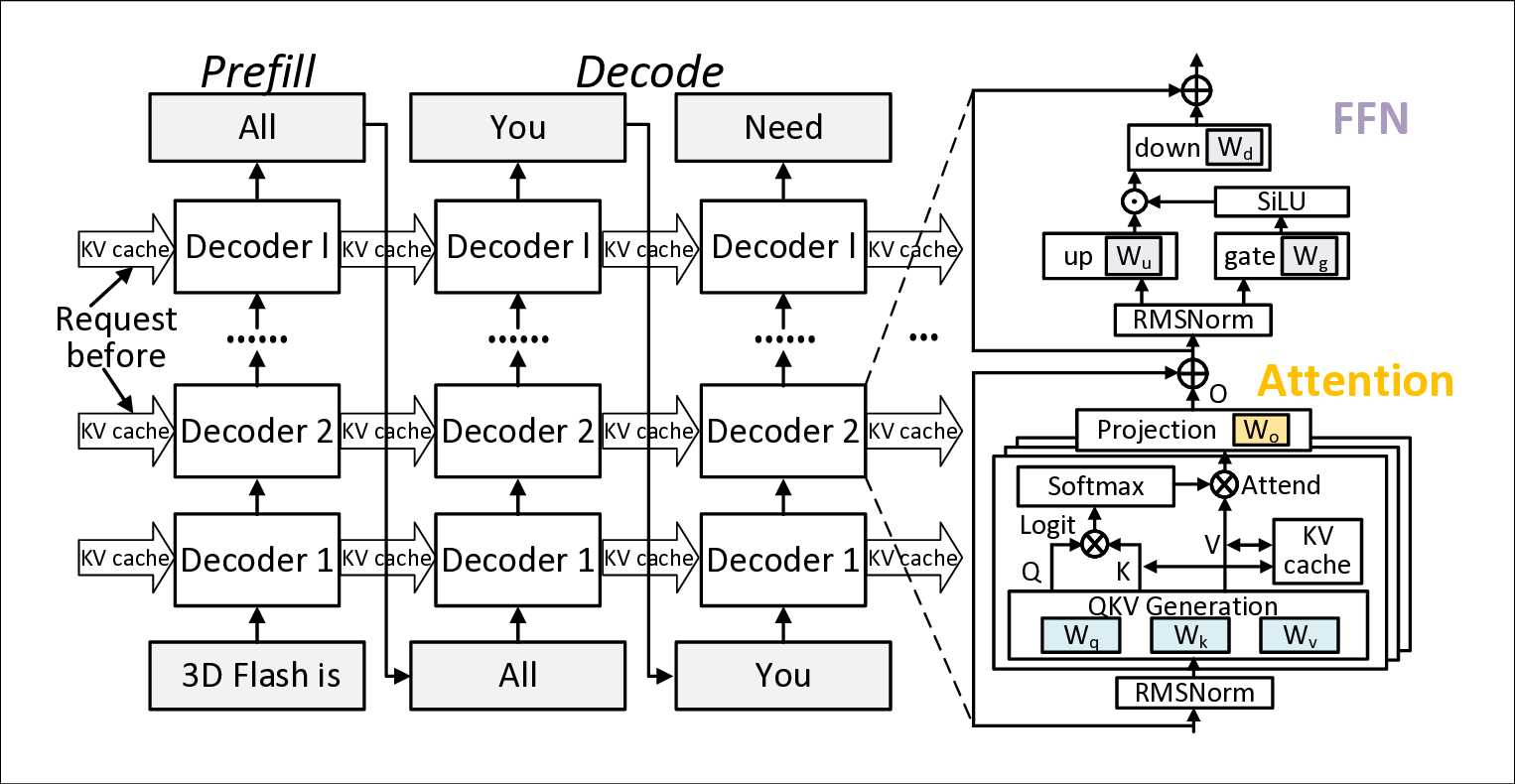
Deploying large language models (LLMs) on edge devices enables personalized agents with strong privacy and low cost. However, with tens to hundreds of billions of parameters, single-batch autoregressive inference suffers from extremely low arithmetic intensity, creating severe weight-loading and bandwidth pressures on resource-constrained platforms. Recent in-flash computing (IFC) solutions alleviate this bottleneck by co-locating weight-related linear computations in the decode phase with flash, yet still rely on DRAM for the key-value (KV) cache. As context length grows, the KV cache can exceed model weights in size, imposing prohibitive DRAM cost and capacity requirements. Attempts to offload KV cache to flash suffer from severe performance penalties.
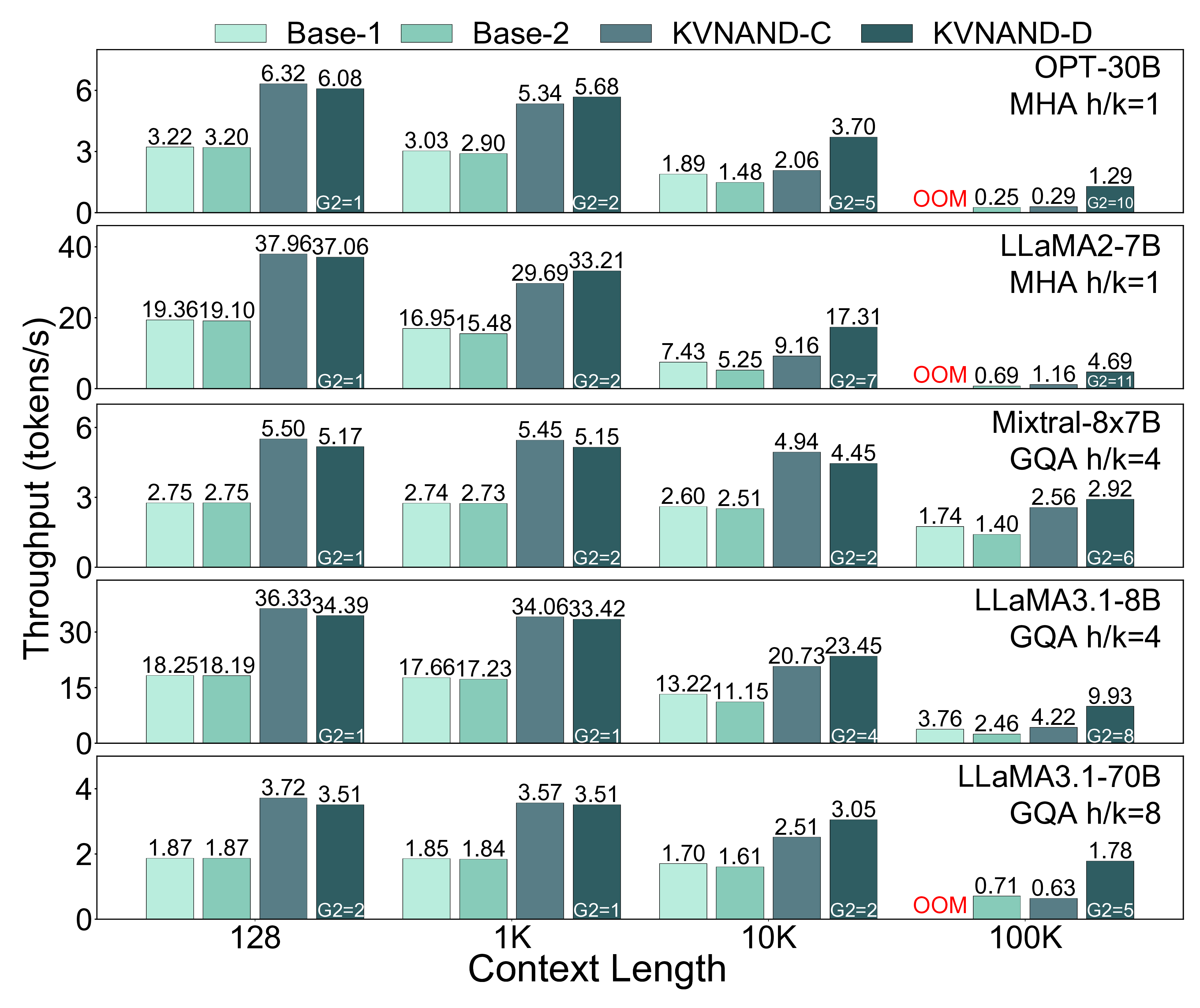
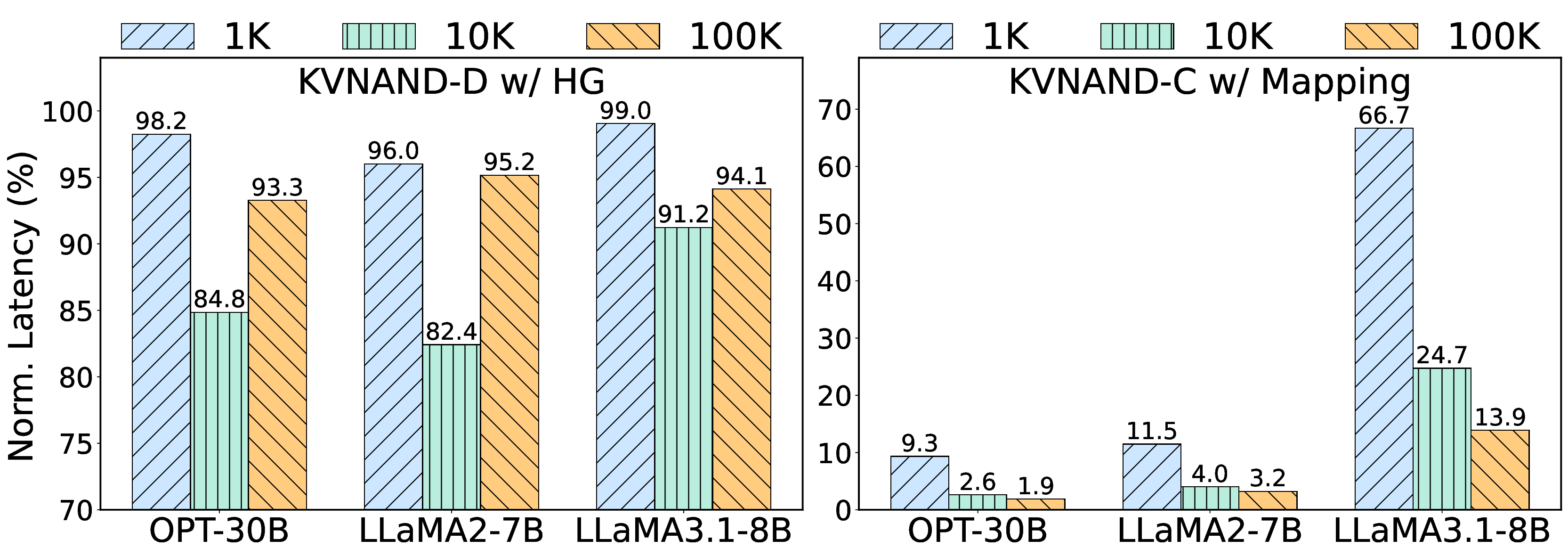
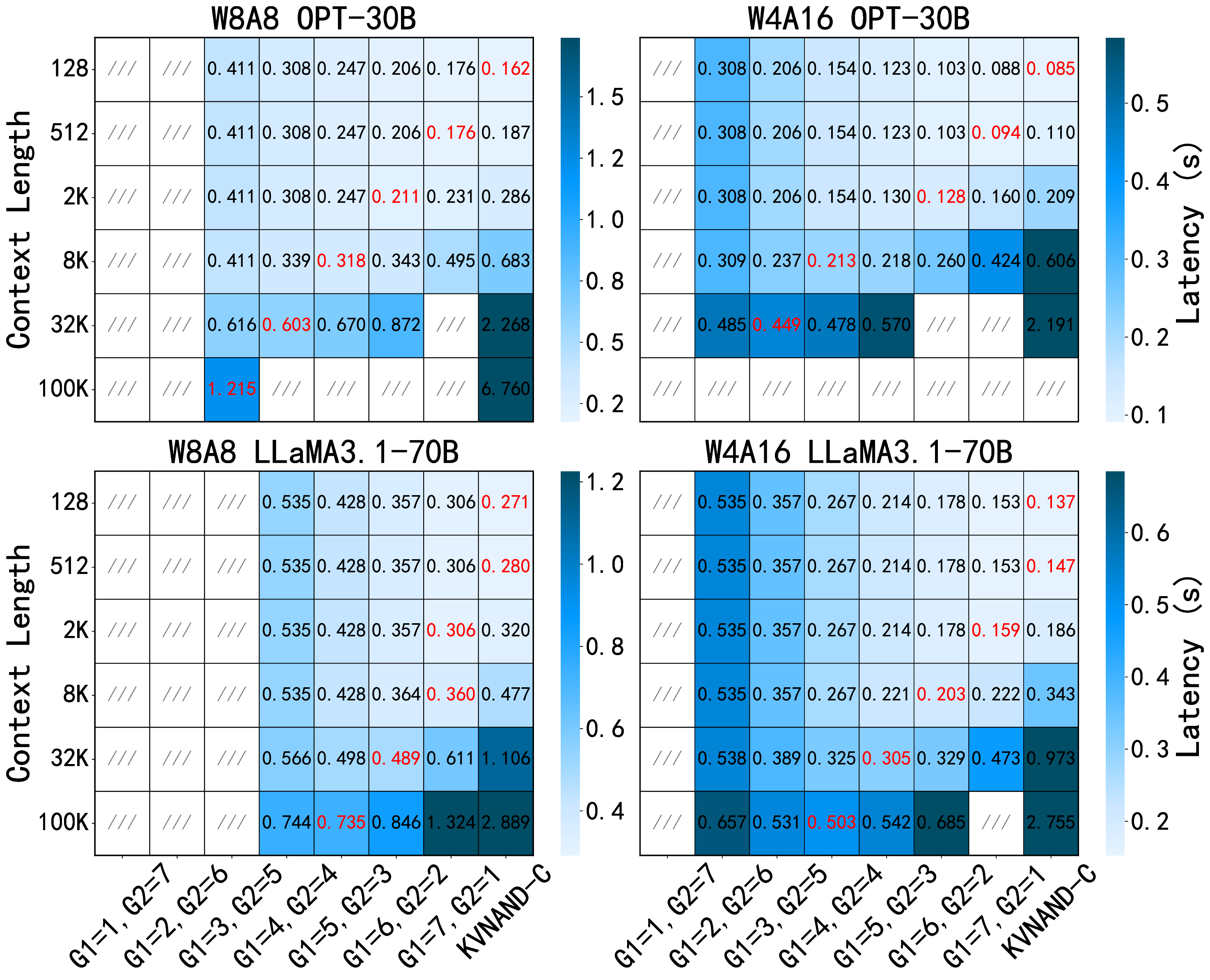
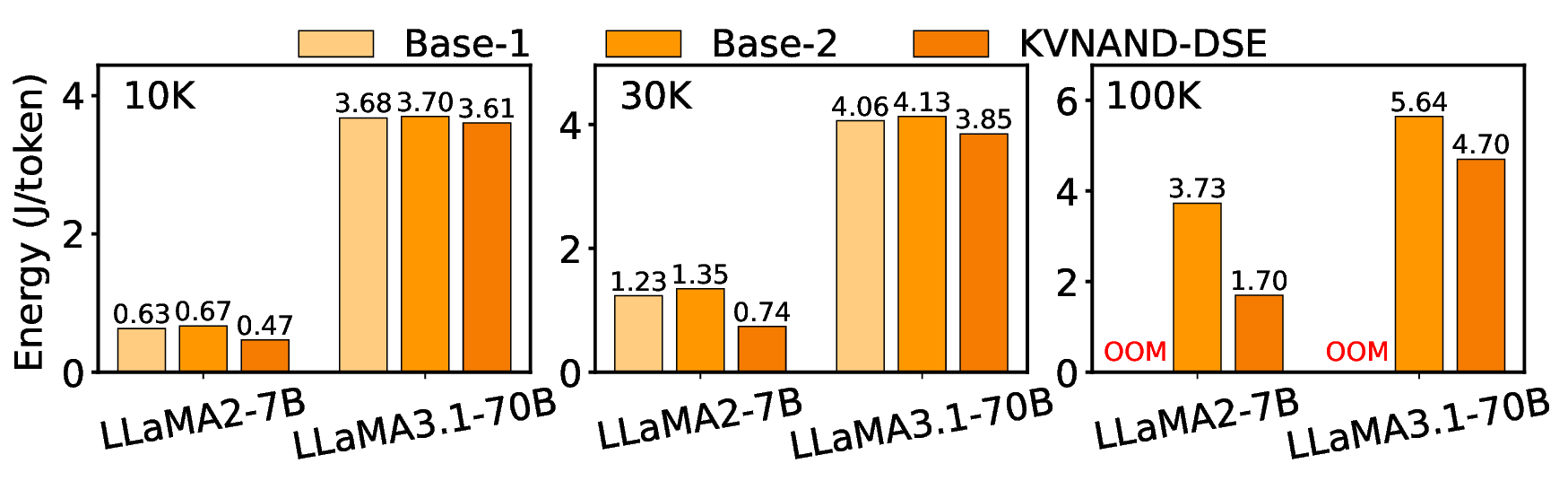
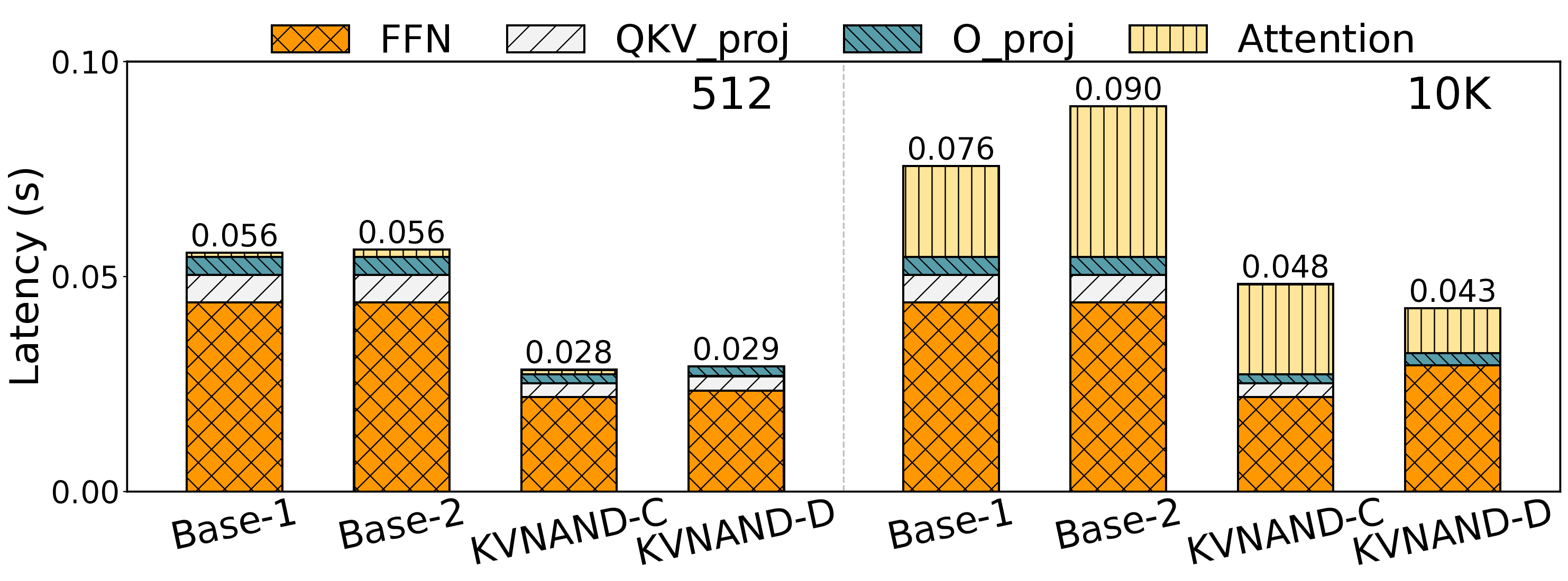
We propose KVNAND, the first DRAM-free, IFC-based architecture that stores both model weights and KV cache entirely in compute-enabled 3D NAND flash. KVNAND addresses the fundamental performance challenges of flash under intensive KV cache access by leveraging IFC for all memory-bound operations to reduce data transfer overhead, introducing head-group parallelism to boost throughput, and employing page-level KV cache mapping to align token access patterns with flash organization. In addition, we propose a design space exploration framework that evaluates discrete and compact KVNAND variants to balance weight and KV placement, automatically identifying the optimal design trade-off. These techniques mitigate latency, energy, and reliability concerns, turning flash into a practical medium for long-context KV storage. Evaluations on MHA 7B and GQA 70B LLMs show that KVNAND achieves 1.98\(\times\)/1.94\(\times\)/2.05\(\times\) geomean speedup at 128/1K/10K-token contexts compared to DRAM-equipped IFC designs and addresses out-of-memory failures at 100K context length.
As Large Language Models (LLMs) integrate into daily workflows, demand increases for personalized AI agents that align with user preferences, domain knowledge, and interaction styles. Deploying such agents on edge devices offers privacy, low-latency responsiveness, and cost efficiency by eliminating cloud dependency, making on-device LLMs a compelling direction for AI democratization [81].
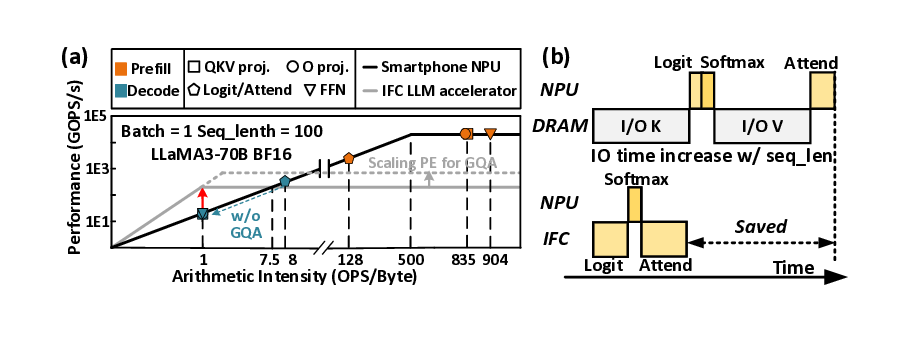
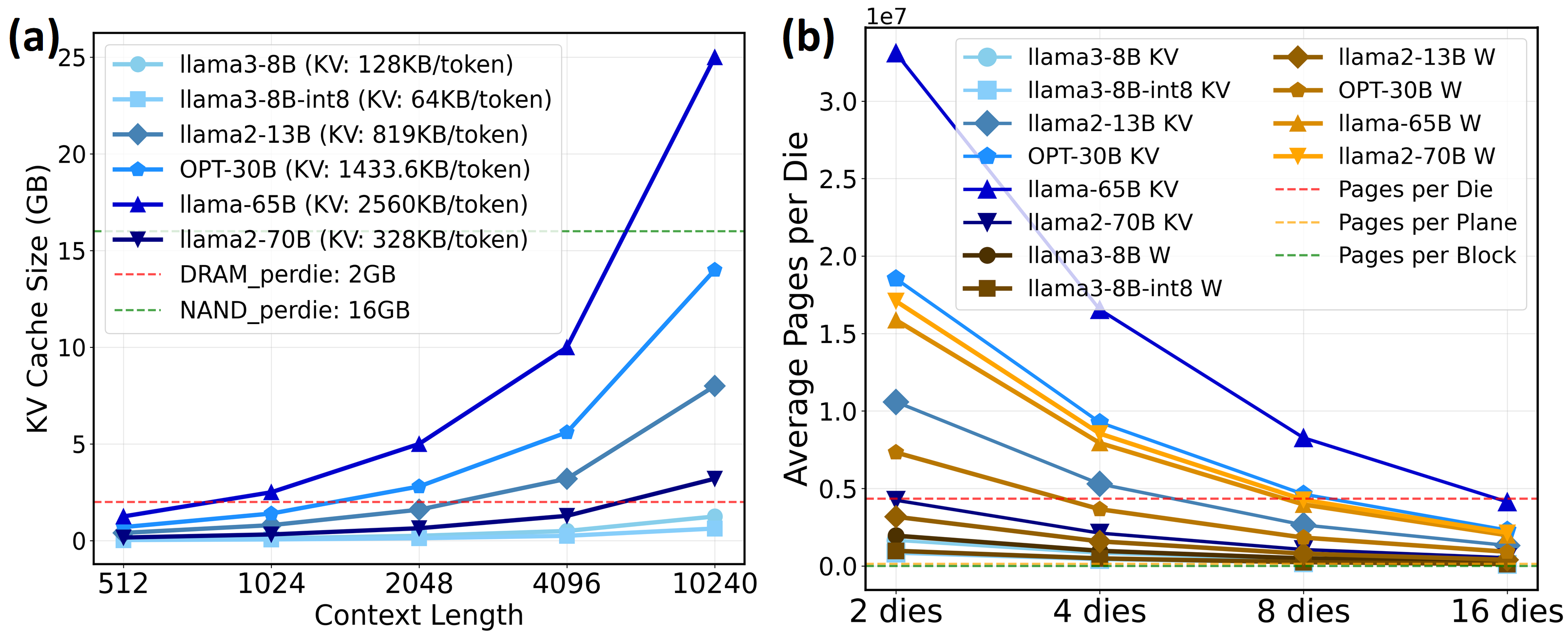
Realizing high-quality personal LLM agents on resourcelimited edge devices faces two main bottlenecks: memory capacity and bandwidth. [67], [78], [81], [89] Modern LLMs require tens to hundreds of GBs just for weights (e.g., LLaMA2-70B needs ∼ 140 GB [71]), far exceeding typical edge-device DRAM limits (8-16 GB on smartphones, <64 GB on laptops). The growing demand for long-context agentic workflows like long document analysis [35], multi-turn dialogue [84], and chain-of-thought reasoning [10] introduces the KV cache as another dominant consumer of this limited memory [19], [74]. Moreover, recent state-of-the-art (SoTA) models support extensive context lengths ranging from 128K (LLaMA3.1-70B [50]) to 1M (Gemini 2.5 Pro [13]). The KV cache demand scales linearly with context length; for example, a 13B model already requires ∼ 8 GB KV memory at a 10K context [71], placing prohibitive pressure on edge resources. Meanwhile, unlike the compute-intensive prefill stage dominated by matrix-matrix multiplication (GEMM), decoding reduces to memory-bound matrix-vector multiplication (GEMV), exhibiting extremely low arithmetic intensity (≈ 1 OPS/Byte at FP16).
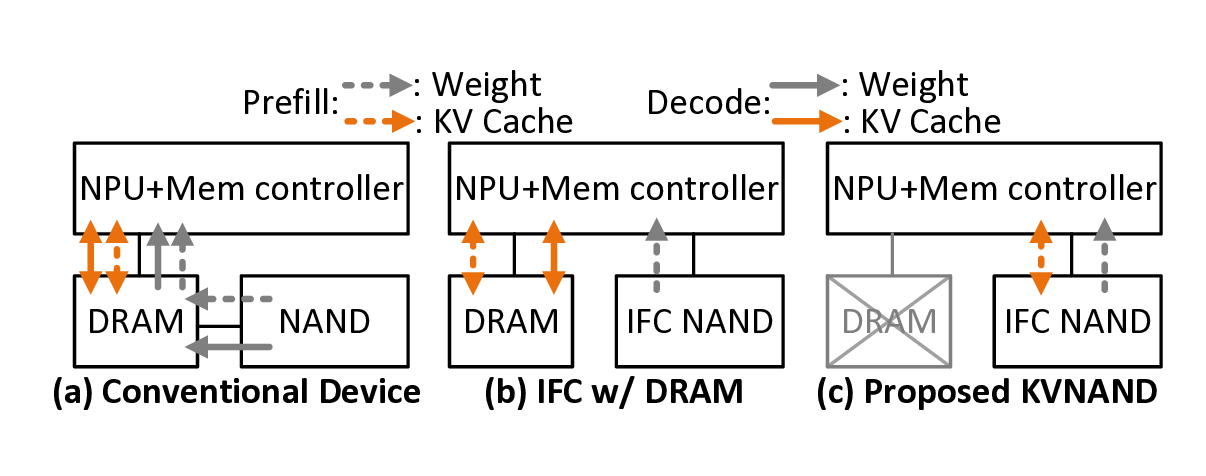
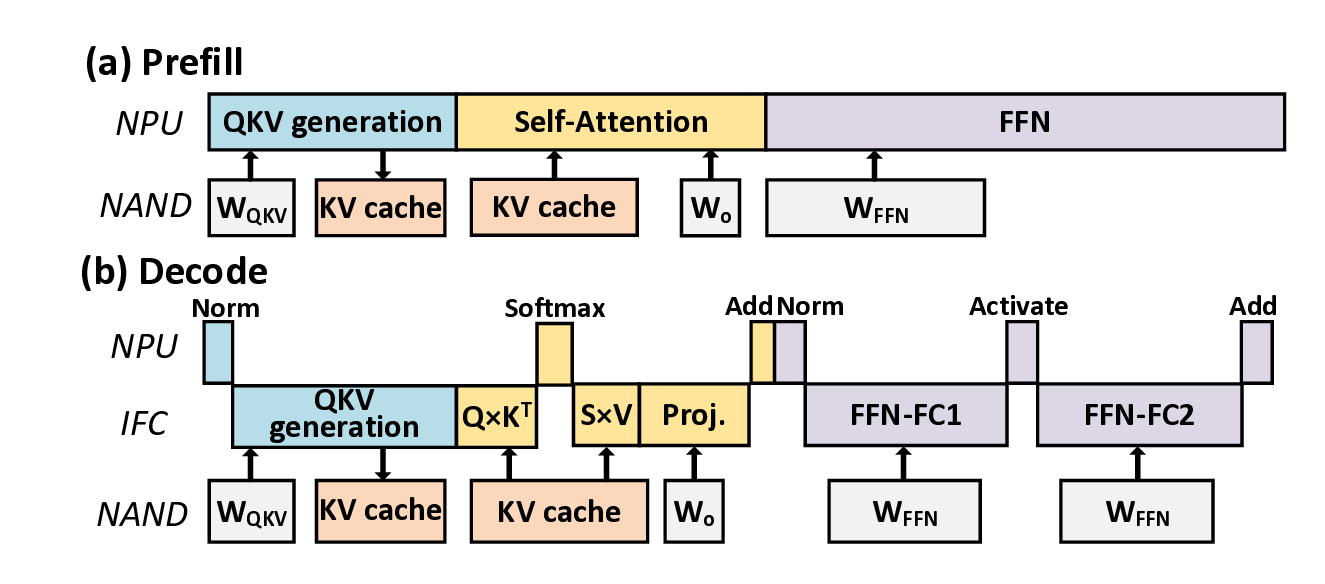
To address the challenges of memory footprint, conventional devices selectively load weights from high-capacity flash into DRAM [5], but still suffering from limited flash I/O bandwidth. Figure 1(b) summarizes more advanced inflash computing (IFC) designs such as Cambricon-LLM [81] and Lincoln [67], which push memory-bound operations into the flash to utilize the higher inner bandwidth. Unfortunately, these designs still rely on DRAM for the KV cache, which imposes prohibitive cost and energy under long contexts, while KV-dependent attention computations remain on the NPU, constraining performance.
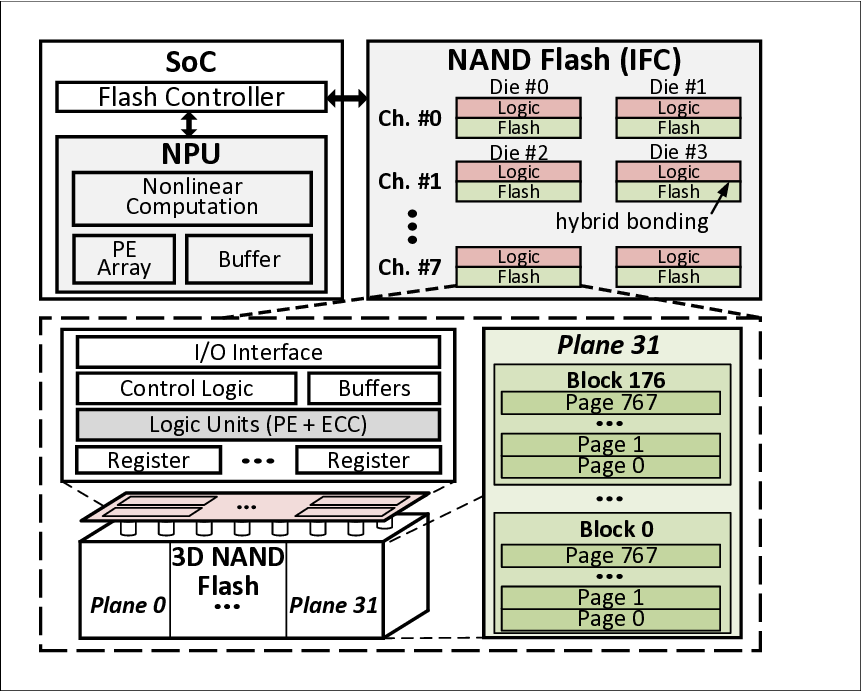
To overcome these bottlenecks, we propose KVNAND, a DRAM-free NPU-IFC architecture that unifies model weights and KV cache within compute-enabled 3D hybrid-bonding NAND flash. KVNAND eliminates the need for DRAM by storing KV cache directly in flash, leveraging the large capacity and low cost. The architecture extends IFC coverage beyond model weights-related GEMVs to the KV-related GEMVs to improve performance. This approach ensures that all memory-bound computations are serviced by IFC, avoiding intensive KV cache transfers.
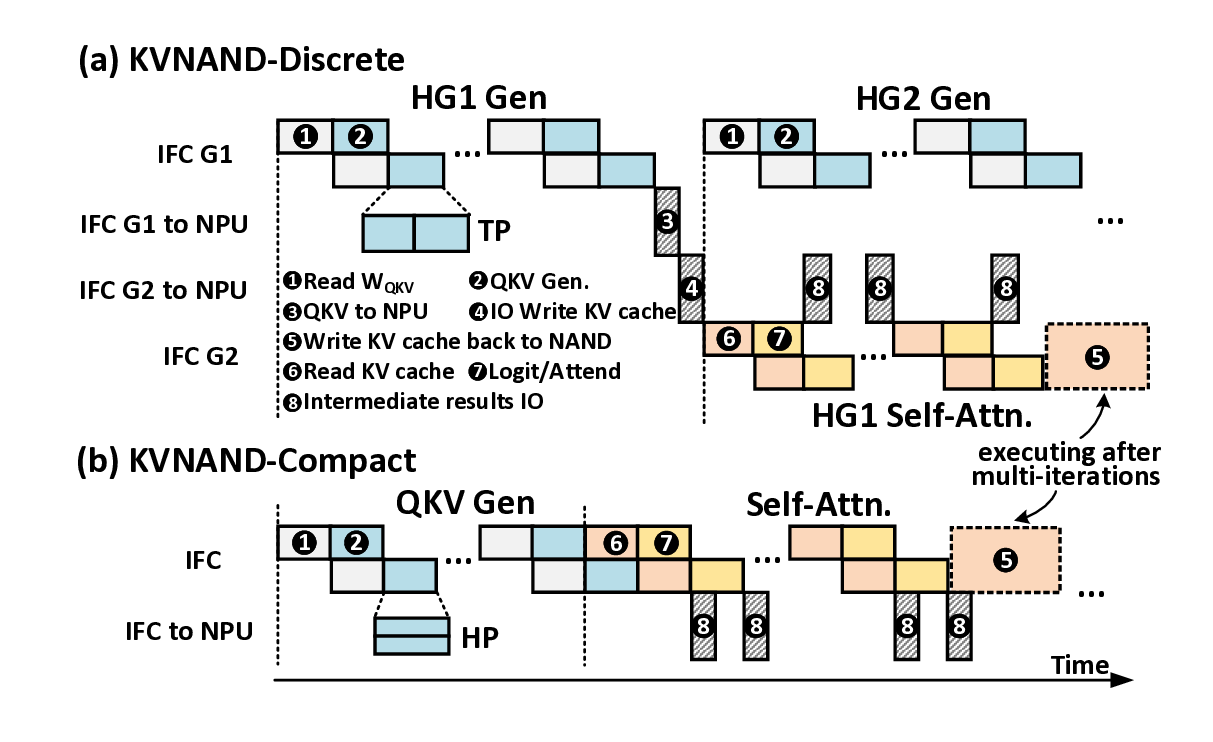
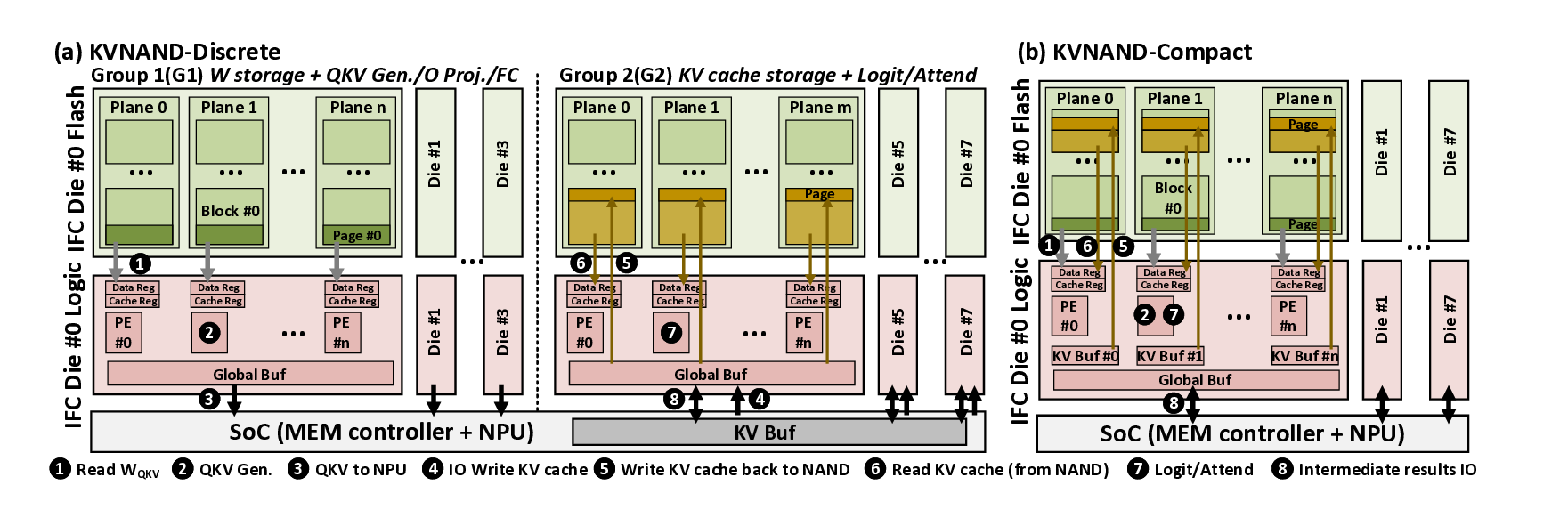
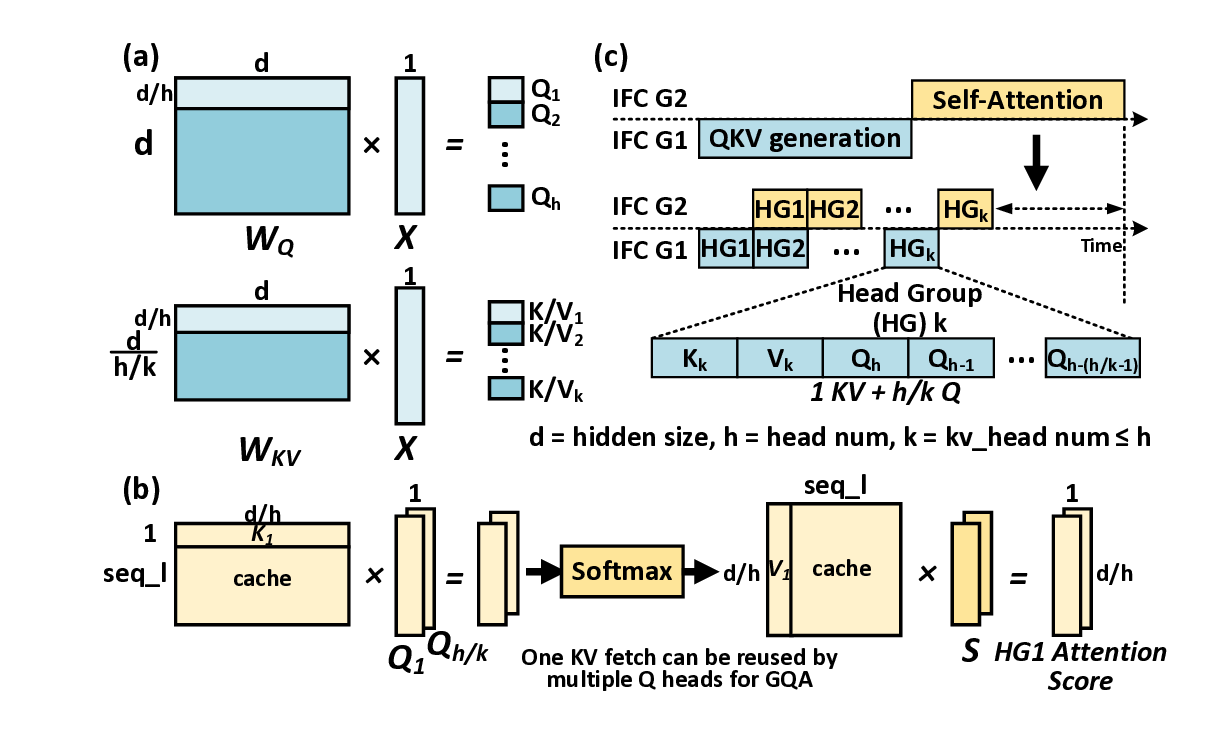
To accommodate diverse model scales and context length requirements, we design two complementary KVNAND variants and explore the design space, drawing inspiration from the fundamental tradeoffs inherent in pipeline-parallelism (PP) and tensor-parallelism (TP). KVNAND-Discrete places weights and KV cache in separate groups of IFC dies for KVheavy cases, enabling head-group pipeline parallel execution that overlaps QKV generation with attention computation. KVNAND-Compact instead stores KV cache in-place within the same flash arrays as the weights for short context length, exploiting higher TP under the same hardware budget and reducing KV inter-die communication.
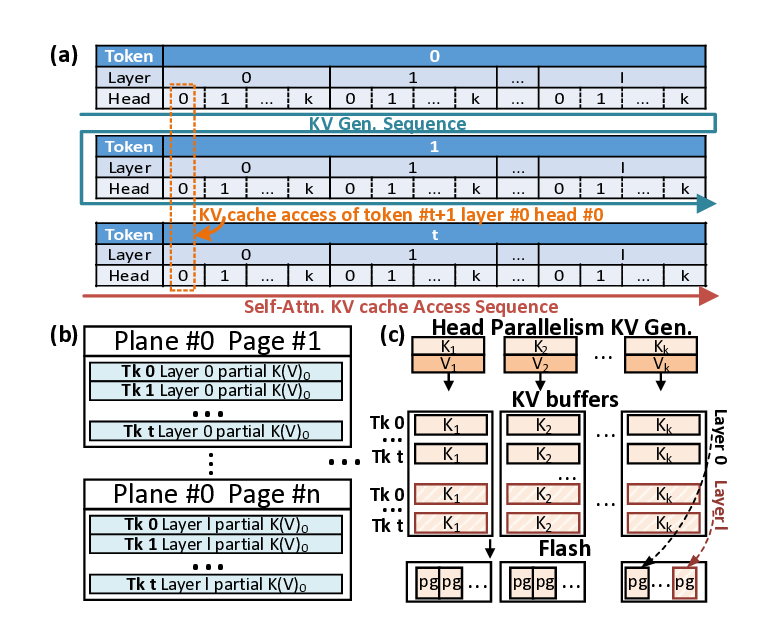
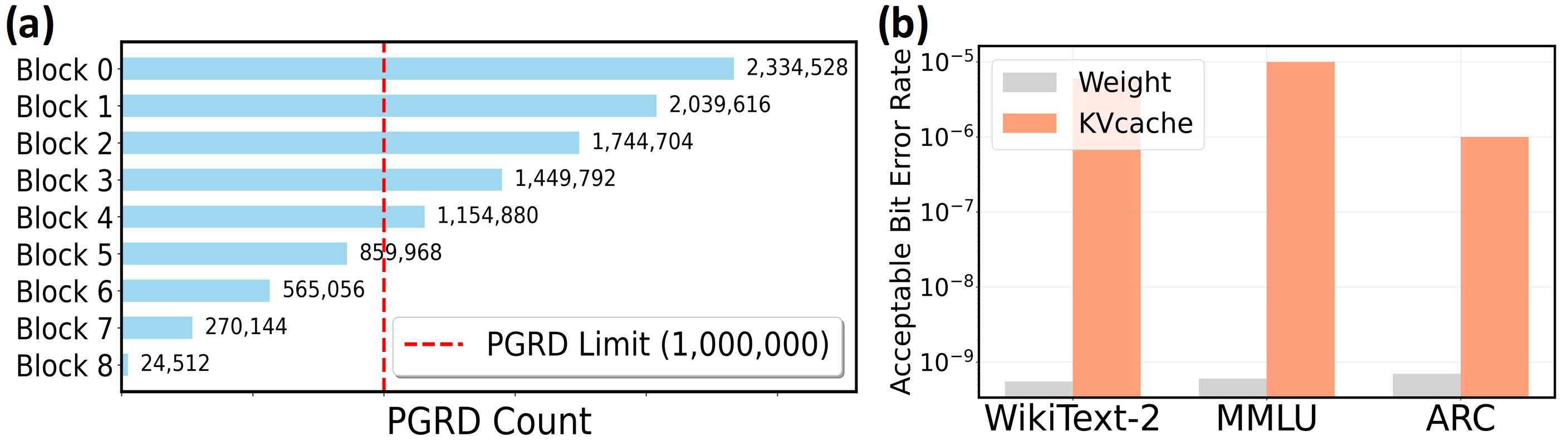
KVNAND further introduces a page-level KV cache mapping strategy that aligns KV placement with flash’s page-level access granularity and the distinct access patterns of KV generation and attention. With the aid of lightweight KV buffers, this scheme improves read/write efficiency and significantly reduces redundant page reads. In addition to IFC’s core benefit of significantly reducing the movement of intermediate results and large-batch KV cache, the external bandwidth of modern NAND is rapidly evolving. Per-die bandwidth has increased from 3.6 GB/s (ONFI 5.2) to 4.8 GB/s [51], [58], [79], closely approaching that of LPDDR5X DRAM (8 GB/s) [54] Reliability concerns can also be alleviated by using periodic reclaim [67] and intensive spare flash capacity.
To the best of our knowledge, KVNAND is the first ondevice LLM inference architecture that offloads all storageintensive operands directly into compute-enabled flash dies. Our design preserves the key advantages of SoTA IFC-based LLM accelerators while further extending the role of modern 3D NAND flash as both the storage substrate and execution engine for deploying long-context LLMs on edge devices. The main contributions are as follows:
• We propose the first DRAM-free IFC-NPU heterogeneous on-device LLM inference accelerator, which stores both the KV cache and weights and executes memory-bound operations in compute-enabled 3D NAND flash.
• We introduce discrete and compact variants of KVNAND and provide an design space exploration (DSE) framework for selecting configurations under given model, context length, and hardware constraints.
• We op
This content is AI-processed based on open access ArXiv data.