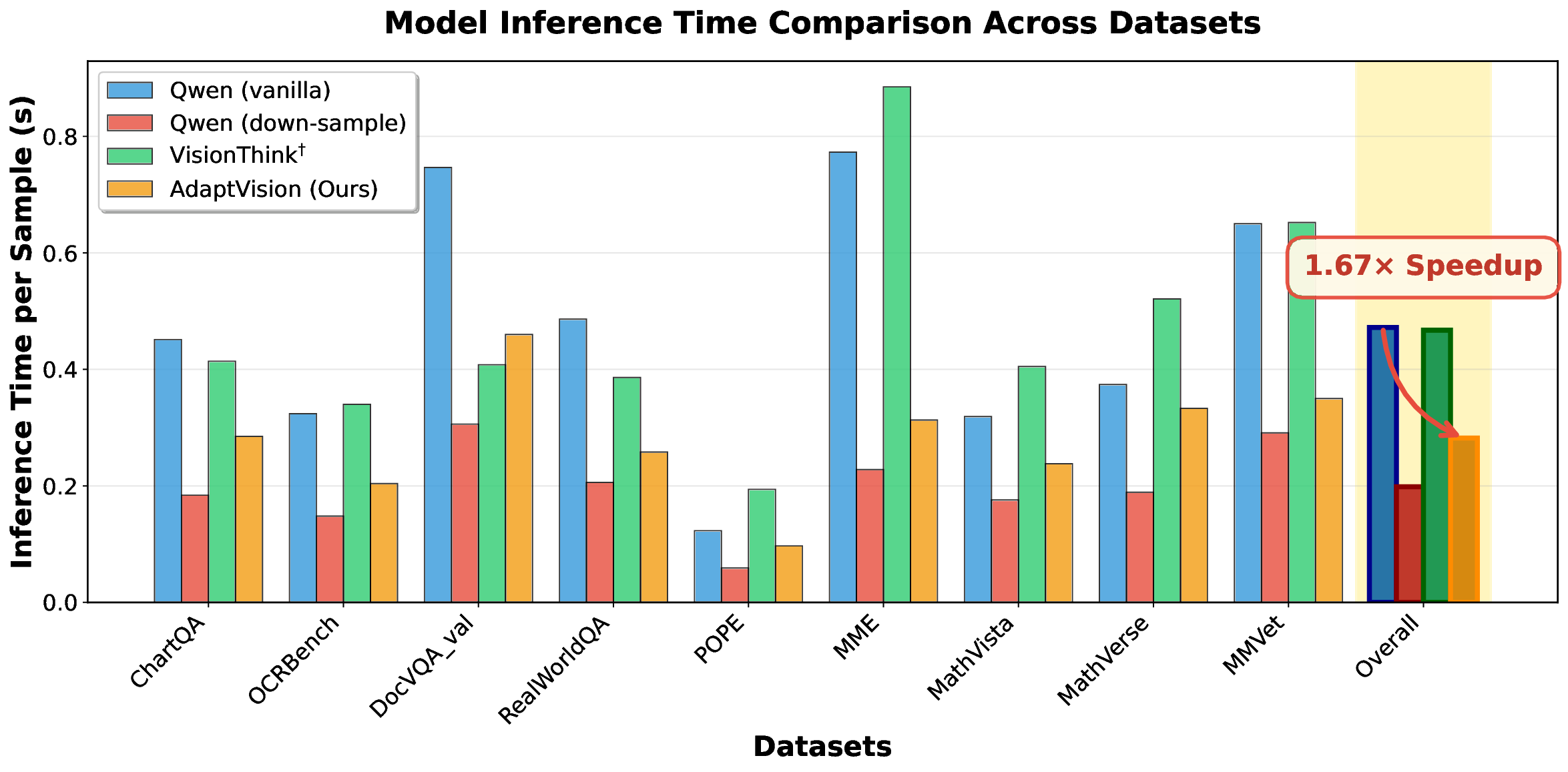
Figure 1. Our key motivations and AdaptVision performance
and efficiency.
Top:
Coarse-to-fine.
Human visual atten-
tion mechanisms first guide the search for question-relevant re-
gions in images, which are then subjected to detailed analysis.
Down: AdaptVision achieves superior performance with signifi-
cantly fewer visual tokens than previous efficient VLM methods.
projecting and adapting visual tokens into large language
model (LLM) space [1, 2, 31, 42]. However, the promising
performance of VLMs largely relies on the large amount of
vision tokens, inevitably introducing a huge memory and
computational overhead when compared to LLMs, partic-
ularly for high-resolution images. For instance, a 2048 ×
1024 image yields 2,678 vision tokens in Qwen2.5-VL [3].
Therefore, it is crucial to avoid the excessive consumption
of visual tokens.
Numerous studies have explored visual token compres-
sion to enhance VLM efficiency [5, 9, 13, 28, 32, 36, 37,
40]. Existing works can be categorized into two main re-
search directions. The first prunes or merges a fixed num-
ber of visual tokens based on predetermined thresholds,
according to the importance and similarity of vision to-
kens [5, 36, 40]. The second dynamically processes distinct
samples, where the system adaptively switches between us-
ing 100% vision tokens for OCR-related tasks and 25%
vision tokens for simpler tasks by selectively employing
quarter-resolution images [37]. However, existing efficient
arXiv:2512.03794v1 [cs.CV] 3 Dec 2025
VLM paradigms and methods are largely passive, as they
can only reduce the number of vision tokens by predefined
ratios. This leads to a natural question: Can VLMs adap-
tively determine the minimum number of vision tokens for
each sample according to different scenarios?
Cognitive neuroscience reveals that our visual system
operates through an active, sequential, and adaptive process
known as active vision [6, 11]. It first captures coarse, low-
spatial-frequency information to grasp the gist of a scene,
then directs attention to salient regions for detailed analy-
sis [22]. This coarse-to-fine processing mechanism enables
humans to efficiently parse complex visual inputs with min-
imal cognitive load. Fig. 1 provides an illustrative example.
The cognitive strategy of active vision is operational-
ized in recent VLMs through the “thinking-with-images”
paradigm, such as invoking tools to zoom and crop specific
regions [14, 41] to advance fine-grained visual understand-
ing. We argue that this active reasoning capability can be
effectively applied to the critical task of visual token reduc-
tion, allowing the model to decide how few visual tokens
are sufficie