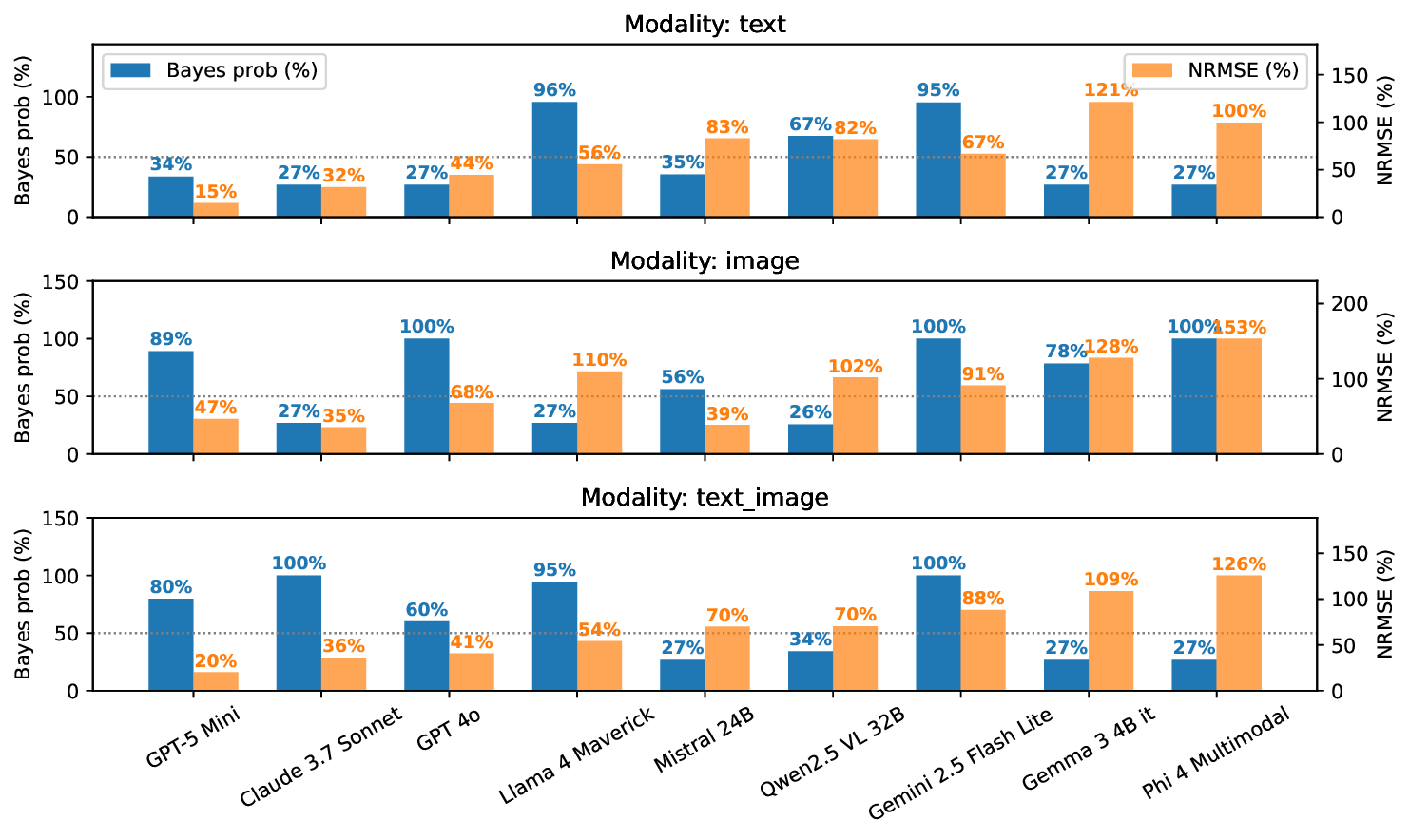
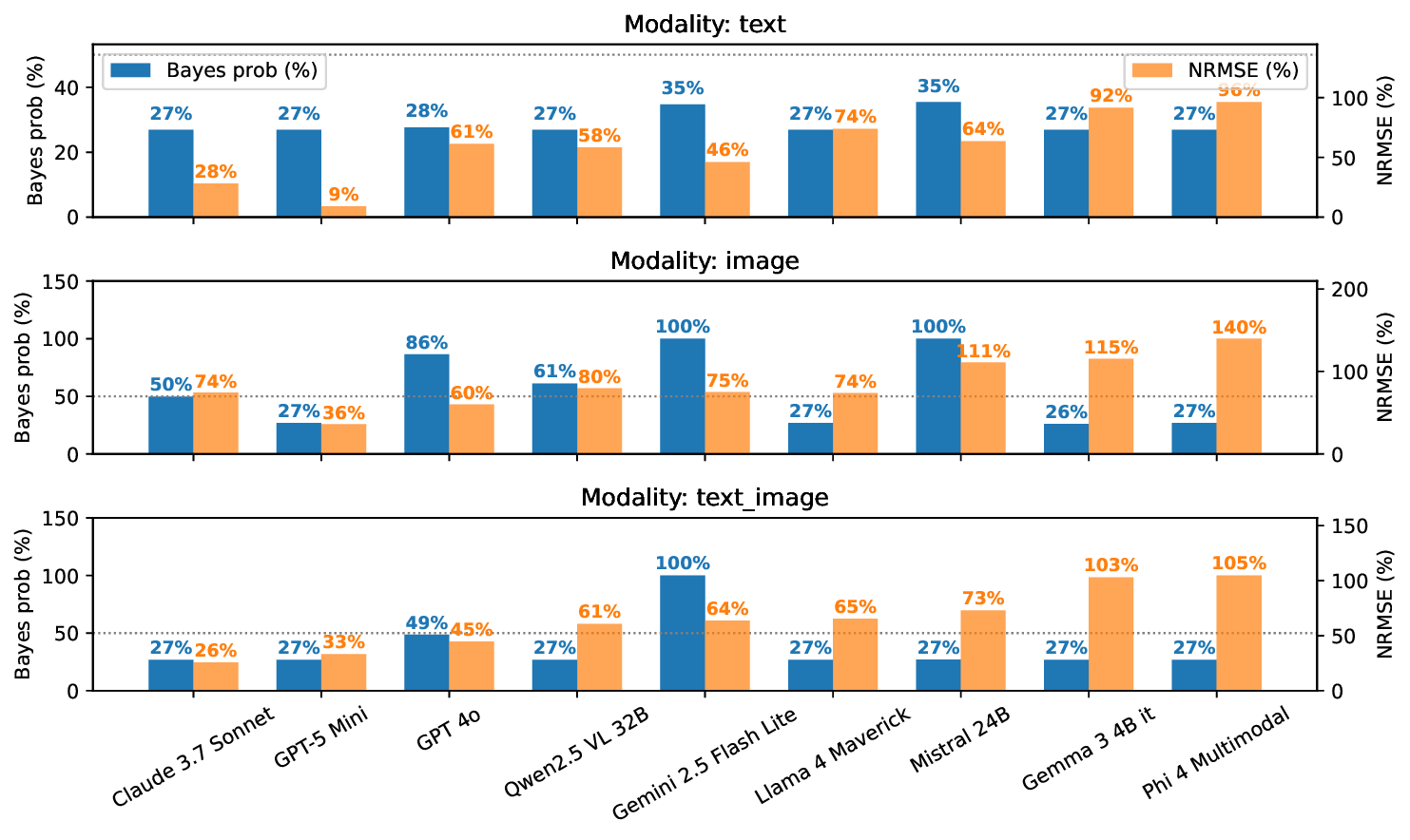
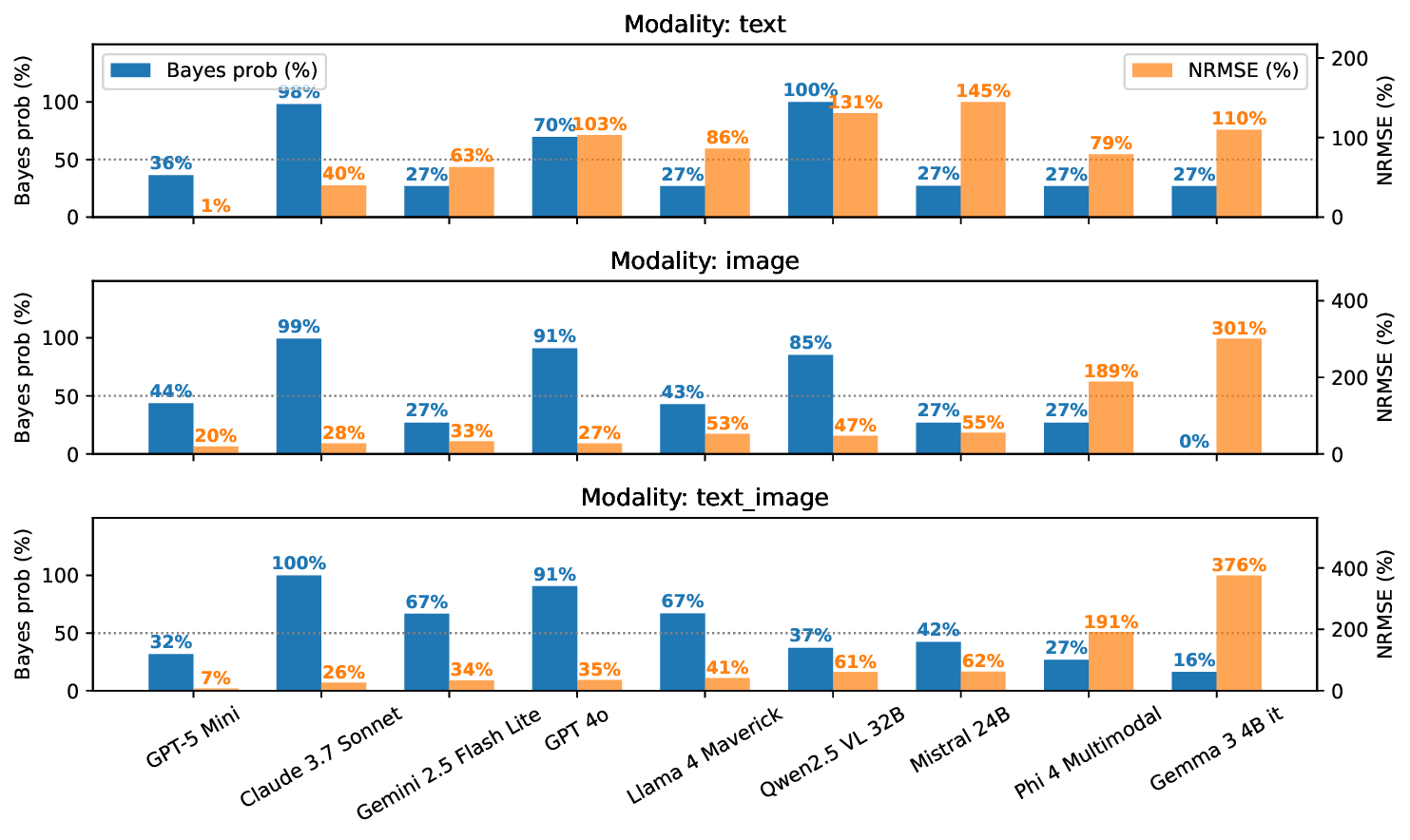
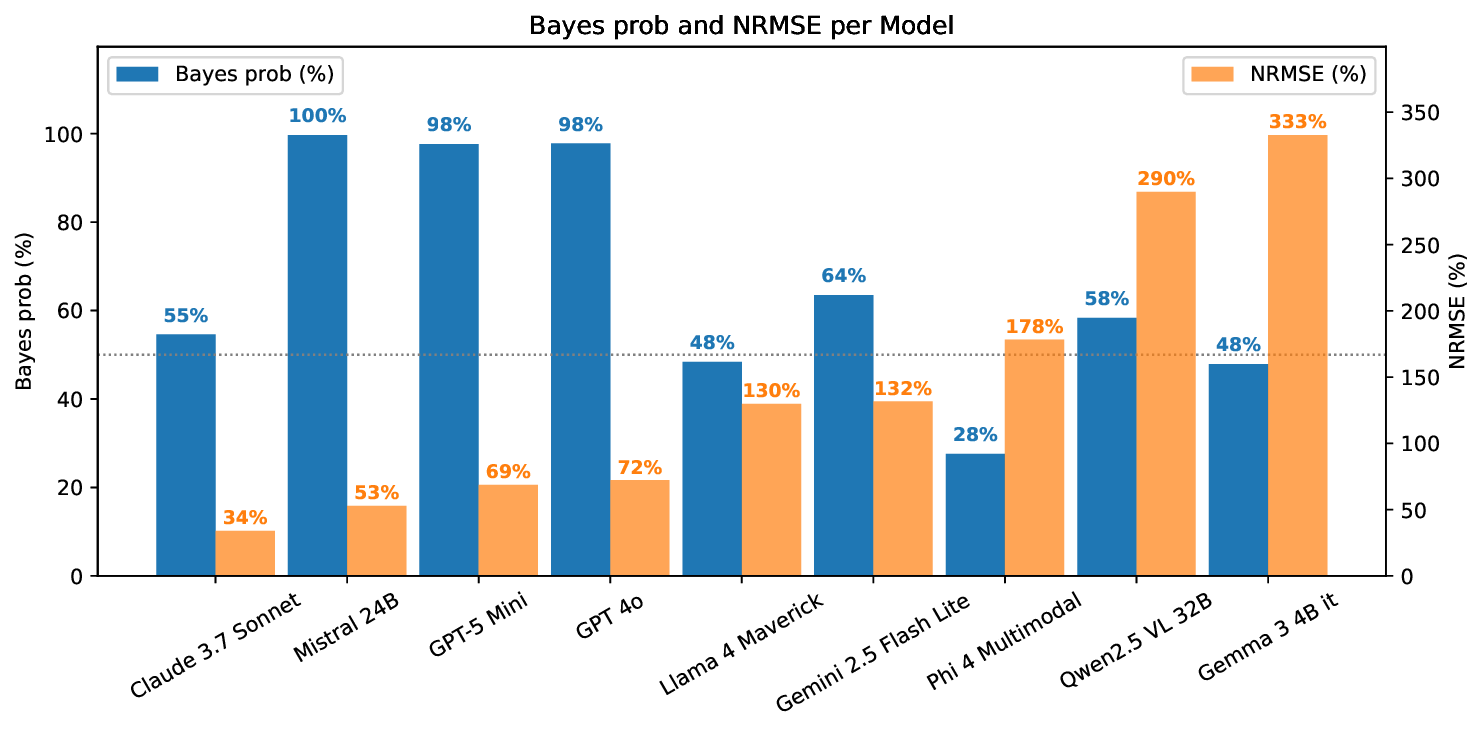
Large language models (LLMs) excel at explicit reasoning, but their implicit computational strategies remain underexplored. Decades of psychophysics research show that humans intuitively process and integrate noisy signals using near-optimal Bayesian strategies in perceptual tasks. We ask whether LLMs exhibit similar behaviour and perform optimal multimodal integration without explicit training or instruction. Adopting the psychophysics paradigm, we infer computational principles of LLMs from systematic behavioural studies. We introduce a behavioural benchmark - BayesBench: four magnitude estimation tasks (length, location, distance, and duration) over text and image, inspired by classic psychophysics, and evaluate a diverse set of nine LLMs alongside human judgments for calibration. Through controlled ablations of noise, context, and instruction prompts, we measure performance, behaviour and efficiency in multimodal cue-combination. Beyond accuracy and efficiency metrics, we introduce a Bayesian Consistency Score that detects Bayes-consistent behavioural shifts even when accuracy saturates. Our results show that while capable models often adapt in Bayes-consistent ways, accuracy does not guarantee robustness. Notably, GPT-5 Mini achieves perfect text accuracy but fails to integrate visual cues efficiently. This reveals a critical dissociation between capability and strategy, suggesting accuracy-centric benchmarks may over-index on performance while missing brittle uncertainty handling. These findings reveal emergent principled handling of uncertainty and highlight the correlation between accuracy and Bayesian tendencies. We release our psychophysics benchmark and consistency metric (https://bayes-bench.github.io) as evaluation tools and to inform future multimodal architecture designs.
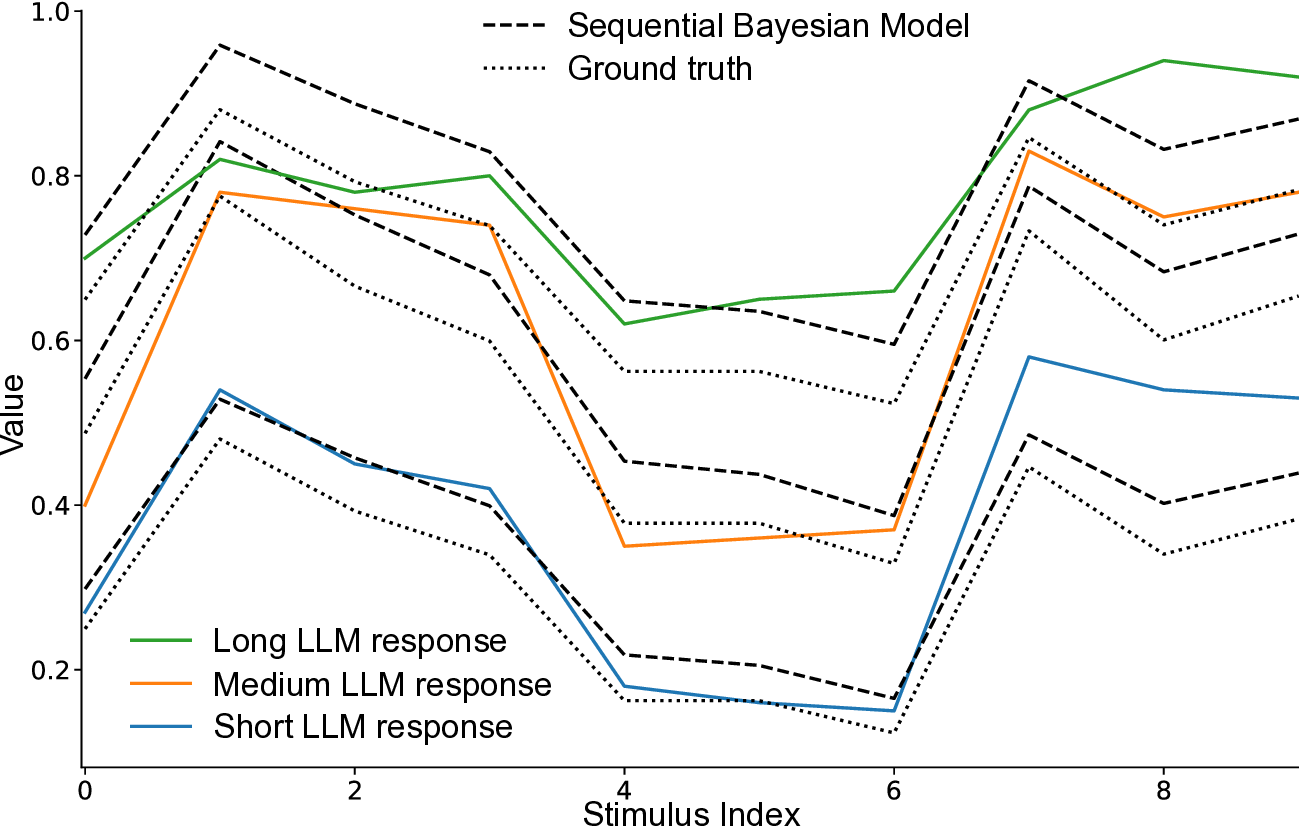
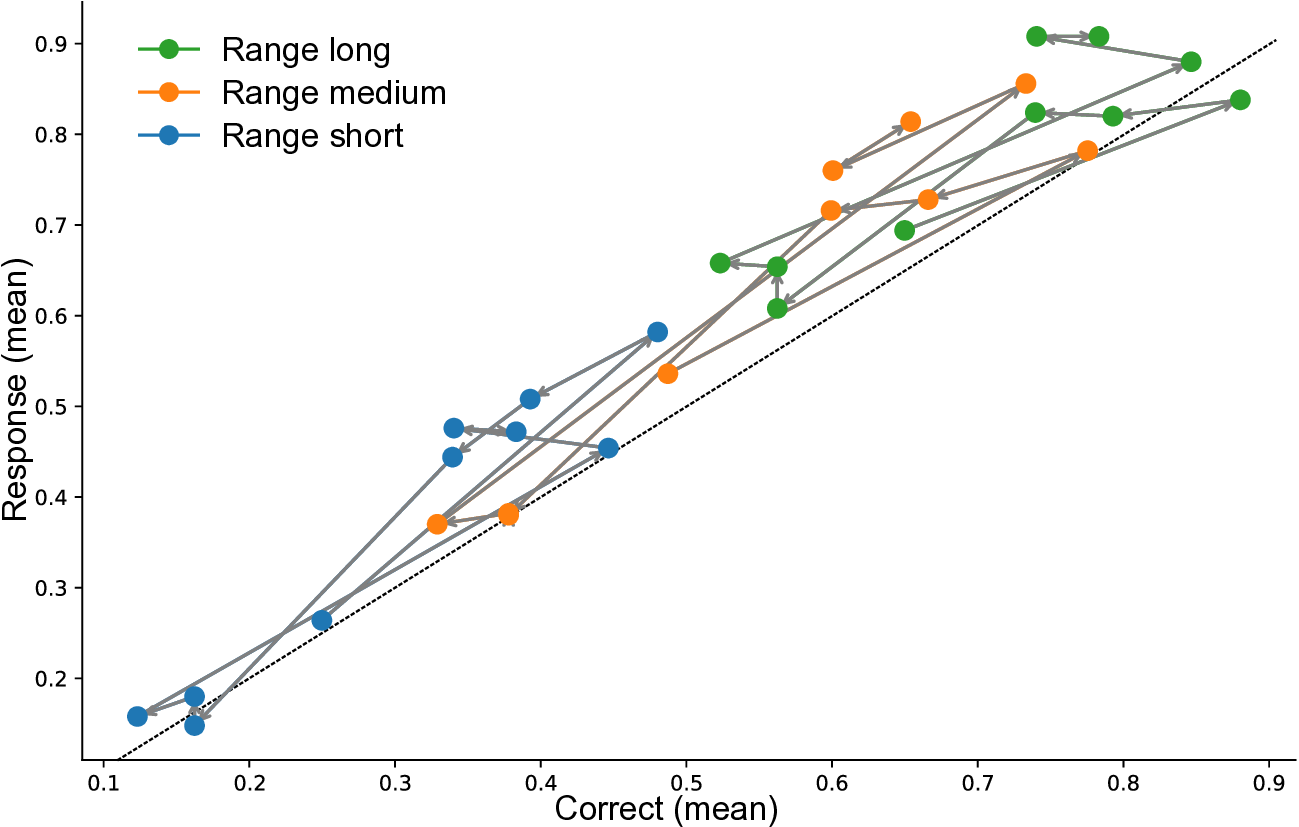
The estimation of magnitudes, including quantities like length, duration, or distance, represents one of the most fundamental computations in biological and artificial intelligence. Humans perform these judgments through the Bayesian integration of noisy sensory signals, automatically weighting cues by their reliability (Ernst & Banks, 2002) and incorporating prior expectations to minimise estimation error (Remington et al., 2018;Knill & Pouget, 2004). This computational strategy emerges without explicit instruction across diverse cultures and developmental stages, suggesting it reflects a fundamental solution to information processing under uncertainty. This universality raises the critical question of whether modern LLMs, trained solely on next-token prediction without explicit perceptual objectives (Radford et al., 2018), spontaneously develop analogous computational strategies. Understanding how LLMs process and integrate uncertain information has immediate implications for building robust multimodal systems that appropriately handle varying input quality (Kendall & Gal, 2017;Ma et al., 2022). Thurley, 2016). We see in both that there is a regression to the mean effect, where responses are biased towards the centre of the stimulus range.
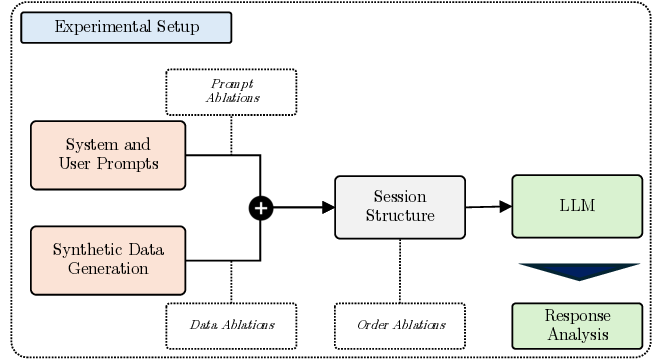
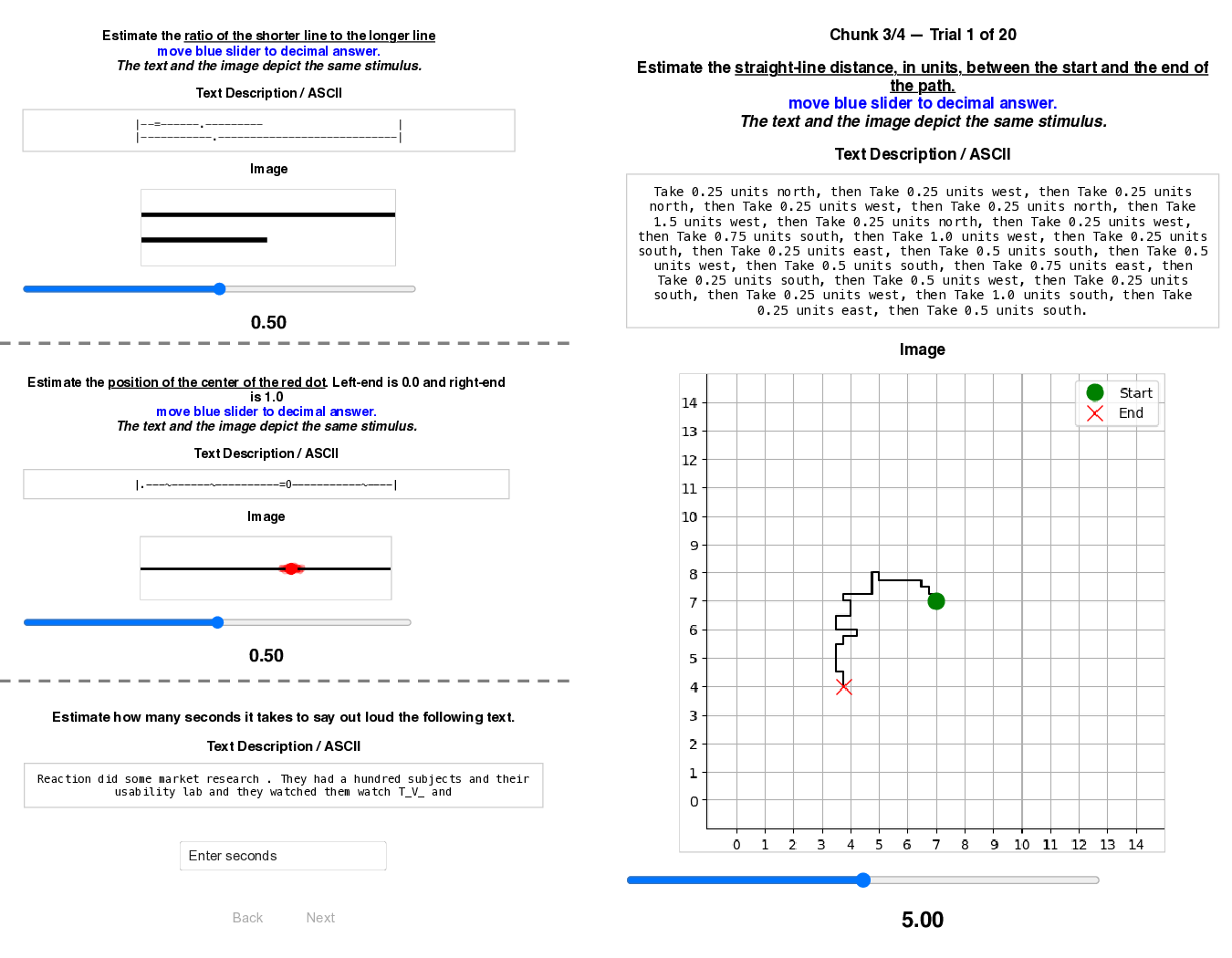
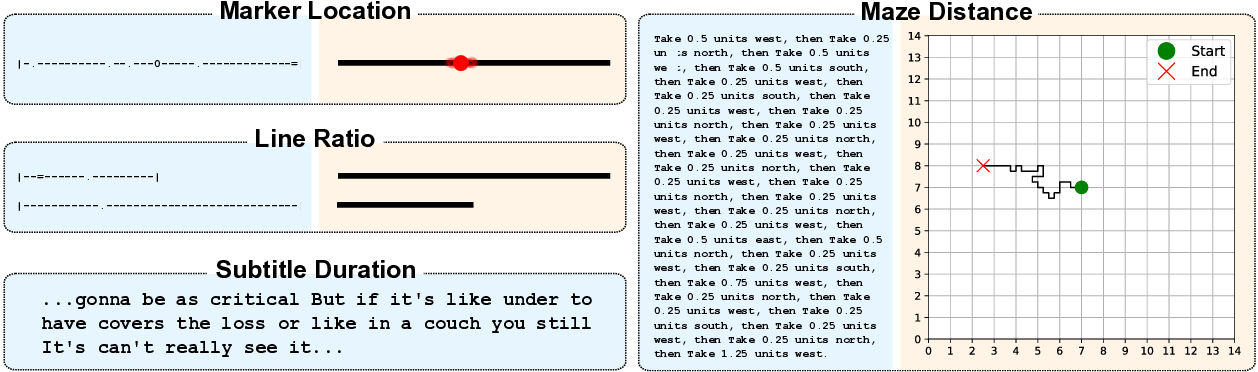
To investigate this, we apply classical psychophysics methodology (Petzschner et al., 2015) to probe these implicit computational strategies in LLMs, treating them as black-box observers and inferring their mechanisms from systematic behavioural analysis. By controlling stimulus uncertainty and measuring characteristic signatures of Bayesian processing, we can determine whether LLMs exhibit human-like optimal perception without explicit training. We found that classic identity mapping tasks, prevalent in psychophysics studies, transfer well to experiments with LLMs and reveal a rich set of patterns. We demonstrate that these controlled tasks serve as necessary ‘unit tests’ for multimodal robustness. Unlike naturalistic tasks where noise is unquantifiable, our protocol enables controlled ablations that test for optimal integration strategies, exposing brittleness invisible to standard benchmarks. We present three contributions: 1) We introduce a systematic psychophysics framework for LLMs, a reproducible pipeline for four synthetic magnitude estimation tasks probing length, location, distance, and duration.
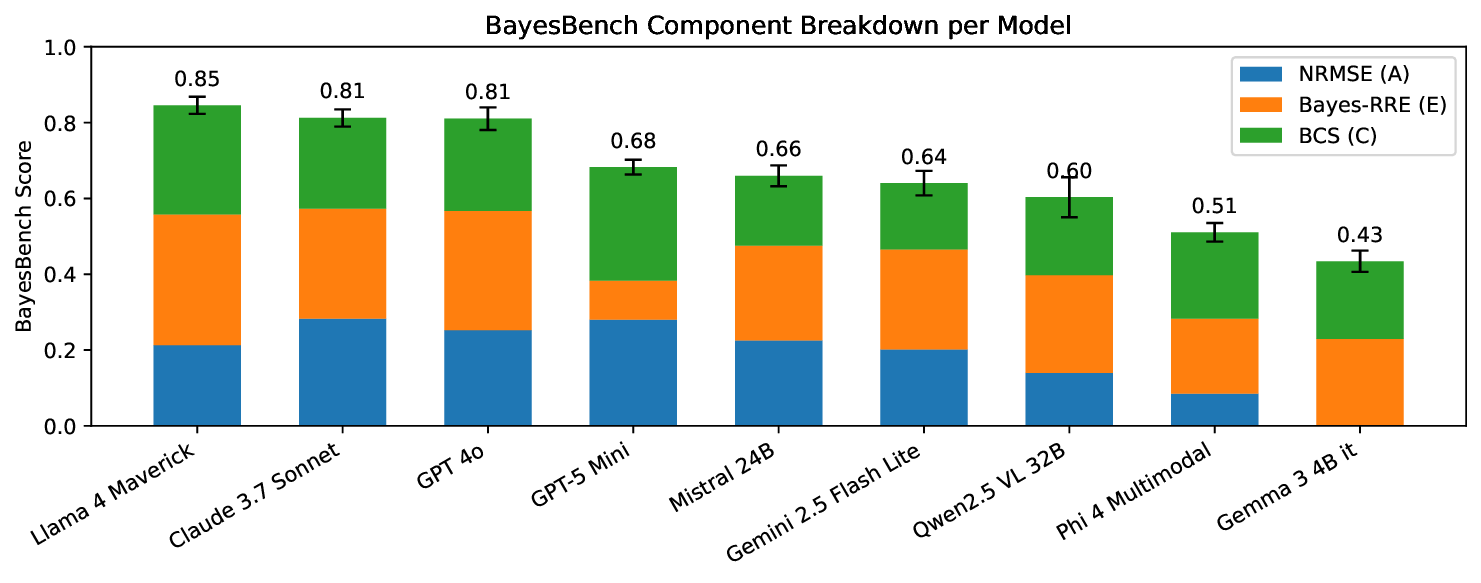
Our pipeline allows controlled ablations of noise, context, and instruction prompts to track behavioural changes. This framework can serve as infrastructure for future investigations bridging human psychophysics studies 2) We develop a new benchmark: BayesBench based on task performance, cue-combination efficiency, and Bayesian consistency computed with a novel Bayesian Consistency Scores 3) We demonstrate emergent Bayes-consistent behaviour in capable LLMs, while uncovering a critical ‘Safety Gap’ where highly accurate models fail to adopt robust strategies.
Human psychophysics. The quantitative study of perception has revealed systematic relationships between physical stimuli and perceptual judgements, formalised in classical laws like Weber-Fechner’s logarithmic scaling and Vierordt’s temporal regression effects (Fechner, 1860;Weber, 1834;Gibbon, 1977;Jazayeri & Shadlen, 2010;Roseboom et al., 2019;Sherman et al., 2022;Fountas & Zakharov, 2023). These phenomena, including scalar variability and sequential biases, emerge from optimal Bayesian inference under uncertainty (Petzschner & Glasauer, 2011). Recent computational models further suggest that these perceptual biases, particularly in time perception, are intrinsically supported by predictive mechanisms in episodic memory Fountas et al. (2022). When observers estimate magnitudes, they automatically combine noisy measurements with prior expectations, producing characteristic behavioural patterns. Figure 1 illustrates this regression-to-the-mean effect in both Llama-4 Maverick’s responses and human psychophysics data-evidence of shared computational principles despite vastly different substrates, as we will see in later sections.
LLMs and Bayesian behaviour. Certain aspects of LLMs are shown to be consistent with Bayesian computation. For example, in-context learning can be interpreted as approximate Bayesian inference (Xie et al., 2021) and, in reasoning, Bayesian teaching is shown to improve performance (Qiu et al., 2025). Similarly, LLMs spontaneously segment sequences using Bayesian surprise in ways that correlate with human event perception (Kumar et al., 2023;Fountas et al., 2025). However, most studies probe explicit reasoning or learned behaviours, where models can leverage acquired statistical rules, rather than perceptual tasks that could reveal computational strategies emerging implicitly from pretraining.
Multimodal studies. Progress have been rapid in developing multimodal LLMs, alongside this is the deployment of benchmarks such as MMbench (Liu et al., 2024) and SEED-bench (Li et al., 2024) that
This content is AI-processed based on open access ArXiv data.