This research presents a novel approach to enhancing automatic speech recognition systems by integrating noise detection capabilities directly into the recognition architecture. Building upon the wav2vec2 framework, the proposed method incorporates a dedicated noise identification module that operates concurrently with speech transcription. Experimental validation using publicly available speech and environmental audio datasets demonstrates substantial improvements in transcription quality and noise discrimination. The enhanced system achieves superior performance in word error rate, character error rate, and noise detection accuracy compared to conventional architectures. Results indicate that joint optimization of transcription and noise classification objectives yields more reliable speech recognition in challenging acoustic conditions.
Modern automatic speech recognition systems have achieved remarkable performance through deep learning architectures, particularly models based on self-supervised learning paradigms.
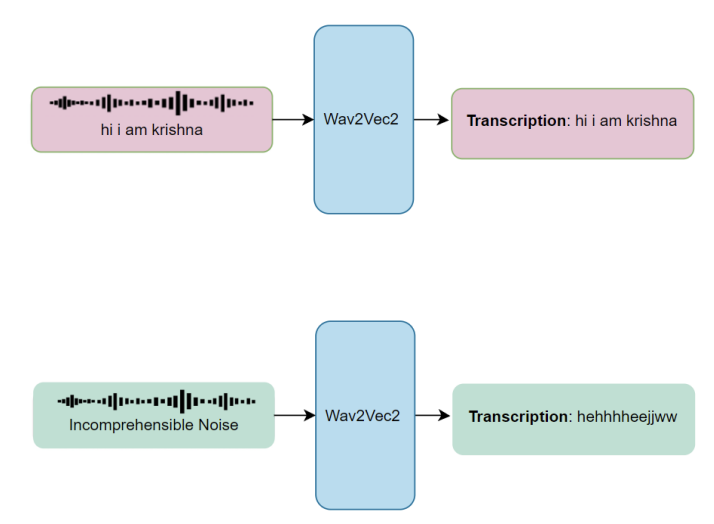
However, real-world deployment scenarios frequently involve challenging acoustic environments where background disturbances significantly compromise recognition accuracy. When processing audio containing substantial non-speech content, conventional systems often generate incoherent outputs, leading to elevated error rates that undermine practical utility.
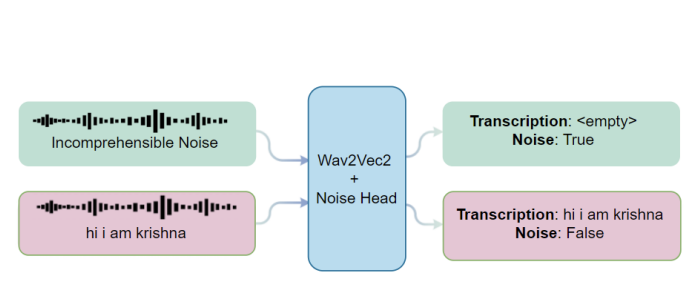
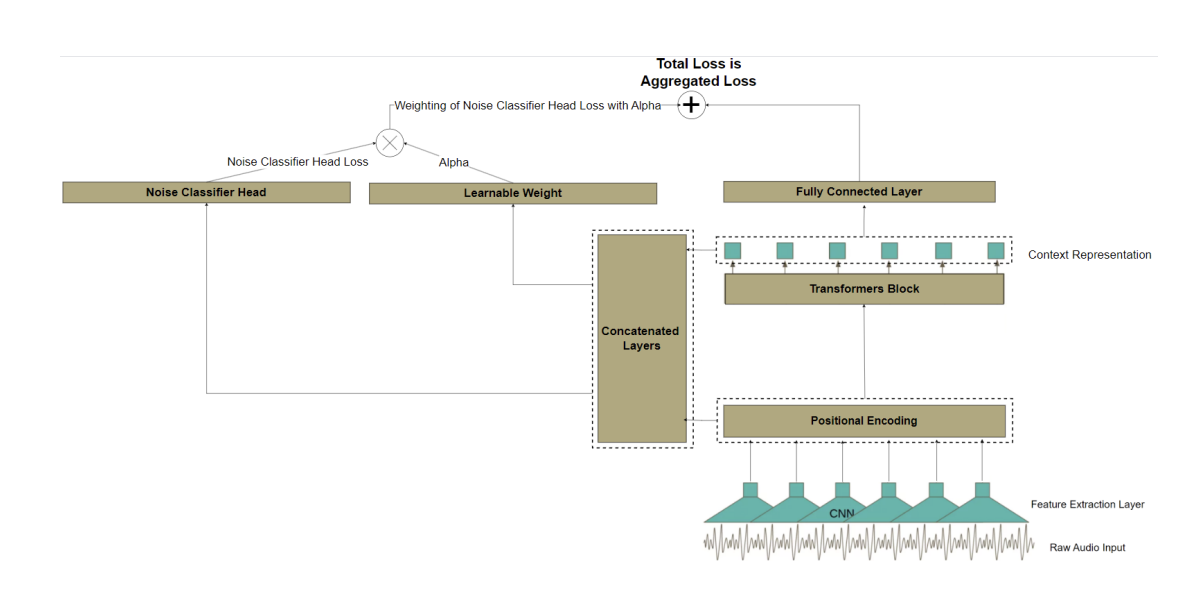
The fundamental challenge addressed in this work stems from the inability of standard ASR architectures to explicitly differentiate between meaningful speech signals and irrelevant acoustic interference. This limitation manifests as increased word error rates and character error rates when processing audio with poor signal-to-noise characteristics. This paper introduces an augmented architecture that extends the wav2vec2 model by incorporating a parallel noise detection pathway. Unlike conventional approaches that handle noise through preprocessing or post-processing stages, the proposed method integrates noise awareness directly into the feature learning process. This architectural modification enables the
Addressing acoustic interference in speech recognition has been a persistent research focus across both neural network and traditional statistical approaches. Early methods emphasized front-end signal processing techniques such as spectral subtraction to enhance signal quality before recognition. Contemporary neural approaches have shifted toward end-to-end systems that implicitly learn noise-robust representations. Recent work has explored various strategies for improving robustness, including domain adaptation techniques, multi-condition training paradigms, and architectural modifications. Data augmentation using simulated room acoustics and diverse noise conditions has proven particularly effective for building generalized models. The availability of large-scale datasets containing realistic acoustic environments has enabled more comprehensive robustness evaluation.
The wav2vec2 framework represents a significant advancement in speech representation learning through self-supervised pretraining on unlabeled audio data. By learning representations that capture acoustic and linguistic structure without explicit supervision, these models achieve strong performance with limited labeled data for downstream tasks.
Cross-lingual extensions of wav2vec2 have demonstrated the potential for multilingual speech recognition using shared architectures. However, performance in acoustically challenging conditions remains an active area of investigation, particularly for low-resource languages and noisy environments.
While previous research has addressed noise robustness through various means, the approach presented here differs in several key aspects. Rather than treating noise handling as a preprocessing concern or relying solely on augmented training data, this work integrates noise awareness as an explicit architectural component. The dual-head design enables simultaneous optimization of transcription accuracy and noise detection, creating a system that inherently understands when input audio contains meaningful speech versus when it should abstain from generating transcriptions.
The experimental framework utilizes multiple publicly available corpora to ensure comprehensive coverage of speech and noise conditions.
For English language speech content, three established datasets were selected: LibriSpeech provides read audiobook recordings totaling 66 hours for training, Common Voice supplies diverse speaker recordings for validation spanning 3 hours, and FLEURS offers multilingual speech data used for testing purposes with 1 hour of English content.
The noise component incorporates three distinct sources: MUSAN provides music and ambient sounds, UrbanSound8K contributes urban environmental recordings, and office environment recordings capture workplace acoustic conditions. These sources ensure representation of diverse interference types including music, crowd noise, mechanical sounds, and general environmental disturbances.
All audio underwent standardized preprocessing including resampling to 16 kHz, removal of punctuation marks, conversion to lowercase characters, and replacement of whitespace with pipe symbols. The training set composition includes 5 percent noise samples mixed with speech audio, while evaluation sets maintain equal proportions of speech and noise content to rigorously test classification capabilities.
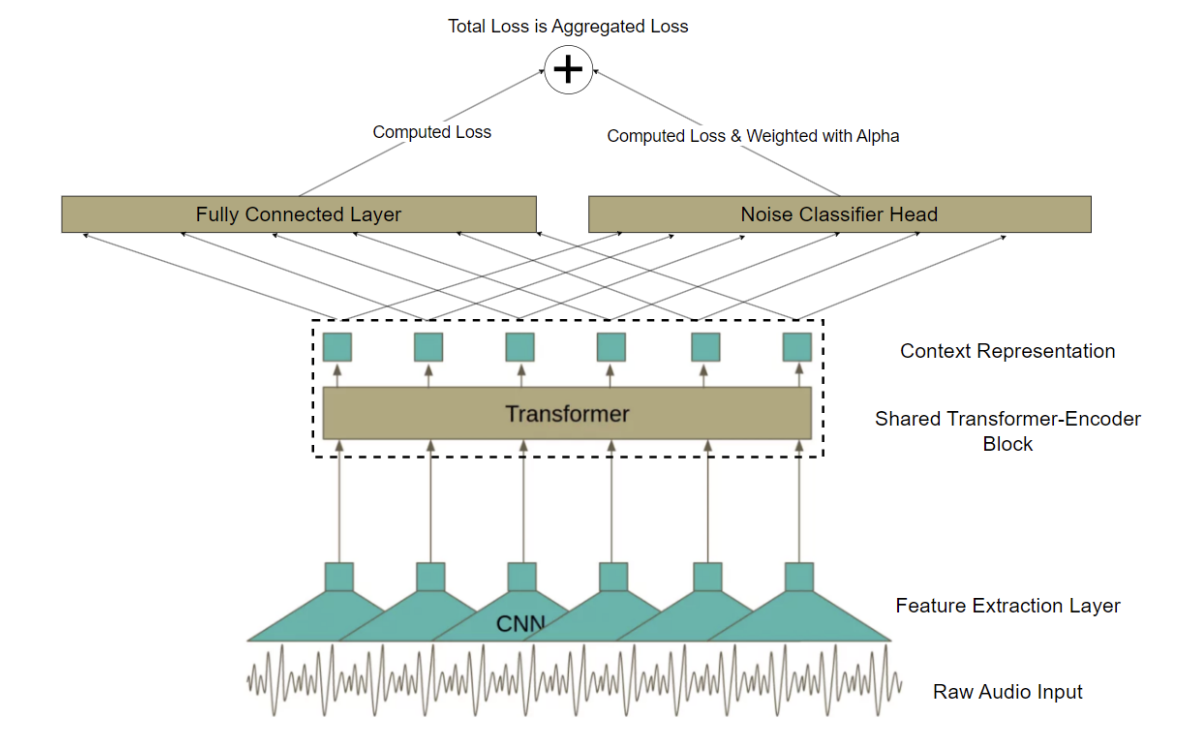
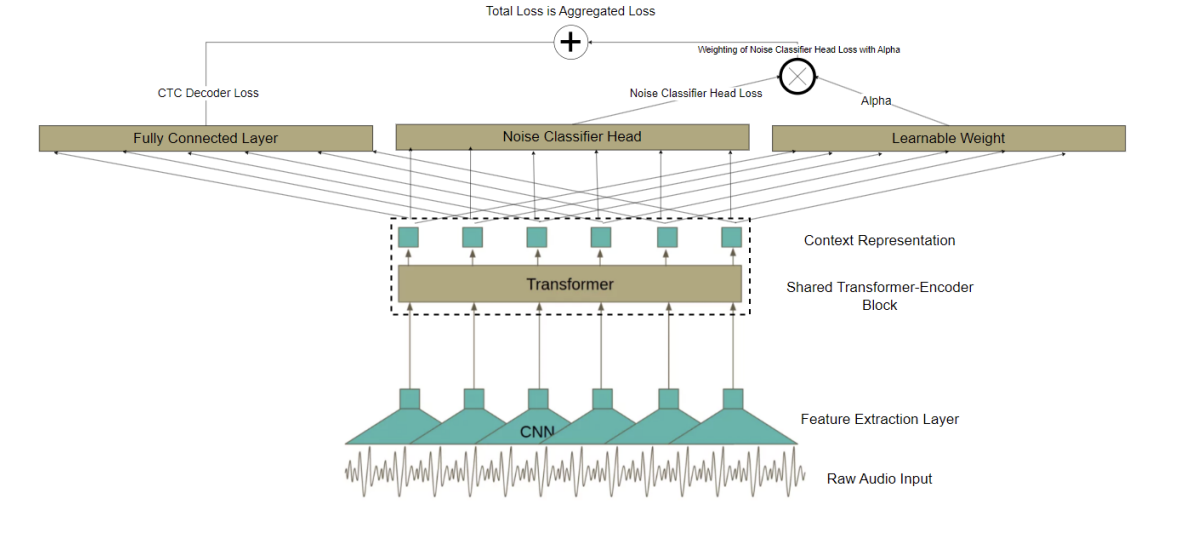
The proposed architecture builds upon established self-supervised speech models with targeted modifications to enable noise awareness. Figures 1 through 5 illustrate the progressive architectural enhancements.
The foundation for this work is the wav2vec2-XLSR-53 model, which provides multilingual speech representations through cross-lingual pretraining. T
This content is AI-processed based on open access ArXiv data.